BambooAI
v0.3.52
Uma biblioteca leve que utiliza grandes modelos de linguagem (LLMS) para fornecer recursos de interação de linguagem natural, assim como um assistente de pesquisa e análise de dados, permitindo uma conversa com seus dados. Você pode fornecer seus próprios conjuntos de dados ou permitir que a biblioteca localize e busque dados para você. Ele suporta pesquisas na Internet e interações externas da API.
A biblioteca Bambooai é uma ferramenta experimental e leve que utiliza grandes modelos de idiomas (LLMS) para facilitar a análise de dados, tornando -o mais acessível aos usuários, incluindo aqueles sem experiência em programação. Ele funciona como assistente de pesquisa e análise de dados, permitindo que os usuários interajam com seus dados por meio da linguagem natural. Os usuários podem fornecer seus próprios conjuntos de dados ou bambu pode ajudar no fornecimento dos dados necessários. A ferramenta também integra pesquisas da Internet e acessa APIs externas para aprimorar sua funcionalidade.
O Bambooai processa consultas de linguagem natural sobre conjuntos de dados e podem gerar e executar o código Python para análise e visualização de dados. Isso permite que os usuários obtenham informações de seus dados sem amplo conhecimento de codificação. Os usuários simplesmente insistem seu conjunto de dados, fazem perguntas em inglês simples e o Bambooai fornece as respostas, juntamente com as visualizações, se necessário, para ajudar a entender melhor os dados.
O Bambooai pretende aumentar os recursos dos analistas de dados em todos os níveis. Ele simplifica a análise e a visualização dos dados, ajudando a otimizar os fluxos de trabalho. A biblioteca foi projetada para ser fácil de usar, eficiente e adaptável para atender a várias necessidades.
Experimente no Google Colab:
Um exemplo de aprendizado de máquina usando dados de dados fornecidos:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyter Notebook:
Tarefa: você pode criar um modelo de aprendizado de máquina para prever a sobrevivência dos passageiros no Titanic? Saia a precisão do modelo. Plote a matriz de confusão, a matriz de correlação e outras métricas relevantes. Pesquise a Internet para obter a melhor abordagem para esta tarefa.
Interface do usuário da web:
Tarefa: Várias consultas relacionadas à análise de dados esportivos
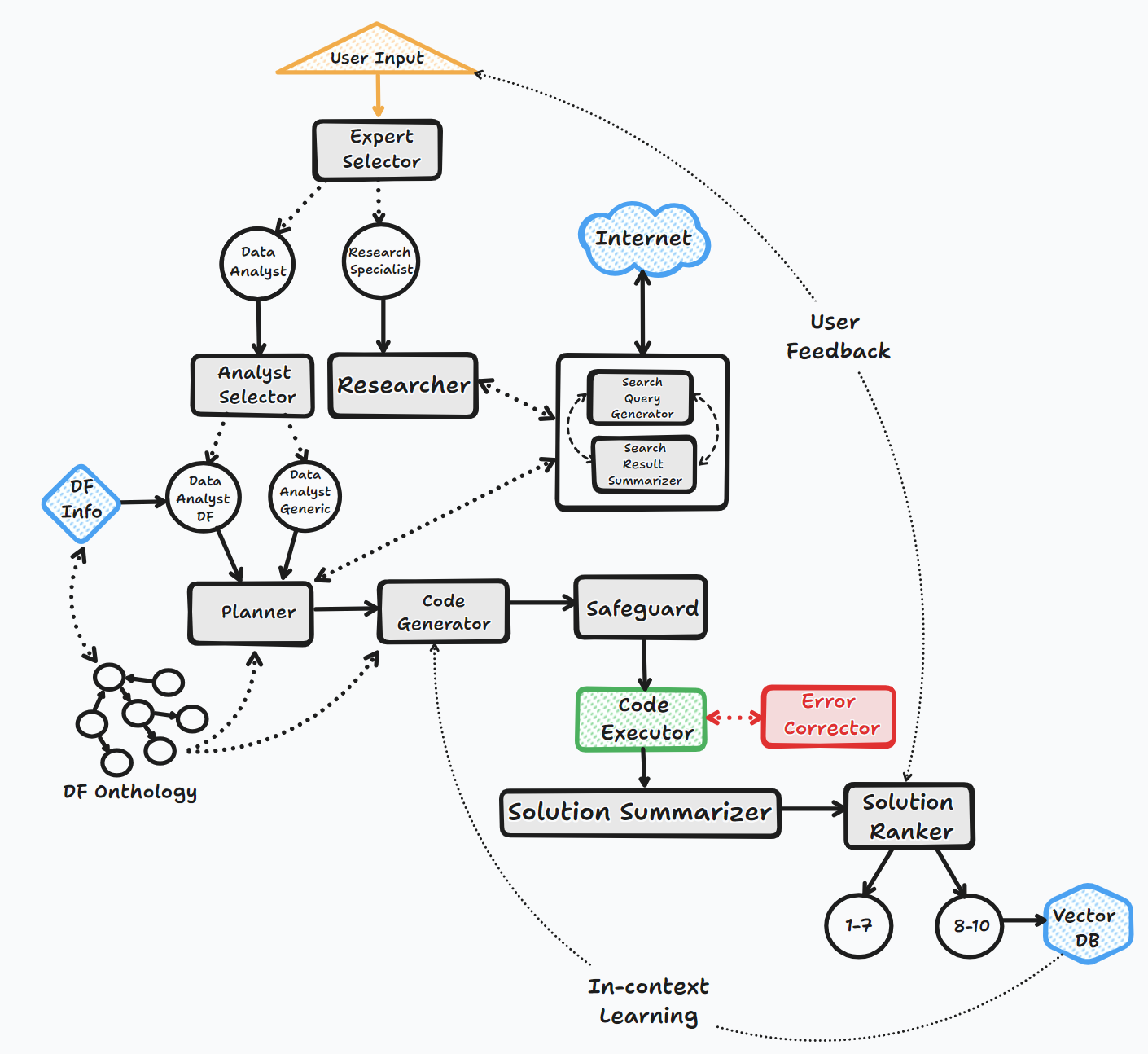
O agente Bambooai opera através de várias etapas importantes para interagir com os usuários e gerar respostas:
1. Iniciação
2. Avaliação de tarefas
3. Construição de prompt dinâmico
4. Depuração, execução e correção de erros
5. Resultados, classificação e construção da base de conhecimento
6. Feedback humano e continuação de loop
Ao longo deste processo, o agente solicita continuamente a entrada do usuário, armazena mensagens para contexto e gera e executa código para garantir resultados ideais. Vários modelos de IA e um banco de dados vetorial são empregados nesse processo para fornecer respostas precisas e úteis às perguntas do usuário.
Fluxograma (fluxo de agente geral):
A biblioteca suporta o uso de vários modelos de código aberto ou proprietários, via API ou local.
API:
Local:
Você pode especificar qual fornecedor/modelo que deseja usar para um agente específico modificando o conteúdo do arquivo LLM_CONFIG, substituindo o nome do modelo OpenAI padrão pelo modelo e fornecedor do seu escolha. por exemplo. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . O objetivo do llm_config é descrito em mais detalhes abaixo.
Instalação
pip install bambooai
Uso
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
Aviso de depreciação (25 de outubro de 2023): Observe que os parâmetros "LLM", "LOCAL_CODE_MODEL", "LLM_SWITCH_PLAN" e "LLM_SWITCH_CODE" foram depreciados a partir de V 0.3.29. A atribuição de modelos e parâmetros de modelo aos agentes agora é tratada via LLM_CONFIG. Isso pode ser definido como uma variável de ambiente ou através de um arquivo llm_config.json no diretório de trabalho. Por favor, veja os detalhes abaixo
A configuração específica de LLM específica do agente é armazenada na variável de ambiente LLM_CONFIG , ou no arquivo "llm_config.json, que precisa ser armazenado no diretório de trabalho do bamboai. Modifique a configuração da configuração de suas preferências.
A biblioteca Bambooai usa o conjunto de modelos de prompt de código hard -codificado padrão para cada agente. Se você deseja experimentá -los, pode modificar o arquivo "Prompt_Templates_sample.json", remover o "_sample do nome e armazenar no diretório de trabalho.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Variáveis de ambiente
A biblioteca requer uma conta da API OpenAI e a chave da API para conectar -se ao OpenAI LLMS. A chave da API do OpenAI precisa ser armazenada em uma variável de ambiente OPENAI_API_KEY . A chave pode ser obtida daqui: https://platform.openai.com/account/api-keys.
Além dos modelos OpenAI, uma seleção de modelos de diferentes fornecedores também é suportada (Groq, Gêmeos, Mistral, Antrópica). As teclas da API precisam ser armazenadas em variáveis de ambiente no seguinte formato <VENDOR_NAME>_API_KEY . Você precisa usar os modelos GEMINI_API_KEY para o Google Gemini.
Como mencionado acima, a configuração LLM pode ser armazenada em um formato de string na variável de ambiente LLM_CONFIG . Você pode usar o conteúdo do llm_config_sample.json fornecido como ponto de partida e modificar para sua preferência, dependendo dos modelos aos quais você tem acesso.
O db de vetor de pincona é opcional. Se você não quiser usá -lo, não precisa fazer nada. Se você tiver uma conta com Pinecone e gostaria de usar a base de conhecimento e os recursos de classificação, você será obrigado a configurar a variável PINECONE_API_KEY Envirooment e definir o parâmetro 'vetor_db' como true. O índice de banco de dados vetorial é criado após a primeira execução.
A pesquisa do Google também é opcional. Se você não quiser usá -lo, não precisa fazer nada. Se você possui uma conta com o Serper e gostaria de usar a funcionalidade de pesquisa do Google, será obrigado a configurar e explicar ": https://serper.dev/" e defina a variável de ambiente SERPER_API_KEY e defina o parâmetro 'Search_tool' como TRUE. Por padrão, o Bambooai só pode raspar sites com conteúdo HTML. No entanto, também é capaz de usar o selênio com o Chromedriver, que é muito mais poderoso. Para ativar essa funcionalidade, você precisará fazer o download da manualidade de uma versão do ChromedRiver que corresponde à sua versão do navegador Chrome, armazená -la no sistema de arquivos e criar uma variável de ambiente SELENIUM_WEBDRIVER_PATH com um caminho para o seu cromedriver. O Bambooai wil pega automaticamente e use o Selenium para todas as tarefas de raspagem.
Modelos de código aberto local
Atualmente, a biblioteca suporta diretamente os seguintes modelos de código aberto. Eu selecionei os modelos que atualmente obtêm a maior pontuação no referência da Humaneval.
Se você deseja usar o modelo local para um agente específico, modifique o conteúdo llm_config que substitui o nome do modelo OpenAI pelo nome do modelo local e altere o valor do provedor para 'local'. por exemplo. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} Atualmente, é recomendável usar modelos locais apenas para geração de código, todas as tarefas como pseudo e pseudo Modelos Openai de escolha. O modelo é baixado do HuggingFace e local em cache para execuções subsequentes. Para um desempenho razoável, é necessário que a GPU habilitada para CUDA e a biblioteca Pytorch compatíveis com a versão CUDA. Abaixo estão as bibliotecas necessárias que não estão incluídas no pacote e precisarão ser instaladas independentemente:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
As configurações e parâmetros para modelos locais estão localizados no módulo local_models.py e podem ser ajustados para corresponder à sua configuração ou preferências específicas.
Ollama
A biblioteca também suporta o uso de Ollama https://ollama.com/ e todos os seus modelos. Se você deseja usar um modelo de Ollama local para um agente específico, modifique o conteúdo LLM_CONFIG, substituindo o nome do modelo OpenAI pelo nome do modelo Ollama e altere o valor do provedor para 'Ollama'. por exemplo. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Log
Todas as interações LLM (local ou via APIs) são registradas no arquivo bambooai_consolidated_log.json . Quando o tamanho do arquivo de log atingir 5 MB, um novo arquivo de log é criado. Um total de 3 arquivos de log são mantidos no sistema de arquivos antes que o arquivo mais antigo seja substituído.
Os seguintes detalhes são capturados:
Estrutura de log:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Tarefa: Devive um modelo de aprendizado de máquina para prever a sobrevivência dos passageiros no Titanic. A saída deve incluir a precisão do modelo e as visualizações da matriz de confusão, matriz de correlação e outras métricas relevantes.
Conjunto de dados: titanic.csv
Modelo: GPT-4-Turbo
| Métrica | Valor |
|---|---|
| Tempo de execução | 77,12 segundos |
| Tokens de entrada | 7128 |
| Tokens de saída | 1215 |
| Custo total | $ 0,1077 |
| Métrica | Valor |
|---|---|
| Tempo de execução | 47,39 segundos |
| Tokens de entrada | 722 |
| Tokens de saída | 931 |
| Custo total | $ 0,0353 |
Avaliação objetiva das ferramentas de IA para Analytics de dados esportivos_ Maxwell-V2 vs. LLMs.pdf genérico
Contribuições são bem -vindas; Por favor, sinta -se à vontade para abrir uma solicitação de tração. Lembre -se de que nosso objetivo é manter uma base de código concisa com alta legibilidade.


