BambooAI
v0.3.52
LLMS (Large Language Models)를 사용하여 데이터 분석 어시스턴트와 마찬가지로 자연 언어 상호 작용 기능을 제공하기 위해 LLM (Lange Language Models)을 사용하는 가벼운 라이브러리. 귀하는 자신의 데이터 세트를 제공하거나 라이브러리가 귀하를 위해 데이터를 찾아서 가져 오도록 허용 할 수 있습니다. 인터넷 검색 및 외부 API 상호 작용을 지원합니다.
Bambooi Library는 LLM (Large Language Model)을 사용하여 데이터 분석을 용이하게하여 프로그래밍 전문 지식이없는 사용자를 포함하여 사용자가보다 액세스 할 수 있도록 실험적이고 Lightweigh 도구입니다. 연구 및 데이터 분석의 보조원으로 기능하여 사용자가 자연어를 통해 데이터와 상호 작용할 수 있습니다. 사용자는 자신의 데이터 세트를 제공하거나 Bambooai가 필요한 데이터를 소싱하는 데 도움이 될 수 있습니다. 이 도구는 또한 인터넷 검색을 통합하고 외부 API에 액세스하여 기능을 향상시킵니다.
Bambooi는 데이터 세트에 대한 자연어 쿼리를 처리하고 데이터 분석 및 시각화를 위해 Python 코드를 생성하고 실행할 수 있습니다. 이를 통해 사용자는 광범위한 코딩 지식없이 데이터에서 통찰력을 도출 할 수 있습니다. 사용자는 단순히 데이터 세트를 입력하고 간단한 영어로 질문을하며 Bambooi는 데이터를 더 잘 이해하는 데 도움이되는 경우에 대한 시각화와 함께 답변을 제공합니다.
Bambooi는 모든 수준에서 데이터 분석가의 기능을 강화하는 것을 목표로합니다. 데이터 분석 및 시각화를 단순화하여 워크 플로를 간소화하는 데 도움이됩니다. 이 라이브러리는 다양한 요구를 충족시키기 위해 사용자 친화적이고 효율적이며 적응할 수 있도록 설계되었습니다.
Google Colab에서 사용해보십시오.
제공된 데이터 프레임을 사용한 기계 학습 예 :
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyter 노트 :
작업 : 타이타닉에서 승객의 생존을 예측하기 위해 기계 학습 모델을 고안 해 주시겠습니까? 모델의 정확도를 출력하십시오. 혼란 매트릭스, 상관 행렬 및 기타 관련 메트릭을 플로팅하십시오. 이 작업에 대한 최상의 접근 방식을 위해 인터넷을 검색하십시오.
웹 UI :
작업 : 스포츠 데이터 분석과 관련된 다양한 쿼리
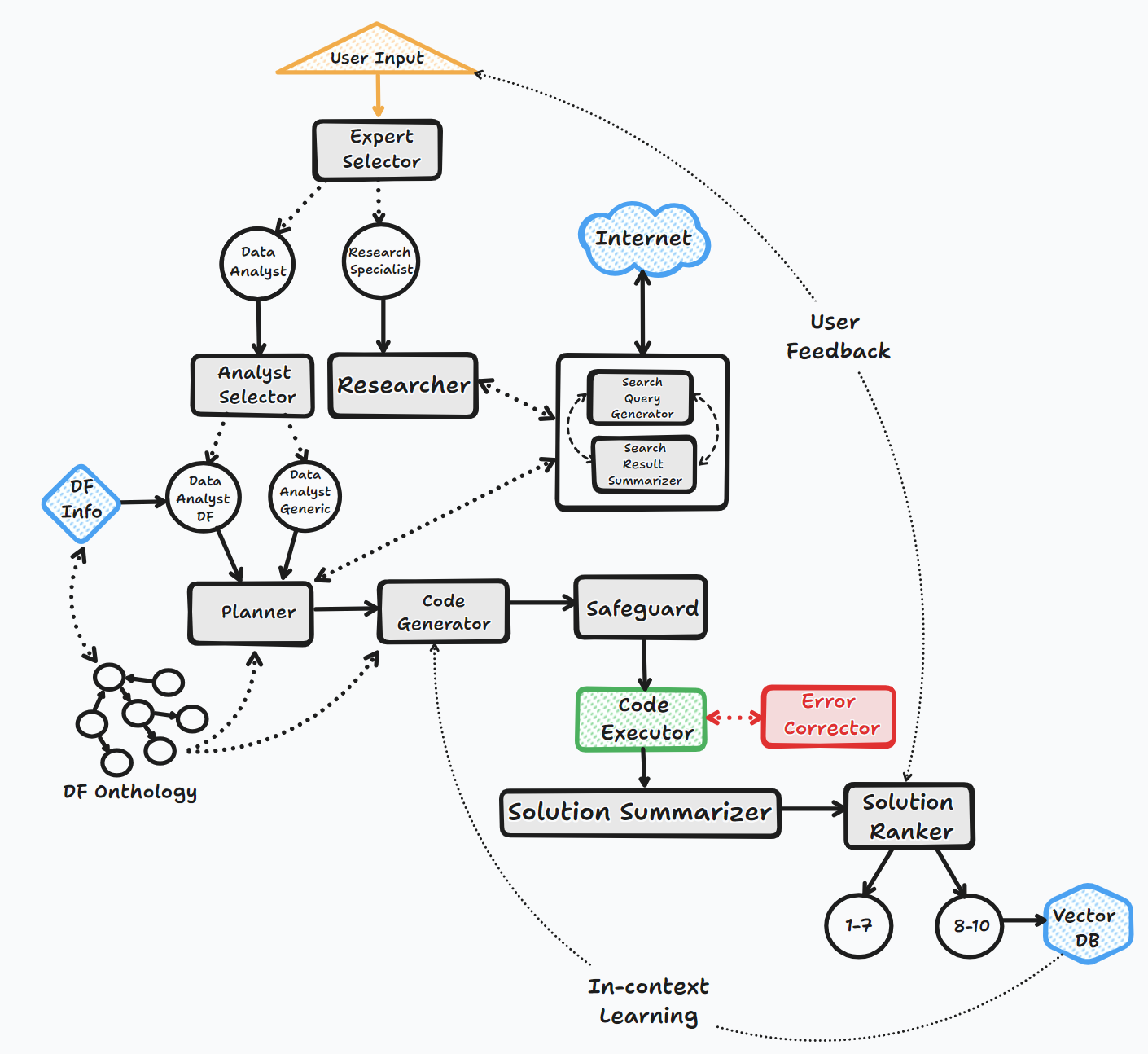
Bambooi Agent는 몇 가지 주요 단계를 통해 작동하여 사용자와 상호 작용하고 응답을 생성합니다.
1. 시작
2. 작업 평가
3. 동적 프롬프트 빌드
4. 디버깅, 실행 및 오류 수정
5. 결과, 순위 및 지식 기반 구축
6. 인간 피드백 및 루프 연속
이 프로세스를 통해 에이전트는 사용자 입력을 지속적으로 요청하고 컨텍스트를 위해 메시지를 저장하고 코드를 생성하고 실행하여 최적의 결과를 보장합니다. 이 프로세스에는 다양한 AI 모델과 벡터 데이터베이스가 사용되어 사용자의 질문에 대한 정확하고 유용한 응답을 제공합니다.
흐름도 (일반 에이전트 흐름) :
라이브러리는 API 또는 Localy를 통해 다양한 오픈 소스 또는 독점 모델의 사용을 지원합니다.
API :
현지의:
LLM_CONFIG 파일의 컨텐츠를 수정하여 기본 OpenAI 모델 이름을 선택의 모델 및 공급 업체로 대체하여 특정 에이전트에 사용할 공급 업체/모델을 지정할 수 있습니다. 예를 들어. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . LLM_CONFIG의 목적은 아래에 자세히 설명되어 있습니다.
설치
pip install bambooai
용법
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
감가 상각 통지 (2023 년 10 월 25 일) : "llm", "local_code_model", "llm_switch_plan"및 "llm_switch_code"매개 변수는 v 0.3.29 기준으로 더 이상 사용되지 않았습니다. 에이전트에 모델 및 모델 매개 변수의 할당은 이제 LLM_Config를 통해 처리됩니다. 이것은 작업 디렉토리의 환경 변수 또는 llm_config.json 파일을 통해 설정할 수 있습니다. 아래 세부 사항을 참조하십시오
에이전트 특정 LLM 구성은 LLM_CONFIG 환경 변수 또는 Bambooi의 작업 디렉토리에 저장 해야하는 "LLM_CONFIG.JSON 파일에 저장됩니다. 구성은 Dictionaries의 JSON 목록 형식이며 모델 이름, 공급자, 온도 및 MAX_TOKENS를 지정할 수 있습니다. 선호도를 반영하도록 구성을 수정하십시오. "Env var"나 "llm_config.json"이 존재하지 않으면 Bambooi는 모든 에이전트에 대해 "gpt-3.5-turbo"를 사용하는 기본 하드 코드 구성을 사용합니다.
Bambooi Library는 각 에이전트에 대한 기본 하드 코드 된 프롬프트 템플릿 세트를 사용합니다. 그들과 함께 실험하려면 제공된 "prompt_templates_sample.json"파일을 수정하고 "이름에서 _sample을 제거하고 작업 디렉토리에 저장할 수 있습니다. 그 후, 수정 된"prompt_templates.json "의 내용은 하드 코드 된 기본값 대신 항상 사용될 수 있습니다. "prompt_templates.json".
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
환경 변수
라이브러리에는 OpenAI API 계정과 API 키가 OpenAI LLMS에 연결해야합니다. OpenAI API 키는 OPENAI_API_KEY 환경 변수에 저장해야합니다. 키는 https://platform.openai.com/account/api-keys에서 얻을 수 있습니다.
OpenAI 모델 외에도 다양한 제공 업체의 모델이 지원됩니다 (Groq, Gemini, Mistral, Anthropic). API 키는 다음 형식 <VENDOR_NAME>_API_KEY 형식으로 환경 변수에 저장해야합니다. Google Gemini 모델에는 GEMINI_API_KEY 사용해야합니다.
위에서 언급했듯이 LLM 구성은 LLM_CONFIG 환경 변수의 문자열 형식으로 저장 될 수 있습니다. 제공된 LLM_CONFIG_SAMPE.JSON의 내용을 시작점으로 사용하고 액세스 할 수있는 모델에 따라 선호도를 수정할 수 있습니다.
Pincone 벡터 DB는 선택 사항입니다. 당신이 그것을 사용하고 싶지 않다면, 당신은 아무것도 할 필요가 없습니다. Pinecone이있는 계정이 있고 지식 기반 및 순위 기능을 사용하려면 PINECONE_API_KEY Envirooment 변수를 설정하고 'vector_db'매개 변수를 true로 설정해야합니다. 벡터 DB 인덱스는 첫 번째 실행시 생성됩니다.
Google 검색도 선택 사항입니다. 당신이 그것을 사용하고 싶지 않다면, 당신은 아무것도 할 필요가 없습니다. Serper와 계정이 있고 Google 검색 기능을 사용하려면 ": https://serper.dev/"로 설정하고 계정을 설정하고 SERPER_API_KEY 환경 변수를 설정하고 'Search_Tool'매개 변수를 true로 설정해야합니다. Bambooai는 기본적으로 HTML 컨텐츠로 웹 사이트 만 긁을 수 있습니다. 그러나 훨씬 더 강력한 Chromedriver와 함께 셀레늄을 사용할 수도 있습니다. 이 기능을 활성화하려면 Chrome 브라우저 버전과 일치하는 Chromedriver 버전을 수동으로 다운로드하고 파일 시스템에 저장하고 Chromedriver로가는 경로로 환경 변수 SELENIUM_WEBDRIVER_PATH 작성하십시오. Bambooaai는 자동적으로 집어 들고 모든 스크래핑 작업에 셀레늄을 사용합니다.
로컬 오픈 소스 모델
라이브러리는 현재 다음 오픈 소스 모델을 직접 지원합니다. 현재 HumaneVal 벤치 마크에서 가장 높은 점수를받는 모델을 선택했습니다.
특정 에이전트의 로컬 모델을 사용하려면 OpenAI 모델 이름을 로컬 모델 이름으로 대체하는 LLM_CONFIG 컨텐츠를 수정하고 제공자 값을 '로컬'으로 변경하십시오. 예를 들어. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} 현재 코드 생성 작업에만 지역 모델을 사용하는 것이 좋습니다. 선택의 여지가 있습니다. 이 모델은 후속 실행을 위해 Huggingface 및 Cached Localy에서 다운로드됩니다. 합리적인 성능을 얻으려면 CUDA가 활성화 된 GPU 및 CUDA 버전과 호환되는 Pytorch 라이브러리가 필요합니다. 아래는 패키지에 포함되지 않았으며 독립적으로 설치 해야하는 필수 라이브러리입니다.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
로컬 모델의 설정 및 매개 변수는 local_models.py 모듈에 있으며 특정 구성 또는 기본 설정에 맞게 조정할 수 있습니다.
올라마
도서관은 또한 Ollama https://ollama.com/의 사용 및 모든 모델의 사용을 지원합니다. 특정 에이전트에 로컬 Ollama 모델을 사용하려면 OpenAI 모델 이름을 Ollama 모델 이름으로 대체하는 LLM_CONFIG 컨텐츠를 수정하고 제공자 값을 'Ollama'로 변경하십시오. 예를 들어. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
벌채 반출
모든 LLM 상호 작용 (로컬 또는 API)은 bambooai_consolidated_log.json 파일에 로그인됩니다. 로그 파일의 크기가 5MB에 도달하면 새 로그 파일이 생성됩니다. 가장 오래된 파일을 덮어 쓰기 전에 총 3 개의 로그 파일이 파일 시스템에 보관됩니다.
다음 세부 사항이 캡처됩니다.
로그 구조 :
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
작업 : 타이타닉에서 승객의 생존을 예측하기 위해 기계 학습 모델을 고안하십시오. 출력에는 모델의 정확도 및 혼동 행렬의 시각화, 상관 매트릭스 및 기타 관련 메트릭이 포함되어야합니다.
데이터 세트 : Titanic.csv
모델 : GPT-4-TURBO
| 메트릭 | 값 |
|---|---|
| 실행 시간 | 77.12 초 |
| 입력 토큰 | 7128 |
| 출력 토큰 | 1215 |
| 총 비용 | $ 0.1077 |
| 메트릭 | 값 |
|---|---|
| 실행 시간 | 47.39 초 |
| 입력 토큰 | 722 |
| 출력 토큰 | 931 |
| 총 비용 | $ 0.0353 |
스포츠 데이터 분석을위한 AI 도구의 객관적인 평가 _ Maxwell-V2 vs. Generic LLMS.pdf
기부금을 환영합니다. 풀 요청을 자유롭게 열어주세요. 우리의 목표는 가독성이 높은 간결한 코드베이스를 유지하는 것입니다.


