BambooAI
v0.3.52
使用大型语言模型(LLM)提供自然语言互动功能的轻量级库,就像研究和数据分析助理促使您的数据对话一样。您可以提供自己的数据集,也可以允许库为您找到和获取数据。它支持Internet搜索和外部API交互。
Bookeai库是一种实验性的,轻巧的工具,它利用大型语言模型(LLMS)来促进数据分析,使用户更容易访问,包括没有编程专业知识的用户。它是研究和数据分析的助手,使用户可以通过自然语言与数据互动。用户可以提供自己的数据集,或者Bookeai可以帮助采购必要的数据。该工具还集成了Internet搜索并访问外部API以增强其功能。
Boogyai处理有关数据集的自然语言查询,并可以生成和执行Python代码以进行数据分析和可视化。这使用户能够在无广泛的编码知识的情况下从其数据中获得见解。用户只需输入他们的数据集,用简单的英语提出问题,而Bookyai则提供答案以及可视化,以帮助更好地理解数据。
Boogyai的目标是增强各个级别的数据分析师的功能。它简化了数据分析和可视化,有助于简化工作流程。该图书馆旨在用户友好,高效且适应能够满足各种需求。
在Google Colab中尝试一下:
使用提供的数据框的机器学习示例:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyter笔记本:
任务:您能否设计一个机器Learnig模型来预测乘客在泰坦尼克号上的生存?输出模型的准确性。绘制混淆矩阵,相关矩阵和其他相关指标。搜索Internet以获取最佳方法来完成此任务。
Web UI:
任务:与体育数据分析有关的各种查询
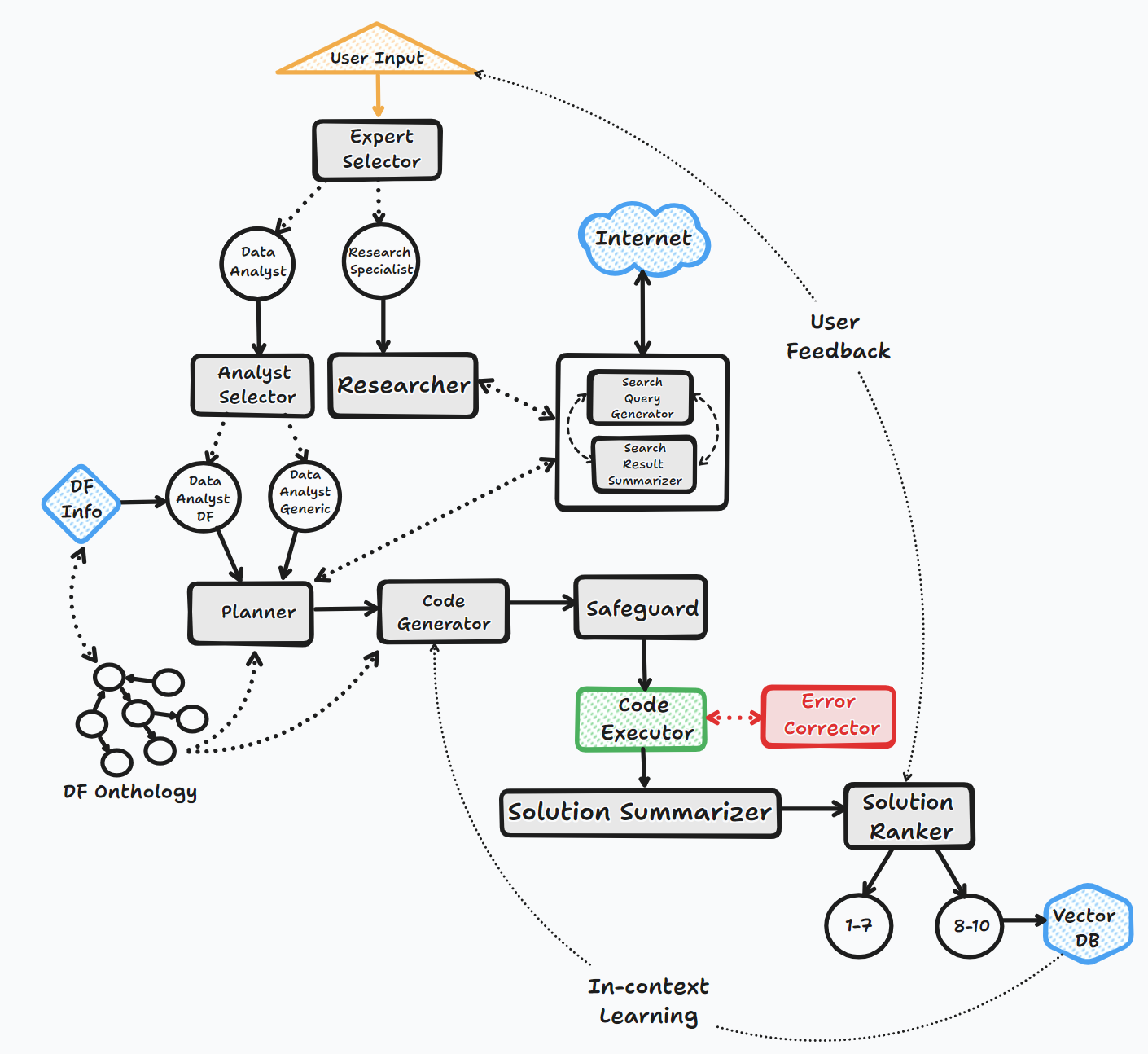
Bookeai代理通过几个关键步骤操作,与用户互动并产生响应:
1。启动
2。任务评估
3。动态提示构建
4。调试,执行和错误纠正
5。结果,排名和知识基础建立
6。人类反馈和循环继续
在此过程中,代理会连续征求用户输入,存储消息以获取上下文,并生成和执行代码以确保最佳结果。在此过程中,采用了各种AI模型和矢量数据库,以提供对用户问题的准确和有用的回答。
流程图(通用代理流):
该图书馆支持通过API或Localy使用各种开源或专有模型。
API:
当地的:
您可以通过修改llm_config文件的内容来指定要用于特定代理的供应商/模型,用您选择的模型和供应商替换默认的OpenAI模型名称。例如。 {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} 。 LLM_Config的目的将在下面更详细地描述。
安装
pip install bambooai
用法
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
弃用通知(2023年10月25日):请注意,“ llm”,“ local_code_model”,“ llm_switch_plan”和“ llm_switch_code”参数已被弃用为v 0.3.29。现在通过llm_config来处理模型和模型参数对代理的分配。可以将其设置为环境变量,也可以通过工作目录中的llm_config.json文件设置。请参阅下面的详细信息
The agent specific llm configuration is stored in LLM_CONFIG environment variable, or in the "LLM_CONFIG.json file which needs to be stored in the BambooAI's working directory. The config is in a form of JSON list of dictionaries and specifies model name, provider, temperature and max_tokens for each agent. You can use the provided LLM_CONFIG_sample.json as a starting point, and modify the config为了反映您的偏好,如果存在“ env var”和“ llm_config.json”,Bookeai将使用默认的硬编码配置,用于所有代理商使用“ GPT-3.5-Turbo”。
Bookeai库为每个代理使用默认的硬编码及时模板。如果您想与它们进行实验,可以修改提供的“提示_templates_sample.json”文件,从其名称中删除“ _sample并存储在工作目录中。随后,修改后的“ strump_templates.json.json”的内容将使用default/replevers remeptry/replate indepts/replate。
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
环境变量
该库需要一个OpenAI API帐户和API密钥才能连接到OpenAI LLMS。 OpenAI API密钥需要存储在OPENAI_API_KEY环境变量中。可以从此处获得键:https://platform.openai.com/account/api-keys。
除了OpenAI模型外,还支持来自不同提供商的模型(Groq,Gemini,Mistral,Anthropic)。 API键需要以以下格式存储在环境变量中<VENDOR_NAME>_API_KEY 。您需要将GEMINI_API_KEY用于Google Gemini型号。
如上所述,LLM配置可以在LLM_CONFIG环境变量中以字符串格式存储。您可以将提供的llm_config_sample.json的内容作为起点,并根据您可以访问的模型进行修改。
Pincone Vector DB是可选的。如果您不想使用它,则无需做任何事情。如果您有Pinecone的帐户,并且想使用知识库和排名功能,则需要您设置PINECONE_API_KEY Envirooment变量,并将'vector_db'参数设置为true。向量数据库索引是在第一次执行时创建的。
Google搜索也是可选的。如果您不想使用它,则无需做任何事情。如果您有一个带有Serper的帐户,并且想使用Google搜索功能,则将要求您设置和帐户“:https://serper.dev/”,并设置SERPER_API_KEY环境变量,然后将'search_tool'参数设置为true。默认情况下,Bookeai只能刮擦带有HTML内容的网站。但是,它也能够将硒与Chromedriver一起使用,这更强大。要启用此功能,您需要手动下载与Chrome浏览器版本相匹配的Chromedriver版本,将其存储在文件系统中,并创建环境变量SELENIUM_WEBDRIVER_PATH ,并使用通往Chromedriver的路径。 Boogyai Will会自动拾取它,并使用硒进行所有刮擦任务。
本地开源模型
该库当前直接支持以下开源模型。我选择了当前在人道基准测试中得分最高的型号。
如果要使用特定代理的本地模型,请修改llm_config内容,用本地模型名称代替OpenAI模型名称,然后将提供商值更改为“本地”。例如。 {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} At present it is recommended to use local models only for code generation tasks, all other tasks like pseudo code generaration, summarisation, error correction and ranking should be still handled by OpenAI models选择。该模型是从HuggingFace下载的,并在Localy中下载以进行后续执行。为了合理的性能,它需要启用CUDA的GPU,并且与CUDA版本兼容的Pytorch库。以下是包装中未包含的所需库,需要独立安装:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
本地模型的设置和参数位于local_models.py模块中,可以调整以匹配您的特定配置或首选项。
霍拉马
图书馆还支持Ollama https://ollama.com/的使用以及所有模型。如果要为特定代理使用本地的Ollama模型,请修改llm_config内容,用Ollama模型名称代替OpenAI模型名称,然后将提供商的值更改为“ Ollama”。例如。 {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
记录
所有LLM交互(本地或通过API)均在bambooai_consolidated_log.json文件中记录。当日志文件的大小达到5 MB时,会创建一个新的日志文件。在最旧的文件被覆盖之前,总共将3个日志文件保存在文件系统上。
捕获以下细节:
日志结构:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
任务:设计机器学习模型,以预测乘客在泰坦尼克号上的生存。输出应包括模型的准确性以及混淆矩阵,相关矩阵和其他相关指标的可视化。
数据集: Titanic.csv
型号: GPT-4-Turbo
| 公制 | 价值 |
|---|---|
| 执行时间 | 77.12秒 |
| 输入令牌 | 7128 |
| 输出令牌 | 1215 |
| 总成本 | $ 0.1077 |
| 公制 | 价值 |
|---|---|
| 执行时间 | 47.39秒 |
| 输入令牌 | 722 |
| 输出令牌 | 931 |
| 总成本 | $ 0.0353 |
体育数据分析的AI工具的客观评估_ Maxwell-V2与通用LLMS.pdf
欢迎捐款;请随时打开拉动请求。请记住,我们的目标是保持具有高可读性的简洁代码库。


