BambooAI
v0.3.52
ห้องสมุดที่มีน้ำหนักเบาใช้แบบจำลองภาษาขนาดใหญ่ (LLMs) เพื่อให้ความสามารถในการโต้ตอบภาษาธรรมชาติเช่นผู้ช่วยการวิจัยและการวิเคราะห์ข้อมูลที่เปิดใช้งานการสนทนากับข้อมูลของคุณ คุณสามารถให้ชุดข้อมูลของคุณเองหรืออนุญาตให้ไลบรารีค้นหาและดึงข้อมูลให้คุณ รองรับการค้นหาทางอินเทอร์เน็ตและการโต้ตอบ API ภายนอก
ห้องสมุด Bambooai เป็นเครื่องมือทดลองเบา ๆ ที่ใช้แบบจำลองภาษาขนาดใหญ่ (LLMs) เพื่ออำนวยความสะดวกในการวิเคราะห์ข้อมูลทำให้ผู้ใช้สามารถเข้าถึงได้มากขึ้นรวมถึงผู้ที่ไม่มีความเชี่ยวชาญด้านการเขียนโปรแกรม มันทำหน้าที่เป็นผู้ช่วยสำหรับการวิจัยและการวิเคราะห์ข้อมูลทำให้ผู้ใช้สามารถโต้ตอบกับข้อมูลของพวกเขาผ่านภาษาธรรมชาติ ผู้ใช้สามารถจัดหาชุดข้อมูลของตนเองหรือไผ่สามารถช่วยในการจัดหาข้อมูลที่จำเป็น เครื่องมือนี้ยังรวมการค้นหาทางอินเทอร์เน็ตและเข้าถึง API ภายนอกเพื่อปรับปรุงการทำงาน
Bamberai ประมวลผลแบบสอบถามภาษาธรรมชาติเกี่ยวกับชุดข้อมูลและสามารถสร้างและดำเนินการรหัส Python สำหรับการวิเคราะห์ข้อมูลและการสร้างภาพข้อมูล สิ่งนี้ช่วยให้ผู้ใช้ได้รับข้อมูลเชิงลึกจากข้อมูลของพวกเขาโดยไม่ต้องมีความรู้การเขียนโค้ดอย่างกว้างขวาง ผู้ใช้เพียงป้อนชุดข้อมูลของพวกเขาถามคำถามเป็นภาษาอังกฤษอย่างง่ายและไผ่ให้คำตอบพร้อมกับการสร้างภาพข้อมูลหากจำเป็นเพื่อช่วยให้เข้าใจข้อมูลได้ดีขึ้น
Bambooai มีจุดมุ่งหมายเพื่อเพิ่มความสามารถของนักวิเคราะห์ข้อมูลในทุกระดับ ช่วยลดความซับซ้อนของการวิเคราะห์ข้อมูลและการสร้างภาพข้อมูลช่วยปรับปรุงเวิร์กโฟลว์ ห้องสมุดได้รับการออกแบบให้ใช้งานง่ายมีประสิทธิภาพและปรับให้เข้ากับความต้องการที่หลากหลาย
ลองใช้ใน Google Colab:
ตัวอย่างการเรียนรู้ของเครื่องโดยใช้ DataFrame ที่ให้มา:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
สมุดบันทึก Jupyter:
ภารกิจ: คุณช่วยกำหนดรูปแบบการเรียนรู้ของเครื่องเพื่อทำนายความอยู่รอดของผู้โดยสารในไททานิคได้หรือไม่? ส่งออกความแม่นยำของโมเดล พล็อตเมทริกซ์ความสับสนเมทริกซ์สหสัมพันธ์และตัวชี้วัดอื่น ๆ ที่เกี่ยวข้อง ค้นหาอินเทอร์เน็ตเพื่อหาแนวทางที่ดีที่สุดสำหรับงานนี้
เว็บ UI:
ภารกิจ: คำถามต่าง ๆ ที่เกี่ยวข้องกับการวิเคราะห์ข้อมูลกีฬา
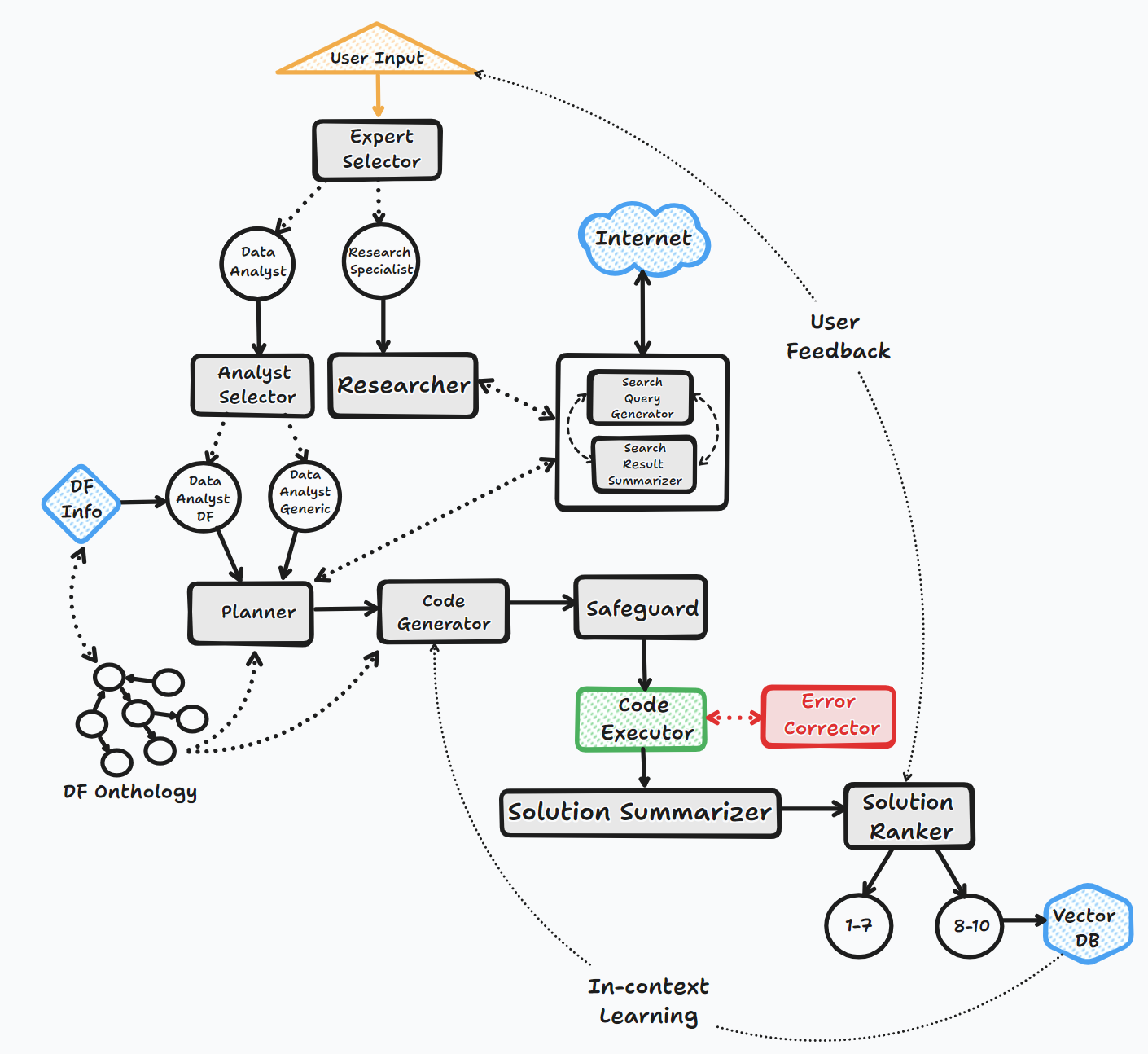
Agent Bambooai ดำเนินการผ่านขั้นตอนสำคัญหลายประการเพื่อโต้ตอบกับผู้ใช้และสร้างคำตอบ:
1. การเริ่มต้น
2. การประเมินผลงาน
3. การสร้างพรอมต์แบบไดนามิก
4. การดีบักการดำเนินการและการแก้ไขข้อผิดพลาด
5. ผลลัพธ์การจัดอันดับและการสร้างฐานความรู้
6. ข้อเสนอแนะของมนุษย์และความต่อเนื่องของลูป
ตลอดกระบวนการนี้เอเจนต์คัดค้านการป้อนข้อมูลของผู้ใช้อย่างต่อเนื่องจัดเก็บข้อความสำหรับบริบทและสร้างและดำเนินการรหัสเพื่อให้แน่ใจว่าผลลัพธ์ที่ดีที่สุด มีการใช้โมเดล AI และฐานข้อมูลเวกเตอร์ต่าง ๆ ในกระบวนการนี้เพื่อให้การตอบสนองที่ถูกต้องและเป็นประโยชน์ต่อคำถามของผู้ใช้
แผนภูมิการไหล (การไหลของตัวแทนทั่วไป):
ห้องสมุดรองรับการใช้แบบจำลองโอเพนซอร์สหรือโมเดลที่เป็นกรรมสิทธิ์ต่าง ๆ ไม่ว่าจะผ่าน API หรือ Localy
API:
ท้องถิ่น:
คุณสามารถระบุสิ่งที่ผู้ขาย/รุ่นที่คุณต้องการใช้สำหรับเอเจนต์เฉพาะโดยการแก้ไขเนื้อหาของไฟล์ LLM_CONFIG แทนที่ชื่อโมเดล OpenAI เริ่มต้นด้วยรุ่นและผู้ขายของตัวเลือกของคุณ เช่น {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} วัตถุประสงค์ของ LLM_CONFIG อธิบายไว้ในรายละเอียดเพิ่มเติมด้านล่าง
การติดตั้ง
pip install bambooai
การใช้งาน
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
ประกาศการเสื่อมราคา (25 ตุลาคม 2566): โปรดทราบว่า "LLM", "local_code_model", "llm_switch_plan" และ "LLM_SWITCH_CODE" พารามิเตอร์ "LLM_SWITCH_PLAN" และ "LLM_SWITCH_CODE" การกำหนดรูปแบบและพารามิเตอร์โมเดลให้กับตัวแทนได้รับการจัดการผ่าน LLM_Config สิ่งนี้สามารถตั้งค่าเป็นตัวแปรสภาพแวดล้อมหรือผ่านไฟล์ llm_config.json ในไดเรกทอรีการทำงาน โปรดดูรายละเอียดด้านล่าง
การกำหนดค่า LLM เฉพาะของตัวแทนจะถูกเก็บไว้ในตัวแปรสภาพแวดล้อม LLM_CONFIG หรือในไฟล์ "LLM_CONFIG.JSON ซึ่งจำเป็นต้องเก็บไว้ในไดเรกทอรีการทำงานของไผ่ เพื่อสะท้อนความต้องการของคุณ
ห้องสมุด Bambooai ใช้ชุดฮาร์ดโค้ดเริ่มต้นของเทมเพลตพร้อมใช้งานสำหรับแต่ละเอเจนต์ หากคุณต้องการทดลองกับพวกเขาคุณสามารถแก้ไขไฟล์ "prompt_templates_sample.json" ที่ให้ไว้ให้ลบ "_sample ออกจากชื่อและจัดเก็บในไดเรกทอรีการทำงานต่อมาเนื้อหาของ prompted_templates ที่แก้ไขแล้ว
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
ตัวแปรสภาพแวดล้อม
ห้องสมุดต้องใช้บัญชี OpenAI API และปุ่ม API เพื่อเชื่อมต่อกับ OpenAI LLMS คีย์ OpenAI API จะต้องเก็บไว้ในตัวแปรสภาพแวดล้อม OPENAI_API_KEY กุญแจสามารถรับได้จากที่นี่: https://platform.openai.com/account/api-keys
นอกจากนี้ยังรองรับโมเดล OpenAI แล้วยังมีการเลือกรุ่นจากผู้ให้บริการที่แตกต่างกัน (GROQ, Gemini, Mistral, มานุษยวิทยา) คีย์ API จะต้องเก็บไว้ในตัวแปรสภาพแวดล้อมในรูปแบบต่อไปนี้ <VENDOR_NAME>_API_KEY คุณต้องใช้ GEMINI_API_KEY สำหรับรุ่น Google Gemini
ดังที่ได้กล่าวมาแล้วการกำหนดค่า LLM สามารถเก็บไว้ในรูปแบบสตริงในตัวแปรสภาพแวดล้อม LLM_CONFIG คุณสามารถใช้เนื้อหาของ LLM_CONFIG_SAMPLE.JSON เป็นจุดเริ่มต้นและปรับเปลี่ยนตามความต้องการของคุณขึ้นอยู่กับรุ่นที่คุณเข้าถึง
DB เวกเตอร์ Pincone เป็นตัวเลือก หากคุณไม่ต้องการใช้มันคุณไม่จำเป็นต้องทำอะไรเลย หากคุณมีบัญชีที่มี pinecone และต้องการใช้ฐานความรู้และคุณสมบัติการจัดอันดับคุณจะต้องตั้งค่าตัวแปร PINECONE_API_KEY envirooment และตั้งค่าพารามิเตอร์ 'vector_db' เป็น TRUE ดัชนี DB เวกเตอร์ถูกสร้างขึ้นเมื่อดำเนินการครั้งแรก
การค้นหาของ Google ก็เป็นทางเลือก หากคุณไม่ต้องการใช้มันคุณไม่จำเป็นต้องทำอะไรเลย หากคุณมีบัญชีที่มี Serper และต้องการใช้ฟังก์ชั่นการค้นหาของ Google คุณจะต้องตั้งค่าและบัญชีด้วย ": https://serper.dev/" และตั้งค่าตัวแปรสภาพแวดล้อม SERPER_API_KEY และตั้งค่าพารามิเตอร์ 'Search_tool' เป็น TRUE โดยค่าเริ่มต้น Bamberai สามารถขูดเว็บไซต์ด้วยเนื้อหา HTML เท่านั้น อย่างไรก็ตามมันยังสามารถใช้ซีลีเนียมกับ Chromedriver ซึ่งมีประสิทธิภาพมากกว่า ในการเปิดใช้งานฟังก์ชั่นนี้คุณจะต้องดาวน์โหลด ChromeDriver เวอร์ชันที่ตรงกับเบราว์เซอร์ Chrome เวอร์ชันของคุณเก็บไว้ในระบบไฟล์และสร้างตัวแปรสภาพแวดล้อม SELENIUM_WEBDRIVER_PATH ด้วยเส้นทางไปยัง ChromedRiver ของคุณ ไผ่จะหยิบมันขึ้นมาโดยอัตโนมัติและใช้ซีลีเนียมสำหรับงานขูดทั้งหมด
รุ่นโอเพนซอร์สท้องถิ่น
ปัจจุบันห้องสมุดรองรับรุ่นโอเพนซอร์ซต่อไปนี้โดยตรง ฉันเลือกแบบจำลองที่มีคะแนนสูงสุดในเกณฑ์มาตรฐาน Humaneval
หากคุณต้องการใช้โมเดลท้องถิ่นสำหรับเอเจนต์เฉพาะให้แก้ไขเนื้อหา LLM_CONFIG แทนที่ชื่อโมเดล OpenAI ด้วยชื่อรุ่นท้องถิ่นและเปลี่ยนค่าผู้ให้บริการเป็น 'Local' เช่น {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} โมเดล OpenAI ทางเลือก โมเดลถูกดาวน์โหลดจาก HuggingFace และ Cacheed Localy สำหรับการประหารชีวิตครั้งต่อไป สำหรับประสิทธิภาพที่สมเหตุสมผลนั้นต้องใช้ GPU ที่เปิดใช้งาน CUDA และไลบรารี Pytorch ที่เข้ากันได้กับรุ่น CUDA ด้านล่างนี้เป็นไลบรารีที่จำเป็นซึ่งไม่รวมอยู่ในแพ็คเกจและจะต้องติดตั้งอย่างอิสระ:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
การตั้งค่าและพารามิเตอร์สำหรับโมเดลท้องถิ่นจะอยู่ในโมดูล local_models.py และสามารถปรับเพื่อให้ตรงกับการกำหนดค่าหรือการตั้งค่าเฉพาะของคุณ
โอลลา
ห้องสมุดยังรองรับการใช้ Ollama https://ollama.com/ และทุกรุ่น หากคุณต้องการใช้โมเดล Ollama ในเครื่องสำหรับเอเจนต์เฉพาะให้แก้ไขเนื้อหา LLM_CONFIG แทนที่ชื่อโมเดล OpenAI ด้วยชื่อโมเดล Ollama และเปลี่ยนค่าผู้ให้บริการเป็น 'Ollama' เช่น {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
การตัดไม้
การโต้ตอบ LLM ทั้งหมด (ท้องถิ่นหรือผ่าน APIs) จะถูกบันทึกไว้ในไฟล์ bambooai_consolidated_log.json เมื่อขนาดของไฟล์บันทึกถึง 5 MB ไฟล์บันทึกใหม่จะถูกสร้างขึ้น ไฟล์บันทึกทั้งหมด 3 ไฟล์จะถูกเก็บไว้ในระบบไฟล์ก่อนที่ไฟล์ที่เก่าที่สุดจะถูกเขียนทับ
รายละเอียดต่อไปนี้ถูกจับ:
โครงสร้างบันทึก:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
ภารกิจ: คิดค้นรูปแบบการเรียนรู้ของเครื่องเพื่อทำนายความอยู่รอดของผู้โดยสารในไททานิค ผลลัพธ์ควรรวมถึงความแม่นยำของแบบจำลองและการสร้างภาพข้อมูลของเมทริกซ์ความสับสนเมทริกซ์สหสัมพันธ์และตัวชี้วัดอื่น ๆ ที่เกี่ยวข้อง
ชุดข้อมูล: titanic.csv
รุ่น: GPT-4-turbo
| ตัวชี้วัด | ค่า |
|---|---|
| เวลาดำเนินการ | 77.12 วินาที |
| โทเค็นอินพุต | 7128 |
| โทเค็นเอาท์พุท | 1215 |
| ค่าใช้จ่ายทั้งหมด | $ 0.1077 |
| ตัวชี้วัด | ค่า |
|---|---|
| เวลาดำเนินการ | 47.39 วินาที |
| โทเค็นอินพุต | 722 |
| โทเค็นเอาท์พุท | 931 |
| ค่าใช้จ่ายทั้งหมด | $ 0.0353 |
การประเมินวัตถุประสงค์ของเครื่องมือ AI สำหรับการวิเคราะห์ข้อมูลกีฬา _ Maxwell-V2 กับ LLMS.pdf ทั่วไป
ยินดีต้อนรับการมีส่วนร่วม; โปรดอย่าลังเลที่จะเปิดคำขอดึง โปรดทราบว่าเป้าหมายของเราคือการรักษา codebase ที่กระชับด้วยความสามารถในการอ่านสูง


