SummerTime
v1.2.1

Perpustakaan untuk membantu pengguna memilih alat peringkasan yang tepat berdasarkan tugas atau kebutuhan spesifik mereka. Termasuk model, metrik evaluasi, dan set data.
Arsitektur perpustakaan adalah sebagai berikut:
Catatan : Summertime sedang dalam pengembangan aktif, komentar yang bermanfaat sangat dianjurkan, buka masalah atau jangkau salah satu anggota tim.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip LokalAtau, untuk menikmati fitur terbaru, Anda dapat menginstal dari sumbernya:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (saat menggunakan evaluasi) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Model impor, menginisialisasi model default, dan merangkum dokumen sampel.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Juga, silakan jalankan Colab Notebook kami untuk demo yang lebih langsung dan lebih banyak contoh.
SummerTime mendukung berbagai model (misalnya, Textrank, BART, Longformer) serta pembungkus model untuk tugas ringkasan yang lebih kompleks (mis., Model sambungan untuk ringkasan multi-doc, pengambilan BM25 untuk ringkasan berbasis kueri). Beberapa model multibahasa juga didukung (MT5 dan MBART).
| Model | Single-doc | Multi-doc | Berbasis dialog | Berbasis kueri | Multibahasa |
|---|---|---|---|---|---|
| Bartmodel | ✔️ | ||||
| BM25Summodel | ✔️ | ||||
| Hmnetmodel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| LongformerModel | ✔️ | ||||
| Mbartmodel | ✔️ | 50 bahasa (daftar lengkap di sini) | |||
| MT5Model | ✔️ | 101 Bahasa (Daftar Lengkap Di Sini) | |||
| Translationpipelinemodel | ✔️ | ~ 70 bahasa | |||
| Multidocjointmodel | ✔️ | ||||
| MultidocseparateModel | ✔️ | ||||
| Pegasusmodel | ✔️ | ||||
| Textrankmodel | ✔️ | ||||
| Tfidfsummmodel | ✔️ |
Untuk melihat semua model yang didukung, jalankan:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Pengguna dapat dengan mudah mengakses dokumentasi untuk membantu pemilihan model
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Untuk menggunakan model untuk peringkasan, cukup jalankan:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Semua model dapat diinisialisasi dengan opsi opsional berikut:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Semua model akan menerapkan metode berikut:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :SummerTime mendukung dataset peringkasan yang berbeda di berbagai domain (misalnya, dataset CNNDM - artikel berita Corpus, Samsum - Dialog Corpus, QM -SUM - Dialog Corpus Berbasis Query, Multinews - Multi -Document Corpus, ML -SUM - Multi -Lingual Corpus, PubMedqa -Medical Domain, Arxumen - Arxiv - Science - Science -Other.
| Dataset | Domain | # Contoh | SRC. panjang | Tgt. panjang | Pertanyaan | Multi-doc | Dialog | Multi-bahasa |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Artikel ilmiah | 215k | 4.9k | 220 | ||||
| CNN/DM (3.0.0) | Berita | 300K | 781 | 56 | ||||
| Mlsumdataset | Berita multi-bahasa | 1.5m+ | 632 | 34 | ✔️ | Jerman, Spanyol, Prancis, Rusia, Turki | ||
| Multi-berita | Berita | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | Domain terbuka | 16K | 94 | 20 | ✔️ | |||
| PubMedqa | Medis | 272k | 244 | 32 | ✔️ | |||
| Qmsum | Rapat | 1k | 9.0k | 69.6 | ✔️ | ✔️ | ||
| Scisummnet | Artikel ilmiah | 1k | 4.7k | 150 | ||||
| Layar puncak | Acara TV | 26.9k | 6.6k | 337.4 | ✔️ | |||
| Xsum | Berita | 226k | 431 | 23.3 | ||||
| Xlsum | Berita | 1.35m | ??? | ??? | 45 bahasa (lihat dokumentasi) | |||
| Massiveumm | Berita | 12m+ | ??? | ??? | 78 Bahasa (lihat Bagian Peringkasan Multilingual dari Readme untuk detailnya) |
Untuk melihat semua dataset yang didukung, jalankan:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Semua dataset adalah implementasi kelas SummDataset . Pemisahan data mereka dapat diakses sebagai berikut:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Untuk melihat detail dataset, jalankan:
dataset = dataset . CnndmDataset ()
dataset . show_description () Data dalam semua dataset terkandung dalam objek kelas SummInstance , yang memiliki properti berikut:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyData dimuat menggunakan generator untuk menghemat ruang dan waktu
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Anda dapat menggunakan data khusus menggunakan kelas CustomDataset yang memuat data di kelas Dataset Summertime
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) Metode summarize() model multibahasa secara otomatis memeriksa bahasa dokumen input.
Model multibahasa DOC tunggal dapat diinisialisasi dan digunakan dengan cara yang sama seperti model monolingual. Mereka mengembalikan kesalahan jika bahasa yang tidak didukung oleh model adalah input.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )Bahasa -bahasa berikut ini saat ini didukung dalam implementasi dataset MASSIVESUMM: Afrikaans, Amharic, Arab, Assam, Aymara, Azerbaijan, Bambara, Bengali, Tibet, Bosnis, Bulgaria, Catalan, Czech, Welsh, Danish, Jerman, Inggris, Inggris, Esper, Espero, Espero, Espero, Esperino, Welsh, Danish, Jerman, Jerman, Inggris, Esper, Gujarati, Haitian, Hausa, Hebrew, Hindi, Croatian, Hungarian, Armenian,Igbo, Indonesian, Icelandic, Italian, Japanese, Kannada, Georgian, Khmer, Kinyarwanda, Kyrgyz, Korean, Kurdish, Lao, Latvian, Lingala, Lithuanian, Malayalam, Marathi, Macedonian, Malagasy, Mongolian, Burmese, South Ndebele, Nepali, Dutch, Oriya, Oromo, Punjabi, Polish, Portuguese, Dari, Pashto, Romanian, Rundi, Russian, Sinhala, Slovak, Slovenian, Shona, Somali, Spanish, Albanian, Serbian, Swahili, Swedish, Tamil, Telugu, Tetum, Tajik, Thailand, Tigrinya, Turki, Ukraina, Urdu, Uzbek, Vietnam, Xhosa, Yoruba, Yue Cina, Cina, Bislama, dan Gaelik.
Musim panas mendukung berbagai metrik evaluasi termasuk: Bertscore, Bleu, Meteor, Rouge, Rougewe
Untuk mencetak semua metrik yang didukung:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Semua metrik evaluasi dapat diinisialisasi dengan argumen opsional berikut:
def __init__ ( self , metric_name ):Semua objek metrik evaluasi mengimplementasikan metode berikut:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Dapatkan Data Ringkasan Sampel
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Mengevaluasi data tentang metrik yang berbeda
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Diberikan dataset musim panas, Anda dapat menggunakan fungsi pipelines.assemble_model_pipeline untuk mengambil daftar model musim panas yang diinisialisasi yang kompatibel dengan dataset yang disediakan.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
Diberikan dataset musim panas, Anda dapat menggunakan fungsi pipa.assemble_model_pipeline untuk mengambil daftar model musim panas yang diinisialisasi yang kompatibel dengan dataset yang disediakan.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )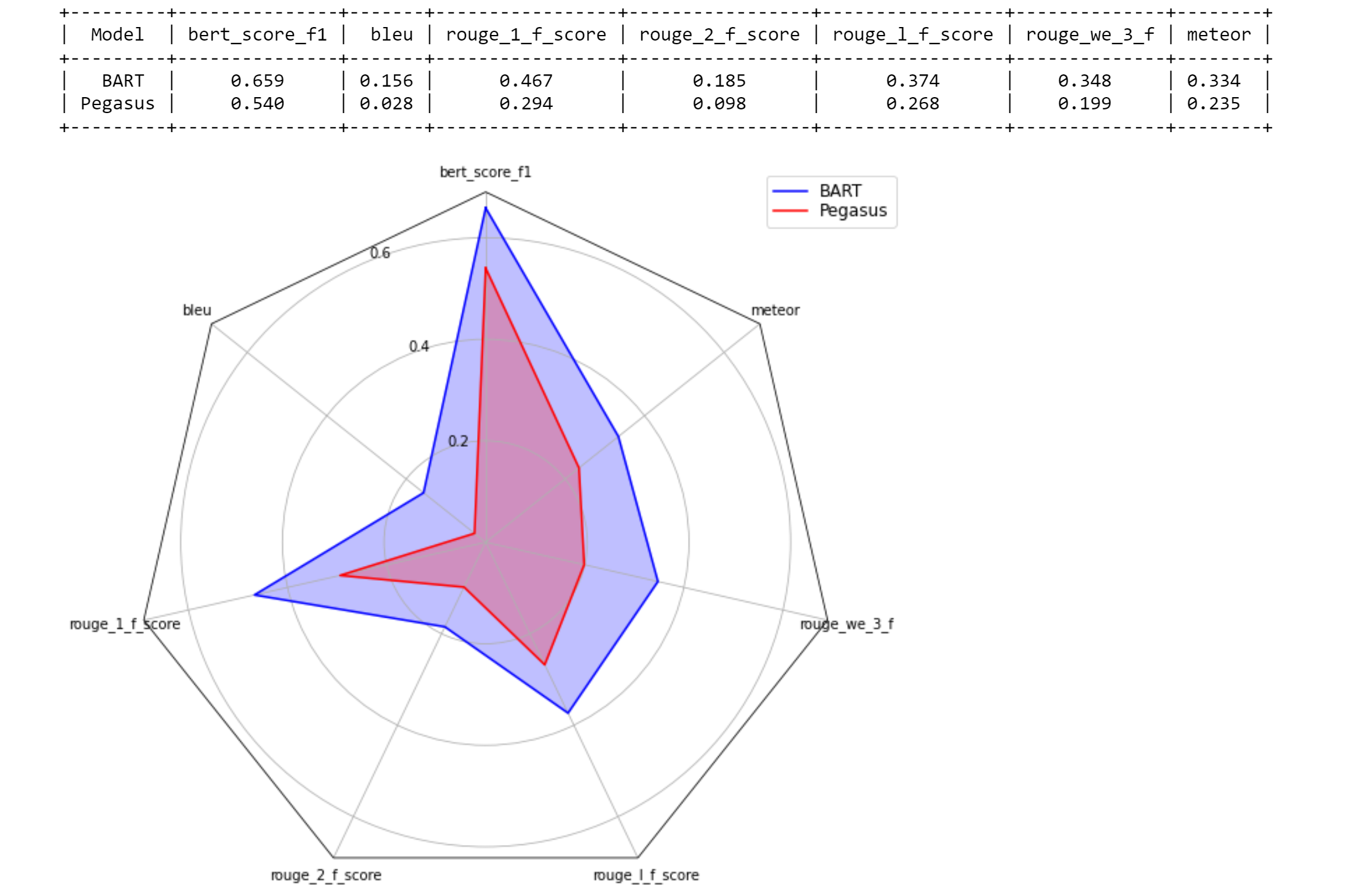
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )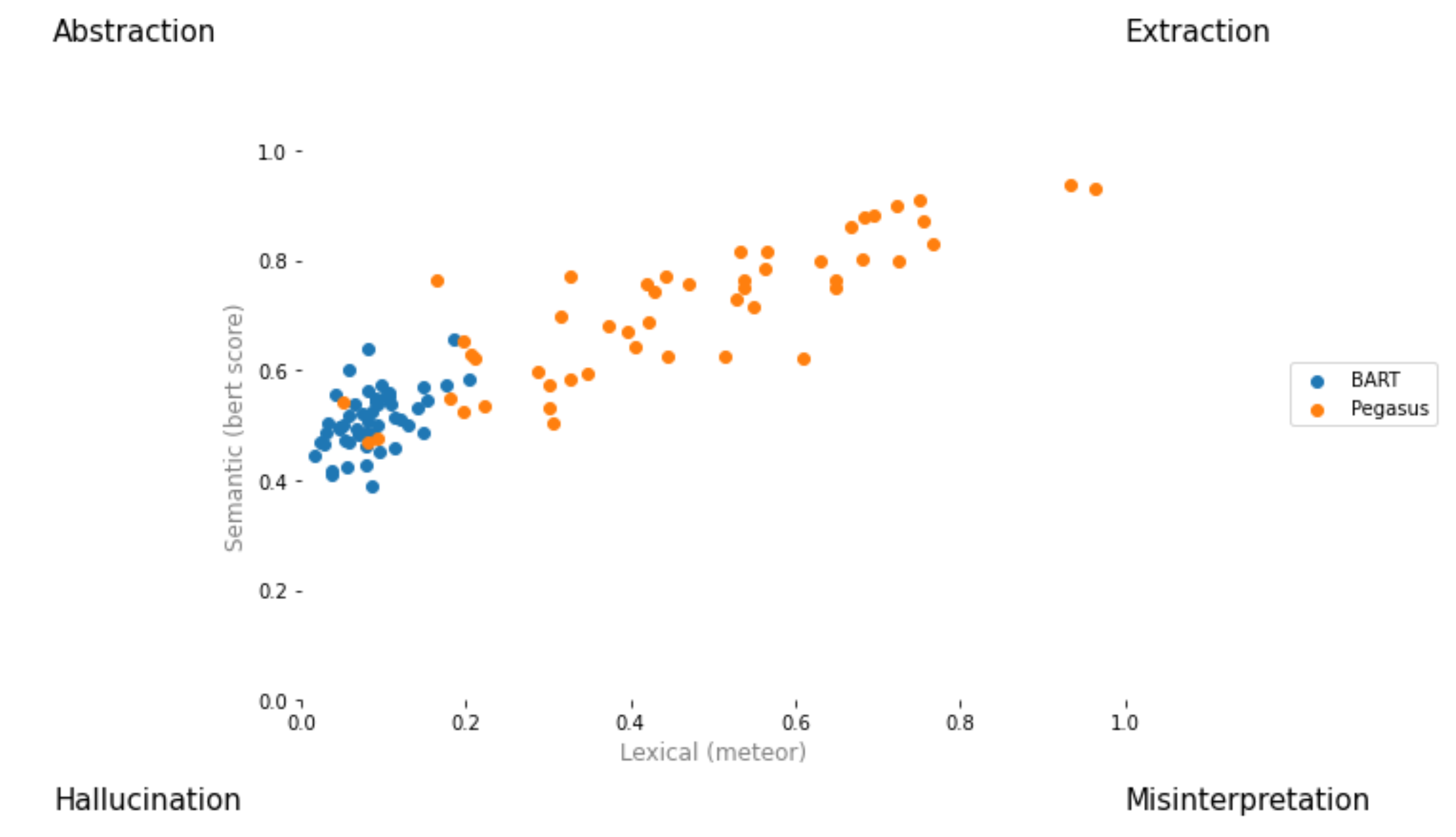
Buat permintaan tarik dan beri nama [ your_gh_username ]/[ your_branch_name ]. Jika perlu, selesaikan konflik penggabungan cabang Anda sendiri dengan Main. Jangan mendorong langsung ke Main.
Jika Anda belum melakukannya, instal black dan flake8 :
pip install black
pip install flake8 Sebelum mendorong komit atau menggabungkan cabang, jalankan perintah berikut dari root proyek. Perhatikan bahwa black akan menulis ke file, dan bahwa Anda harus menambahkan dan melakukan perubahan yang dibuat oleh black sebelum mendorong:
black .
flake8 .Atau jika Anda ingin meletakkan file tertentu:
black path/to/specific/file.py
flake8 path/to/specific/file.py Pastikan black tidak memformat ulang file apa pun dan bahwa flake8 tidak mencetak kesalahan apa pun. Jika Anda ingin mengganti atau mengabaikan preferensi atau praktik apa pun yang ditegakkan oleh black atau flake8 , silakan tinggalkan komentar di PR Anda untuk setiap baris kode yang menghasilkan log peringatan atau kesalahan. Jangan langsung mengedit file konfigurasi seperti setup.cfg .
Lihat dokumen black Docs and flake8 untuk dokumentasi tentang instalasi, mengabaikan file/baris, dan penggunaan lanjutan. Selain itu, berikut ini mungkin berguna:
black [file.py] --diff to Preview perubahan sebagai diff alih -alih secara langsung membuat perubahanblack [file.py] --check to pratinjau perubahan dengan kode status alih -alih membuat perubahan secara langsunggit diff -u | flake8 --diff To hanya menjalankan Flake8 pada perubahan cabang yang bekerja Perhatikan bahwa suite tes CI kami akan mencakup memohon black --check . dan flake8 --count . Pada semua file python non-unittest dan non-setup, dan nol output tingkat kesalahan diperlukan untuk semua tes untuk lulus.
Sistem integrasi berkelanjutan kami disediakan melalui tindakan GitHub. Ketika permintaan tarik dibuat atau diperbarui atau setiap kali main diperbarui, tes unit repositori akan dijalankan sebagai pekerjaan membangun di tangra untuk permintaan tarik itu. Membangun pekerjaan akan lewat atau gagal dalam beberapa menit, dan membangun status dan log terlihat berdasarkan tindakan. Harap pastikan bahwa komit terbaru dalam permintaan tarik melewati semua cek (yaitu semua langkah di semua pekerjaan berjalan sampai selesai) sebelum bergabung, atau meminta ulasan. Untuk melewatkan build atas komit tertentu, tambahkan [skip ci] ke pesan komit. Perhatikan bahwa PR dengan substring /no-ci/ di mana saja di nama cabang tidak akan dimasukkan dalam CI.
Repositori ini dibangun oleh Lily Lab di Yale University, dipimpin oleh Prof. Dragomir Radev. Kontributor utama adalah Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf, dan Yusen Zhang (Penn State).
Jika Anda menggunakan musim panas dalam pekerjaan Anda, pertimbangkan mengutip:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Untuk komentar dan pertanyaan, buka masalah.


