SummerTime
v1.2.1

Библиотека, помогающая пользователям выбирать соответствующие инструменты суммирования на основе их конкретных задач или потребностей. Включает модели, показатели оценки и наборы данных.
Библиотечная архитектура заключается в следующем:
Примечание : Summertime находится в активной разработке, любые полезные комментарии очень рекомендуются, откройте проблему или обратитесь к любому из членов команды.
# install extra dependencies first
pip install pyrouge@git+https://github.com/bheinzerling/pyrouge.git
pip install en_core_web_sm@https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.0.0/en_core_web_sm-3.0.0-py3-none-any.whl
# install summertime from PyPI
pip install summertime
pipВ качестве альтернативы, чтобы насладиться самыми последними функциями, вы можете установить из источника:
git clone [email protected]:Yale-LILY/SummerTime
pip install -e . ROUGE (при использовании оценки) export ROUGE_HOME=/usr/local/lib/python3.7/dist-packages/summ_eval/ROUGE-1.5.5/Модель импорта, инициализирует модель по умолчанию и суммирует образцы документов.
from summertime import model
sample_model = model . summarizer ()
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
sample_model . summarize ( documents )
# ["California's largest electricity provider has turned off power to hundreds of thousands of customers."]Кроме того, пожалуйста, запустите нашу ноутбук Colab для более практической демонстрации и дополнительных примеров.
Summertime поддерживает различные модели (например, Textrank, BART, Longformer), а также модельные обертки для более сложных задач суммирования (например, совместная модель для Summarzation Multi-DOC, поиск BM25 для суммирования на основе запросов). Также поддерживаются несколько многоязычных моделей (MT5 и MBART).
| Модели | Одиночный док | Multi-Doc | Основанный на диалоге | На основе запросов | Многоязычный |
|---|---|---|---|---|---|
| Бартмодель | ✔ | ||||
| BM25SummModel | ✔ | ||||
| HmnetModel | ✔ | ||||
| Lexrankmodel | ✔ | ||||
| Longformermodel | ✔ | ||||
| Mbartmodel | ✔ | 50 языков (полный список здесь) | |||
| MT5Model | ✔ | 101 языки (полный список здесь) | |||
| Перевод PipipelineModel | ✔ | ~ 70 языков | |||
| Multidocjointmodel | ✔ | ||||
| Многотокератемодель | ✔ | ||||
| Пегасусмодель | ✔ | ||||
| TextrankModel | ✔ | ||||
| Tfidfsummmodel | ✔ |
Чтобы увидеть все поддерживаемые модели, запустите:
from summertime . model import SUPPORTED_SUMM_MODELS
print ( SUPPORTED_SUMM_MODELS ) from summertime import model
# To use a default model
default_model = model . summarizer ()
# Or a specific model
bart_model = model . BartModel ()
pegasus_model = model . PegasusModel ()
lexrank_model = model . LexRankModel ()
textrank_model = model . TextRankModel ()Пользователи могут легко получить доступ к документации, чтобы помочь с выбором модели
default_model . show_capability ()
pegasus_model . show_capability ()
textrank_model . show_capability ()Чтобы использовать модель для суммирования, просто запустите:
documents = [
""" PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions.
The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected
by the shutoffs which were expected to last through at least midday tomorrow."""
]
default_model . summarize ( documents )
# or
pegasus_model . summarize ( documents )Все модели могут быть инициализированы со следующими дополнительными параметрами:
def __init__ ( self ,
trained_domain : str = None ,
max_input_length : int = None ,
max_output_length : int = None ,
):Все модели будут реализовать следующие методы:
def summarize ( self ,
corpus : Union [ List [ str ], List [ List [ str ]]],
queries : List [ str ] = None ) -> List [ str ]:
def show_capability ( cls ) -> None :Summertime поддерживает различные наборы данных обобщения в разных областях (например, набор данных CNNDM - новостная статья Corpus, Samsum - Диалог Corpus, QM -SUM - Корпус на основе запросов, Multinews - Multi -Document Corpus, ML -Sum - мультингальное корпус, Pubmedqa - Medical Domain, Arxiv -Papers Domain, среди других.
| Набор данных | Домен | # Примеры | SRC. длина | Тгт длина | Запрос | Multi-Doc | Диалог | Многоязычный |
|---|---|---|---|---|---|---|---|---|
| Arxiv | Научные статьи | 215K | 4,9К | 220 | ||||
| CNN/DM (3.0.0) | Новости | 300K | 781 | 56 | ||||
| Mlsumdataset | Многоязычные новости | 1,5 м+ | 632 | 34 | ✔ | Немецкий, испанский, французский, русский, турецкий | ||
| Мульти-новые | Новости | 56K | 2.1K | 263.8 | ✔ | |||
| Самсум | Открытый домен | 16k | 94 | 20 | ✔ | |||
| PubMedqa | Медицинский | 272K | 244 | 32 | ✔ | |||
| QMSUM | Встречи | 1K | 9.0K | 69,6 | ✔ | ✔ | ||
| Scisummnet | Научные статьи | 1K | 4,7K | 150 | ||||
| Суммар | Телешоу | 26,9K | 6,6k | 337.4 | ✔ | |||
| Xsum | Новости | 226K | 431 | 23.3 | ||||
| XLSUM | Новости | 1,35 м | ??? | ??? | 45 языков (см. Документацию) | |||
| Massivesumm | Новости | 12м+ | ??? | ??? | 78 языков (подробности см. В разделе «Многоязычное обобщение». |
Чтобы увидеть все поддерживаемые наборы данных, запустите:
from summertime import dataset
print ( dataset . list_all_dataset ()) from summertime import dataset
cnn_dataset = dataset . CnndmDataset ()
# or
xsum_dataset = dataset . XsumDataset ()
# ..etc Все наборы данных являются реализациями класса SummDataset . Их разделения данных можно получить следующим образом:
dataset = dataset . CnndmDataset ()
train_data = dataset . train_set
dev_data = dataset . dev_set
test_data = dataset . test_set Чтобы увидеть детали наборов данных, запустите:
dataset = dataset . CnndmDataset ()
dataset . show_description () Данные во всех наборах данных содержатся в объекте класса SummInstance , который имеет следующие свойства:
data_instance . source = source # either `List[str]` or `str`, depending on the dataset itself, string joining may needed to fit into specific models.
data_instance . summary = summary # a string summary that serves as ground truth
data_instance . query = query # Optional, applies when a string query is present
print ( data_instance ) # to print the data instance in its entiretyДанные загружаются с помощью генератора для сэкономить на пространстве и времени
data_instance = next ( cnn_dataset . train_set )
print ( data_instance ) import itertools
# Get a slice from the train set generator - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
print ( corpus ) Вы можете использовать пользовательские данные, используя класс CustomDataset , который загружает данные в классе набора данных SummerTime
from summertime . dataset import CustomDataset
''' The train_set, test_set and validation_set have the following format:
List[Dict], list of dictionaries that contain a data instance.
The dictionary is in the form:
{"source": "source_data", "summary": "summary_data", "query":"query_data"}
* source_data is either of type List[str] or str
* summary_data is of type str
* query_data is of type str
The list of dictionaries looks as follows:
[dictionary_instance_1, dictionary_instance_2, ...]
'''
# Create sample data
train_set = [
{
"source" : "source1" ,
"summary" : "summary1" ,
"query" : "query1" , # only included, if query is present
}
]
validation_set = [
{
"source" : "source2" ,
"summary" : "summary2" ,
"query" : "query2" ,
}
]
test_set = [
{
"source" : "source3" ,
"summary" : "summary3" ,
"query" : "query3" ,
}
]
# Depending on the dataset properties, you can specify the type of dataset
# i.e multi_doc, query_based, dialogue_based. If not specified, they default to false
custom_dataset = CustomDataset (
train_set = train_set ,
validation_set = validation_set ,
test_set = test_set ,
query_based = True ,
multi_doc = True
dialogue_based = False ) import itertools
from summertime import dataset , model
cnn_dataset = dataset . CnndmDataset ()
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# Example 1 - traditional non-neural model
# LexRank model
lexrank = model . LexRankModel ( corpus )
print ( lexrank . show_capability ())
lexrank_summary = lexrank . summarize ( corpus )
print ( lexrank_summary )
# Example 2 - A spaCy pipeline for TextRank (another non-neueral extractive summarization model)
# TextRank model
textrank = model . TextRankModel ()
print ( textrank . show_capability ())
textrank_summary = textrank . summarize ( corpus )
print ( textrank_summary )
# Example 3 - A neural model to handle large texts
# LongFormer Model
longformer = model . LongFormerModel ()
longformer . show_capability ()
longformer_summary = longformer . summarize ( corpus )
print ( longformer_summary ) Метод summarize() многоязычных моделей автоматически проверяет язык входных документов.
Многоязычные модели с одним доком могут быть инициализированы и использованы так же, как и одноязычные модели. Они возвращают ошибку, если язык, не поддерживаемый моделью, является вводом.
mbart_model = st_model . MBartModel ()
mt5_model = st_model . MT5Model ()
# load Spanish portion of MLSum dataset
mlsum = datasets . MlsumDataset ([ "es" ])
corpus = itertools . islice ( mlsum . train_set , 5 )
corpus = [ instance . source for instance in train_set ]
# mt5 model will automatically detect Spanish as the language and indicate that this is supported!
mt5_model . summarize ( corpus )Следующие языки в настоящее время поддерживаются в нашем реализации набора данных Massivesmum: африкаанс, амхарский, арабский, ассамский, аймара, азербайджани, бамбара, бенгальский, тибетский, боснийский, болгарский, каталонский, чех, валлийский, данный, немецкий, грек, английский, эсперский, эсперский, филайский, филайский, филайский, филайский, филайский, филайский, филибин, эйр, эсперский, филип, филип, фили. Gujarati, Haitian, Hausa, Hebrew, Hindi, Croatian, Hungarian, Armenian,Igbo, Indonesian, Icelandic, Italian, Japanese, Kannada, Georgian, Khmer, Kinyarwanda, Kyrgyz, Korean, Kurdish, Lao, Latvian, Lingala, Lithuanian, Malayalam, Marathi, Macedonian, Malagasy, Монгольский, бирманский, южный ндебеле, непальский, голландский, орийя, оромо, пенджаби, польский, португальский, Дари, пушту, румын, Рунди, Русский, сингала, Словак, Словена, Шона, Сомали, Испанский, Албанский, Сербиан, Свахил, Свадский, Тамил, Там, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тама, Тигринья, турецкая, украинская, урду, узбек, вьетнамцы, Xhosa, йоруба, китайский китайский, китайский, бислама и гэльский.
Летнее время поддерживает различные показатели оценки, включая: Bertscore, Bleu, Meteor, Rouge, Rougewe
Для печати всех поддерживаемых показателей:
from summertime . evaluation import SUPPORTED_EVALUATION_METRICS
print ( SUPPORTED_EVALUATION_METRICS ) import summertime . evaluation as st_eval
bert_eval = st_eval . bertscore ()
bleu_eval = st_eval . bleu_eval ()
meteor_eval = st_eval . bleu_eval ()
rouge_eval = st_eval . rouge ()
rougewe_eval = st_eval . rougewe ()Все показатели оценки могут быть инициализированы со следующими дополнительными аргументами:
def __init__ ( self , metric_name ):Все метрические объекты оценки реализуют следующие методы:
def evaluate ( self , model , data ):
def get_dict ( self , keys ):Получите примерные данные
from summertime . evaluation . base_metric import SummMetric
from summertime . evaluation import Rouge , RougeWe , BertScore
import itertools
# Evaluates model on subset of cnn_dailymail
# Get a slice of the train set - first 5 instances
train_set = itertools . islice ( cnn_dataset . train_set , 5 )
corpus = [ instance for instance in train_set ]
print ( corpus )
articles = [ instance . source for instance in corpus ]
summaries = sample_model . summarize ( articles )
targets = [ instance . summary for instance in corpus ]Оценить данные по разным метрикам
from summertime . evaluation import BertScore , Rouge , RougeWe ,
# Calculate BertScore
bert_metric = BertScore ()
bert_score = bert_metric . evaluate ( summaries , targets )
print ( bert_score )
# Calculate Rouge
rouge_metric = Rouge ()
rouge_score = rouge_metric . evaluate ( summaries , targets )
print ( rouge_score )
# Calculate RougeWe
rougewe_metric = RougeWe ()
rougwe_score = rougewe_metric . evaluate ( summaries , targets )
print ( rougewe_score ) Учитывая летний набор данных, вы можете использовать функцию pipelines.assemble_model_pipeline для получения списка инициализированных моделей Summertime, которые совместимы с предоставленным набором данных.
from summertime . pipeline import assemble_model_pipeline
from summertime . dataset import CnndmDataset , QMsumDataset
single_doc_models = assemble_model_pipeline ( CnndmDataset )
# [
# (<model.single_doc.bart_model.BartModel object at 0x7fcd43aa12e0>, 'BART'),
# (<model.single_doc.lexrank_model.LexRankModel object at 0x7fcd43aa1460>, 'LexRank'),
# (<model.single_doc.longformer_model.LongformerModel object at 0x7fcd43b17670>, 'Longformer'),
# (<model.single_doc.pegasus_model.PegasusModel object at 0x7fccb84f2910>, 'Pegasus'),
# (<model.single_doc.textrank_model.TextRankModel object at 0x7fccb84f2880>, 'TextRank')
# ]
query_based_multi_doc_models = assemble_model_pipeline ( QMsumDataset )
# [
# (<model.query_based.tf_idf_model.TFIDFSummModel object at 0x7fc9c9c81e20>, 'TF-IDF (HMNET)'),
# (<model.query_based.bm25_model.BM25SummModel object at 0x7fc8b4fa8c10>, 'BM25 (HMNET)')
# ]=======
Учитывая летний набор данных, вы можете использовать функцию pipelines.assemble_model_pipeline для получения списка инициализированных моделей Summertime, которые совместимы с предоставленным набором данных.
# Get test data
import itertools
from summertime . dataset import XsumDataset
# Get a slice of the train set - first 5 instances
sample_dataset = XsumDataset ()
sample_data = itertools . islice ( sample_dataset . train_set , 100 )
generator1 = iter ( sample_data )
generator2 = iter ( sample_data )
bart_model = BartModel ()
pegasus_model = PegasusModel ()
models = [ bart_model , pegasus_model ]
metrics = [ metric () for metric in SUPPORTED_EVALUATION_METRICS ] from summertime . evaluation . model_selector import ModelSelector
selector = ModelSelector ( models , generator1 , metrics )
table = selector . run ()
print ( table )
visualization = selector . visualize ( table )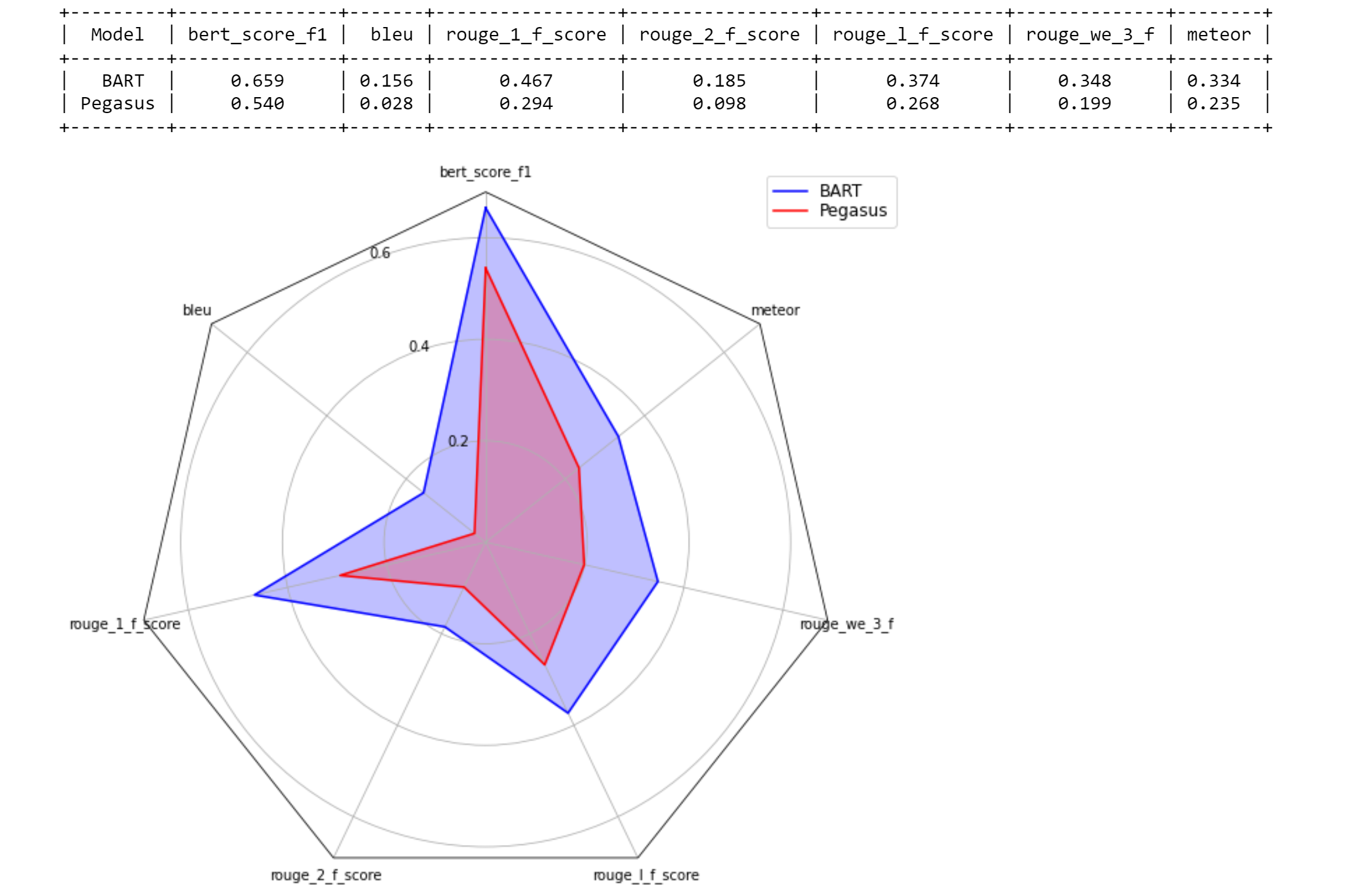
from summertime . evaluation . model_selector import ModelSelector
new_selector = ModelSelector ( models , generator2 , metrics )
smart_table = new_selector . run_halving ( min_instances = 2 , factor = 2 )
print ( smart_table )
visualization_smart = selector . visualize ( smart_table ) from summertime . evaluation . model_selector import ModelSelector
from summertime . evaluation . error_viz import scatter
keys = ( "bert_score_f1" , "bleu" , "rouge_1_f_score" , "rouge_2_f_score" , "rouge_l_f_score" , "rouge_we_3_f" , "meteor" )
scatter ( models , sample_data , metrics [ 1 : 3 ], keys = keys [ 1 : 3 ], max_instances = 5 )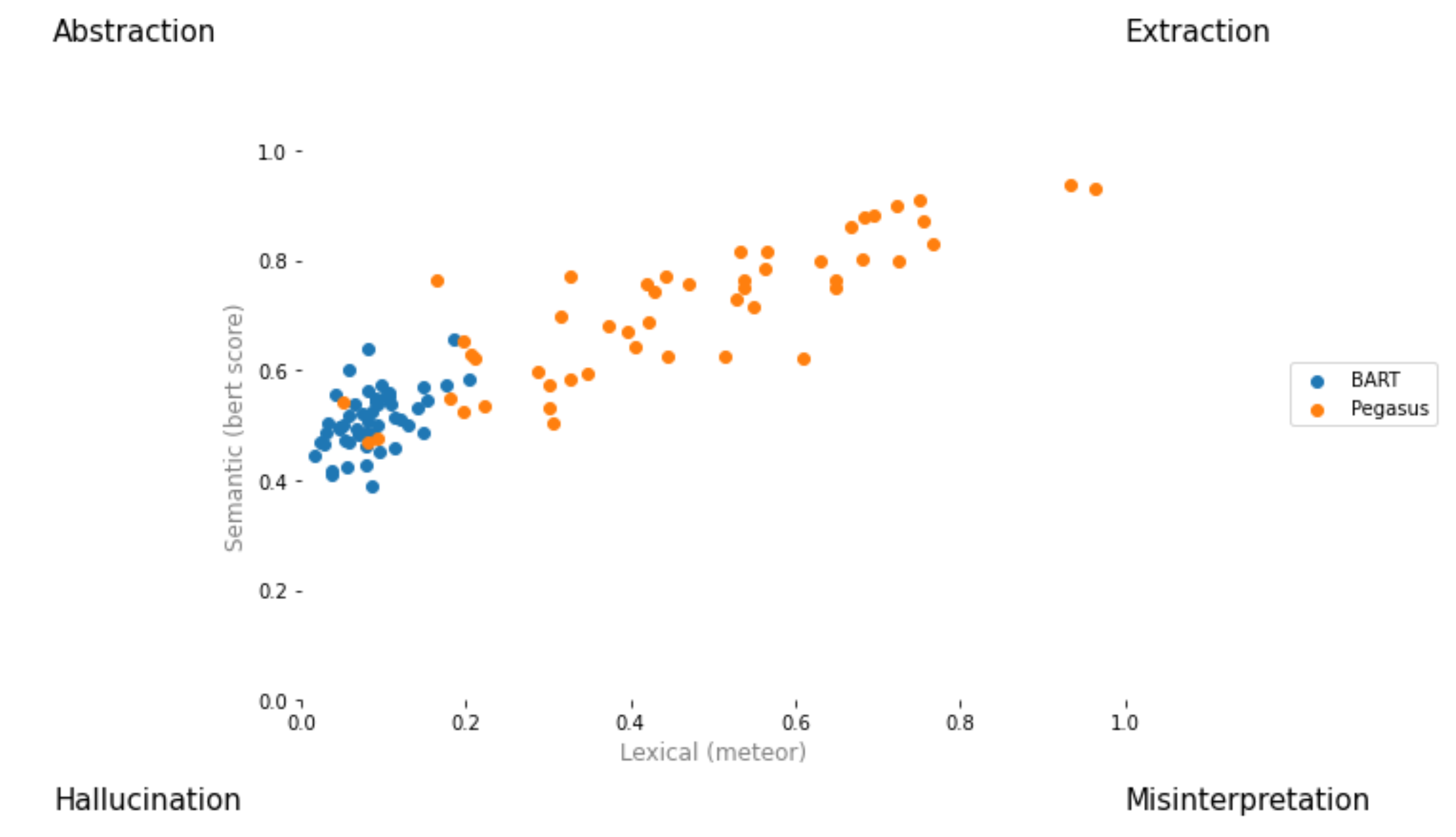
Создайте запрос на тягу и назовите его [ your_gh_username ]/[ your_branch_name ]. При необходимости урегулируйте конфликты слияния вашей собственной филиала с Main. Не подталкивайте прямо к основному.
Если вы еще этого не сделали, установите black и flake8 :
pip install black
pip install flake8 Прежде чем нажимать коммиты или слияние ветвей, запустите следующие команды из корня проекта. Обратите внимание, что black будет писать в файлы, и что вы должны добавить и совершать изменения, внесенные black , прежде чем нажимать:
black .
flake8 .Или, если вы хотите прокинуть определенные файлы:
black path/to/specific/file.py
flake8 path/to/specific/file.py Убедитесь, что black не переформатирует какие -либо файлы и что flake8 не печатает никаких ошибок. Если вы хотите переопределить или игнорировать какие -либо предпочтения или практики, применяемые black или flake8 , пожалуйста, оставьте комментарий в вашем пиаре для любых строк кода, которые генерируют предупреждение или журналы ошибок. Не редактируйте файлы конфигурации, такие как setup.cfg .
См. black Docs и Docs flake8 для документации по установке, игнорированию файлов/линий и расширенного использования. Кроме того, следующее может быть полезно:
black [file.py] --diff для просмотра изменений как различия вместо напрямую вносить измененияblack [file.py] --check для просмотра изменений с кодами состояния вместо непосредственного внесения измененийgit diff -u | flake8 --diff , чтобы запустить Flake8 при изменениях рабочей филиала Обратите внимание, что наш набор CI Test будет включать в себя вызов black --check . и flake8 --count . Во всех не Unitital и не определенных файлах Python и нулевой вывод на уровне ошибок требуется для прохождения всех тестов.
Наша система непрерывной интеграции предоставляется с помощью действий GitHub. Когда любой запрос на вытягивание создается или обновляется или когда main обновляется, модульные тесты репозитория будут выполняться в качестве заданий по строительству Tangra для этого запроса на привлечение. Строительные задания пройдут либо в течение нескольких минут, а статусы сборки и журналы видны под действиями. Пожалуйста, убедитесь, что самый последний Commit in Outsists проходит все чеки (т. Е. Все шаги во всех работах, которые проходят до завершения), прежде чем слияние или запросить проверку. Чтобы пропустить построение на любом конкретном коммите, добавьте [skip ci] к сообщению Commit. Обратите внимание, что PR с подстрокой /no-ci/ в любом месте имени филиала не будут включены в CI.
Этот репозиторий построен Lily Lab в Йельском университете, во главе с профессором Драгомиром Радевом. Основными участниками являются Ансонг Ни, Чжангир Азербаев, Трой Фэн, Мурори Мутума, Хейли Шоэлкопф и Юсен Чжан (штат Пенсильвания).
Если вы используете летнее время в своей работе, подумайте о цитировании:
@article{ni2021summertime,
title={SummerTime: Text Summarization Toolkit for Non-experts},
author={Ansong Ni and Zhangir Azerbayev and Mutethia Mutuma and Troy Feng and Yusen Zhang and Tao Yu and Ahmed Hassan Awadallah and Dragomir Radev},
journal={arXiv preprint arXiv:2108.12738},
year={2021}
}
Для комментариев и вопроса, пожалуйста, откройте проблему.


