SummerTime
v1.2.1

사용자가 특정 작업 또는 요구 사항에 따라 적절한 요약 도구를 선택할 수 있도록 도와줍니다. 모델, 평가 지표 및 데이터 세트가 포함됩니다.
라이브러리 아키텍처는 다음과 같습니다.
참고 : Summertime은 활발한 개발 중이며, 유용한 의견이 적극 권장됩니다. 문제를 열거나 팀원에게 연락하십시오.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip 설치또는 가장 최근의 기능을 즐기려면 소스에서 설치할 수 있습니다.
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE 설정 (평가를 사용하는 경우) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/모델을 가져오고 기본 모델을 초기화하며 샘플 문서를 요약합니다.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]또한보다 실습 데모와 더 많은 예제를 위해 Colab 노트북을 실행하십시오.
SummerTime은보다 복잡한 요약 작업을위한 모델 포장지뿐만 아니라 다양한 모델 (예 : Multi-DOC 요약을위한 공동 모델, 쿼리 기반 요약을위한 BM25 검색)을 지원합니다. 여러 다국어 모델도 지원됩니다 (MT5 및 MBART).
| 모델 | 단일 DOC | 멀티 DOC | 대화 기반 | 쿼리 기반 | 다국어 |
|---|---|---|---|---|---|
| 바트 모델 | ✔️ | ||||
| BM25summmodel | ✔️ | ||||
| hmnetmodel | ✔️ | ||||
| LexRankModel | ✔️ | ||||
| LongformerModel | ✔️ | ||||
| MBARTMODEL | ✔️ | 50 개 언어 (여기 전체 목록) | |||
| mt5 모델 | ✔️ | 101 언어 (여기 전체 목록) | |||
| TranslationPipelInemodel | ✔️ | ~ 70 개 언어 | |||
| MultidocjointModel | ✔️ | ||||
| Multidocseparatemodel | ✔️ | ||||
| 페가 수스 모델 | ✔️ | ||||
| TextrankModel | ✔️ | ||||
| tfidfsummmodel | ✔️ |
지원되는 모든 모델을 보려면 실행 :
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()사용자는 모델 선택을 지원하기 위해 문서에 쉽게 액세스 할 수 있습니다.
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()요약을 위해 모델을 사용하려면 간단히 실행하십시오.
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )모든 모델은 다음 옵션 옵션으로 초기화 할 수 있습니다.
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):모든 모델은 다음 방법을 구현합니다.
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :SummerTime은 다양한 도메인 (예 : CNNDM 데이터 세트 - 뉴스 기사 코퍼스, 삼미 - 대화 코퍼스, QM -SUM- 쿼리 기반 대화 코퍼스, 멀티 - 문서 코퍼스, ML -SUM- 다중 언어 코퍼스, PubMedqa- 의료 도메인, ARXIV- 과학 종이, 과학 논문에 걸쳐 다양한 요약 데이터 세트를 지원합니다.
| 데이터 세트 | 도메인 | # 예 | SRC. 길이 | Tgt. 길이 | 질문 | 멀티 DOC | 대화 | 다국어 |
|---|---|---|---|---|---|---|---|---|
| arxiv | 과학적 기사 | 215K | 4.9k | 220 | ||||
| CNN/DM (3.0.0) | 소식 | 300K | 781 | 56 | ||||
| mlsumdataset | 다국어 뉴스 | 1.5m+ | 632 | 34 | ✔️ | 독일어, 스페인어, 프랑스어, 러시아어, 터키 | ||
| 멀티 뉴스 | 소식 | 56K | 2.1k | 263.8 | ✔️ | |||
| 삼미 | 오픈 도메인 | 16k | 94 | 20 | ✔️ | |||
| PubMedqa | 의료 | 272K | 244 | 32 | ✔️ | |||
| QMSUM | 회의 | 1K | 9.0K | 69.6 | ✔️ | ✔️ | ||
| scisummnet | 과학적 기사 | 1K | 4.7k | 150 | ||||
| summscreen | TV 쇼 | 26.9k | 6.6k | 337.4 | ✔️ | |||
| xsum | 소식 | 226K | 431 | 23.3 | ||||
| xlsum | 소식 | 1.35m | ? | ? | 45 개 언어 (문서 참조) | |||
| MASSIVESUMM | 소식 | 12m+ | ? | ? | 78 언어 (자세한 내용은 Readme의 다국어 요약 섹션 참조) |
지원되는 모든 데이터 세트를 보려면 실행하십시오.
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc 모든 데이터 세트는 SummDataset 클래스의 구현입니다. 데이터 분할은 다음과 같이 액세스 할 수 있습니다.
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set 데이터 세트의 세부 사항을 보려면 실행하십시오.
dataset = dataset . CnndmDataset ()
dataset . show_description () 모든 데이터 세트의 데이터는 SummInstance 클래스 객체에 포함되어 있으며 여기에는 다음 속성이 있습니다.
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entirety생성기를 사용하여 데이터가로드되어 공간과 시간을 절약합니다.
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) 여름 데이터 세트 클래스에 데이터를로드하는 CustomDataset 클래스를 사용하여 사용자 정의 데이터를 사용할 수 있습니다.
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) 다국어 모델의 summarize() 메소드는 입력 문서 언어를 자동으로 확인합니다.
단일 DOC 다국어 모델은 단일 모델과 동일한 방식으로 초기화 및 사용할 수 있습니다. 모델에서 지원하지 않는 언어가 입력되면 오류를 반환합니다.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )다음 언어는 현재 Afrikaans, Amharic, Arabic, Assamese, Aymara, Azerbaijani, Bambara, Bengali, Tibetan, Bosnian, Bulgarian, Catalan, Czech, Welsh, Danish, Greek, Greek, Esperanto, Persian, Filipino, Filipino,, Filipino,, Filipino, Filipino, Filipino, Filipino, Filipone, Esperanto와 같은 MassiveSumm 데이터 세트를 구현하는 데 지원됩니다. 구자라트, 아이티안, 하우사, 히브리어, 힌디어, 크로아티아, 헝가리어, 아르메니아,이 그보, 인도네시아어, 아이슬란드, 이탈리아, 일본어, 칸나다어, 그루지야, 크메르, 크메르 르완다, 키르기즈, 한국, 쿠르드족, 라오, 라비안, 링 갈라, 말라 얄 람어, 말라 알람, 말라 람어 몽골, 버마어, 사우스 Ndebele, 네팔, 네덜란드, 오리야, 오로모, 펀자 브비, 폴란드어, 포르투갈어, 다리, 파쉬토, 루마니아, 런디, 러시아어, 신 할라, 슬로바키아, 슬로베니아, 쇼아, 소말리아, 스페인, 알바니아, 세르비아, 스와힐리어, 스웨덴, 텔루 구조, 텔루 구스 Tajik, Thai, Tigrinya, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Xhosa, Yoruba, Yue Chinese, Chinese, Bislama 및 Gaelic.
Summertime은 Bertscore, Bleu, Meteor, Rouge, Rougewe를 포함한 다양한 평가 지표를 지원합니다.
지원되는 모든 메트릭을 인쇄하려면 :
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()모든 평가 메트릭은 다음과 같은 선택적 인수로 초기화 할 수 있습니다.
def __init__ ( self , metric_name ):모든 평가 메트릭 객체는 다음 방법을 구현합니다.
def evaluate ( self , model , data ):
def get_dict ( self , keys ):샘플 요약 데이터를 가져옵니다
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]다른 메트릭에 대한 데이터를 평가하십시오
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) 여름 데이터 세트가 주어지면 pipelines.assemble_model_pipeline 사용하여 제공된 데이터 세트와 호환되는 초기 서머 타임 모델 목록을 검색 할 수 있습니다.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
여름 데이터 세트가 주어지면 파이프 라인을 사용하여 제공된 데이터 세트와 호환되는 초기 서머 타임 모델 목록을 검색 할 수 있습니다.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )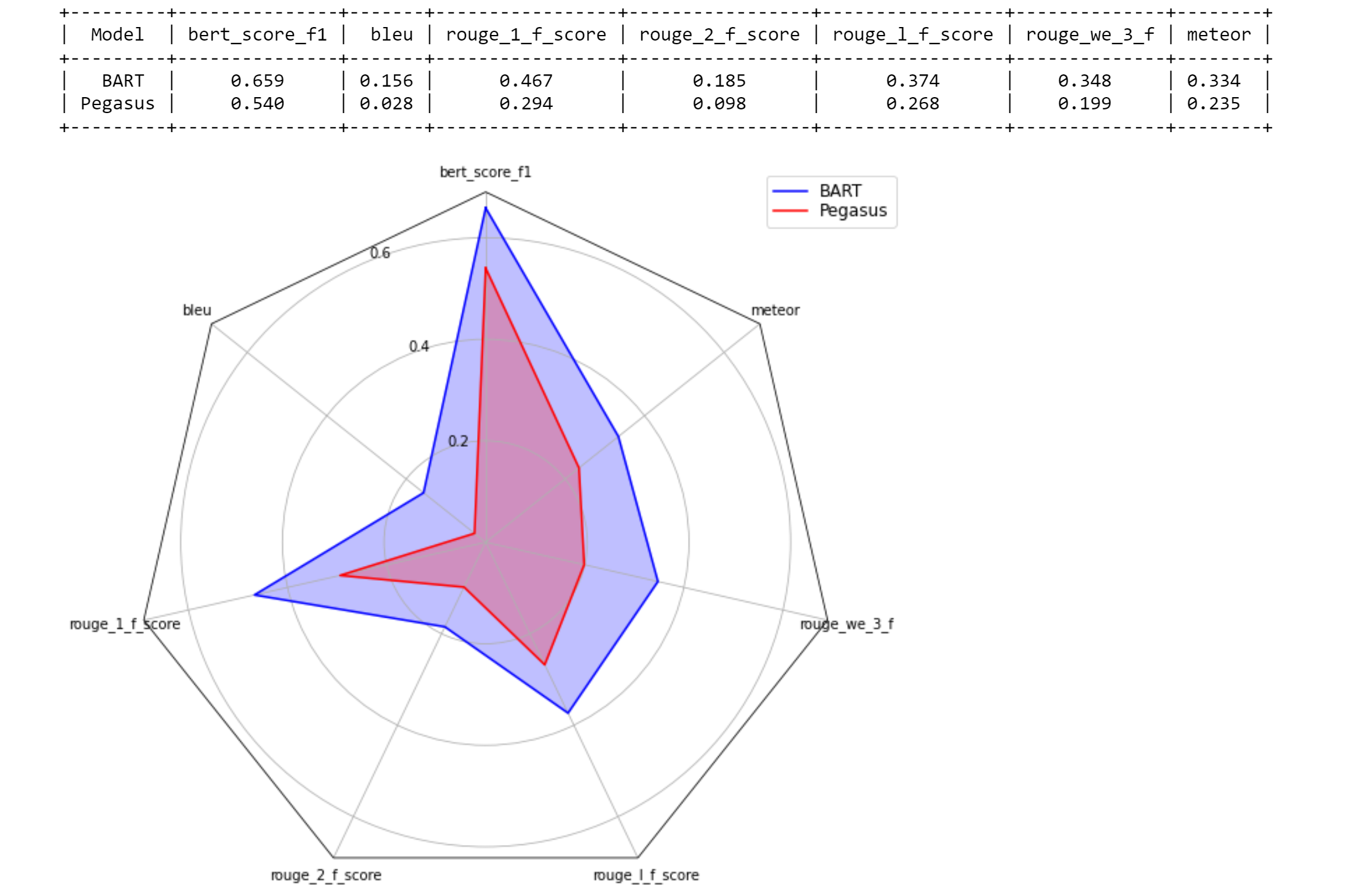
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )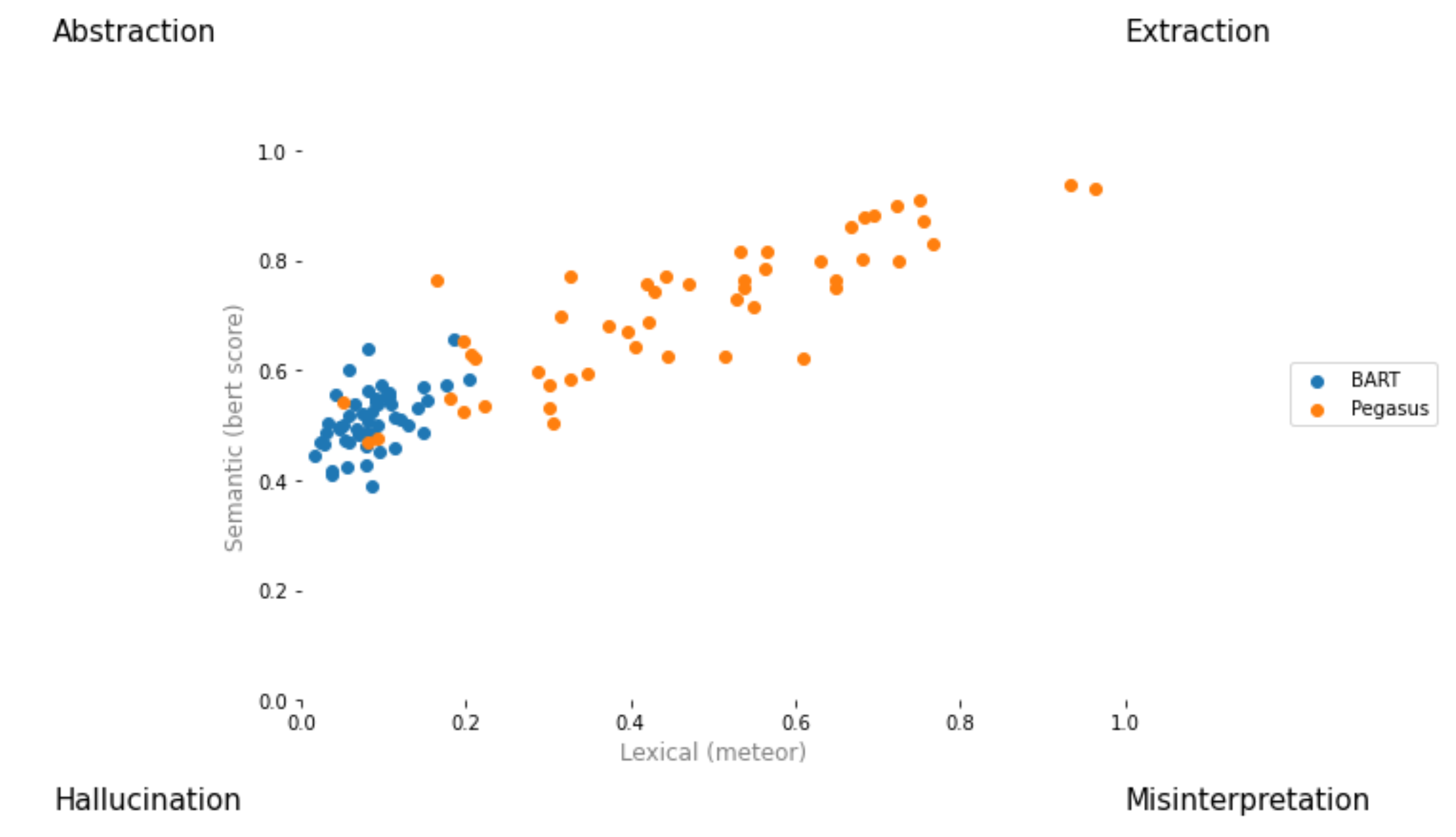
풀 요청을 작성하고 [ your_gh_username ]/[ your_branch_name ]으로 이름을 지정합니다. 필요한 경우 자신의 지점의 병합 충돌을 메인과 해결하십시오. 메인으로 직접 밀지 마십시오.
아직 그렇지 않은 경우 black 및 flake8 설치하십시오.
pip install black
pip install flake8 커밋을 추진하거나 분기를 병합하기 전에 프로젝트 루트에서 다음 명령을 실행하십시오. black 파일에 쓸 것이며 푸시하기 전에 black 으로 변경하고 커밋해야합니다.
black .
flake8 .또는 구체적인 파일을 보려면 :
black path/to/specific/file.py
flake8 path/to/specific/file.py black 파일을 재구성하지 않으며 flake8 이 오류를 인쇄하지 않도록하십시오. black 또는 flake8 에 의해 시행 된 선호도 또는 관행을 무시하거나 무시하려면 경고 또는 오류 로그를 생성하는 모든 코드 라인에 대해 PR에 의견을 남겨주십시오. setup.cfg 와 같은 구성 파일을 직접 편집하지 마십시오.
설치에 대한 문서, 파일/라인 무시 및 고급 사용법에 대한 설명서는 black Docs 및 flake8 문서를 참조하십시오. 또한 다음이 유용 할 수 있습니다.
black [file.py] --diff 미리보기로 변경하여 직접 변경하는 대신 diff로 변경됩니다.black [file.py] --check 직접 변경하는 대신 상태 코드로 변경 사항을 미리보기로 확인하십시오.git diff -u | flake8 --diff 작업 지점 변경에서 Flake8 만 실행하는 것 CI 테스트 스위트에는 black --check . 및 flake8 --count . 모든 테스트가 통과하려면 모든 비 시트 및 비 세트 파이썬 파일에서 제로 오류 수준 출력이 필요합니다.
우리의 지속적인 통합 시스템은 GitHub 작업을 통해 제공됩니다. 풀 요청이 생성되거나 업데이트되거나 main 업데이트 될 때마다 리포지토리의 단위 테스트는 해당 풀 요청을 위해 Tangra의 구축 작업으로 실행됩니다. 빌드 작업은 몇 분 안에 전달되거나 실패하며, 조치 하에서 상태와 로그를 빌드합니다. 가장 최근의 Commit in Pull 요청이 병합하기 전에 모든 수표 (즉, 모든 작업의 모든 단계)를 통과하거나 검토를 요청하는지 확인하십시오. 특정 커밋에 대한 빌드를 건너 뛰려면 [skip ci] 커밋 메시지에 추가하십시오. 지점 이름의 서브 스트링 /no-ci/ 가있는 PR은 CI에 포함되지 않습니다.
이 저장소는 Yale University의 Lily Lab에 의해 구축되며 Dragomir Radev 교수가 이끄는 것입니다. 주요 공헌자는 Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf 및 Yusen Zhang (Penn State)입니다.
작업에서 여름을 사용하는 경우 다음을 고려하십시오.
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
의견과 질문은 문제를여십시오.


