BambooAI
v0.3.52
Une bibliothèque légère utilisant des modèles de grande langue (LLM) pour fournir des capacités d'interaction en langage naturel, un peu comme un assistant de recherche et d'analyse de données permettant une conversation avec vos données. Vous pouvez soit fournir vos propres ensembles de données, soit permettre à la bibliothèque de localiser et de récupérer des données pour vous. Il prend en charge les recherches sur Internet et les interactions API externes.
La bibliothèque Bambooai est un outil expérimental et LightWeigh qui utilise des modèles de langues importants (LLM) pour faciliter l'analyse des données, ce qui la rend plus accessible aux utilisateurs, y compris celles sans expertise en programmation. Il fonctionne comme un assistant pour la recherche et l'analyse des données, permettant aux utilisateurs d'interagir avec leurs données par le langage naturel. Les utilisateurs peuvent fournir leurs propres ensembles de données ou Bambooai peut aider à s'approvisionner les données nécessaires. L'outil intègre également les recherches sur Internet et accède aux API externes pour améliorer sa fonctionnalité.
Bambooai traite les requêtes en langage naturel sur les ensembles de données et peut générer et exécuter le code Python pour l'analyse et la visualisation des données. Cela permet aux utilisateurs de dériver des informations de leurs données sans connaissances approfondies. Les utilisateurs saisissent simplement leur ensemble de données, posent des questions en anglais simple, et Bambooai fournit les réponses, ainsi que des visualisations si nécessaire, pour mieux comprendre les données.
Bambooai vise à augmenter les capacités des analystes de données à tous les niveaux. Il simplifie l'analyse et la visualisation des données, contribuant à rationaliser les workflows. La bibliothèque est conçue pour être conviviale, efficace et adaptable pour répondre à divers besoins.
Essayez-le dans Google Colab:
Un exemple d'apprentissage automatique à l'aide de DataFrame fourni:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Cahier Jupyter:
Tâche: pouvez-vous s'il vous plaît concevoir un modèle d'apprentissage machine pour prédire la survie des passagers sur le Titanic? Sortir la précision du modèle. Tracez la matrice de confusion, la matrice de corrélation et d'autres mesures pertinentes. Recherchez Internet la meilleure approche de cette tâche.
UI Web:
Tâche: diverses requêtes liées à l'analyse des données sportives
L'agent Bambooai fonctionne à travers plusieurs étapes clés pour interagir avec les utilisateurs et générer des réponses:
1. Initiation
2. Évaluation des tâches
3. Bâtiment invite dynamique
4. Débogage, exécution et correction d'erreur
5. Résultats, classement et construction de la base de connaissances
6. Rétroaction humaine et continuation de boucle
Tout au long de ce processus, l'agent sollicite continuellement la saisie de l'utilisateur, stocke les messages pour le contexte et génère et exécute du code pour garantir des résultats optimaux. Divers modèles d'IA et une base de données vectorielle sont utilisés dans ce processus pour fournir des réponses précises et utiles aux questions de l'utilisateur.
Tableau d'écoulement (flux général d'agent):
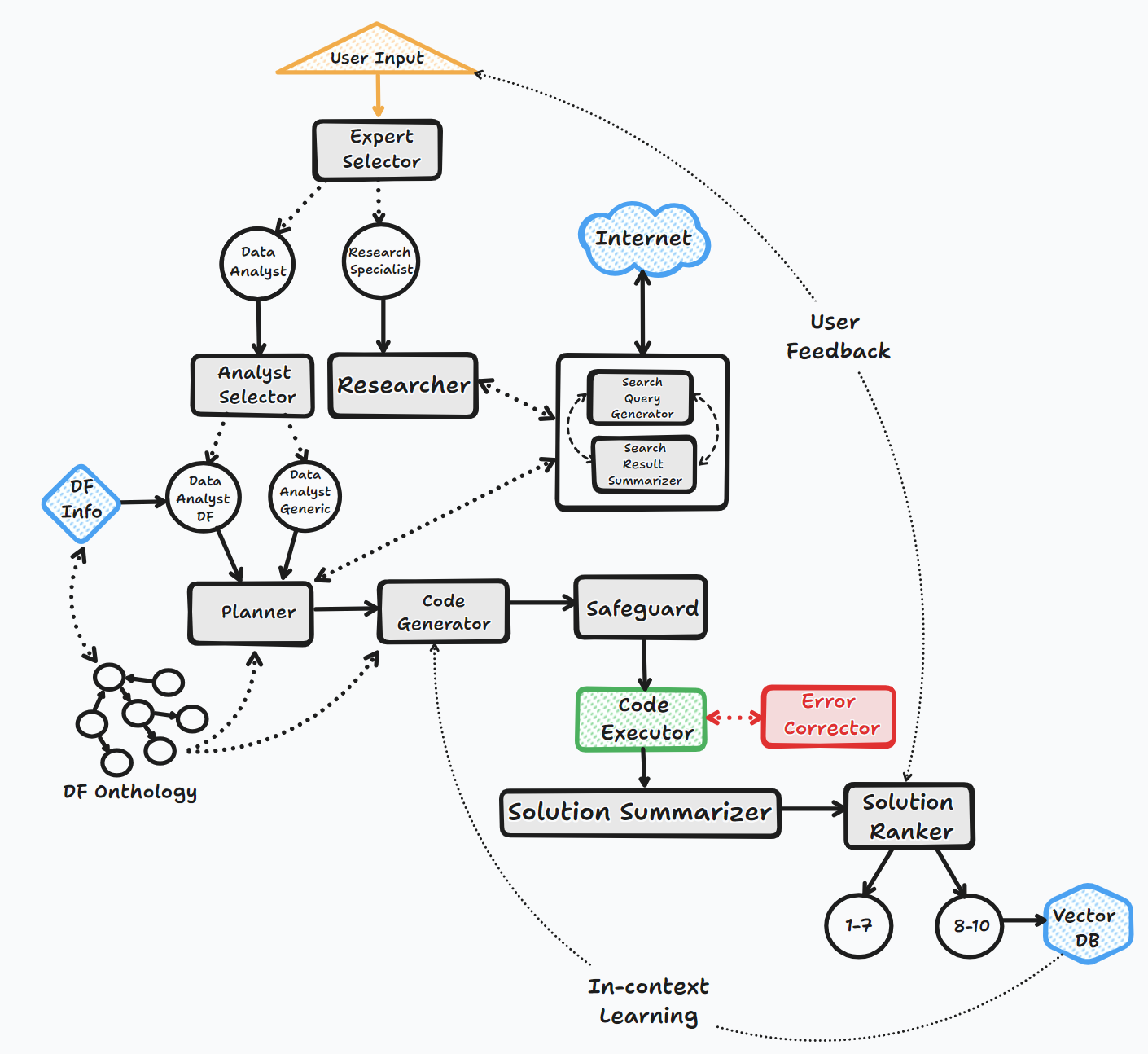
La bibliothèque prend en charge l'utilisation de divers modèles open source ou propriétaires, via l'API ou la location.
API:
Locale:
Vous pouvez spécifier le fournisseur / modèle que vous souhaitez utiliser pour un agent spécifique en modifiant le contenu du fichier LLM_Config, en remplaçant le nom du modèle OpenAI par défaut par le modèle et le fournisseur de votre choix. par exemple, par exemple {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . Le but de LLM_Config est décrit plus en détail ci-dessous.
Installation
pip install bambooai
Usage
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
Avis de dépréciation (25 octobre 2023): Veuillez noter que le "llm", "local_code_model", "llm_switch_plan" et "llm_switch_code" Les paramètres ont été dépréciés en tant que V 0.3.29. L'attribution des modèles et des paramètres du modèle aux agents est désormais gérée via LLM_Config. Cela peut être défini soit en tant que variable d'environnement, soit via un fichier llm_config.json dans le répertoire de travail. Veuillez consulter les détails ci-dessous
La configuration LLM spécifique de l'agent est stockée dans la variable d'environnement LLM_CONFIG , ou dans le fichier "llm_config.json qui doit être stocké dans le répertoire de travail du bambouai. La configuration est sous une forme de liste JSON de dictionnaires et spécifie le nom du modèle, le fournisseur, la température et le maximum pour chaque agent. La configuration pour refléter vos préférences.
La bibliothèque Bambooai utilise un ensemble de modèles d'invite codé par défaut par défaut pour chaque agent. Si vous souhaitez expérimenter avec eux, vous pouvez modifier le fichier "invite_template_sample.json", supprimez le "_Sample de son nom et de son stockage dans le répertoire de travail. Par la suite, le contenu de l'invite instant_Template.json" modifié est utilisé à la place de l'invite modifiée.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Variables d'environnement
La bibliothèque nécessite un compte API OpenAI et la touche API pour se connecter à OpenAI LLMS. La touche API OpenAI doit être stockée dans une variable d'environnement OPENAI_API_KEY . La clé peut être obtenue à partir d'ici: https://platform.openai.com/Account/API-Keys.
En plus des modèles OpenAI, une sélection de modèles de différents fournisseurs est également prise en charge (Groq, Gemini, Mistral, anthropic). Les touches API doivent être stockées dans les variables d'environnement au format suivant <VENDOR_NAME>_API_KEY . Vous devez utiliser GEMINI_API_KEY pour les modèles Google Gemini.
Comme mentionné ci-dessus, la configuration LLM peut être stockée dans un format de chaîne dans la variable d'environnement LLM_CONFIG . Vous pouvez utiliser le contenu du LLM_Config_sample.json fourni comme point de départ et modifiez votre préférence, selon les modèles auxquels vous avez accès.
La DB du vecteur Pincone est facultative. Si vous ne voulez pas l'utiliser, vous n'avez rien à faire. Si vous avez un compte avec PineCone et que vous souhaitez utiliser la base de connaissances et les fonctionnalités de classement, vous devrez configurer PINECONE_API_KEY ENVIROOMENT Variable, et définir le paramètre 'Vector_DB' sur true. L'indice DB vectoriel est créé lors de la première exécution.
La recherche Google est également facultative. Si vous ne voulez pas l'utiliser, vous n'avez rien à faire. Si vous avez un compte avec Serper et que vous souhaitez utiliser la fonctionnalité de recherche Google, vous devrez configurer et rendre compte avec ": https://serper.dev/", et définir la variable d'environnement SERPER_API_KEY et définir le paramètre 'search_tool' sur true. Par défaut, Bambooai ne peut gratter que les sites Web avec du contenu HTML. Cependant, il est également capable d'utiliser du sélénium avec Chromedriver, qui est beaucoup plus puissant. Pour activer cette fonctionnalité, vous devrez télécharger une version de ChromEdriver qui correspond à votre version du navigateur Chrome, stocker sur le système de fichiers et créer une variable d'environnement SELENIUM_WEBDRIVER_PATH avec un chemin vers votre ChromEdriver. Bambooai le ramassera automatiquement et utilise le sélénium pour toutes les tâches de grattage.
Modèles open source locaux
La bibliothèque prend actuellement en charge directement les modèles open source suivants. J'ai sélectionné les modèles qui marquent actuellement le plus haut sur la référence Humaneval.
Si vous souhaitez utiliser le modèle local pour un agent spécifique, modifiez le contenu LLM_Config en remplaçant le nom du modèle OpenAI par le nom du modèle local et modifiez la valeur du fournisseur en «local». par exemple, par exemple {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} À l'heure actuelle, il est recommandé d'utiliser unique Modèles Openai de choix. Le modèle est téléchargé à partir de HuggingFace et Cached Localy pour les exécutions ultérieures. Pour une performance raisonnable, il nécessite GPU compatible CUDA et la bibliothèque Pytorch compatible avec la version CUDA. Vous trouverez ci-dessous les bibliothèques requises qui ne sont pas incluses dans le package et devront être installées indépendamment:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
Les paramètres et paramètres des modèles locaux sont situés dans le module local_models.py et peuvent être ajustés pour correspondre à votre configuration ou préférences particulières.
Ollla
La bibliothèque prend également en charge l'utilisation de Olllama https://ollama.com/ et tous ses modèles. Si vous souhaitez utiliser un modèle Olllama local pour un agent spécifique, modifiez le contenu LLM_Config en remplaçant le nom du modèle OpenAI par le nom du modèle Olllama et modifiez la valeur du fournisseur en «olllama». par exemple, par exemple {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Enregistrement
Toutes les interactions LLM (locales ou via API) sont enregistrées dans le fichier bambooai_consolidated_log.json . Lorsque la taille du fichier journal atteint 5 Mo, un nouveau fichier journal est créé. Un total de 3 fichiers journaux sont conservés sur le système de fichiers avant que le fichier le plus ancien ne soit remplacé.
Les détails suivants sont capturés:
Structure du journal:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Tâche: concevoir un modèle d'apprentissage automatique pour prédire la survie des passagers sur le Titanic. La sortie doit inclure la précision du modèle et les visualisations de la matrice de confusion, la matrice de corrélation et d'autres mesures pertinentes.
Ensemble de données: titanic.csv
Modèle: GPT-4-turbo
| Métrique | Valeur |
|---|---|
| Temps d'exécution | 77,12 secondes |
| Jetons d'entrée | 7128 |
| Jetons de sortie | 1215 |
| Coût total | 0,1077 $ |
| Métrique | Valeur |
|---|---|
| Temps d'exécution | 47,39 secondes |
| Jetons d'entrée | 722 |
| Jetons de sortie | 931 |
| Coût total | 0,0353 $ |
Évaluation objective des outils d'IA pour l'analyse des données sportives_ Maxwell-V2 vs Generic Llms.pdf
Les contributions sont les bienvenues; N'hésitez pas à ouvrir une demande de traction. Gardez à l'esprit que notre objectif est de maintenir une base de code concise avec une grande lisibilité.


