SummerTime
v1.2.1

Una biblioteca para ayudar a los usuarios a elegir las herramientas de resumen apropiadas en función de sus tareas o necesidades específicas. Incluye modelos, métricas de evaluación y conjuntos de datos.
La arquitectura de la biblioteca es la siguiente:
Nota : El verano está en desarrollo activo, cualquier comentario útil está muy alentado, abra un problema o comuníquese con cualquiera de los miembros del equipo.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pipAlternativamente, para disfrutar de las características más recientes, puede instalar desde la fuente:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (cuando se usa la evaluación) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Importa el modelo, inicializa el modelo predeterminado y resume los documentos de muestra.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Además, ejecute nuestro cuaderno Colab para obtener una demostración más práctica y más ejemplos.
El verano admite diferentes modelos (p. Ej., Textrank, Bart, Longformer), así como envoltorios de modelos para tareas de resumen más complejas (p. Ej. También se admiten varios modelos multilingües (MT5 y MBART).
| Modelos | De un solo doce | Multidoc | Basado en diálogo | Basado en la consulta | Plurilingüe |
|---|---|---|---|---|---|
| Bartmodelo | ✔️ | ||||
| BM25Summmodel | ✔️ | ||||
| Hmnetmodel | ✔️ | ||||
| Lexrankmodel | ✔️ | ||||
| Longformermodelo | ✔️ | ||||
| Mbartmodelo | ✔️ | 50 idiomas (lista completa aquí) | |||
| Mt5modelo | ✔️ | 101 idiomas (lista completa aquí) | |||
| TraducciónPipelinemodel | ✔️ | ~ 70 idiomas | |||
| Multidocjointmodel | ✔️ | ||||
| Multidocesparatemodelo | ✔️ | ||||
| Pegasusmodelo | ✔️ | ||||
| Textrankmodel | ✔️ | ||||
| Tfidfsummmodel | ✔️ |
Para ver todos los modelos compatibles, ejecute:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Los usuarios pueden acceder fácilmente a la documentación para ayudar con la selección del modelo.
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Para usar un modelo para resumir, simplemente ejecute:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Todos los modelos se pueden inicializar con las siguientes opciones opcionales:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Todos los modelos implementarán los siguientes métodos:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :Summertime admite diferentes conjuntos de datos de resumen en diferentes dominios (por ejemplo, CNNDM DataSet - News Artículo Corpus, Samsum - Dialogue Corpus, QM -SUM - Corpus de diálogo basado en consultas, MultineWS - Multi -Document Corpus, ML -suM - Corpus multi -lingüística, PubMedqa - Domain ARXIV - Domain de Ciencias de Ciencias, entre otros Corpus.
| Conjunto de datos | Dominio | # Ejemplos | Src. longitud | Tgt. longitud | Consulta | Multidoc | Diálogo | Plurilingüe |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Artículos científicos | 215k | 4.9k | 220 | ||||
| CNN/DM (3.0.0) | Noticias | 300k | 781 | 56 | ||||
| Mlsumdataset | Noticias multilingües | 1.5m+ | 632 | 34 | ✔️ | Alemán, español, francés, ruso, turco | ||
| Múltiples | Noticias | 56k | 2.1k | 263.8 | ✔️ | |||
| Samsum | Dominio abierto | 16k | 94 | 20 | ✔️ | |||
| PubMedqa | Médico | 272k | 244 | 32 | ✔️ | |||
| Qmsum | Reuniones | 1k | 9.0k | 69.6 | ✔️ | ✔️ | ||
| Escasez | Artículos científicos | 1k | 4.7k | 150 | ||||
| Veranano | Programas de televisión | 26.9k | 6.6k | 337.4 | ✔️ | |||
| Xsum | Noticias | 226k | 431 | 23.3 | ||||
| Xlsum | Noticias | 1.35m | ???? | ???? | 45 idiomas (ver documentación) | |||
| Massivedumm | Noticias | 12m+ | ???? | ???? | 78 idiomas (ver sección de resumen multilingüe de ReadMe para más detalles) |
Para ver todos los conjuntos de datos compatibles, ejecute:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Todos los conjuntos de datos son implementaciones de la clase SummDataset . Se puede acceder a sus divisiones de datos de la siguiente manera:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Para ver los detalles de los conjuntos de datos, ejecute:
dataset = dataset . CnndmDataset ()
dataset . show_description () Los datos en todos los conjuntos de datos están contenidos en un objeto de clase SummInstance , que tiene las siguientes propiedades:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyLos datos se cargan utilizando un generador para ahorrar en el espacio y el tiempo
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Puede usar datos personalizados utilizando la clase CustomDataset que carga los datos en la clase de conjunto de datos de verano
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) El método summarize() de los modelos multilingües verifica automáticamente el lenguaje de documentos de entrada.
Los modelos multilingües de un solo doctor se pueden inicializar y usar de la misma manera que los modelos monolingües. Devuelven un error si se ingresa un idioma que no es compatible con el modelo.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )The following languages are currently supported in our implementation of the MassiveSumm dataset: Afrikaans, Amharic, Arabic, Assamese, Aymara, Azerbaijani, Bambara, Bengali, Tibetan, Bosnian, Bulgarian, Catalan, Czech, Welsh, Danish, German, Greek, English, Esperanto, Persian, Filipino, French, Fulah, Irish, Gujarati, haitiano, hausa, hebreo, hindi, croata, húngaro, armenio, igbo, indonesio, islandés, italiano, japonés, kannada, georgiano, khmer, kinyarwanda, kyrgyz, kuredia, kurdish, lao, latton, lingala, lithuanian, malayalam, maratón, maratón, Macedón, Macedón, Macedín, Lingala, lingala, lithuanian, Malayalam, maratón, Macedón, Macedón, Macedón, Linteria, Lingala, Lithuanian, Malayalam, Marathonia, Marathonia, Macedona, Macedón, Macedona, Macedona. Malgache, mongolos, birmano, sur ndebele, nepalí, holandés, oriya, oromo, punjabi, polaco, portugués, dari, pashto, rumano, ruso, ruso, cingalés, eslovak, sloveniano, shona, somalí, español, albaniano, serbio, swahili, swedish, tamil, tamil, tam, tamil, tam, Tamil, tam, tam, tamil, Tamil, Tam, Tamil, Tam, Tamil, Tamil, Tam, Tamil, Tam, Tamil, Tam, Tamil, Tamil, Tam, Tam, Tamil, Tam, Tam, Tamil, Tam, Tamil, Tam, Tamil, Tam, Tamily Tayika, tailandés, Tigrinya, turco, ucraniano, urdu, uzbeko, vietnamita, xhosa, yoruba, yue chino, chino, bislama y gaélico.
El verano admite diferentes métricas de evaluación que incluyen: Bertscore, Bleu, Meteor, Rouge, Rougewe
Para imprimir todas las métricas compatibles:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Todas las métricas de evaluación se pueden inicializar con los siguientes argumentos opcionales:
def __init__ ( self , metric_name ):Todos los objetos métricos de evaluación implementan los siguientes métodos:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Obtener datos de resumen de muestra
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Evaluar los datos sobre diferentes métricas
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Dado un conjunto de datos de verano, puede usar la función pipelines.assemble_model_pipeline .
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
Dado un conjunto de datos de verano, puede usar la función de tuberías.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )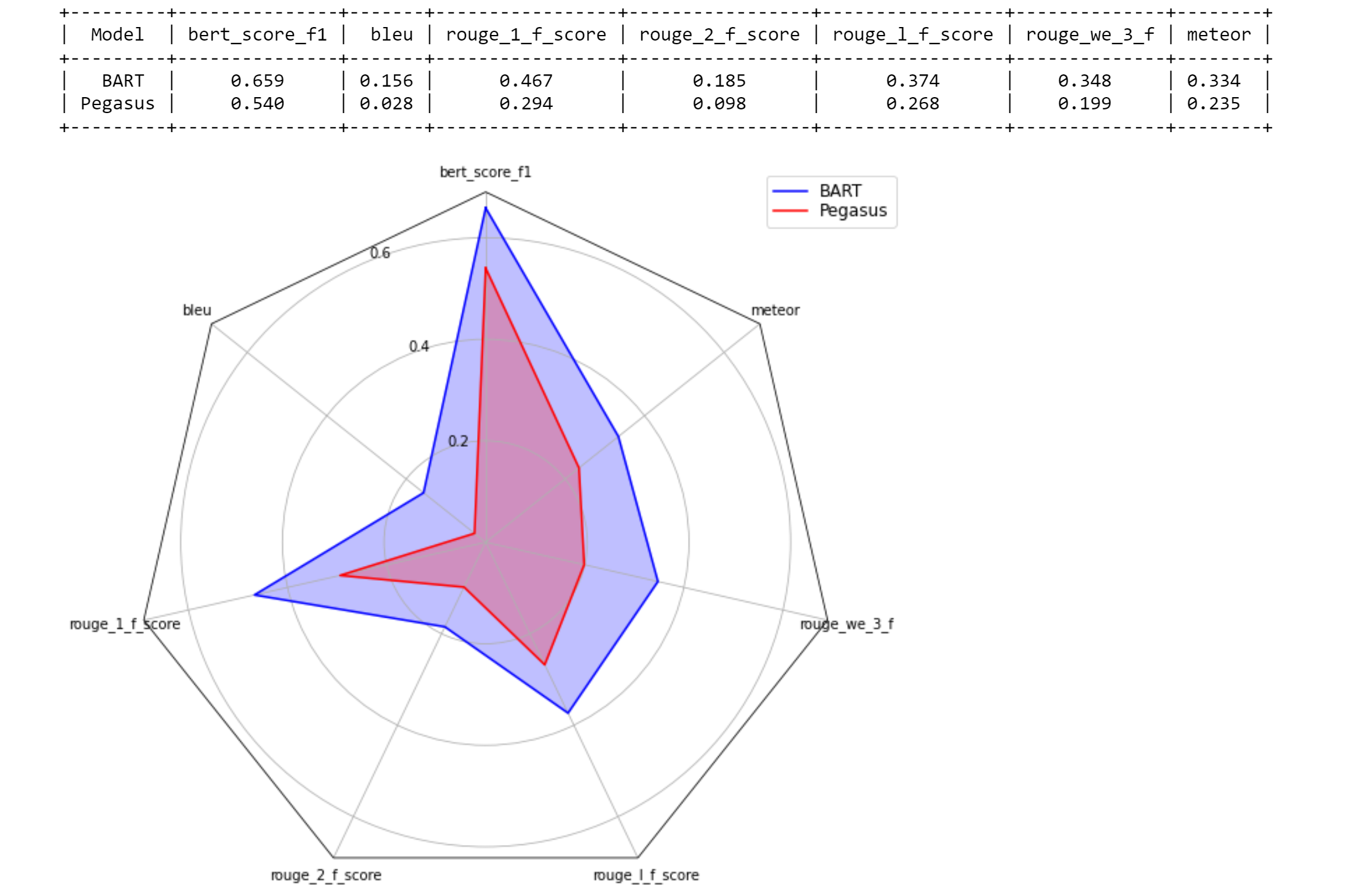
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )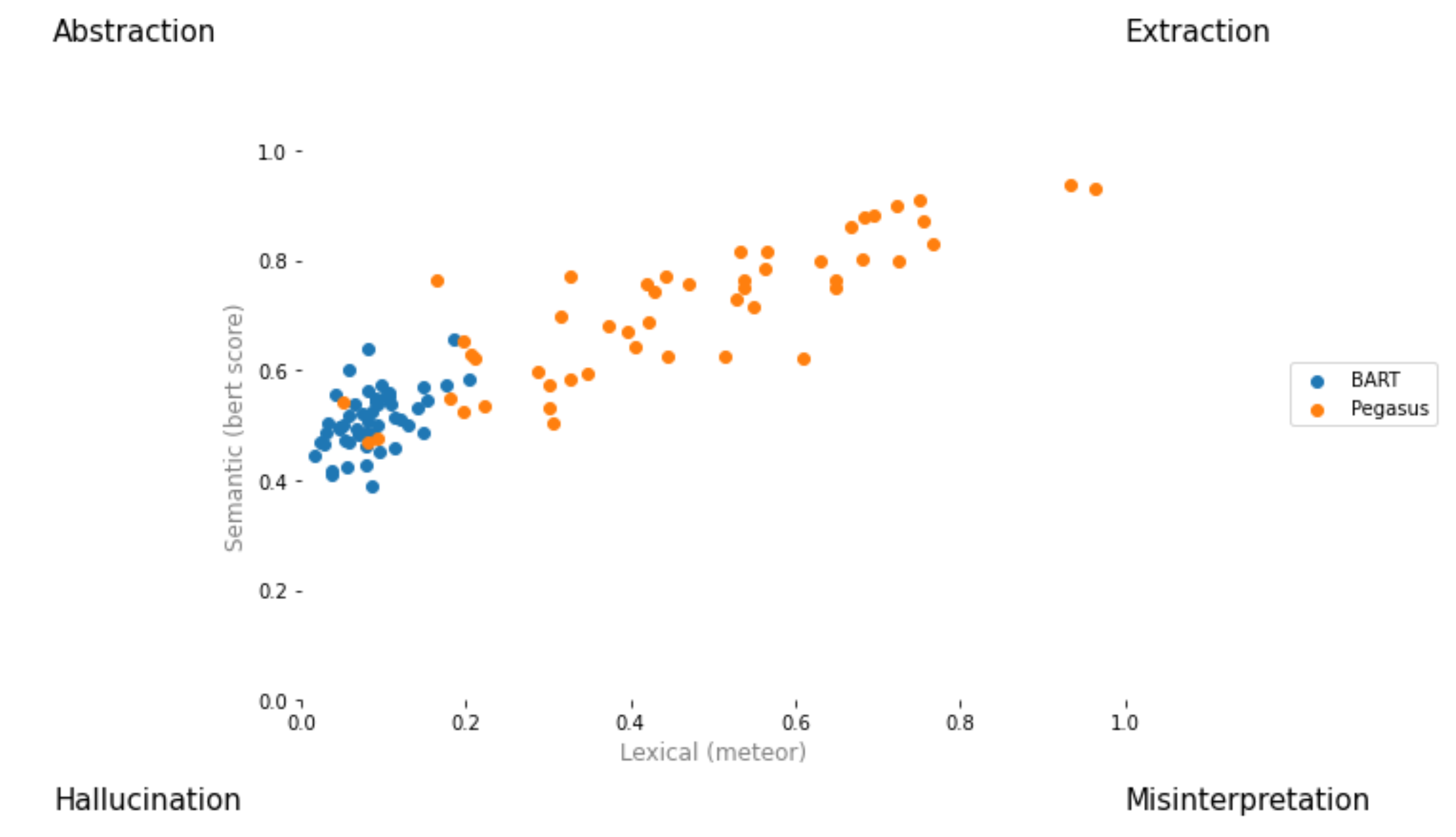
Cree una solicitud de extracción y asígnele unlo [ your_gh_username ]/[ your_branch_name ]. Si es necesario, resuelva los conflictos de fusión de su propia sucursal con Main. No empuje directamente a Main.
Si aún no lo ha hecho, instale black y flake8 :
pip install black
pip install flake8 Antes de presionar compromisos o fusionar ramas, ejecute los siguientes comandos desde la raíz del proyecto. Tenga en cuenta que black escribirá a los archivos, y que debe agregar y confirmar cambios realizados por black antes de presionar:
black .
flake8 .O si desea que se pelee archivos específicos:
black path/to/specific/file.py
flake8 path/to/specific/file.py Asegúrese de que black no reformatea ningún archivo y que flake8 no imprima ningún error. Si desea anular o ignorar cualquiera de las preferencias o prácticas aplicadas por black o flake8 , deje un comentario en su PR para cualquier línea de código que genere registros de advertencia o error. No edite directamente archivos de configuración como setup.cfg .
Consulte los documentos black Docs y flake8 para la documentación sobre la instalación, ignorando archivos/líneas y uso avanzado. Además, lo siguiente puede ser útil:
black [file.py] --diff para obtener la vista previa de cambios como diffs en lugar de hacer cambios directamenteblack [file.py] --check los cambios de vista previa con los códigos de estado en lugar de hacer cambios directamentegit diff -u | flake8 --diff -Diff solo ejecuta Flake8 en los cambios de rama de trabajo Tenga en cuenta que nuestra suite de prueba CI incluirá invocar black --check . y flake8 --count . En todos los archivos Python no unitestos y no SETUP, y se requiere una salida de nivel de error cero para que todas las pruebas pasen.
Nuestro sistema de integración continua se proporciona a través de acciones de GitHub. Cuando se crea o actualiza cualquier solicitud de extracción o cuando se actualice main , las pruebas unitarias del repositorio se ejecutarán como trabajos de compilación en Tangra para esa solicitud de extracción. Los trabajos de compilación pasarán o fallarán en unos minutos, y los estados y registros de construcción son visibles en acciones. Asegúrese de que la compromiso más reciente en las solicitudes de extracción pase todos los cheques (es decir, todos los pasos en todos los trabajos se ejecutan hasta su finalización) antes de fusionar o solicitar una revisión. Para omitir una construcción sobre cualquier confirmación en particular, agregue [skip ci] al mensaje de confirmación. Tenga en cuenta que los PR con la subcadena /no-ci/ en cualquier parte del nombre de la rama no se incluirán en CI.
Este repositorio está construido por el Lily Lab en la Universidad de Yale, dirigido por el Prof. Dragomir Radev. Los principales contribuyentes son Ansong Ni, Zhangir Azerbayev, Troy Feng, Murori Mutuma, Hailey Schoelkopf y Yusen Zhang (Penn State).
Si usa verano en su trabajo, considere citar:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Para comentarios y preguntas, abra un problema.


