BambooAI
v0.3.52
مكتبة خفيفة الوزن تستخدم نماذج لغوية كبيرة (LLMS) لتوفير إمكانات تفاعل اللغة الطبيعية ، مثل مساعد البحث وتحليل البيانات الذي يتيح المحادثة مع بياناتك. يمكنك إما توفير مجموعات البيانات الخاصة بك ، أو السماح للمكتبة بتحديد موقع البيانات لك وجلبها. وهو يدعم عمليات البحث عبر الإنترنت وتفاعلات API الخارجية.
مكتبة Bambooai هي أداة تجريبية وخفيفة تستخدم نماذج لغوية كبيرة (LLMS) لتسهيل تحليل البيانات ، مما يجعلها في متناول المستخدمين ، بما في ذلك أولئك الذين ليس لديهم خبرة في البرمجة. يعمل كمساعد للبحث وتحليل البيانات ، مما يسمح للمستخدمين بالتفاعل مع بياناتهم من خلال اللغة الطبيعية. يمكن للمستخدمين تزويد مجموعات البيانات الخاصة بهم أو يمكن أن تساعد Bambooai في تحديد مصادر البيانات اللازمة. تعمل الأداة أيضًا على دمج عمليات البحث على الإنترنت والوصول إلى واجهات برمجة التطبيقات الخارجية لتعزيز وظائفها.
تقوم Bambooai بمعالجة الاستعلامات اللغوية الطبيعية حول مجموعات البيانات ويمكنها إنشاء وتنفيذ رمز Python لتحليل البيانات وتصورها. وهذا يمكّن المستخدمين من استخلاص رؤى من بياناتهم دون معرفة ترميز واسعة النطاق. يقوم المستخدمون ببساطة بإدخال مجموعة البيانات الخاصة بهم ، وطرح الأسئلة باللغة الإنجليزية البسيطة ، ويوفر Bambooai الإجابات ، إلى جانب التصورات إذا لزم الأمر ، للمساعدة في فهم البيانات بشكل أفضل.
يهدف Bambooai إلى زيادة قدرات محللي البيانات عبر جميع المستويات. إنه يبسط تحليل البيانات وتصورها ، مما يساعد على تبسيط تدفقات العمل. تم تصميم المكتبة لتكون سهلة الاستخدام وفعالة وقابلة للتكيف لتلبية الاحتياجات المختلفة.
جربه في Google Colab:
مثال على التعلم الآلي باستخدام DataFrame الموردة:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
كمبيوتر محمول Jupyter:
المهمة: هل يمكنك وضع نموذج Learnig Machine من فضلك للتنبؤ ببقاء الركاب على Titanic؟ إخراج دقة النموذج. ارسم مصفوفة الارتباك ، مصفوفة الارتباط ، والمقاييس الأخرى ذات الصلة. ابحث عبر الإنترنت عن أفضل نهج لهذه المهمة.
واجهة المستخدم على الويب:
المهمة: استفسارات مختلفة تتعلق بتحليل البيانات الرياضية
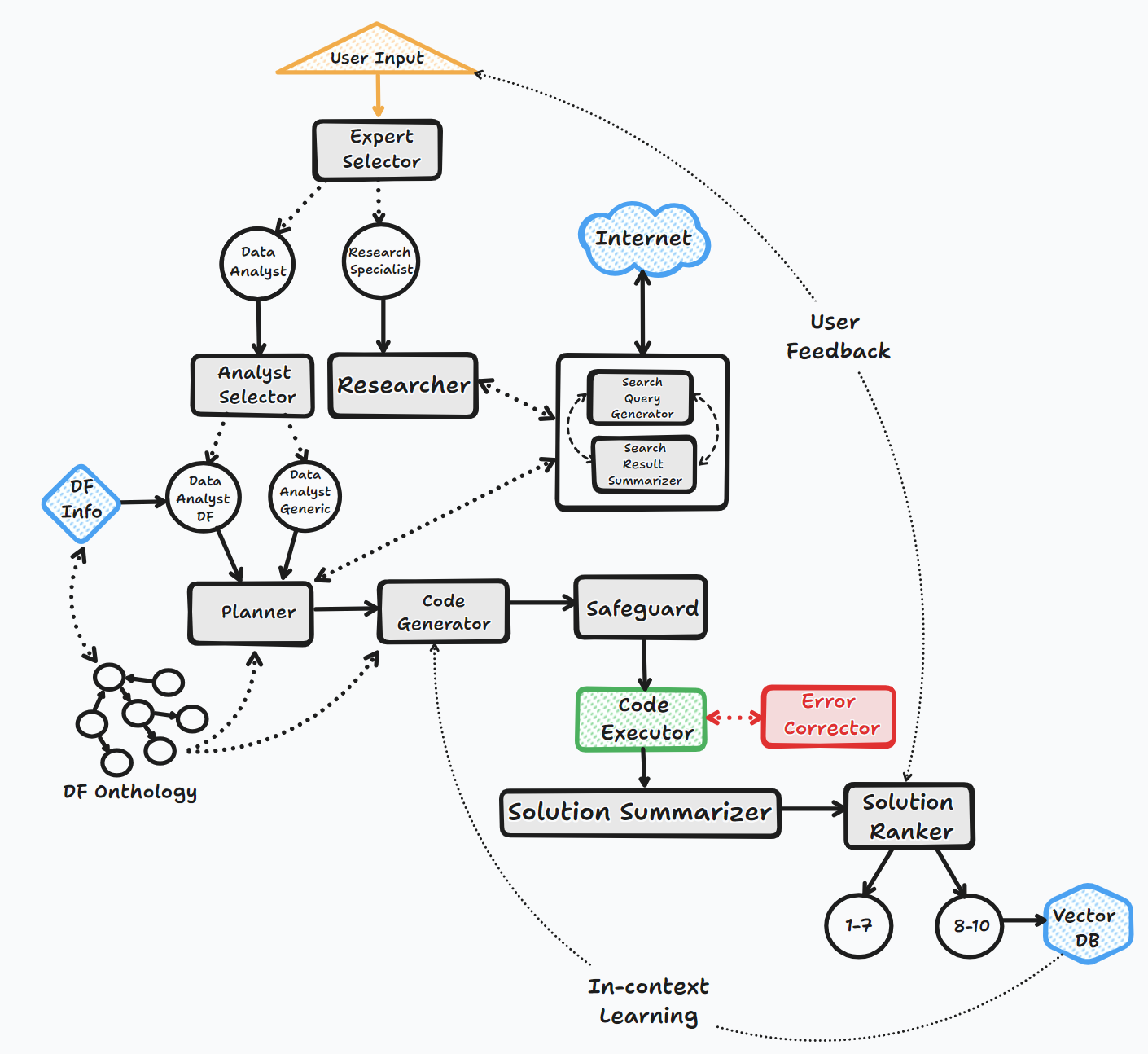
يعمل وكيل Bambooai من خلال عدة خطوات رئيسية للتفاعل مع المستخدمين وإنشاء الردود:
1. البدء
2. تقييم المهمة
3.
4. تصحيح الأخطاء والتنفيذ وتصحيح الخطأ
5. النتائج والترتيب وبناء قاعدة المعرفة
6. ردود الفعل البشرية واستمرار حلقة
خلال هذه العملية ، يطلب العامل إدخال المستخدم بشكل مستمر ، ويخزن الرسائل للسياق ، وينشئ وتنفيذ التعليمات البرمجية لضمان النتائج المثلى. يتم استخدام نماذج الذكاء الاصطناعى المختلفة وقاعدة بيانات المتجهات في هذه العملية لتوفير ردود دقيقة ومفيدة على أسئلة المستخدم.
مخطط التدفق (تدفق العامل العام):
تدعم المكتبة استخدام مختلف النماذج مفتوحة المصدر أو الملكية ، إما عن طريق API أو Localy.
API:
محلي:
يمكنك تحديد البائع/النموذج الذي تريد استخدامه لوكيل معين عن طريق تعديل محتوى ملف LLM_CONFIG ، واستبدال اسم طراز Openai الافتراضي مع النموذج والبائع الذي تختاره. على سبيل المثال. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . يتم وصف الغرض من LLM_CONFIG بمزيد من التفصيل أدناه.
تثبيت
pip install bambooai
الاستخدام
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
إشعار الإهمال (25 أكتوبر ، 2023): يرجى ملاحظة أن معلمات "LLM" و "LOCAL_CODE_MODEL" و "LLM_SWITCH_PLAN" و "LLM_SWITCH_CODE" تم إهمالها اعتبارًا من V 0.3.29. يتم الآن معالجة تعيين النماذج ومعلمات النموذج إلى الوكلاء عبر LLM_CONFIG. يمكن تعيين ذلك إما كمتغير للبيئة أو عبر ملف LLM_CONFIG.JSON في دليل العمل. يرجى الاطلاع على التفاصيل أدناه
يتم تخزين تكوين LLM المحدد للوكيل في متغير بيئة LLM_CONFIG ، أو في ملف "LLM_CONFIG.JSON الذي يجب تخزينه في دليل عمل Bambooai. التكوين لتعكس تفضيلاتك.
تستخدم مكتبة Bambooai مجموعة من القوالب المذهلة الافتراضية لكل وكيل. إذا كنت ترغب في تجربتها ، فيمكنك تعديل ملف "progred_templates_sample.json" ، قم بإزالة "_sample من اسمه وتخزينه في دليل العمل. في وقت لاحق ، سيتم استخدام محتوى" order_templates.json "المعدلة بدلاً من الافتراضات المتشددين.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
متغيرات البيئة
تتطلب المكتبة حساب Openai API ومفتاح API للاتصال بـ Openai LLMS. يجب تخزين مفتاح API Openai في متغير بيئة OPENAI_API_KEY . يمكن الحصول على المفتاح من هنا: https://platform.openai.com/account/api- keys.
بالإضافة إلى نماذج Openai ، يتم أيضًا دعم مجموعة مختارة من النماذج من مختلف مقدمي الخدمات (Groq ، Gemini ، Mistral ، Anthropic). يجب تخزين مفاتيح API في متغيرات البيئة بالتنسيق التالي <VENDOR_NAME>_API_KEY . تحتاج إلى استخدام GEMINI_API_KEY لنماذج Google Gemini.
كما ذكر أعلاه ، يمكن تخزين تكوين LLM بتنسيق سلسلة في متغير بيئة LLM_CONFIG . يمكنك استخدام محتوى LLM_CONFIG_SAMPLE.JSON المقدم كنقطة انطلاق وتعديله إلى تفضيلاتك ، اعتمادًا على النماذج التي يمكنك الوصول إليها.
PINCONE VECTOR DB اختياري. إذا كنت لا تريد استخدامه ، فلن تحتاج إلى فعل أي شيء. إذا كان لديك حساب مع Pinecone وترغب في استخدام قاعدة المعرفة وميزات الترتيب ، فسيتم مطالبتك بإعداد متغير PINECONE_API_KEY EnviRooment ، وتعيين المعلمة "Vector_DB" على TRUE. يتم إنشاء مؤشر DECTOR DB عند التنفيذ الأول.
بحث Google هو أيضًا اختياري. إذا كنت لا تريد استخدامه ، فلن تحتاج إلى فعل أي شيء. إذا كان لديك حساب مع Serper وترغب في استخدام وظيفة بحث Google ، فسيتم مطالبتك بإعداد وحساب ": https://serper.dev/" ، وتعيين متغير بيئة SERPER_API_KEY ، وتعيين معلمة "Search_Tool" على True. بشكل افتراضي ، لا يمكن لـ Bambooai سوى كشط المواقع ذات المحتوى HTML. ومع ذلك ، فهي قادرة أيضًا على استخدام السيلينيوم مع chromedriver ، وهو أكثر قوة بكثير. لتمكين هذه الوظيفة ، ستحتاج إلى تنزيل إصدار من chromedriver الذي يطابق نسختك من متصفح Chrome ، وتخزينه على نظام الملفات وإنشاء متغير البيئة SELENIUM_WEBDRIVER_PATH مع مسار إلى chromedriver الخاص بك. Bambooai ويل التقاطها التلقائي ، واستخدم السيلينيوم لجميع مهام الكشط.
نماذج المصادر المحلية المحلية
تدعم المكتبة حاليًا مباشرة النماذج التالية مفتوحة المصدر. لقد اخترت النماذج التي تسجل حاليًا أعلى مستوى في معيار Humaneval.
إذا كنت ترغب في استخدام النموذج المحلي لوكيل معين ، فقم بتعديل محتوى LLM_CONFIG باستبدال اسم طراز Openai باسم النموذج المحلي وتغيير قيمة المزود إلى "محلي". على سبيل المثال. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} نماذج Openai المفضلة. يتم تنزيل النموذج من Huggingface و inciced localy لعمليات الإعدام اللاحقة. للحصول على أداء معقول ، يتطلب GPU الممكّن من CUDA ومكتبة Pytorch متوافقة مع إصدار CUDA. فيما يلي المكتبات المطلوبة التي لم يتم تضمينها في الحزمة وستحتاج إلى تثبيتها بشكل مستقل:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
توجد إعدادات ومعلمات النماذج المحلية في وحدة Local_Models.py ويمكن ضبطها لتتناسب مع التكوين أو التفضيلات الخاصة بك.
أولاما
تدعم المكتبة أيضًا استخدام Ollama https://ollama.com/ وجميع الطرز. إذا كنت ترغب في استخدام نموذج Ollama المحلي لوكيل معين ، فقم بتعديل محتوى LLM_CONFIG لاستبدال اسم طراز Openai باسم Ollama Model وتغيير قيمة الموفر إلى "Ollama". على سبيل المثال. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
قطع الأشجار
يتم تسجيل جميع تفاعلات LLM (محلية أو عبر واجهات برمجة التطبيقات) في ملف bambooai_consolidated_log.json . عندما يصل حجم ملف السجل إلى 5 ميغابايت ، يتم إنشاء ملف سجل جديد. يتم الاحتفاظ بما مجموعه 3 ملفات سجل على نظام الملفات قبل الكتابة الأقدم.
يتم التقاط التفاصيل التالية:
هيكل السجل:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
المهمة: وضع نموذج التعلم الآلي للتنبؤ بقاء الركاب على تيتانيك. يجب أن يتضمن الإخراج دقة النموذج وتصورات مصفوفة الارتباك ، مصفوفة الارتباط ، والمقاييس الأخرى ذات الصلة.
مجموعة البيانات: titanic.csv
النموذج: GPT-4-TURBO
| متري | قيمة |
|---|---|
| وقت التنفيذ | 77.12 ثانية |
| إدخال الرموز | 7128 |
| الرموز الإخراج | 1215 |
| التكلفة الإجمالية | 0.1077 دولار |
| متري | قيمة |
|---|---|
| وقت التنفيذ | 47.39 ثانية |
| إدخال الرموز | 722 |
| الرموز الإخراج | 931 |
| التكلفة الإجمالية | 0.0353 دولار |
تقييم موضوعي لأدوات الذكاء الاصطناعى لتحليلات البيانات الرياضية
المساهمات موضع ترحيب. لا تتردد في فتح طلب سحب. ضع في اعتبارك أن هدفنا هو الحفاظ على قاعدة كود موجزة ذات قابلية عالية من القراءة.


