BambooAI
v0.3.52
Eine leichte Bibliothek, die große Sprachmodelle (LLMs) verwendet, um Interaktionsfunktionen für natürliche Sprache bereitzustellen, ähnlich wie ein Forschungs- und Datenanalyse -Assistent, der Konversation mit Ihren Daten ermöglicht. Sie können entweder Ihre eigenen Datensätze bereitstellen oder der Bibliothek erlauben, Daten für Sie zu finden und zu holen. Es unterstützt Internetsuche und externe API -Interaktionen.
Die Bambooai -Bibliothek ist ein experimentelles, lichtwiegiges Tool, das große Sprachmodelle (LLMs) verwendet, um die Datenanalyse zu erleichtern, wodurch sie für Benutzer, einschließlich derjenigen ohne Programmierkompetenz, zugänglicher wird. Es fungiert als Assistent für Forschungs- und Datenanalysen, sodass Benutzer über natürliche Sprache mit ihren Daten interagieren können. Benutzer können ihre eigenen Datensätze liefern, oder Bambooai können bei der Beschaffung der erforderlichen Daten behilflich sein. Das Tool integriert auch Internetsuche und greift auf externe APIs auf, um seine Funktionalität zu verbessern.
Bambooai verarbeitet natürliche Sprachabfragen zu Datensätzen und kann Python -Code für die Datenanalyse und Visualisierung generieren und ausführen. Auf diese Weise können Benutzer Erkenntnisse aus ihren Daten ohne umfangreiche Codierungskenntnisse abgeben. Benutzer geben einfach ihren Datensatz ein, stellen Fragen in einfachem Englisch, und Bambooai bietet die Antworten sowie visualisierungen, falls erforderlich, um die Daten besser zu verstehen.
Bambooai zielt darauf ab, die Funktionen von Datenanalysten auf allen Ebenen zu erweitern. Es vereinfacht die Datenanalyse und Visualisierung und hilft bei der Straffung von Workflows. Die Bibliothek ist so konzipiert, dass sie benutzerfreundlich, effizient und anpassungsfähig sind, um verschiedene Anforderungen zu erfüllen.
Probieren Sie es in Google Colab aus:
Ein Beispiel für maschinelles Lernen unter Verwendung des angegebenen Datenframees:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyter Notebook:
Aufgabe: Können Sie bitte ein maschinelles Lernmodell entwickeln, um das Überleben von Passagieren auf der Titanic vorherzusagen? Die Genauigkeit des Modells ausgeben. Zeichnen Sie die Verwirrungsmatrix, die Korrelationsmatrix und andere relevante Metriken. Suchen Sie das Internet nach dem besten Ansatz für diese Aufgabe.
Web -Benutzeroberfläche:
Aufgabe: Verschiedene Abfragen in Bezug auf Sportdatenanalysen
Der Bambooai -Agent arbeitet durch mehrere wichtige Schritte, um mit Benutzern zu interagieren und Antworten zu generieren:
1. Initiierung
2. Aufgabenbewertung
3.. Dynamische Eingabeaufforderung Build
4. Debugging, Ausführung und Fehlerkorrektur
5. Ergebnisse, Ranking und Wissensbasisbau
6. menschliches Feedback und Loop Fortsetzung
Während dieses Prozesses bittet der Agent kontinuierlich die Benutzereingabe, speichert Nachrichten für den Kontext und generiert und führt Code aus, um optimale Ergebnisse zu gewährleisten. In diesem Prozess werden verschiedene KI -Modelle und eine Vektordatenbank verwendet, um genaue und hilfreiche Antworten auf die Fragen des Benutzers zu liefern.
Flussdiagramm (General Agent Flow):
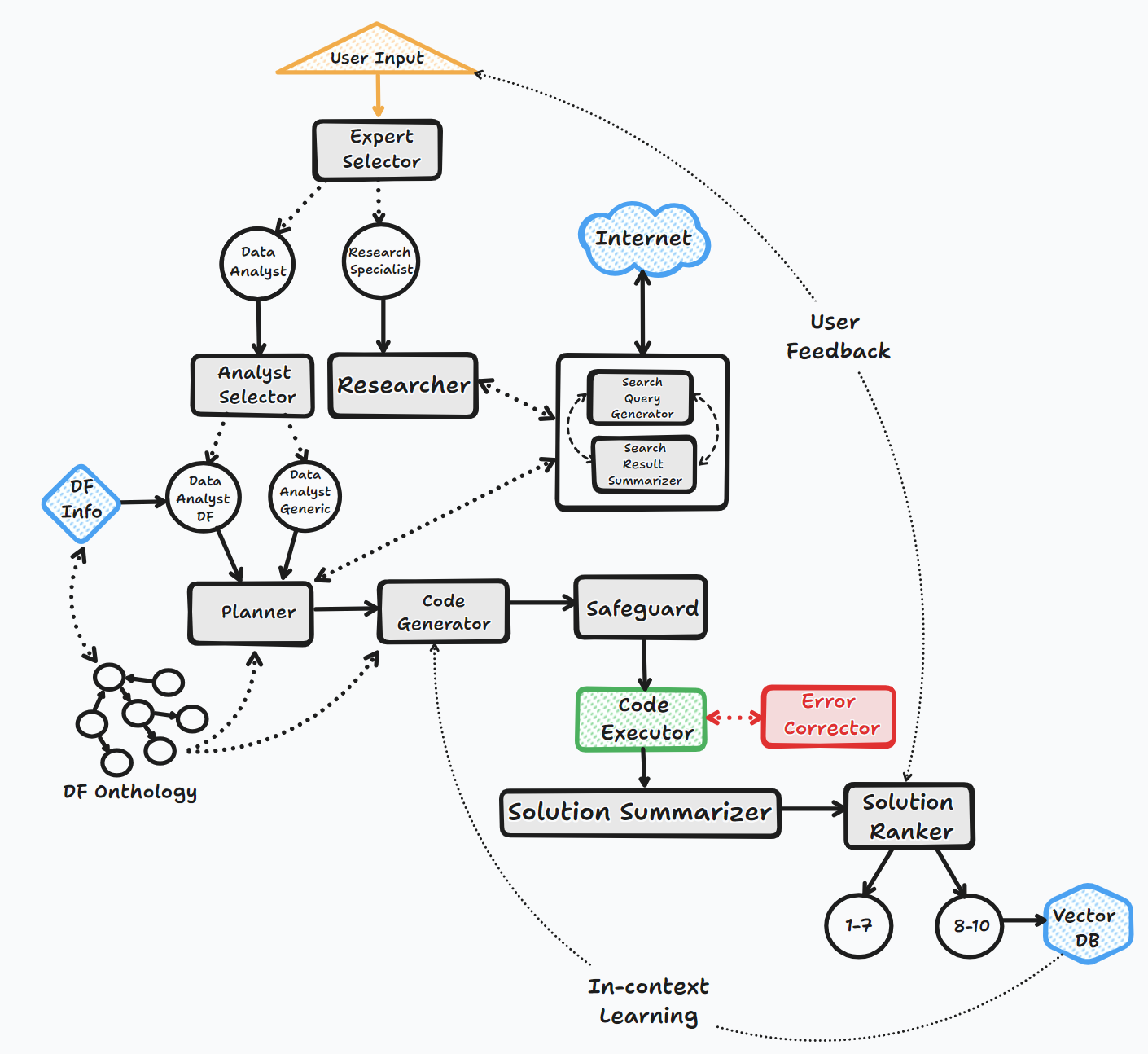
Die Bibliothek unterstützt die Verwendung verschiedener Open Source- oder Proprietary -Modelle, entweder über API oder lokal.
API:
Lokal:
Sie können angeben, welchen Anbieter/Modell Sie für einen bestimmten Agenten verwenden möchten, indem Sie den Inhalt der LLM_CONFIG -Datei ändern und den Standard -OpenAI -Modellnamen durch das Modell und den Anbieter Ihrer Wahl ersetzen. z.B. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . Der Zweck von llm_config wird nachstehend ausführlicher beschrieben.
Installation
pip install bambooai
Verwendung
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
Abschreibungsbescheid (25. Oktober 2023): Bitte beachten Sie, dass die Parameter "LLM", "local_code_model", "llm_switch_plan" und "llm_switch_code" ab V 0.3.29 veraltet wurden. Die Zuordnung von Modellen und Modellparametern zu Agenten wird nun über LLM_CONfig behandelt. Dies kann entweder als Umgebungsvariable oder über eine llm_config.json -Datei im Arbeitsverzeichnis festgelegt werden. Bitte beachten Sie die Details unten
Die agentenspezifische LLM -Konfiguration wird in LLM_CONFIG -Umgebungsvariable oder in der Datei "llm_config.json" gespeichert, die in der Arbeitsverzeichnis des Bambooai gespeichert werden muss. Die Konfiguration besteht aus einer Form von JSON -Liste von JSON -Liste von Wechselkörpern. Die Konfiguration, um Ihre Einstellungen widerzuspiegeln.
Die Bambooai -Bibliothek verwendet für jeden Agenten einen standardmäßigen festcodierten Satz von Eingabeaufforderungen. Wenn Sie mit ihnen experimentieren möchten, können Sie die angegebene Datei "prompt_templates_sample.json" ändern, die "_Sample aus seinem Namen speichern und im Arbeitsverzeichnis speichern. Anschließend wird der Inhalt der modifizierten" Eingabeaufforderung.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Umgebungsvariablen
Die Bibliothek benötigt ein OpenAI -API -Konto und die API -Schlüssel, um eine Verbindung zu OpenAI LLMs herzustellen. Der OpenAI -API -Schlüssel muss in einer Umgebungsvariablen OPENAI_API_KEY gespeichert werden. Der Schlüssel kann von hier erhalten werden: https://platform.openai.com/account/api-keys.
Zusätzlich zu OpenAI -Modellen wird auch eine Auswahl von Modellen aus verschiedenen Anbietern unterstützt (GROQ, GEMINI, MISTRAL, Anthropic). Die API -Tasten müssen in <VENDOR_NAME>_API_KEY im folgenden Format gespeichert werden. Sie müssen GEMINI_API_KEY für Google Gemini -Modelle verwenden.
Wie oben erwähnt, kann die LLM -Konfiguration in einem String -Format in der Umgebungsvariablen LLM_CONFIG gespeichert werden. Sie können den Inhalt des bereitgestellten llm_config_sample.json als Ausgangspunkt verwenden und Ihre Präferenz ändern, je nachdem, auf welche Modelle Sie zugreifen können.
Der Pincone -Vektor DB ist optional. Wenn Sie es nicht verwenden möchten, müssen Sie nichts tun. Wenn Sie ein Konto mit PineCone haben und die Knowledge Base und die Ranking -Funktionen verwenden möchten, müssen Sie die Umweltvariable PINECONE_API_KEY einrichten und den Parameter 'Vector_DB' auf True festlegen. Der Vektor -DB -Index wird bei der ersten Ausführung erstellt.
Die Google -Suche ist ebenfalls optional. Wenn Sie es nicht verwenden möchten, müssen Sie nichts tun. Wenn Sie ein Konto mit Serper haben und die Google -Suchfunktionen verwenden möchten, müssen Sie mit ": https://serper.dev/" einrichten und Konto einstellen und die Umgebungsvariable SERPER_API_KEY festlegen und den Parameter 'Search_tool' auf True festlegen. Standardmäßig kann Bambooai nur Websites mit HTML -Inhalten kratzen. Es ist jedoch auch in der Lage, Selen mit Chromedriver zu verwenden, was viel stärker ist. Um diese Funktionalität zu ermöglichen, müssen Sie eine Version von Chromedriver manuell herunterladen, die Ihrer Version des Chrome -Browsers entspricht, sie auf dem Dateisystem speichern und eine Umgebungsvariable SELENIUM_WEBDRIVER_PATH mit einem Pfad zu Ihrem Chromedriver erstellen. Bambooai wird es automatisch aufnehmen und Selen für alle Schablonen -Aufgaben verwenden.
Lokale Open Source -Modelle
Die Bibliothek unterstützt derzeit die folgenden Open-Source-Modelle direkt. Ich habe die Modelle ausgewählt, die derzeit am höchsten auf dem Humaner -Benchmark erzielt werden.
Wenn Sie das lokale Modell für einen bestimmten Agenten verwenden möchten, ändern Sie den Inhalt von LLM_CONFIG, der den OpenAI -Modellnamen durch den lokalen Modellnamen ersetzt und den Anbieterwert in "Lokal" ändern. z.B. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} Gegenwärtig ist es empfohlen, lokale Modelle nur für Code-Generierung zu verwenden, und andere Aufgaben, die von anderen Aufgaben zu stilllingen, summieren. OpenAI -Modelle der Wahl. Das Modell wird von Huggingface und Cached Localy für nachfolgende Ausführungen heruntergeladen. Für eine angemessene Leistung erfordert die CUDA -fähige GPU und die mit der CUDA -Version kompatibele Pytorch -Bibliothek. Im Folgenden finden Sie die erforderlichen Bibliotheken, die nicht im Paket enthalten sind und unabhängig installiert werden müssen:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
Die Einstellungen und Parameter für lokale Modelle befinden sich im Modul local_models.py und können so eingestellt werden, dass sie Ihren bestimmten Konfigurationen oder Einstellungen entsprechen.
Ollama
Die Bibliothek unterstützt auch die Verwendung von Ollama https://ollama.com/ und all seinen Modellen. Wenn Sie ein lokales OLLAMA -Modell für einen bestimmten Agenten verwenden möchten, ändern Sie den Inhalt von LLM_CONF, der den OpenAI -Modellnamen durch den OLLAMA -Modellnamen ersetzt und den Anbieterwert in "Ollama" ändern. z.B. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Protokollierung
Alle LLM -Interaktionen (lokal oder über APIs) sind in der Datei bambooai_consolidated_log.json protokolliert. Wenn die Größe der Protokolldatei 5 MB erreicht, wird eine neue Protokolldatei erstellt. Insgesamt 3 Protokolldateien werden im Dateisystem aufbewahrt, bevor die älteste Datei überschrieben wird.
Die folgenden Details werden erfasst:
Protokollstruktur:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Aufgabe: Entwickeln Sie ein maschinelles Lernmodell, um das Überleben von Passagieren auf der Titanic vorherzusagen. Die Ausgabe sollte die Genauigkeit des Modells und die Visualisierungen der Verwirrungsmatrix, die Korrelationsmatrix und andere relevante Metriken umfassen.
Datensatz: titanic.csv
Modell: GPT-4-Turbo
| Metrisch | Wert |
|---|---|
| Ausführungszeit | 77,12 Sekunden |
| Eingangs -Token | 7128 |
| Ausgangstoken | 1215 |
| Gesamtkosten | $ 0,1077 |
| Metrisch | Wert |
|---|---|
| Ausführungszeit | 47,39 Sekunden |
| Eingangs -Token | 722 |
| Ausgangstoken | 931 |
| Gesamtkosten | $ 0,0353 |
Objektive Bewertung von KI-Tools für Sportdatenanalytics_ Maxwell-V2 im Vergleich zu generischen LLMs.pdf
Beiträge sind willkommen; Bitte öffnen Sie eine Pull -Anfrage. Denken Sie daran, dass unser Ziel darin besteht, eine kurze Codebasis mit hoher Lesbarkeit aufrechtzuerhalten.


