SummerTime
v1.2.1

Eine Bibliothek, mit der Benutzer basierend auf ihren spezifischen Aufgaben oder Bedürfnissen entsprechende Zusammenfassungstools auswählen können. Enthält Modelle, Bewertungsmetriken und Datensätze.
Die Bibliotheksarchitektur lautet wie folgt:
Hinweis : Die Sommerzeit befindet sich in aktiver Entwicklung. Alle hilfreichen Kommentare werden sehr gefördert. Bitte öffnen Sie ein Problem oder wenden Sie sich an eines der Teammitglieder.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pip -InstallationUm die neuesten Funktionen zu genießen, können Sie alternativ aus der Quelle installieren:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (bei Verwendung der Bewertung) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Importiert das Modell, initialisiert das Standardmodell und fasst Beispieldokumente zusammen.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Führen Sie auch unser Colab-Notizbuch für eine praktischere Demo und weitere Beispiele durch.
Summertime unterstützt verschiedene Modelle (z. B. Textrank, Bart, Longformer) sowie Modellverpackungen für komplexere Zusammenfassung Aufgaben (z. B. JointModel für die Multi-Doc-Summarzation, BM25-Abruf für abfragebasierte Summarisierung). Es werden auch mehrere mehrsprachige Modelle unterstützt (MT5 und MBART).
| Modelle | Single-Doc | Multi-Doc | Dialogbasis | Abfragebasierte | Mehrsprachig |
|---|---|---|---|---|---|
| Bartmodel | ✔️ | ||||
| BM25Summmodel | ✔️ | ||||
| Hmnetmodel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| Langformenmodell | ✔️ | ||||
| Mbartmodel | ✔️ | 50 Sprachen (vollständige Liste hier) | |||
| MT5Model | ✔️ | 101 Sprachen (vollständige Liste hier) | |||
| TranslationPipelinemodel | ✔️ | ~ 70 Sprachen | |||
| MultidocjointModel | ✔️ | ||||
| Multidocsaratemodell | ✔️ | ||||
| Pegasusmodel | ✔️ | ||||
| Textrankmodel | ✔️ | ||||
| Tfidfsummmodel | ✔️ |
Um alle unterstützten Modelle zu sehen, rennen Sie:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Benutzer können problemlos auf Dokumentation zugreifen, um die Modellauswahl zu unterstützen
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Um ein Modell für die Zusammenfassung zu verwenden, führen Sie einfach aus:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Alle Modelle können mit den folgenden optionalen Optionen initialisiert werden:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Alle Modelle implementieren die folgenden Methoden:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :Summertime unterstützt verschiedene Summarisierungsdatensätze über verschiedene Domänen hinweg (EG, CNNDM -Datensatz - News -Artikel Corpus, Samsum - Dialog Corpus, QM -Sum - Abfragebasierter Dialog -Corpus, Multinews - Multi -Dokument -Korpus, ML -Sum - Multi -Ling -Korpus, PubMedqa - Medical Domain, ARXIV - ARXIV - ARXIV - ARXIV - ARXIV -Science -Paper -Domain, unter anderem.
| Datensatz | Domain | # Beispiele | Src. Länge | TGT. Länge | Abfrage | Multi-Doc | Dialog | Mehrsprachig |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Wissenschaftliche Artikel | 215k | 4,9k | 220 | ||||
| CNN/DM (3.0.0) | Nachricht | 300k | 781 | 56 | ||||
| Mlsumdataset | Mehrsprachige Nachrichten | 1,5 m+ | 632 | 34 | ✔️ | Deutsch, Spanisch, Französisch, Russisch, Türkisch | ||
| Multi-News | Nachricht | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | Open-Domäne | 16k | 94 | 20 | ✔️ | |||
| PubMedqa | Medizinisch | 272K | 244 | 32 | ✔️ | |||
| Qmsum | Treffen | 1k | 9.0k | 69.6 | ✔️ | ✔️ | ||
| Skisummnet | Wissenschaftliche Artikel | 1k | 4,7k | 150 | ||||
| Summscreen | Fernsehsendungen | 26,9K | 6,6K | 337.4 | ✔️ | |||
| Xsum | Nachricht | 226K | 431 | 23.3 | ||||
| Xlsum | Nachricht | 1,35 m | ??? | ??? | 45 Sprachen (siehe Dokumentation) | |||
| Massivesumm | Nachricht | 12m+ | ??? | ??? | 78 Sprachen (siehe Abschnitt "Mehrsprachiger Zusammenfassung) von Readme für Einzelheiten)) |
Um alle unterstützten Datensätze zu sehen, rennen Sie:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Alle Datensätze sind Implementierungen der SummDataset -Klasse. Auf ihre Datenspaltungen können wie folgt zugegriffen werden:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Um die Details der Datensätze anzuzeigen, rennen Sie:
dataset = dataset . CnndmDataset ()
dataset . show_description () Die Daten in allen Datensätzen sind in einem SummInstance -Klassenobjekt enthalten, das die folgenden Eigenschaften enthält:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyDie Daten werden mit einem Generator geladen, um Platz und Zeit zu speichern
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Sie können benutzerdefinierte Daten mithilfe der CustomDataset -Klasse verwenden, die die Daten in der Summertime -Datensatzklasse lädt
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) Die Methode summarize() von mehrsprachigen Modellen prüft automatisch auf Eingabedokumentsprachen.
Einzeldoc-mehrsprachige Modelle können auf die gleiche Weise wie einsprachige Modelle initialisiert und verwendet werden. Sie geben einen Fehler zurück, wenn eine vom Modell nicht unterstützte Sprache eingegeben wird.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )The following languages are currently supported in our implementation of the MassiveSumm dataset: Afrikaans, Amharic, Arabic, Assamese, Aymara, Azerbaijani, Bambara, Bengali, Tibetan, Bosnian, Bulgarian, Catalan, Czech, Welsh, Danish, German, Greek, English, Esperanto, Persian, Filipino, French, Fulah, Irish, Gujarati, Haitian, Hausa, Hebrew, Hindi, Croatian, Hungarian, Armenian,Igbo, Indonesian, Icelandic, Italian, Japanese, Kannada, Georgian, Khmer, Kinyarwanda, Kyrgyz, Korean, Kurdish, Lao, Latvian, Lingala, Lithuanian, Malayalam, Marathi, Macedonian, Malagasy, Mongolian, Burmese, South Ndebele, Nepali, Dutch, Oriya, Oromo, Punjabi, Polish, Portuguese, Dari, Pashto, Romanian, Rundi, Russian, Sinhala, Slovak, Slovenian, Shona, Somali, Spanish, Albanian, Serbian, Swahili, Swedish, Tamil, Telugu, Tetum, Tajik, Thai, Tigrinya, Türkisch, Ukrainisch, Urdu, Usbek, Vietnamesisch, Xhosa, Yoruba, Yue Chinese, Chinese, Bislama und Gaelic.
Summertime unterstützt unterschiedliche Bewertungsmetriken, einschließlich: Bertscore, Bleu, Meteor, Rouge, Rougewe
Alle unterstützten Metriken drucken:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Alle Bewertungsmetriken können mit den folgenden optionalen Argumenten initialisiert werden:
def __init__ ( self , metric_name ):Alle Bewertungsmetrikobjekte implementieren die folgenden Methoden:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Holen Sie sich Beispiele zusammenfassende Daten
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Bewerten Sie die Daten zu verschiedenen Metriken
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Bei einem Summertime -Datensatz können Sie die Funktion der pipelines.assemble_model_pipeline verwenden.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]========
Bei einem Summertime -Datensatz können Sie die Funktion der Pipelines verwenden.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )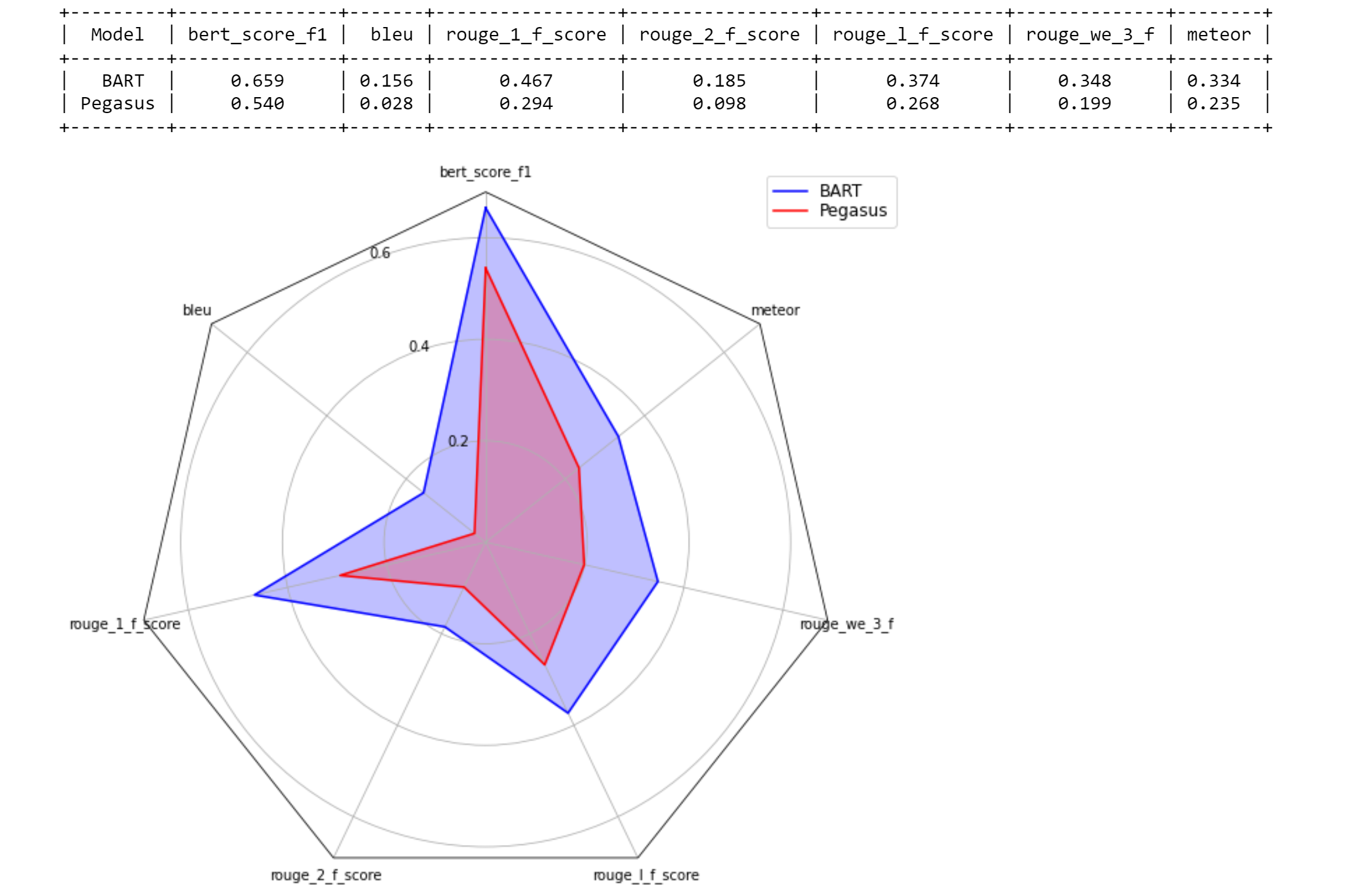
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )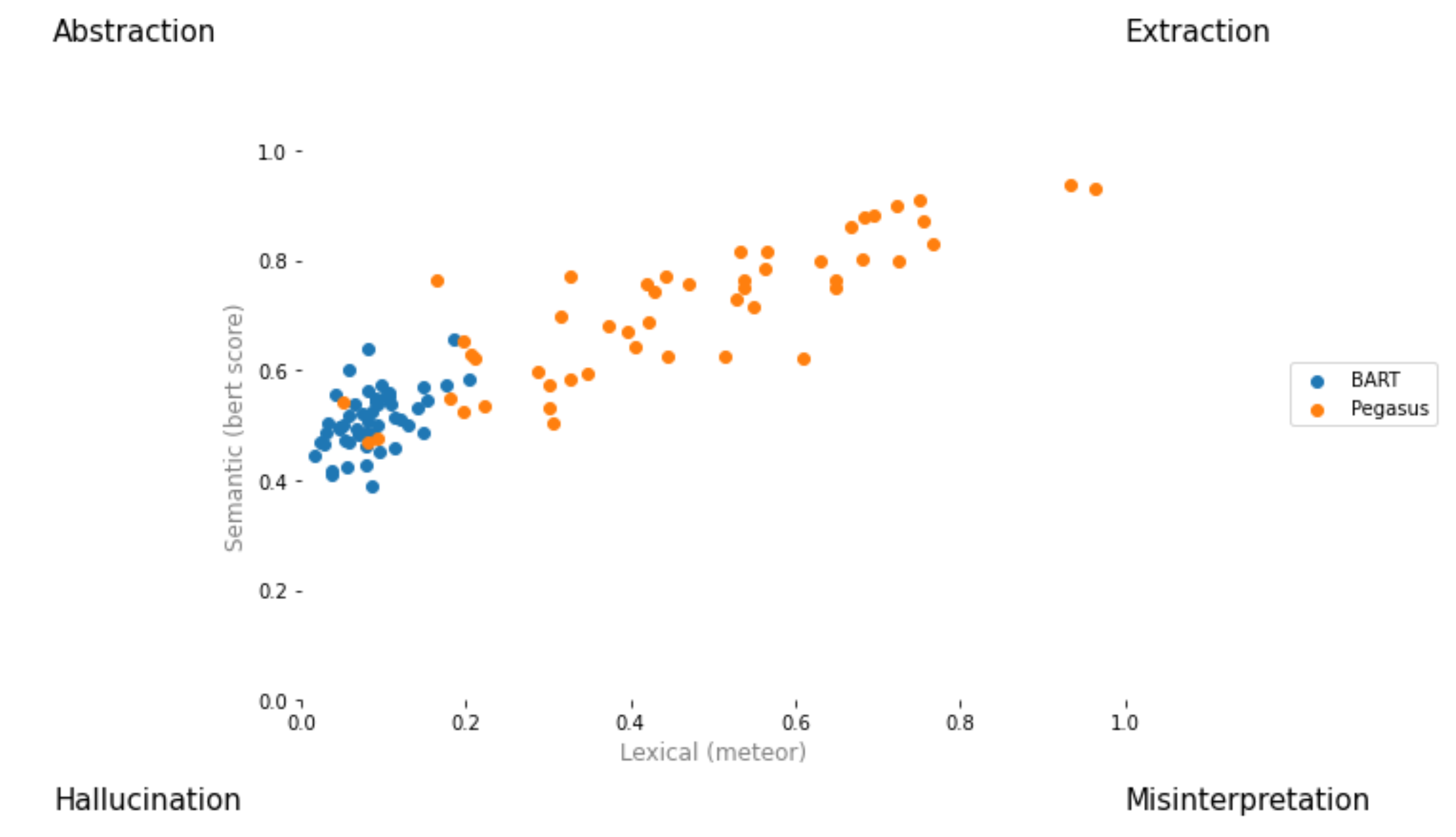
Erstellen Sie eine Pull -Anfrage und nennen Sie es [ your_gh_username ]/[ your_branch_name ]. Lösen Sie bei Bedarf die Zusammenführungskonflikte Ihrer eigenen Niederlassung mit Main. Schieben Sie nicht direkt zum Main.
Wenn Sie es noch nicht getan haben, installieren Sie black und flake8 :
pip install black
pip install flake8 Führen Sie die folgenden Befehle aus der Projektwurzel aus, bevor Sie Commits oder Verschmelzungen verschieben. Beachten Sie, dass black in Dateien schreibt und dass Sie vor dem black Änderungen hinzufügen und festlegen sollten:
black .
flake8 .Oder wenn Sie spezifische Dateien aus FINTEN möchten:
black path/to/specific/file.py
flake8 path/to/specific/file.py Stellen Sie sicher, dass black keine Dateien formatiert und dass flake8 keine Fehler druckt. Wenn Sie eine der von black oder flake8 erzwungenen Vorlieben oder Praktiken überschreiben oder ignorieren möchten, hinterlassen Sie bitte einen Kommentar in Ihrem PR für Codestellen, die Warn- oder Fehlerprotokolle generieren. Bearbeiten Sie Konfigurationsdateien wie setup.cfg nicht direkt.
Die Dokumentation zur Installation, das Ignorieren von Dateien/Zeilen und die erweiterte Verwendung finden Sie in den black Dokumenten und flake8 -Dokumenten. Darüber hinaus kann Folgendes nützlich sein:
black [file.py] --diff zur Vorschau von Änderungen als Diffs, anstatt direkt Änderungen vorzunehmenblack [file.py] --check die Vorschau von Änderungen mit Statuscodes, anstatt direkt Änderungen vorzunehmengit diff -u | flake8 --diff um nur Flake8 für Arbeitszweigänderungen durchzuführen Beachten Sie, dass unsere CI -Testsuite das Aufrufen black --check . und flake8 --count . Bei allen nicht eintesten und nicht einsetzenden Python-Dateien und keine Ausgabe auf Fehlerebene ist erforderlich, damit alle Tests bestanden werden müssen.
Unser kontinuierliches Integrationssystem wird durch GitHub -Aktionen bereitgestellt. Wenn eine Pull -Anfrage erstellt oder aktualisiert wird oder wenn main aktualisiert werden, werden die Unit -Tests des Repository als Build -Jobs auf Tangra für diese Pull -Anfrage durchgeführt. Baujobs vergehen entweder innerhalb weniger Minuten und erstellen Status und Protokolle sind unter Aktionen sichtbar. Bitte stellen Sie sicher, dass das jüngste Commit in Pull -Anfragen alle Schecks (dh alle Schritte in allen Aufträgen, die bis zum Fertigstellung ausgeführt werden) vorgestellt werden, bevor sie zusammengeführt werden, oder eine Überprüfung anfordern. Um einen Aufbau auf einem bestimmten Commit zu überspringen, fügen Sie [skip ci] an die Commit -Nachricht an. Beachten Sie, dass PRs mit dem Substring /no-ci/ Anywhere im Zweignamen nicht in CI enthalten sind.
Dieses Repository wird vom Lily Lab der Yale University unter der Leitung von Prof. Dragomir Radev erstellt. Die wichtigsten Mitwirkenden sind Ansong Ni, Zhangir Aserbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf und Yusen Zhang (Penn State).
Wenn Sie Summertime in Ihrer Arbeit verwenden, sollten Sie sich angeben:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Für Kommentare und Frage öffnen Sie bitte ein Problem.


