SummerTime
v1.2.1

Uma biblioteca para ajudar os usuários a escolher ferramentas de resumo apropriadas com base em suas tarefas ou necessidades específicas. Inclui modelos, métricas de avaliação e conjuntos de dados.
A arquitetura da biblioteca é a seguinte:
NOTA : O verão está em desenvolvimento ativo, quaisquer comentários úteis são altamente encorajados, abra um problema ou entre em contato com qualquer um dos membros da equipe.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pipComo alternativa, para aproveitar os recursos mais recentes, você pode instalar a partir da fonte:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (ao usar a avaliação) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Modelo de importações, inicializa o modelo padrão e resume os documentos de amostra.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Além disso, execute nosso notebook Colab para uma demonstração mais prática e mais exemplos.
O Summertime suporta diferentes modelos (por exemplo, TexTrank, Bart, Longformer), bem como invólucros de modelos para tarefas de resumo mais complexas (por exemplo, Model de junta para resumo multi-doutorado, recuperação de BM25 para resumo baseado em consulta). Vários modelos multilíngues também são suportados (MT5 e MBART).
| Modelos | Doc | Multi-Doc | Baseado em diálogo | Baseada em consulta | Multilíngue |
|---|---|---|---|---|---|
| Bartmodel | ✔️ | ||||
| BM25SummModel | ✔️ | ||||
| HMNetModel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| FORMURA LONGO | ✔️ | ||||
| MbartModel | ✔️ | 50 idiomas (lista completa aqui) | |||
| MT5Model | ✔️ | 101 Idiomas (lista completa aqui) | |||
| TraduçãoPipelineModel | ✔️ | ~ 70 idiomas | |||
| MultidocJointModel | ✔️ | ||||
| Multidocseparatemodel | ✔️ | ||||
| Pegasusmodel | ✔️ | ||||
| TexTrankmodel | ✔️ | ||||
| Tfidfsummmodel | ✔️ |
Para ver todos os modelos suportados, execute:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Os usuários podem acessar facilmente a documentação para ajudar na seleção do modelo
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Para usar um modelo para resumo, basta executar:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Todos os modelos podem ser inicializados com as seguintes opções opcionais:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Todos os modelos implementarão os seguintes métodos:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :SummerTime supports different summarization datasets across different domains (eg, CNNDM dataset - news article corpus, Samsum - dialogue corpus, QM-Sum - query-based dialogue corpus, MultiNews - multi-document corpus, ML-sum - multi-lingual corpus, PubMedQa - Medical domain, Arxiv - Science papers domain, among others.
| Conjunto de dados | Domínio | # Exemplos | Src. comprimento | Tgt. comprimento | Consulta | Multi-Doc | Diálogo | Multilíngue |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Artigos científicos | 215K | 4.9K | 220 | ||||
| CNN/DM (3.0.0) | Notícias | 300k | 781 | 56 | ||||
| Mlsumdataset | Notícias multilíngues | 1,5m+ | 632 | 34 | ✔️ | Alemão, espanhol, francês, russo, turco | ||
| Multi-News | Notícias | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | Domínio aberto | 16K | 94 | 20 | ✔️ | |||
| PubMedqa | Médico | 272k | 244 | 32 | ✔️ | |||
| Qmsum | Reuniões | 1k | 9.0K | 69.6 | ✔️ | ✔️ | ||
| Scisummnet | Artigos científicos | 1k | 4.7K | 150 | ||||
| Somscreen | Programas de TV | 26.9K | 6.6k | 337.4 | ✔️ | |||
| Xsum | Notícias | 226k | 431 | 23.3 | ||||
| Xlsum | Notícias | 1,35m | ??? | ??? | 45 idiomas (consulte a documentação) | |||
| Massivesummumm | Notícias | 12m+ | ??? | ??? | 78 Idiomas (consulte a seção de resumo multilíngue do ReadMe para obter detalhes) |
Para ver todos os conjuntos de dados suportados, execute:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Todos os conjuntos de dados são implementações da classe SummDataset . Suas divisões de dados podem ser acessadas da seguinte forma:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Para ver os detalhes dos conjuntos de dados, execute:
dataset = dataset . CnndmDataset ()
dataset . show_description () Os dados em todos os conjuntos de dados estão contidos em um objeto de classe SummInstance , que possui as seguintes propriedades:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyOs dados são carregados usando um gerador para economizar no espaço e no tempo
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Você pode usar dados personalizados usando a classe CustomDataset que carrega os dados na classe DataSet de verão
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) O método summarize() de modelos multilíngues verifica automaticamente a linguagem de documentos de entrada.
Modelos multilíngues de DOC único podem ser inicializados e usados da mesma maneira que os modelos monolíngues. Eles retornam um erro se um idioma não suportado pelo modelo for entrada.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )The following languages are currently supported in our implementation of the MassiveSumm dataset: Afrikaans, Amharic, Arabic, Assamese, Aymara, Azerbaijani, Bambara, Bengali, Tibetan, Bosnian, Bulgarian, Catalan, Czech, Welsh, Danish, German, Greek, English, Esperanto, Persian, Filipino, French, Fulah, Irish, Gujarati, Haitian, Hausa, Hebrew, Hindi, Croatian, Hungarian, Armenian,Igbo, Indonesian, Icelandic, Italian, Japanese, Kannada, Georgian, Khmer, Kinyarwanda, Kyrgyz, Korean, Kurdish, Lao, Latvian, Lingala, Lithuanian, Malayalam, Marathi, Macedonian, Malagasy, Mongolian, Burmese, South Ndebele, Nepali, Dutch, Oriya, Oromo, Punjabi, Polish, Portuguese, Dari, Pashto, Romanian, Rundi, Russian, Sinhala, Slovak, Slovenian, Shona, Somali, Spanish, Albanian, Serbian, Swahili, Swedish, Tamil, Telugu, Tetum, Tajique, tailandês, tigrinya, turco, ucraniano, urdu, uzbeque, vietnamita, xhosa, ioruba, yue chinês, chinês, bislama e gaélico.
O verão suporta diferentes métricas de avaliação, incluindo: Bertscore, Bleu, Meteor, Rouge, Rougewe
Para imprimir todas as métricas suportadas:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Todas as métricas de avaliação podem ser inicializadas com os seguintes argumentos opcionais:
def __init__ ( self , metric_name ):Todos os objetos métricos de avaliação implementam os seguintes métodos:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Obtenha dados de resumo da amostra
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Avalie os dados sobre diferentes métricas
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Dado um conjunto de dados de verão, você pode usar os pipelines.assemble_model_pipeline para recuperar uma lista de modelos de verão inicializados que são compatíveis com o conjunto de dados fornecido.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
Dado um conjunto de dados de verão, você pode usar os pipelines.ASSEMBLE_MODEL_PIPELINE para recuperar uma lista de modelos de verão inicializados que são compatíveis com o conjunto de dados fornecido.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )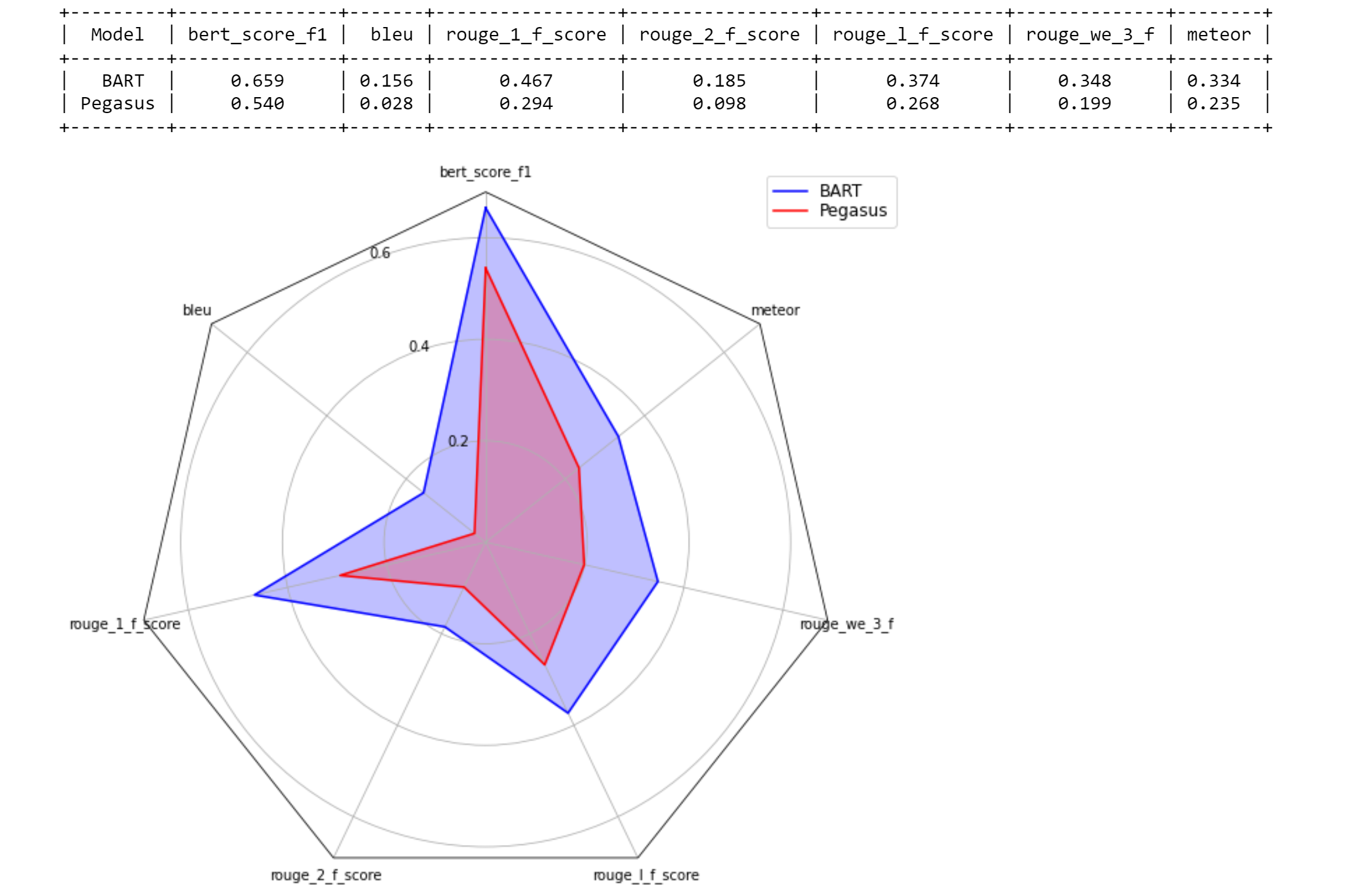
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )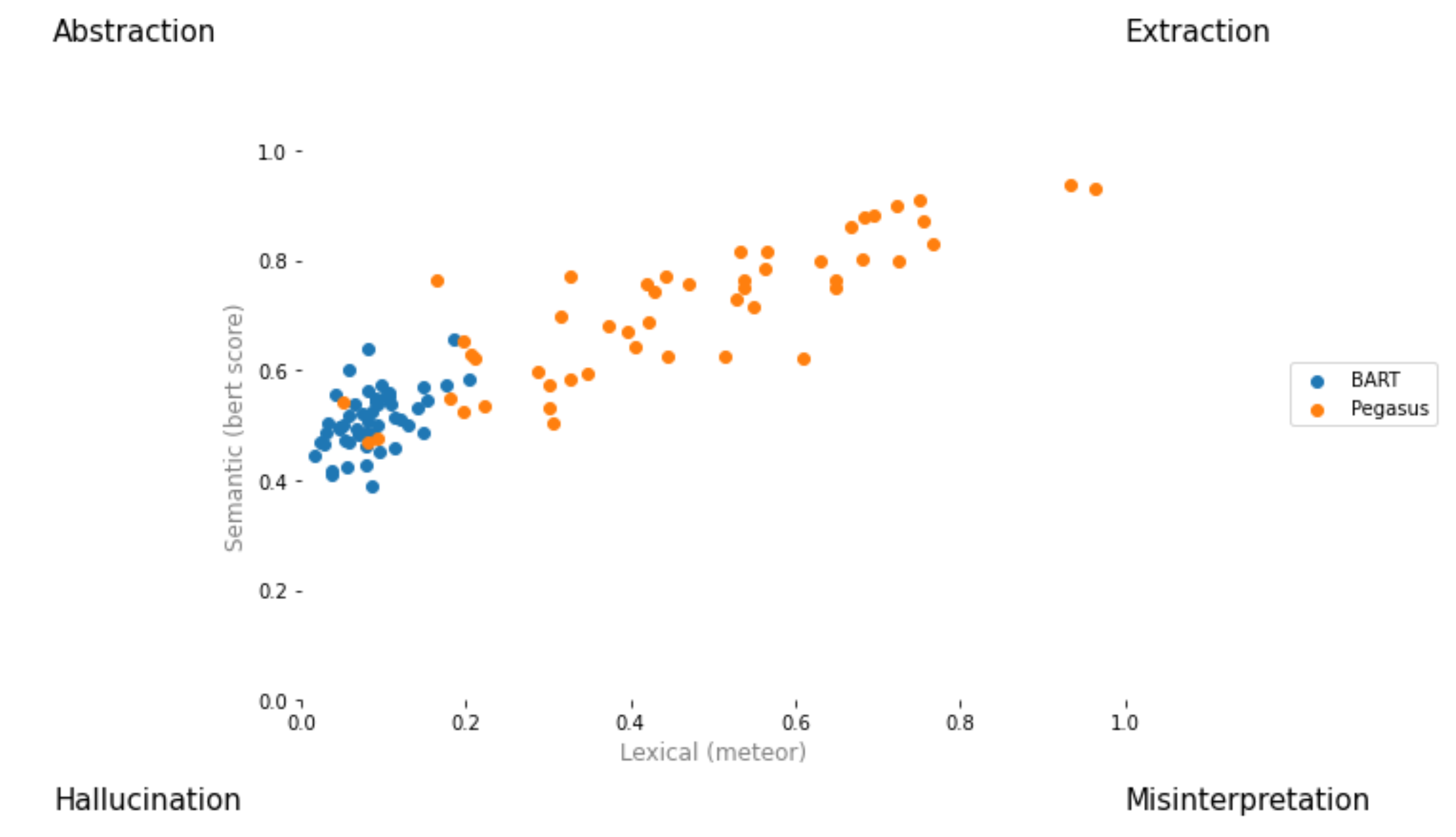
Crie uma solicitação de tração e nomeie -a [ your_gh_username ]/[ your_branch_name ]. Se necessário, resolva a fusão de sua própria filial, conflita com Main. Não empurre diretamente para o principal.
Se você ainda não o fez, instale black e flake8 :
pip install black
pip install flake8 Antes de empurrar cometidos ou mesclar ramificações, execute os seguintes comandos da raiz do projeto. Observe que black escreverá em arquivos e que você deve adicionar e cometer alterações feitas por black antes de pressionar:
black .
flake8 .Ou se você quiser fins de imersão em arquivos específicos:
black path/to/specific/file.py
flake8 path/to/specific/file.py Certifique -se de que black não reformate nenhum arquivo e que flake8 não imprime nenhum erro. Se você deseja substituir ou ignorar qualquer uma das preferências ou práticas aplicadas pelo black ou flake8 , deixe um comentário em seu PR para qualquer linha de código que gerem logs de aviso ou erro. Não edite diretamente arquivos de configuração, como setup.cfg .
Consulte os documentos black e os documentos flake8 para documentação sobre a instalação, ignorar arquivos/linhas e uso avançado. Além disso, o seguinte pode ser útil:
black [file.py] --diff para visualizar as alterações como diferenças em vez de fazer alterações diretamenteblack [file.py] --check para visualizar as alterações com códigos de status em vez de fazer alterações diretamentegit diff -u | flake8 --diff para executar apenas Flake8 nas mudanças de ramo de trabalho Observe que nossa suíte de teste de CI incluirá invocar black --check . e flake8 --count . Em todos os arquivos Python não-uniformes e não definidos, e a saída zero no nível de erro é necessária para que todos os testes sejam aprovados.
Nosso sistema de integração contínuo é fornecido através de ações do GitHub. Quando qualquer solicitação de tração for criada ou atualizada ou sempre que main for atualizado, os testes de unidade do repositório serão executados como trabalhos de construção no tangra para essa solicitação de tração. Os trabalhos de construção passarão ou falharão dentro de alguns minutos e os status e os logs da construção são visíveis em ações. Certifique -se de que a confirmação mais recente em solicitações de tração passe todas as verificações (ou seja, todas as etapas de todos os trabalhos são concluídos) antes de mesclar ou solicitar uma revisão. Para pular uma construção sobre qualquer commit em particular, anexe [skip ci] à mensagem de confirmação. Observe que o PRS com a substring /no-ci/ em qualquer lugar do nome da filial não será incluído no IC.
Este repositório é construído pelo Lily Lab da Universidade de Yale, liderado pelo Prof. Dragomir Radev. Os principais colaboradores são Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf e Yusen Zhang (Penn State).
Se você usar o verão em seu trabalho, considere citar:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Para comentários e perguntas, abra um problema.


