SummerTime
v1.2.1

ห้องสมุดเพื่อช่วยให้ผู้ใช้เลือกเครื่องมือการสรุปที่เหมาะสมตามงานหรือความต้องการเฉพาะของพวกเขา รวมถึงแบบจำลองตัวชี้วัดการประเมินผลและชุดข้อมูล
สถาปัตยกรรมห้องสมุดมีดังนี้:
หมายเหตุ : ฤดูร้อนกำลังอยู่ในระหว่างการพัฒนาความคิดเห็นที่เป็นประโยชน์ใด ๆ ได้รับการสนับสนุนอย่างสูงโปรดเปิดปัญหาหรือติดต่อกับสมาชิกในทีมใด ๆ
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip ท้องถิ่นอีกทางเลือกหนึ่งคือการเพลิดเพลินไปกับคุณสมบัติล่าสุดคุณสามารถติดตั้งได้จากแหล่งที่มา:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (เมื่อใช้การประเมินผล) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/นำเข้าโมเดลเริ่มต้นโมเดลเริ่มต้นและสรุปเอกสารตัวอย่าง
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]นอกจากนี้โปรดเรียกใช้สมุดบันทึก Colab ของเราเพื่อการสาธิตที่มากขึ้นและตัวอย่างเพิ่มเติม
ฤดูร้อนรองรับโมเดลที่แตกต่างกัน (เช่น Textrank, BART, Longformer) เช่นเดียวกับเครื่องห่อแบบจำลองสำหรับงานสรุปที่ซับซ้อนมากขึ้น (เช่น JointModel สำหรับการสรุปหลาย DOC, การดึง BM25 สำหรับการสรุปแบบสอบถาม) นอกจากนี้ยังรองรับหลายภาษาหลายภาษา (MT5 และ MBART)
| แบบจำลอง | เดี่ยว | หลายตัว | อิงตามบทสนทนา | ตามแบบสอบถาม | พูดได้หลายภาษา |
|---|---|---|---|---|---|
| Bartmodel | |||||
| BM25SUMMMODEL | |||||
| Hmnetmodel | |||||
| lexrankmodel | |||||
| Longformermodel | |||||
| mbartmodel | 50 ภาษา (รายการทั้งหมดที่นี่) | ||||
| MT5MODEL | 101 ภาษา (รายการทั้งหมดที่นี่) | ||||
| TranslationPipelInemodel | ~ 70 ภาษา | ||||
| MultidocjointModel | |||||
| multidocseparateModel | |||||
| Pegasusmodel | |||||
| Textrankmodel | |||||
| tfidfsummmodel |
หากต้องการดูทุกรุ่นที่รองรับ Run:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()ผู้ใช้สามารถเข้าถึงเอกสารได้อย่างง่ายดายเพื่อช่วยในการเลือกรุ่น
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()หากต้องการใช้แบบจำลองสำหรับการสรุปเพียงแค่เรียกใช้:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )ทุกรุ่นสามารถเริ่มต้นด้วยตัวเลือกทางเลือกต่อไปนี้:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):ทุกรุ่นจะใช้วิธีการต่อไปนี้:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :ฤดูร้อนรองรับชุดข้อมูลการสรุปที่แตกต่างกันในโดเมนที่แตกต่างกัน (เช่นชุดข้อมูล CNNDM - บทความข่าวคอร์ปัส, Samsum - บทสนทนาคลังข้อมูล, QM -Sum - บทสนทนาที่ใช้แบบสอบถามแบบสอบถาม, MultiNews - Multi -Document Corpus, ML -Sum -multi
| ชุดข้อมูล | โดเมน | # ตัวอย่าง | src. ความยาว | tgt. ความยาว | สอบถาม | หลายตัว | บทสนทนา | หลายภาษา |
|---|---|---|---|---|---|---|---|---|
| arxiv | บทความทางวิทยาศาสตร์ | 215K | 4.9K | 220 | ||||
| CNN/DM (3.0.0) | ข่าว | 300K | 781 | 56 | ||||
| mlsumdataset | ข่าวหลายภาษา | 1.5m+ | 632 | 34 | เยอรมัน, สเปน, ฝรั่งเศส, รัสเซีย, ตุรกี | |||
| มัลตินิวส์ | ข่าว | 56K | 2.1k | 263.8 | ||||
| samsum | โดเมนเปิดโล่ง | 16k | 94 | 20 | ||||
| PubMedqa | ทางการแพทย์ | 272K | 244 | 32 | ||||
| QMSUM | การประชุม | 1k | 9.0k | 69.6 | ||||
| scisummnet | บทความทางวิทยาศาสตร์ | 1k | 4.7K | 150 | ||||
| หน้าจอ | รายการทีวี | 26.9K | 6.6k | 337.4 | ||||
| Xsum | ข่าว | 226K | 431 | 23.3 | ||||
| XLSUM | ข่าว | 1.35m | - | - | 45 ภาษา (ดูเอกสาร) | |||
| massivesumm | ข่าว | 12m+ | - | - | 78 ภาษา (ดูส่วนการสรุปหลายภาษาของ ReadMe สำหรับรายละเอียด) |
หากต้องการดูชุดข้อมูลที่รองรับทั้งหมดเรียกใช้:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc ชุดข้อมูลทั้งหมดคือการใช้งานของคลาส SummDataset การแยกข้อมูลของพวกเขาสามารถเข้าถึงได้ดังนี้:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set หากต้องการดูรายละเอียดของชุดข้อมูล Run:
dataset = dataset . CnndmDataset ()
dataset . show_description () ข้อมูลในชุดข้อมูลทั้งหมดมีอยู่ในวัตถุคลาส SummInstance ซึ่งมีคุณสมบัติดังต่อไปนี้:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyข้อมูลถูกโหลดโดยใช้เครื่องกำเนิดไฟฟ้าเพื่อประหยัดพื้นที่และเวลา
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) คุณสามารถใช้ข้อมูลที่กำหนดเองโดยใช้คลาส CustomDataset ที่โหลดข้อมูลในคลาส DataSet Summertime
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) วิธี summarize() ของโมเดลหลายภาษาตรวจสอบภาษาเอกสารที่ป้อนโดยอัตโนมัติ
แบบจำลองหลายภาษาเดี่ยวสามารถเริ่มต้นและใช้ในลักษณะเดียวกับโมเดล monolingual พวกเขาส่งคืนข้อผิดพลาดหากภาษาที่ไม่รองรับโดยโมเดลคืออินพุต
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )ปัจจุบันภาษาต่อไปนี้ได้รับการสนับสนุนในการใช้งานชุดข้อมูล Massivesumm ของเรา: Afrikaans, Amharic, Arabic, Assamese, Aymara, Azerbaijani, Bambara, Bengali, Tibetan, Bosnian, Bulgarian, Catalan, Czech รัฐคุชราต, เฮติ, Hausa, ฮีบรู, ภาษาฮินดี, โครเอเชีย, ฮังการี, อาร์เมเนีย, อิกโบ, อินโดนีเซีย, ไอซ์แลนด์, อิตาลี, ญี่ปุ่น, กันนาดา, จอร์เจีย, คินทาเลีย, คีนา มาลากัส, มองโกเลีย, พม่า, เซาท์เนเดเบเล่, เนปาล, ดัตช์, โอริยะ, โอโรโม, ปัญจาบ, โปแลนด์, โปรตุเกส, ดารี, Pashto, โรมาเนีย, Rundi, รัสเซีย, Sinhala, Slovak, Slovenian Tetum, Tajik, Thai, Tigrinya, Turkish, Ukrainian, Urdu, Uzbek, Vietnamese, Xhosa, Yoruba, Yue Chinese, Chinese, Bislama และ Gaelic
ฤดูร้อนสนับสนุนตัวชี้วัดการประเมินที่แตกต่างกันรวมถึง: Bertscore, Bleu, Meteor, Rouge, Rougewe
ในการพิมพ์ตัวชี้วัดที่รองรับทั้งหมด:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()ตัวชี้วัดการประเมินทั้งหมดสามารถเริ่มต้นด้วยอาร์กิวเมนต์เสริมต่อไปนี้:
def __init__ ( self , metric_name ):วัตถุตัวชี้วัดการประเมินทั้งหมดใช้วิธีการต่อไปนี้:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):รับข้อมูลสรุปตัวอย่าง
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]ประเมินข้อมูลเกี่ยวกับตัวชี้วัดที่แตกต่างกัน
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) ด้วยชุดข้อมูลฤดูร้อนคุณสามารถใช้ฟังก์ชัน pipelines.assemble_model_pipeline เพื่อดึงรายการของรุ่นฤดูร้อนเริ่มต้นที่เข้ากันได้กับชุดข้อมูลที่ให้ไว้
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]-
ด้วยชุดข้อมูลฤดูร้อนคุณสามารถใช้ฟังก์ชัน pipelines.assemble_model_pipeline เพื่อดึงรายการของรุ่นฤดูร้อนเริ่มต้นที่เข้ากันได้กับชุดข้อมูลที่ให้ไว้
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )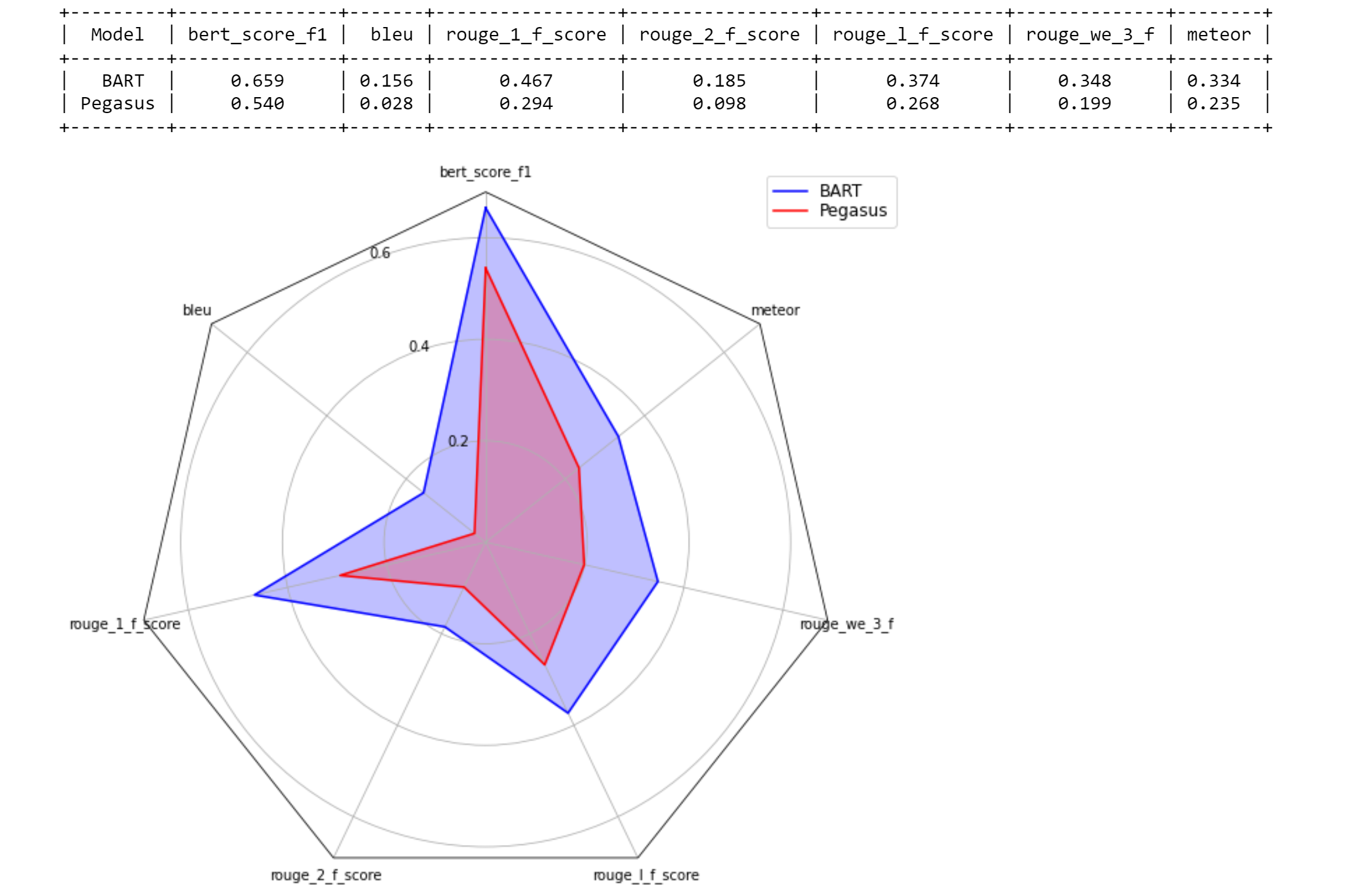
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )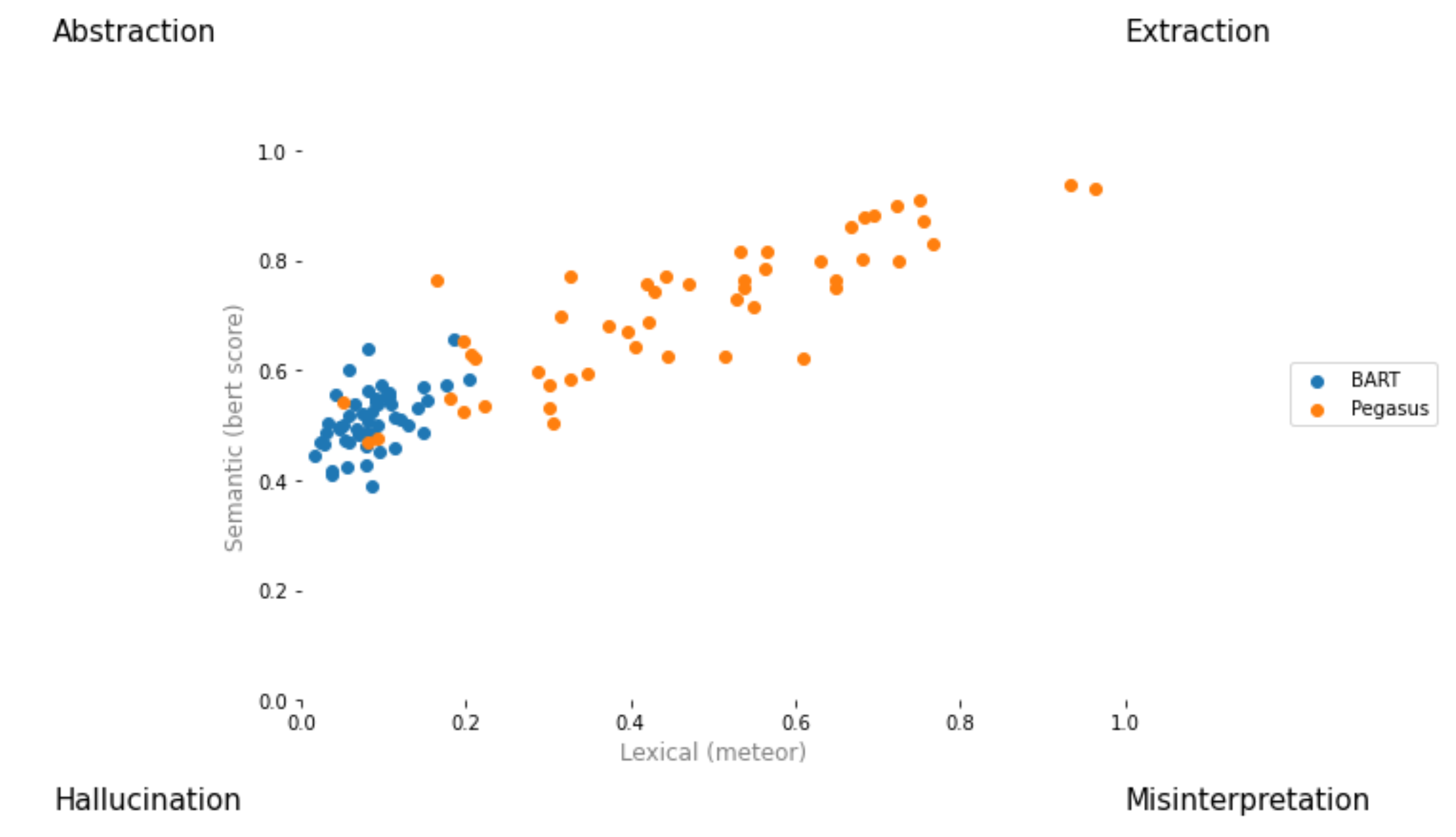
สร้างคำขอดึงและตั้งชื่อ [ your_gh_username ]/[ your_branch_name ] หากจำเป็นให้แก้ไขความขัดแย้งการผสานของสาขาของคุณเองกับหลัก อย่าผลักไปที่หลักโดยตรง
หากคุณยังไม่ได้ติดตั้ง black และ flake8 :
pip install black
pip install flake8 ก่อนที่จะผลักดันหรือรวมสาขาให้เรียกใช้คำสั่งต่อไปนี้จากรูทโครงการ โปรดทราบว่า black จะเขียนไปยังไฟล์และคุณควรเพิ่มและกระทำการเปลี่ยนแปลงที่ทำโดย black ก่อนที่จะผลัก:
black .
flake8 .หรือถ้าคุณต้องการผ้าสำลีเฉพาะไฟล์:
black path/to/specific/file.py
flake8 path/to/specific/file.py ตรวจสอบให้แน่ใจว่า black ไม่ได้ฟอร์แมตไฟล์ใด ๆ และ flake8 นั้นไม่ได้พิมพ์ข้อผิดพลาดใด ๆ หากคุณต้องการแทนที่หรือเพิกเฉยต่อการตั้งค่าหรือการปฏิบัติใด ๆ ที่บังคับใช้โดย black หรือ flake8 โปรดแสดงความคิดเห็นใน PR ของคุณสำหรับบรรทัดใด ๆ ของรหัสที่สร้างคำเตือนหรือบันทึกข้อผิดพลาด อย่าแก้ไขไฟล์กำหนดค่าโดยตรงเช่น setup.cfg
ดูเอกสาร black Docs และ flake8 สำหรับเอกสารเกี่ยวกับการติดตั้งโดยไม่สนใจไฟล์/บรรทัดและการใช้งานขั้นสูง นอกจากนี้อาจมีประโยชน์ต่อไปนี้:
black [file.py] --diff เพื่อดูตัวอย่างการเปลี่ยนแปลงเป็น diffs แทนที่จะทำการเปลี่ยนแปลงโดยตรงblack [file.py] --check ตรวจสอบการเปลี่ยนแปลงการเปลี่ยนแปลงด้วยรหัสสถานะแทนการเปลี่ยนแปลงโดยตรงgit diff -u | flake8 --diff เพื่อเรียกใช้ Flake8 ในการเปลี่ยนแปลงสาขาการทำงาน โปรดทราบว่าชุดทดสอบ CI ของเราจะรวมถึงการเรียกใช้ black --check . และ flake8 --count . ในไฟล์ Python ที่ไม่ได้ตั้งค่าและไม่ใช่การตั้งค่าทั้งหมดและจำเป็นต้องมีเอาต์พุตระดับข้อผิดพลาดเป็นศูนย์สำหรับการทดสอบทั้งหมดที่จะผ่าน
ระบบการรวมอย่างต่อเนื่องของเรานั้นมีให้ผ่านการกระทำของ GitHub เมื่อคำขอดึงใด ๆ ถูกสร้างขึ้นหรืออัปเดตหรือเมื่อใดก็ตามที่มีการอัปเดตหลักการทดสอบหน่วยของที่ main จะทำงานเป็นงานสร้างบน Tangra สำหรับคำขอดึงนั้น สร้างงานจะผ่านหรือล้มเหลวภายในไม่กี่นาทีและสร้างสถานะและบันทึกสามารถมองเห็นได้ภายใต้การกระทำ โปรดตรวจสอบให้แน่ใจว่าการร้องขอการดึงข้อมูลล่าสุดผ่านการตรวจสอบทั้งหมด (เช่นทุกขั้นตอนในงานทั้งหมดที่ทำงานให้เสร็จสมบูรณ์) ก่อนที่จะรวมหรือขอการตรวจสอบ หากต้องการข้ามการสร้างในการกระทำใด ๆ โดยเฉพาะต่อผนวก [skip ci] ไปยังข้อความ commit โปรดทราบว่า PRS ที่มี substring /no-ci/ ที่ใดก็ได้ในชื่อสาขาจะไม่รวมอยู่ใน CI
ที่เก็บนี้สร้างขึ้นโดย Lily Lab ที่มหาวิทยาลัยเยลนำโดยศาสตราจารย์ Dragomir Radev ผู้สนับสนุนหลักคือ Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf และ Yusen Zhang (Penn State)
หากคุณใช้ฤดูร้อนในงานของคุณให้พิจารณาอ้าง:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
สำหรับความคิดเห็นและคำถามโปรดเปิดปัญหา


