BambooAI
v0.3.52
大規模な言語モデル(LLM)を利用して、データとの会話を可能にする研究およびデータ分析アシスタントのように、自然言語の相互作用機能を提供する軽量ライブラリ。独自のデータセットを提供するか、ライブラリがデータを見つけてフェッチできるようにすることができます。インターネット検索と外部APIインタラクションをサポートします。
Bambooaiライブラリは、データ分析を容易にするために大規模な言語モデル(LLM)を利用する実験的で軽量なツールであり、プログラミングの専門知識を含むユーザーがよりアクセスしやすくします。これは、研究およびデータ分析のアシスタントとして機能し、ユーザーが自然言語を介してデータと対話できるようにします。ユーザーは独自のデータセットを提供することができます。また、このツールはインターネット検索を統合し、外部APIにアクセスして機能を強化します。
Bambooaiは、データセットに関する自然言語クエリを処理し、データ分析と視覚化のためにPythonコードを生成および実行できます。これにより、ユーザーは広範なコーディング知識なしにデータから洞察を導き出すことができます。ユーザーはデータセットを入力し、単純な英語で質問をするだけで、Bambooaiはデータをよりよく理解するために、必要に応じて視覚化とともに回答を提供します。
Bambooaiは、あらゆるレベルでデータアナリストの機能を強化することを目指しています。データ分析と視覚化を簡素化し、ワークフローの合理化に役立ちます。ライブラリは、さまざまなニーズを満たすためにユーザーフレンドリーで効率的で、適応性があるように設計されています。
Google Colabで試してみてください:
提供されたデータフレームを使用した機械学習の例:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyterノートブック:
タスク:タイタニックの乗客の生存を予測するために、機械学習モデルを考案してください。モデルの精度を出力します。混乱マトリックス、相関マトリックス、およびその他の関連するメトリックをプロットします。このタスクへの最良のアプローチをインターネットを検索してください。
Web UI:
タスク:スポーツデータ分析に関連するさまざまなクエリ
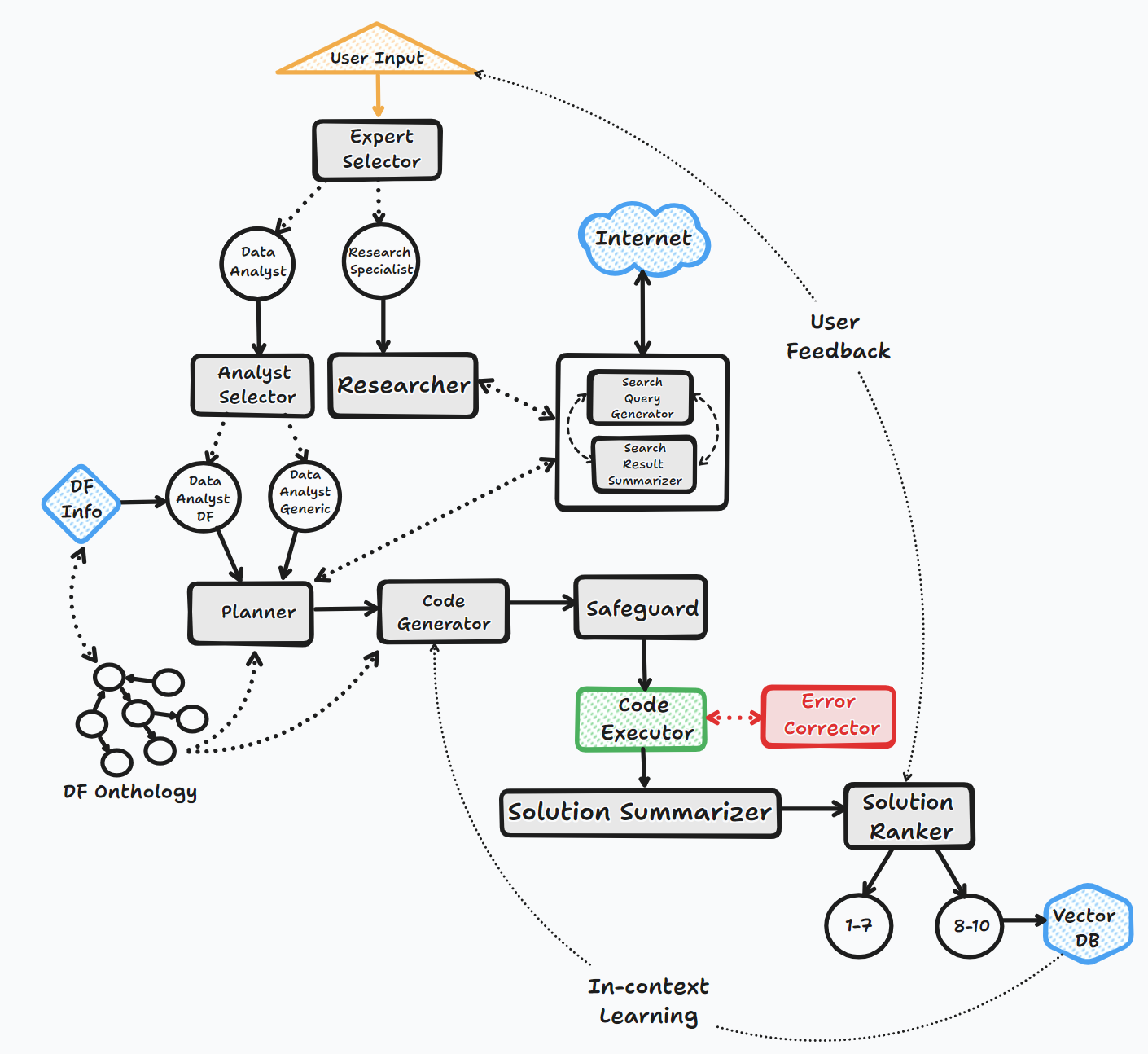
Bambooaiエージェントは、ユーザーと対話して応答を生成するために、いくつかの重要な手順を介して動作します。
1。開始
2。タスク評価
3。動的プロンプトビルド
4。デバッグ、実行、およびエラー修正
5。結果、ランキング、および知識ベースのビルド
6。人間のフィードバックとループの継続
このプロセス全体を通して、エージェントはユーザー入力を継続的に求め、コンテキストのメッセージを保存し、コードを生成および実行して最適な結果を確保します。このプロセスでは、さまざまなAIモデルとベクトルデータベースが採用されており、ユーザーの質問に対する正確で有益な回答を提供しています。
フローチャート(一般的なエージェントフロー):
ライブラリは、APIまたはLocalyを介して、さまざまなオープンソースまたは独自のモデルの使用をサポートしています。
API:
地元:
llm_configファイルのコンテンツを変更して、特定のエージェントに使用するベンダー/モデルを指定して、デフォルトのOpenAIモデル名をModel and Vendor of Choiceeに置き換えることができます。例えば。 {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} 。 LLM_CONFIGの目的については、以下で詳しく説明します。
インストール
pip install bambooai
使用法
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
非推奨通知(2023年10月25日): 「LLM」、「local_code_model」、「llm_switch_plan "、および「llm_switch_code」パラメーターがv 0.3.29の時点で廃止されたことに注意してください。エージェントへのモデルとモデルパラメーターの割り当ては、LLM_CONFIGを介して処理されます。これは、環境変数として、またはワーキングディレクトリのLLM_CONFIG.JSONファイルを介して設定できます。以下の詳細をご覧ください
エージェント固有のLLM構成は、 LLM_CONFIG Environment変数、またはBambooaiのワーキングディレクトリに保存する必要がある「LLM_CONFIG.JSONファイルに保存されます。構成は辞書のJSONリストの形式であり、モデル名、プロバイダー、温度、MAX_TOKENSを指定します。 「Env var」も「LLM_CONFIG.JSON」も存在しない場合、すべてのエージェントに「GPT-3.5-Turbo」を使用するデフォルトのハードコード化された構成を使用します。
Bambooaiライブラリは、各エージェントにデフォルトのハードコードされたプロンプトテンプレートのセットを使用します。それらを試してみたい場合は、提供された「prompt_templates_sample.json」ファイルを変更できます。「_sampleの名前から_sampleを作業ディレクトリに削除できます。その後、変更された「prosped_templates.json」のコンテンツは、ハードコードされたデフォルトの代わりに使用されます。
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
環境変数
ライブラリには、OpenAI LLMSに接続するには、OpenAI APIアカウントとAPIキーが必要です。 OpenAI APIキーは、 OPENAI_API_KEY環境変数に保存する必要があります。キーはここから取得できます:https://platform.openai.com/account/api-keys。
Openaiモデルに加えて、さまざまなプロバイダーからのモデルの選択もサポートされています(Groq、Gemini、Mistral、人類)。 APIキーは、次の形式<VENDOR_NAME>_API_KEYで環境変数に保存する必要があります。 Google GeminiモデルにはGEMINI_API_KEY使用する必要があります。
上記のように、LLM構成は、 LLM_CONFIG環境変数の文字列形式で保存できます。提供されたllm_config_sample.jsonのコンテンツを出発点として使用し、アクセスするモデルに応じて、好みに応じて変更できます。
Pincone Vector DBはオプションです。あなたがそれを使いたいなら、あなたは何もする必要はありません。 Pineconeを使用してアカウントがあり、ナレッジベースとランキング機能を使用したい場合は、 PINECONE_API_KEY Endisooment変数をセットアップし、「Vector_DB」パラメーターをTRUEに設定する必要があります。 Vector DBインデックスは、最初の実行時に作成されます。
Google検索もオプションです。あなたがそれを使いたいなら、あなたは何もする必要はありません。 SERPERを使用してアカウントを持っていて、Google検索機能を使用したい場合は、「:https://serper.dev/」でセットアップしてアカウントが必要になり、 SERPER_API_KEY環境変数を設定し、 'search_tool'パラメーターをtrueに設定します。デフォルトでは、BambooaiはHTMLコンテンツを使用してWebサイトのみをこすります。ただし、ChromedriverでSeleniumを使用することもできます。これははるかに強力です。この機能を有効にするには、Chromeブラウザのバージョンに一致するChromedriverのバージョンを手動でダウンロードし、ファイルシステムに保存し、ChromeDriverへのパスで環境変数SELENIUM_WEBDRIVER_PATHを作成する必要があります。 Bambooai WilはAutomaticalyを拾い上げ、すべてのスクレイピングタスクにセレンを使用します。
ローカルオープンソースモデル
ライブラリは現在、次のオープンソースモデルを直接サポートしています。現在、Humaneval Benchmarkで最高のスコアを獲得したモデルを選択しました。
特定のエージェントにローカルモデルを使用する場合は、OpenAIモデル名をローカルモデル名に置き換えるLLM_CONFIGコンテンツを変更し、プロバイダー値を「ローカル」に変更します。例えば。 {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}}現在、コード生成タスクのようなすべてのコードコードのようなタスクのように、コード生成タスクのようなすべてのコード生成タスクのように、すべてのコード生成タスクのようなものを使用することをお勧めします。選択したOpenaiモデル。このモデルは、その後の実行のためにHuggingfaceとキャッシュされたローカリからダウンロードされます。合理的なパフォーマンスには、CUDA対応GPUとCUDAバージョンと互換性のあるPytorchライブラリが必要です。以下は、パッケージに含まれていない必要なライブラリで、独立してインストールする必要があります。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
ローカルモデルの設定とパラメーターは、local_models.pyモジュールにあり、特定の構成または設定に合わせて調整できます。
オラマ
ライブラリは、Ollama https://ollama.com/およびすべてのモデルの使用もサポートしています。特定のエージェントにローカルOllamaモデルを使用する場合は、Openaiモデル名をOllamaモデル名に置き換えるLLM_CONFIGコンテンツを変更し、プロバイダーの値を「Ollama」に変更します。例えば。 {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
ロギング
すべてのLLMインタラクション(ローカルまたはAPIを介して)は、 bambooai_consolidated_log.jsonファイルに記録されています。ログファイルのサイズが5 MBに達すると、新しいログファイルが作成されます。最古のファイルが上書きされる前に、合計3つのログファイルがファイルシステムに保持されます。
次の詳細がキャプチャされます。
ログ構造:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
タスク:機械学習モデルを考案して、タイタニックの乗客の生存を予測します。出力には、モデルの精度と混乱マトリックス、相関マトリックス、およびその他の関連するメトリックの視覚化が含まれている必要があります。
データセット: Titanic.csv
モデル: GPT-4-Turbo
| メトリック | 価値 |
|---|---|
| 実行時間 | 77.12秒 |
| 入力トークン | 7128 |
| 出力トークン | 1215 |
| 総コスト | 0.1077ドル |
| メトリック | 価値 |
|---|---|
| 実行時間 | 47.39秒 |
| 入力トークン | 722 |
| 出力トークン | 931 |
| 総コスト | 0.0353ドル |
スポーツデータ分析のためのAIツールの客観的評価_ Maxwell-V2対Generic LLMS.PDF
貢献は大歓迎です。プルリクエストを自由に開いてください。私たちの目標は、読みやすさの高い簡潔なコードベースを維持することであることに注意してください。


