BambooAI
v0.3.52
Легкая библиотека, использующая крупные языковые модели (LLMS) для обеспечения возможностей взаимодействия с естественным языком, очень похожие на исследователь и анализ данных, позволяющий беседовать с вашими данными. Вы можете либо предоставить свои собственные наборы данных, либо позволить библиотеке найти и извлекать данные для вас. Он поддерживает поиск в Интернете и внешние взаимодействия API.
Библиотека Bambooai - это экспериментальный, LightWeigh Tool, который использует крупные языковые модели (LLMS) для облегчения анализа данных, что делает его более доступным для пользователей, включая тех, у кого нет опыта программирования. Он функционирует в качестве помощника для исследований и анализа данных, позволяя пользователям взаимодействовать со своими данными через естественный язык. Пользователи могут предоставить свои собственные наборы данных, или Bambooai может помочь в поиске необходимых данных. Инструмент также интегрирует поиск в Интернете и доступ к внешним API для улучшения его функциональности.
Bambooai обрабатывает запросы естественного языка о наборах данных и может генерировать и выполнять код Python для анализа и визуализации данных. Это позволяет пользователям получать информацию из своих данных без обширных знаний о кодировании. Пользователи просто вводят свой набор данных, задают вопросы на простом английском языке, а Bambooai предоставляет ответы, а также визуализации, если это необходимо, чтобы помочь лучше понять данные.
Bambooai стремится расширить возможности аналитиков данных на всех уровнях. Он упрощает анализ и визуализацию данных, помогая оптимизировать рабочие процессы. Библиотека предназначена для удобства для пользователя, эффективной и адаптируемой для удовлетворения различных потребностей.
Попробуйте это в Google Colab:
Пример машинного обучения с использованием предоставленного DataFrame:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Журпина Jupyter:
Задача: Не могли бы вы разработать модель Machine Learnig, чтобы предсказать выживание пассажиров на Титанике? Выводит точность модели. Постройте матрицу путаницы, корреляционную матрицу и другие соответствующие метрики. Поиск в Интернете для лучшего подхода к этой задаче.
Веб -интерфейс:
Задача: различные запросы, связанные с анализом спортивных данных
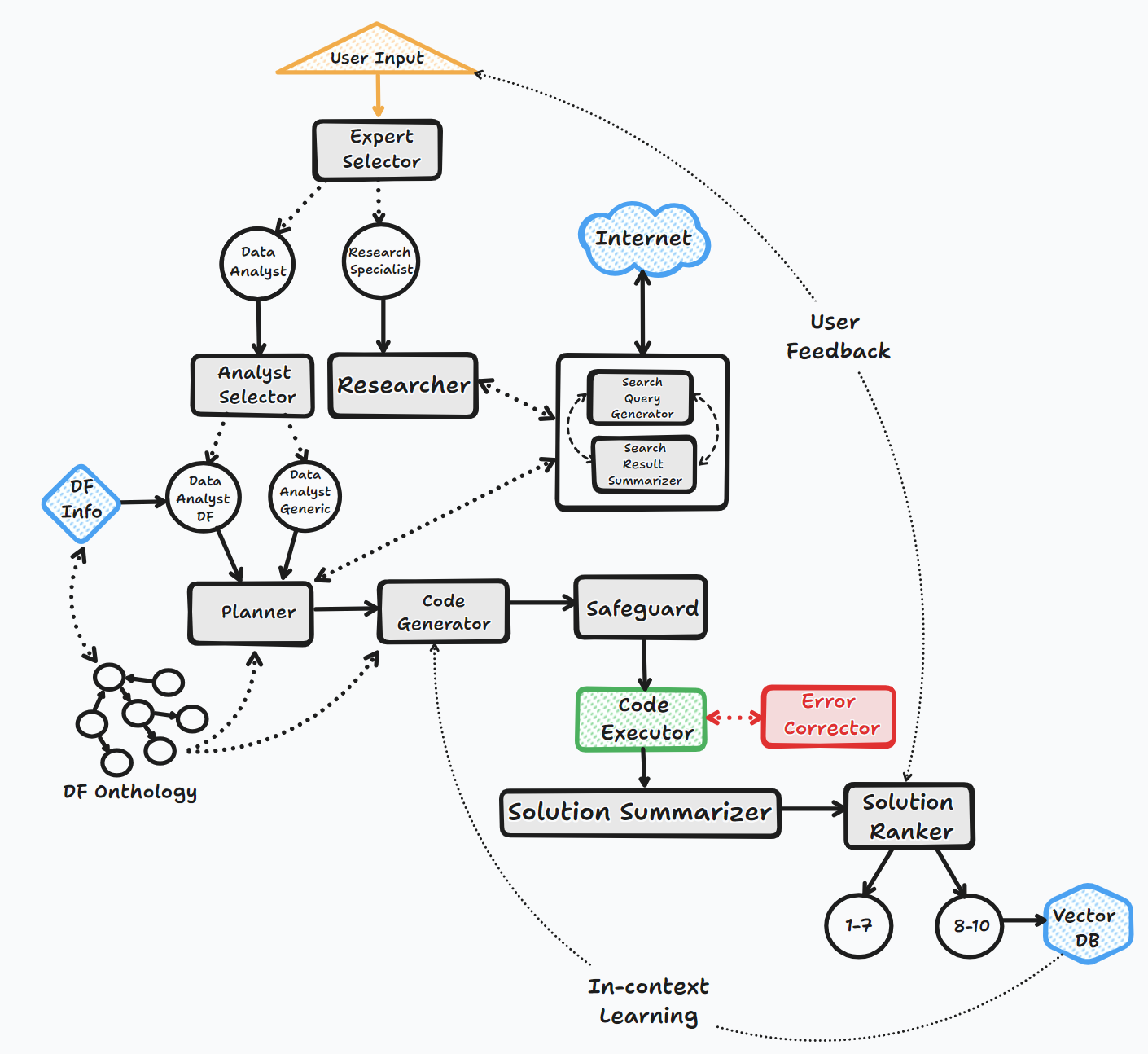
Агент Bambooai работает через несколько ключевых шагов для взаимодействия с пользователями и генерации ответов:
1. Посвящение
2. Оценка задачи
3. Динамическая подсказка
4. Отладка, выполнение и исправление ошибок
5. Результаты, рейтинг и сборка базы знаний
6. Человеческая обратная связь и продолжение петли
На протяжении всего этого процесса агент непрерывно вызывает пользовательский ввод, хранит сообщения для контекста и генерирует и выполняет код для обеспечения оптимальных результатов. Различные модели ИИ и векторная база данных используются в этом процессе для предоставления точных и полезных ответов на вопросы пользователя.
Блок -схема (поток общего агента):
Библиотека поддерживает использование различных моделей с открытым исходным кодом или проприетарных моделей, либо через API, либо Localy.
API:
Местный:
Вы можете указать, какой поставщик/модель вы хотите использовать для конкретного агента, изменяя содержимое файла LLM_CONFIG, заменив имя модели OpenAI по умолчанию моделью и поставщиком вашего выбора. например. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . Цель LLM_CONFIG описана более подробно ниже.
Установка
pip install bambooai
Использование
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
Уведомление об исчезновении (25 октября 2023 г.): Обратите внимание, что «llm», «local_code_model», «llm_switch_plan» и «llm_switch_code» Параметры установились с V 0.3.29. Назначение моделей и параметров модели для агентов теперь обрабатывается через llm_config. Это может быть установлено либо в качестве переменной среды, либо через файл llm_config.json в рабочем каталоге. Пожалуйста, смотрите данные ниже
Конфигурация специфики для агента LLM сохраняется в переменной среды LLM_CONFIG или в файле «LLM_CONFIG.JSON, который необходимо хранить в рабочем каталоге Bambooai. Конфигурация, чтобы отразить ваши предпочтения.
Библиотека Bambooai использует жестко -кодированный набор шаблонов приглашения по умолчанию для каждого агента. Если вы хотите поэкспериментировать с ними, вы можете изменить предоставленный файл «recavle_templates_sample.json», удалите «_Sample с его имени и хранить в рабочем каталоге. Впоследствии содержание модифицированного« recavel_templates.json »будет использоваться вместо того, чтобы быть призванным.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Переменные среды
Библиотека требует учетной записи API OpenAI и ключа API для подключения к OpenAI LLMS. Ключ API OpenAI должен храниться в переменной среды OPENAI_API_KEY . Ключ можно получить отсюда: https://platform.openai.com/account/api-keys.
В дополнение к моделям Openai также поддерживается выбор моделей из разных поставщиков (Groq, Gemini, Mistral, Anpropic). Ключи API должны храниться в переменных среды в следующем формате <VENDOR_NAME>_API_KEY . Вам нужно использовать GEMINI_API_KEY для моделей Google Gemini.
Как упомянуто выше, конфигурация LLM может храниться в формате строки в переменной среды LLM_CONFIG . Вы можете использовать содержимое предоставленного LLM_CONFIG_SAMPLE.JSON в качестве отправной точки и изменить ваше предпочтение, в зависимости от того, к каким моделям у вас есть доступ.
Pincone Vector DB является необязательным. Если вы не хотите использовать его, вам не нужно ничего делать. Если у вас есть учетная запись в Pinecone и вы хотите использовать базу знаний и функции ранжирования, вам потребуется настроить переменную inviroment invirooment PINECONE_API_KEY и установить параметр «vector_db» на true. Индекс Vector DB создается при первом выполнении.
Поиск Google также необязательный. Если вы не хотите использовать его, вам не нужно ничего делать. Если у вас есть учетная запись с Serper и вы хотите использовать функции поиска Google, вам потребуется настроить и учетную запись с помощью ": https://serper.dev/" и установить переменную среды SERPER_API_KEY и установить параметр «search_tool 'для true. По умолчанию Bambooai может соскребить веб -сайты только с HTML -контентом. Однако он также способен использовать селен с хромидривером, который гораздо более мощный. Чтобы включить эту функциональность, вам нужно будет Munualy скачать версию Chromedriver, которая соответствует вашей версии браузера Chrome, хранить ее в файловой системе и создать переменную среды SELENIUM_WEBDRIVER_PATH с пути к вашему хромаредриверу. Bambooai будет выберет его автоматизирование и используйте селен для всех задач по цене.
Местные модели с открытым исходным кодом
Библиотека в настоящее время напрямую поддерживает следующие модели с открытым исходным кодом. Я выбрал модели, которые в настоящее время оценивают самые высокие на эталоне Humaneval.
Если вы хотите использовать локальную модель для конкретного агента, измените содержание LLM_CONFIG, заменяющую имя модели OpenAI на имя локальной модели и измените значение поставщика на «локальный». например. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} В настоящее время рекомендуется использовать локальные модели только для генерации кода, все другие, такие как общие коды, все еще должны быть обойдными, и все еще обойдя, и все еще определяются, и все еще будут обозначать, и все еще обозначают, и все еще будут обозначать, и все еще будут обозначать, и все еще будут обозначать, и все еще будут обозначать, и все еще будут обозначать, и все еще будут обозначать, как и все еще. Openai модели выбора. Модель загружается из Huggingface и Cach Localy для последующих выполнений. Для разумной производительности требуется, чтобы графический процессор с поддержкой CUDA и библиотека Pytorch совместимы с версией CUDA. Ниже приведены необходимые библиотеки, которые не включены в пакет и должны быть установлены независимо:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
Настройки и параметры для локальных моделей расположены в модуле local_models.py и могут быть скорректированы в соответствии с вашей конкретной конфигурацией или предпочтениями.
Оллама
Библиотека также поддерживает использование Ollama https://ollama.com/ и все его модели. Если вы хотите использовать локальную модель OLLAMA для конкретного агента, измените содержание LLM_CONFIG, заменяющую имя модели OpenAI на имя модели Ollama и измените значение поставщика на «Ollama». например. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Регистрация
Все взаимодействия LLM (локальные или через API) регистрируются в файле bambooai_consolidated_log.json . Когда размер файла журнала достигает 5 МБ, создается новый файл журнала. В общей сложности 3 файла журнала хранятся в файловой системе до того, как самый старый файл перезаписывается.
Следующие детали зафиксированы:
Структура журнала:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Задача: разработать модель машинного обучения, чтобы предсказать выживание пассажиров на Титанике. Вывод должен включать точность модели и визуализацию матрицы путаницы, корреляционной матрицы и других соответствующих метрик.
Набор данных: titanic.csv
Модель: GPT-4-Turbo
| Показатель | Ценить |
|---|---|
| Время исполнения | 77,12 секунды |
| Входные токены | 7128 |
| Выходные токены | 1215 |
| Общая стоимость | $ 0,1077 |
| Показатель | Ценить |
|---|---|
| Время исполнения | 47,39 секунды |
| Входные токены | 722 |
| Выходные токены | 931 |
| Общая стоимость | $ 0,0353 |
Объективная оценка инструментов AI для спортивных данных Analytics_ Maxwell-V2 против generic llms.pdf
Взносы приветствуются; Пожалуйста, не стесняйтесь открыть запрос на тягу. Имейте в виду, что наша цель - поддерживать краткую кодовую базу с высокой читаемостью.


