SummerTime
v1.2.1

مكتبة لمساعدة المستخدمين على اختيار أدوات التلخيص المناسبة بناءً على مهامهم أو احتياجاتهم المحددة. يشمل النماذج ، ومقاييس التقييم ، ومجموعات البيانات.
بنية المكتبة هي كما يلي:
ملاحظة : الصيف في التطوير النشط ، يتم تشجيع أي تعليقات مفيدة للغاية ، يرجى فتح مشكلة أو الوصول إلى أي من أعضاء الفريق.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip المحليبدلاً من ذلك ، للاستمتاع بأحدث الميزات ، يمكنك التثبيت من المصدر:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (عند استخدام التقييم) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/يستورد النموذج ، وتهيئة النموذج الافتراضي ، ويلخص مستندات العينة.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]أيضا ، يرجى تشغيل دفتر كولاب لدينا للحصول على المزيد من الأمثلة العملية والمزيد من الأمثلة.
يدعم Summertime نماذج مختلفة (على سبيل المثال ، Textrank ، BART ، Longformer) بالإضافة إلى الأغطية النموذجية لمهام الملخص الأكثر تعقيدًا (على سبيل المثال ، موديل مشترك للتلخيص متعدد المستودعات ، BM25 استرجاع للتلخيص القائم على الاستعلام). يتم دعم العديد من النماذج متعددة اللغات أيضًا (MT5 و MBART).
| النماذج | واحد | متعددة | قائم على الحوار | قائم على الاستعلام | متعدد اللغات |
|---|---|---|---|---|---|
| Bartmodel | ✔ | ||||
| BM25SUMMMODEL | ✔ | ||||
| hmnetmodel | ✔ | ||||
| Lexrankmodel | ✔ | ||||
| LongFormerModel | ✔ | ||||
| mbartmodel | ✔ | 50 لغة (قائمة كاملة هنا) | |||
| mt5model | ✔ | 101 لغة (قائمة كاملة هنا) | |||
| TranslationPipeLinemodel | ✔ | ~ 70 لغة | |||
| multidocjointmodel | ✔ | ||||
| multidocseparatemodel | ✔ | ||||
| PegasusModel | ✔ | ||||
| Textrankmodel | ✔ | ||||
| tfidfsummmodel | ✔ |
لرؤية جميع النماذج المدعومة ، قم بتشغيل:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()يمكن للمستخدمين الوصول بسهولة إلى الوثائق للمساعدة في اختيار النموذج
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()لاستخدام نموذج للتلخيص ، ما عليك سوى التشغيل:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )يمكن تهيئة جميع النماذج مع الخيارات الاختيارية التالية:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):ستنفذ جميع النماذج الطرق التالية:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :يدعم Summertime مجموعات بيانات تلخيص مختلفة عبر مجالات مختلفة (على سبيل المثال ، CNNDM Dataset - CNNDM - مقال أخبار كوربوس ، سامسوم - حوار كوربوس ، QM -SUM - حوار قائم على الاستعلام ، MultineWs - Multi -Document Corpus ، ML -Sum - Corpus Multi -Lingual ، PubMedqa - Domain Medical Domain - ARXIV DOMAIN ، من بينها.
| مجموعة البيانات | اِختِصاص | # أمثلة | SRC. طول | TGT. طول | استفسار | متعددة | حوار | متعدد اللغات |
|---|---|---|---|---|---|---|---|---|
| arxiv | المقالات العلمية | 215k | 4.9k | 220 | ||||
| CNN/DM (3.0.0) | أخبار | 300K | 781 | 56 | ||||
| mlsumdataset | أخبار متعددة اللغات | 1.5m+ | 632 | 34 | ✔ | الألمانية ، الإسبانية ، الفرنسية ، الروسية ، التركية | ||
| متعددة الأخبار | أخبار | 56 ك | 2.1k | 263.8 | ✔ | |||
| سامسوم | المجال المفتوح | 16 كيلو | 94 | 20 | ✔ | |||
| PubMedqa | طبي | 272 كيلو | 244 | 32 | ✔ | |||
| QMSUM | الاجتماعات | 1K | 9.0k | 69.6 | ✔ | ✔ | ||
| Scisummnet | المقالات العلمية | 1K | 4.7k | 150 | ||||
| Summscreen | البرامج التلفزيونية | 26.9k | 6.6k | 337.4 | ✔ | |||
| Xsum | أخبار | 226k | 431 | 23.3 | ||||
| xlsum | أخبار | 1.35m | ؟؟؟ | ؟؟؟ | 45 لغة (انظر الوثائق) | |||
| chaivesumm | أخبار | 12m+ | ؟؟؟ | ؟؟؟ | 78 لغة (انظر قسم التلخيص متعدد اللغات في ReadMe للحصول على التفاصيل) |
لمشاهدة جميع مجموعات البيانات المدعومة ، قم بتشغيل:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc جميع مجموعات البيانات هي تطبيقات فئة SummDataset . يمكن الوصول إلى انشقاقات بياناتهم على النحو التالي:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set لمشاهدة تفاصيل مجموعات البيانات ، قم بتشغيل:
dataset = dataset . CnndmDataset ()
dataset . show_description () توجد البيانات الموجودة في جميع مجموعات البيانات في كائن فئة SummInstance ، والذي يحتوي على الخصائص التالية:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyيتم تحميل البيانات باستخدام مولد لحفظه في المكان والزمان
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) يمكنك استخدام بيانات مخصصة باستخدام فئة CustomDataset التي تقوم بتحميل البيانات في فئة مجموعة بيانات الصيف
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) تتحقق طريقة summarize() من النماذج متعددة اللغات تلقائيًا من لغة مستند الإدخال.
يمكن تهيئة النماذج المتعددة اللغات الواحدة واستخدامها بنفس طريقة النماذج أحادية اللغة. إنهم يعيدون خطأ إذا كانت اللغة غير مدعومة من قبل النموذج هي الإدخال.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )يتم دعم اللغات التالية حاليًا في تنفيذنا لمجموعة بيانات Scasesivesumm: Afrikaans ، amharic ، العربية ، الأسامية ، Aymara ، أذربيجاني ، بامبارا ، البنغالية ، التبت ، البوسني ، الفلغري ، الفلغاري ، الكاتالاني ، ويلش ، دانمش ، ألمانيا ، غربانو ، اللغة الإنجليزية ، الفرس ، غوجاراتي ، هايتي ، الهوسا ، العبرية ، الهندية ، الكرواتية ، الهنغارية ، الأرمنية ، الإغبو ، إندونيسية ، أيسلندي ، إيطالي ، ياباني ، الكانادا ، جورجيا ، خمير ، كينيارواندا ، جيرجيان ، كوريان ، كورديش ، لاتفيان ، لاتفيان ، ليتوا ، ليت. منغولي ، بورميز ، جنوب نديبيلي ، نيبالي ، الهولندي ، الأوريا ، أورومو ، البنجابية ، البولندية ، البرتغالية ، داري ، باشتو ، روماني ، روندي ، روسي ، سنهال ، سلوفاكي ، سلوفيان ، شونا ، الصومالي ، الألبان ، الصربي ، الصربي ، تامايك ، تام. التايلاندية ، تيغنة ، تركية ، أوكرانية ، أردو ، أوزبك ، الفيتنامية ، Xhosa ، يوروبا ، يوي الصينية ، الصينية ، بيسلاما ، والغيلية.
يدعم Summertime مقاييس التقييم المختلفة بما في ذلك: Bertscore ، Bleu ، Meteor ، Rouge ، Rougewe
لطباعة جميع المقاييس المدعومة:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()يمكن تهيئة جميع مقاييس التقييم مع الوسائط الاختيارية التالية:
def __init__ ( self , metric_name ):تنفذ جميع الكائنات المترية التقييم الطرق التالية:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):احصل على نموذج بيانات ملخص
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]تقييم البيانات على مقاييس مختلفة
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) بالنظر إلى مجموعة بيانات Summertime ، يمكنك استخدام وظيفة pipelines.assemble_model_pipeline لاسترداد قائمة من نماذج الصيف المهيئة المتوافقة مع مجموعة البيانات المقدمة.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]========
بالنظر إلى مجموعة بيانات Summertime ، يمكنك استخدام وظيفة pipelines.assemble_model_pipeline لاسترداد قائمة من نماذج الصيف المهيئة المتوافقة مع مجموعة البيانات المقدمة.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )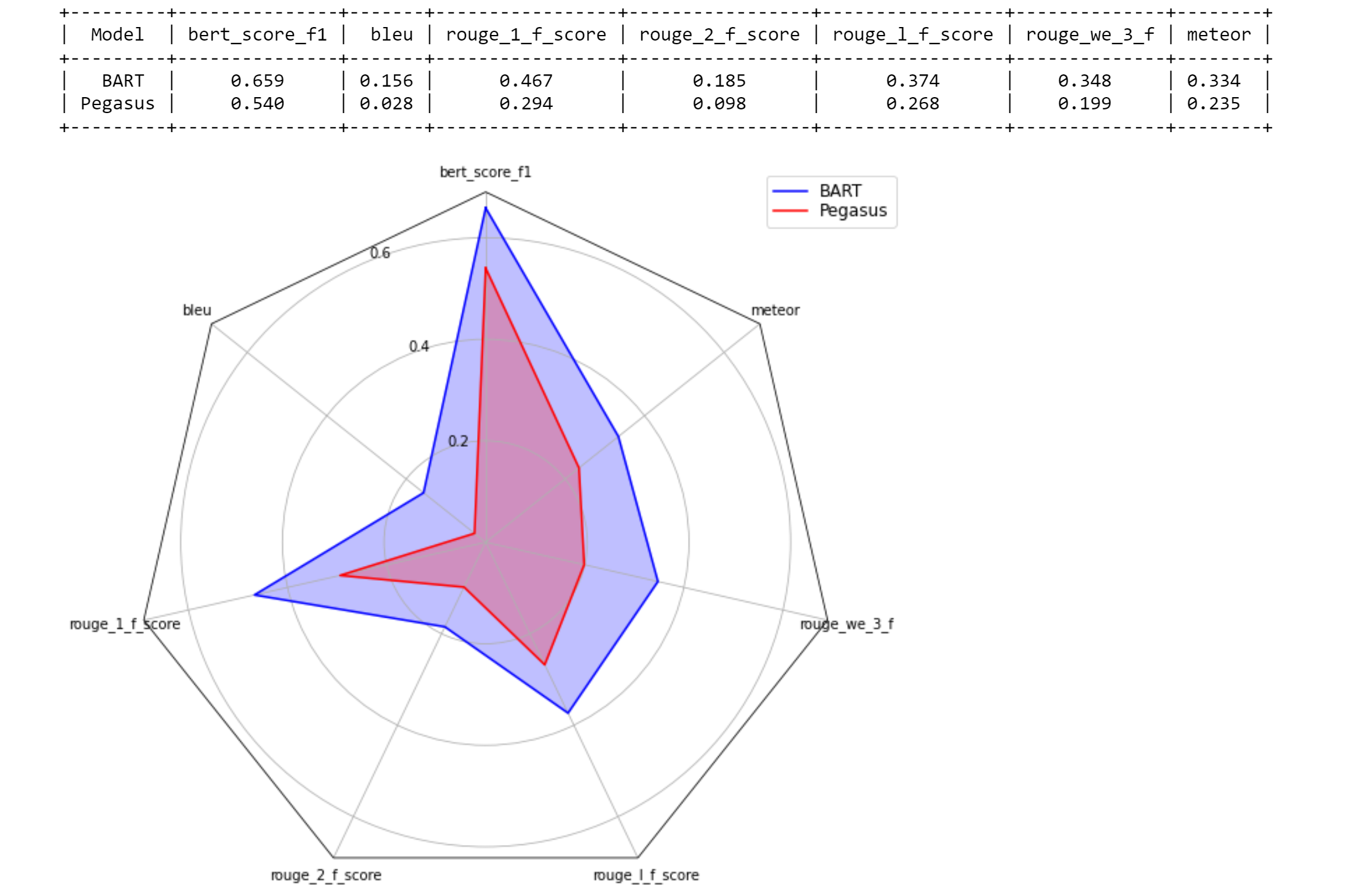
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )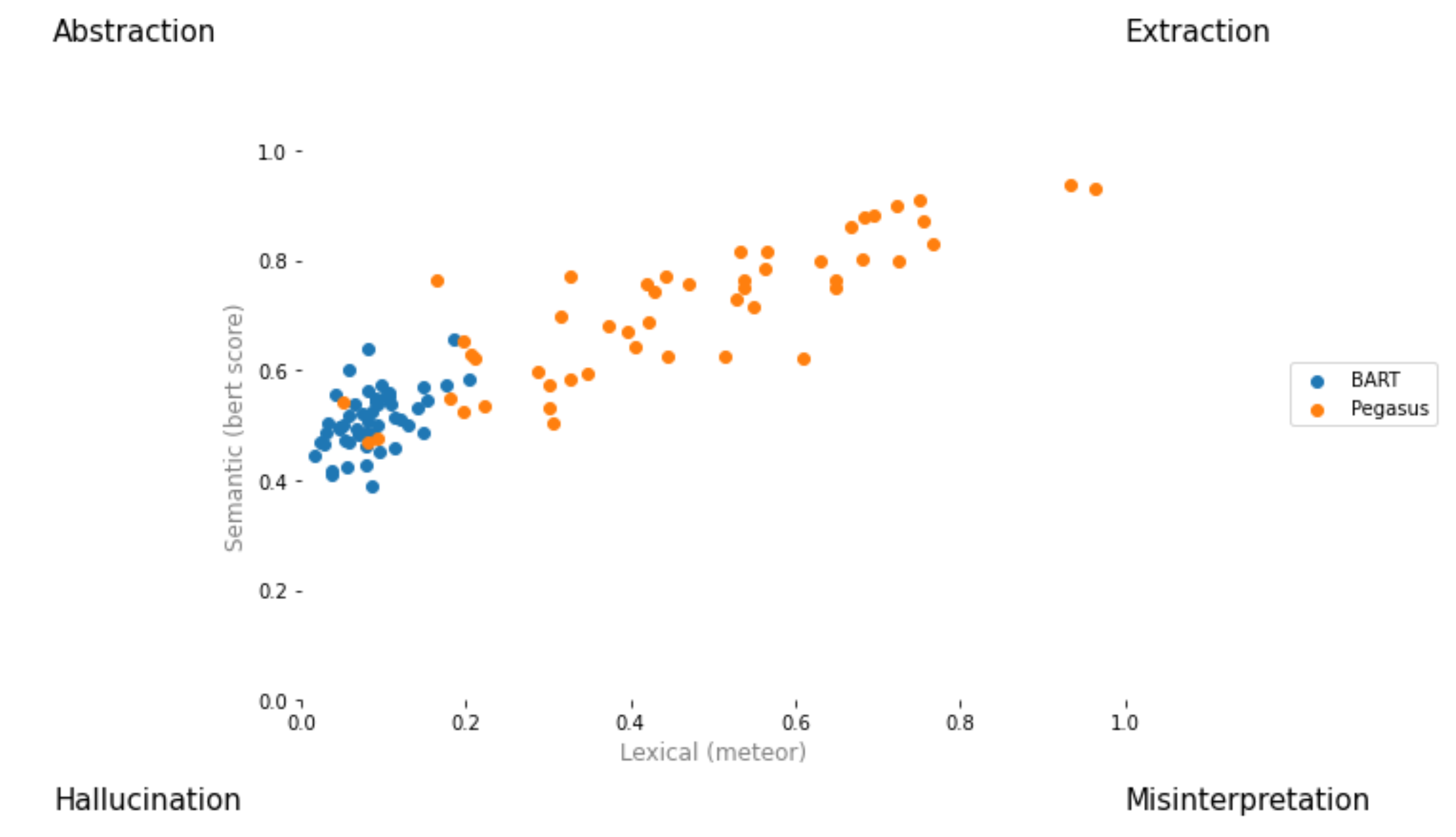
قم بإنشاء طلب سحب وتسميته [ your_gh_username ]/[ your_branch_name ]. إذا لزم الأمر ، حل تعارضات دمج فرعك مع الرئيسي. لا تدفع مباشرة إلى الرئيسية.
إذا لم تكن قد لم تكن بالفعل ، فقم بتثبيت black و flake8 :
pip install black
pip install flake8 قبل الضغط على الفروع أو دمج الفروع ، قم بتشغيل الأوامر التالية من جذر المشروع. لاحظ أن black سوف يكتب إلى الملفات ، وأنه يجب عليك إضافة وارتكاب التغييرات التي أجراها black قبل الدفع:
black .
flake8 .أو إذا كنت ترغب في الترسيب ملفات معينة:
black path/to/specific/file.py
flake8 path/to/specific/file.py تأكد من أن black لا يعيد إعادة تهيئة أي ملفات وأن flake8 لا يطبع أي أخطاء. إذا كنت ترغب في تجاوز أو تجاهل أي من التفضيلات أو الممارسات التي يفرضها black أو flake8 ، فيرجى ترك تعليق في العلاقات العامة الخاصة بك لأي خطوط من الكود التي تولد سجلات التحذير أو الأخطاء. لا تقم بتحرير ملفات التكوين مباشرة مثل setup.cfg .
راجع مستندات المستندات black ومستندات flake8 للوثائق على التثبيت ، وتجاهل الملفات/الخطوط ، والاستخدام المتقدم. بالإضافة إلى ذلك ، قد يكون ما يلي مفيدًا:
black [file.py] --diff لمعاينة التغييرات كصوارير بدلاً من إجراء تغييرات مباشرةblack [file.py] --check لمعاينة التغييرات مع رموز الحالة بدلاً من إجراء تغييرات مباشرةgit diff -u | flake8 --diff لتشغيل Flake8 فقط على تغييرات فرع العمل لاحظ أن مجموعة اختبار CI الخاصة بنا ستشمل استدعاء black --check . و flake8 --count . على جميع ملفات Python غير الأكثر غموضًا وغير المحددة ، والمخرج على مستوى الخطأ صفريًا مطلوبًا لجميع الاختبارات لتمريرها.
يتم توفير نظام التكامل المستمر لدينا من خلال إجراءات GitHub. عند إنشاء أي طلب سحب أو تحديثه أو كلما تم تحديث main ، سيتم إجراء اختبارات وحدة المستودع كوظائف بناء على Tangra لطلب السحب هذا. سوف تمر الوظائف إما أن تمر أو تفشل في غضون بضع دقائق ، وبناء الحالات والسجلات مرئية بموجب الإجراءات. يرجى التأكد من أن الالتزام الأحدث في طلبات السحب يمر جميع الشيكات (أي جميع الخطوات في جميع الوظائف التي يتم تشغيلها إلى الانتهاء) قبل الاندماج ، أو طلب مراجعة. لتخطي البناء على أي التزام معين ، قم بإلحاق [skip ci] إلى رسالة الالتزام. لاحظ أنه لن يتم تضمين PRS مع السلسلة الفرعية /no-ci/ في أي مكان في اسم الفرع في CI.
تم بناء هذا المستودع من قبل Lily Lab في جامعة ييل ، بقيادة البروفيسور دراجومر راديف. المساهمون الرئيسيون هم Ansong NI و Zhangir Azerbayev و Troy Feng و Murori Mutuma و Hailey Schoelkopf و Yusen Zhang (ولاية بنسلفانيا).
إذا كنت تستخدم الصيف في عملك ، فكر في الإشارة إلى:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
للتعليقات والسؤال ، يرجى فتح مشكلة.


