BambooAI
v0.3.52
Una biblioteca liviana que utiliza modelos de idiomas grandes (LLM) para proporcionar capacidades de interacción del lenguaje natural, al igual que un asistente de investigación y análisis de datos que permite una conversación con sus datos. Puede proporcionar sus propios conjuntos de datos o permitir que la biblioteca localice y obtenga datos para usted. Admite búsquedas en Internet e interacciones API externas.
La Biblioteca Bambooai es una herramienta experimental de Lightweigh que utiliza grandes modelos de lenguaje (LLM) para facilitar el análisis de datos, por lo que es más accesible para los usuarios, incluidos aquellos sin experiencia en programación. Funciona como asistente para la investigación y el análisis de datos, lo que permite a los usuarios interactuar con sus datos a través del lenguaje natural. Los usuarios pueden suministrar sus propios conjuntos de datos o Bambooai pueden ayudar a obtener los datos necesarios. La herramienta también integra las búsquedas en Internet y accede a API externas para mejorar su funcionalidad.
Bambooai procesa consultas de lenguaje natural sobre conjuntos de datos y puede generar y ejecutar el código de Python para el análisis y la visualización de datos. Esto permite a los usuarios obtener información de sus datos sin un amplio conocimiento de codificación. Los usuarios simplemente ingresan su conjunto de datos, hacen preguntas en inglés simple y Bambooai proporciona las respuestas, junto con las visualizaciones si es necesario, para ayudar a comprender mejor los datos.
Bambooai tiene como objetivo aumentar las capacidades de los analistas de datos en todos los niveles. Simplifica el análisis y la visualización de datos, ayudando a agilizar los flujos de trabajo. La biblioteca está diseñada para ser fácil de usar, eficiente y adaptable para satisfacer diversas necesidades.
Pruébelo en Google Colab:
Un ejemplo de aprendizaje automático utilizando datos de datos suministrados:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Notebook Jupyter:
Tarea: ¿Puede idear un modelo de Learnig Machine para predecir la supervivencia de los pasajeros en el Titanic? ENCONTRA La precisión del modelo. Trace la matriz de confusión, la matriz de correlación y otras métricas relevantes. Busque en Internet el mejor enfoque de esta tarea.
UI web:
Tarea: varias consultas relacionadas con el análisis de datos deportivos
El agente Bambooai opera a través de varios pasos clave para interactuar con los usuarios y generar respuestas:
1. Iniciación
2. Evaluación de tareas
3. Construcción de inmediato dinámico
4. Depuración, ejecución y corrección de errores
5. Resultados, clasificación y construcción de la base de conocimiento
6. Comentarios humanos y continuación del bucle
A lo largo de este proceso, el agente solicita continuamente la entrada del usuario, almacena mensajes para el contexto y genera y ejecuta código para garantizar resultados óptimos. Se emplean varios modelos de IA y una base de datos vectorial en este proceso para proporcionar respuestas precisas y útiles a las preguntas del usuario.
Diagrama de flujo (flujo de agente general):
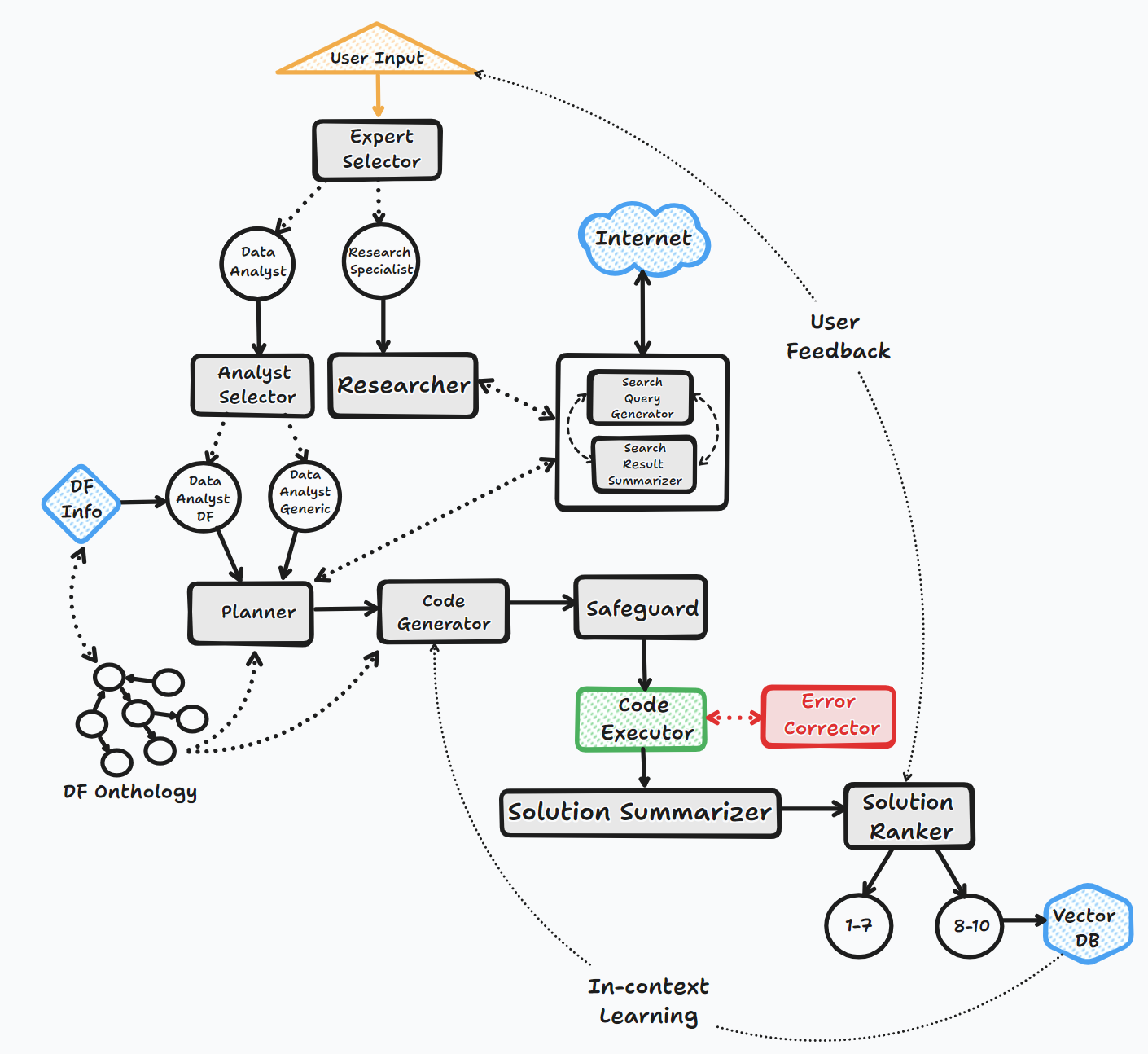
La biblioteca admite el uso de varios modelos de código abierto o patentado, ya sea a través de API o localy.
API:
Local:
Puede especificar qué proveedor/modelo desea utilizar para un agente específico modificando el contenido del archivo LLM_CONFIG, reemplazando el nombre de modelo OpenAI predeterminado con el modelo y el proveedor de su elección. p.ej. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . El propósito de LLM_Config se describe con más detalle a continuación.
Instalación
pip install bambooai
Uso
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
Aviso de deprecación (25 de octubre de 2023): Tenga en cuenta que los parámetros "LLM", "Local_Code_Model", "LLM_SWITCH_PLAN" y "LLM_SWITCH_CODE" se han desaprobado a partir de V 0.3.29. La asignación de modelos y parámetros del modelo a los agentes ahora se maneja a través de LLM_CONFIG. Esto se puede establecer como una variable de entorno o a través de un archivo LLM_CONFIG.JSON en el directorio de trabajo. Consulte los detalles a continuación
La configuración de LLM específica del agente se almacena en la variable de entorno LLM_CONFIG , o en el archivo "LLM_CONFIG.JSON que debe almacenarse en el directorio de trabajo de Bambooai. La configuración está en una forma de lista JSON de diccionarios y especifica el nombre del modelo, el proveedor, la temperatura y max_tokens para cada agente. Puede usar el LM_Config de los modificadores, y modifique el nombre del modelo, y modifique el punto de modificación, y modifique, y modifique, y modifique, y modifique, y modifique, y modifique, y modifique el nombre y modifique, y modifique, y modifique, y modifique, y modifique, y modifique, y modifique, y modifique el nombre, y se modifique. La configuración para reflejar sus preferencias.
La biblioteca Bambooai utiliza un conjunto de plantillas de inmediato por codificación predeterminada para cada agente. Si desea experimentar con ellos, puede modificar el archivo proporcionado "ARD_Templates_Sample.json", eliminar el "_sample de su nombre y almacenar en el directorio de trabajo. Posteriormente, el contenido de" indic_templates.json "modificado se utilizará en lugar de los predeterminados codificados.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Variables de entorno
La biblioteca requiere una cuenta API de OpenAI y la clave API para conectarse a OpenAI LLMS. La tecla API de OpenAI debe almacenarse en una variable de entorno OPENAI_API_KEY . La clave se puede obtener de aquí: https://platform.openai.com/account/api-keys.
Además de los modelos OpenAI, también es compatible con una selección de modelos de diferentes proveedores (Groq, Géminis, Mistral, Anthropic). Las claves API deben almacenarse en variables de entorno en el siguiente formato <VENDOR_NAME>_API_KEY . Debe usar GEMINI_API_KEY para los modelos Google Gemini.
Como se mencionó anteriormente, la configuración LLM se puede almacenar en un formato de cadena en la variable de entorno LLM_CONFIG . Puede usar el contenido de LLM_Config_Sample.json proporcionado como punto de partida y modificar a su preferencia, dependiendo de a qué modelos tenga acceso.
El Pincone Vector DB es opcional. Si no quieres usarlo, no necesitas hacer nada. Si tiene una cuenta con Pinecone y desea utilizar la base de conocimiento y las funciones de clasificación, se le solicitará que configure la variable PINECONE_API_KEY Entirooment y establezca el parámetro 'Vector_DB' en verdadero. El índice Vector DB se crea tras la primera ejecución.
La búsqueda de Google también es opcional. Si no quieres usarlo, no necesitas hacer nada. Si tiene una cuenta con Serper y desea utilizar la funcionalidad de búsqueda de Google, se le solicitará que configure y tenga en cuenta ": https://serper.dev/", y configure la variable de entorno SERPER_API_KEY , y establezca el parámetro 'Search_Tool' en verdadero. Por defecto, Bambooai solo puede raspar sitios web con contenido HTML. Sin embargo, también es capaz de usar selenio con cromedriver, que es mucho más poderoso. Para habilitar esta funcionalidad, necesitará descargar una versión de ChromedRiver que coincida con su versión del navegador Chrome, guárdelo en el sistema de archivos y cree una variable de entorno SELENIUM_WEBDRIVER_PATH con una ruta a su cromedriver. Bambooai lo recogerá Automaticaly y use Selenium para todas las tareas de raspado.
Modelos locales de código abierto
La biblioteca actualmente admite directamente los siguientes modelos de código abierto. He seleccionado los modelos que actualmente obtienen el más alto en el punto de referencia Humaneval.
Si desea utilizar el modelo local para un agente específico, modifique el contenido LLM_CONFIG reemplazando el nombre del modelo OpenAI con el nombre del modelo local y cambie el valor del proveedor a 'local'. p.ej. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} En la actual Modelos de elección. El modelo se descarga de Huggingface y en caché de localy para ejecuciones posteriores. Para un rendimiento razonable, requiere GPU habilitado para CUDA y la biblioteca Pytorch compatible con la versión CUDA. A continuación se presentan las bibliotecas requeridas que no están incluidas en el paquete y deberán instalarse de forma independiente:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
La configuración y los parámetros para los modelos locales se encuentran en el módulo local_models.py y se pueden ajustar para que coincida con su configuración o preferencias particulares.
Ollama
La biblioteca también admite el uso de Ollama https://ollama.com/ y todos sus modelos. Si desea utilizar un modelo Ollama local para un agente específico, modifique el contenido LLM_CONFIG reemplazando el nombre del modelo OpenAI con el nombre del modelo Ollama y cambie el valor del proveedor a 'Ollama'. p.ej. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Explotación florestal
Todas las interacciones LLM (locales o mediante API) se registran en el archivo bambooai_consolidated_log.json . Cuando el tamaño del archivo de registro alcanza 5 MB, se crea un nuevo archivo de registro. Un total de 3 archivos de registro se mantienen en el sistema de archivos antes de que el archivo más antiguo se sobrescribiera.
Se capturan los siguientes detalles:
Estructura de registro:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Tarea: idee un modelo de aprendizaje automático para predecir la supervivencia de los pasajeros en el Titanic. La salida debe incluir la precisión del modelo y las visualizaciones de la matriz de confusión, la matriz de correlación y otras métricas relevantes.
Conjunto de datos: titanic.csv
Modelo: GPT-4-TURBO
| Métrico | Valor |
|---|---|
| Tiempo de ejecución | 77.12 segundos |
| Tokens de entrada | 7128 |
| Tokens de salida | 1215 |
| Costo total | $ 0.1077 |
| Métrico | Valor |
|---|---|
| Tiempo de ejecución | 47.39 segundos |
| Tokens de entrada | 722 |
| Tokens de salida | 931 |
| Costo total | $ 0.0353 |
Evaluación objetiva de herramientas de IA para análisis de datos deportivos_ Maxwell-V2 vs. Generic LLMS.PDF
Las contribuciones son bienvenidas; No dude en abrir una solicitud de extracción. Tenga en cuenta que nuestro objetivo es mantener una base de código concisa con alta legibilidad.


