BambooAI
v0.3.52
Perpustakaan ringan yang menggunakan model bahasa besar (LLM) untuk memberikan kemampuan interaksi bahasa alami, seperti asisten penelitian dan analisis data yang memungkinkan percakapan dengan data Anda. Anda dapat memberikan set data Anda sendiri, atau memungkinkan perpustakaan menemukan dan mengambil data untuk Anda. Ini mendukung pencarian internet dan interaksi API eksternal.
Perpustakaan Bambooai adalah alat eksperimental, Lightweigh yang memanfaatkan model bahasa besar (LLM) untuk memfasilitasi analisis data, membuatnya lebih mudah diakses oleh pengguna, termasuk yang tanpa keahlian pemrograman. Fungsi sebagai asisten untuk penelitian dan analisis data, memungkinkan pengguna untuk berinteraksi dengan data mereka melalui bahasa alami. Pengguna dapat menyediakan kumpulan data mereka sendiri atau bambooai dapat membantu dalam mencari data yang diperlukan. Alat ini juga mengintegrasikan pencarian Internet dan mengakses API eksternal untuk meningkatkan fungsinya.
Bambooai memproses kueri bahasa alami tentang dataset dan dapat menghasilkan dan menjalankan kode Python untuk analisis dan visualisasi data. Ini memungkinkan pengguna untuk memperoleh wawasan dari data mereka tanpa pengetahuan pengkodean yang luas. Pengguna hanya memasukkan dataset mereka, mengajukan pertanyaan dalam bahasa Inggris sederhana, dan Bambooai memberikan jawabannya, bersama dengan visualisasi jika diperlukan, untuk membantu memahami data dengan lebih baik.
Bambooai bertujuan untuk menambah kemampuan analis data di semua tingkatan. Ini menyederhanakan analisis dan visualisasi data, membantu merampingkan alur kerja. Perpustakaan ini dirancang untuk ramah pengguna, efisien, dan mudah beradaptasi untuk memenuhi berbagai kebutuhan.
Cobalah di Google Colab:
Contoh pembelajaran mesin menggunakan DataFrame yang disediakan:
!pip install pandas
!pip install bambooai
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('titanic.csv')
bamboo = BambooAI(df, debug=False, vector_db=False, search_tool=True)
bamboo.pd_agent_converse()
Jupyter Notebook:
Tugas: Bisakah Anda menyusun model pembelajaran mesin untuk memprediksi kelangsungan hidup penumpang di Titanic? Keluaran akurasi model. Plot matriks kebingungan, matriks korelasi, dan metrik lainnya yang relevan. Cari Internet untuk pendekatan terbaik untuk tugas ini.
Web UI:
Tugas: Berbagai pertanyaan yang terkait dengan analisis data olahraga
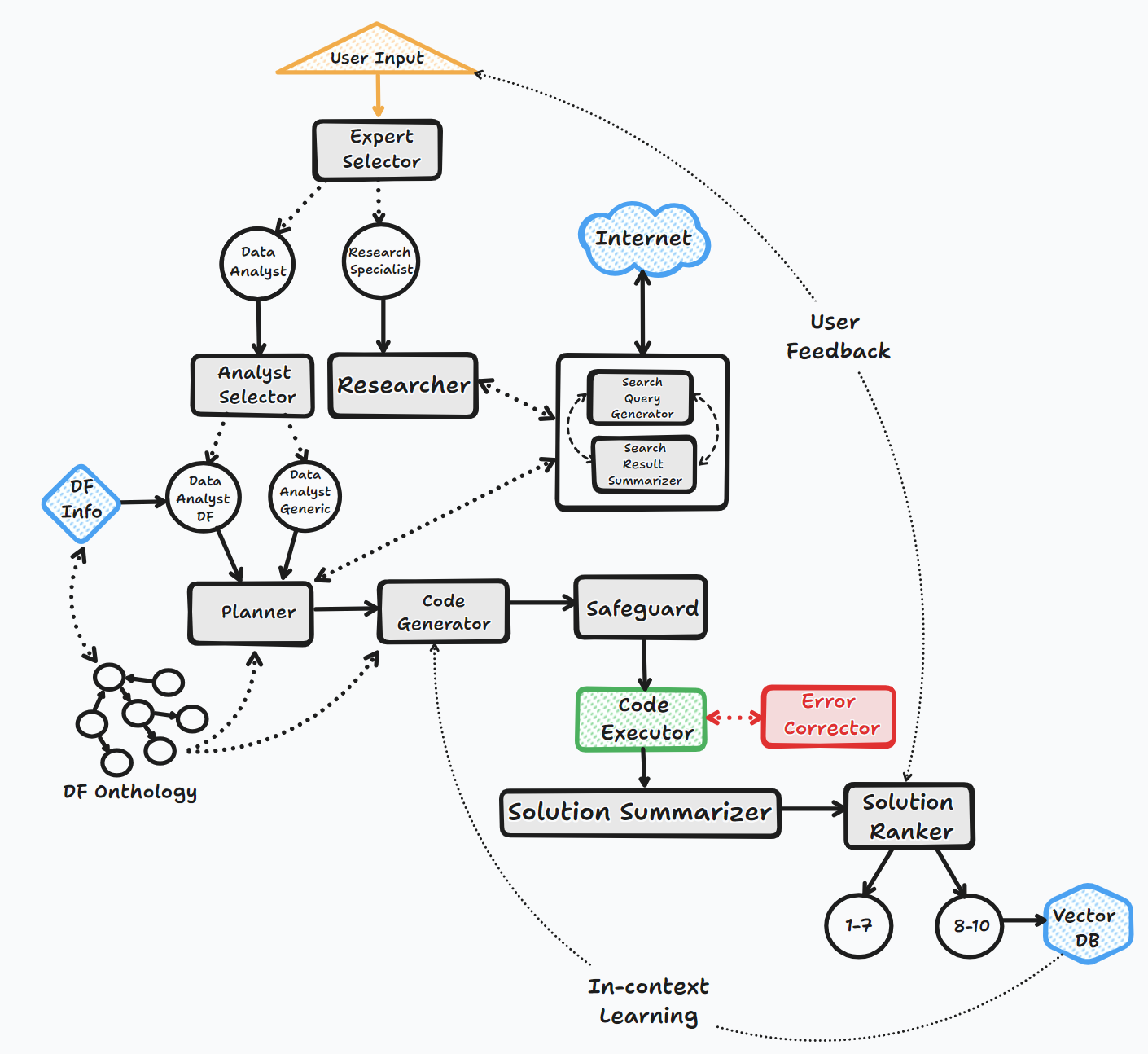
Agen Bambooai beroperasi melalui beberapa langkah kunci untuk berinteraksi dengan pengguna dan menghasilkan tanggapan:
1. Inisiasi
2. Evaluasi tugas
3. Dinamis Prompt Build
4. Debugging, eksekusi, dan koreksi kesalahan
5. Hasil, Peringkat, dan Basis Pengetahuan Bangunan
6. Umpan balik manusia dan kelanjutan loop
Sepanjang proses ini, agen terus -menerus meminta input pengguna, menyimpan pesan untuk konteks, dan menghasilkan dan menjalankan kode untuk memastikan hasil yang optimal. Berbagai model AI dan basis data vektor digunakan dalam proses ini untuk memberikan tanggapan yang akurat dan bermanfaat terhadap pertanyaan pengguna.
Bagan Aliran (Aliran Agen Umum):
Perpustakaan mendukung penggunaan berbagai model open source atau kepemilikan, baik melalui API atau Localy.
API:
Lokal:
Anda dapat menentukan vendor/model apa yang ingin Anda gunakan untuk agen tertentu dengan memodifikasi konten file llm_config, mengganti nama model OpenAI default dengan model dan vendor pemilih Anda. misalnya. {"agent": "Code Generator", "details": {"model": "open-mixtral-8x22b", "provider":"mistral","max_tokens": 4000, "temperature": 0}} . Tujuan LLM_Config dijelaskan secara lebih rinci di bawah ini.
Instalasi
pip install bambooai
Penggunaan
df: pd.DataFrame - Dataframe (It will try to source the data from internet, if 'df' is not provided)
max_conversations: int - Number of "user:assistant" conversation pairs to keep in memory for a context. Default=4
debug: bool - If True, the received code is sent back to the LLM for evaluation of its relevance to the user's question, along with code error checking and debugging.
search_tool: bool - If True, the Planner agent will use a "google search API: https://serper.dev/" if the required information is not available or satisfactory. By default it only support HTML sites, but can be enhanced with Selenium if the ChromeDriver exists on the system (details below).
vector_db: bool - If True, each answer will first be ranked from 1 to 10. If the rank surpasses a certain threshold (8), the corresponding question (vectorised), plan, code, and rank (metadata) are all stored in the Pinecone database. Each time a new question is asked, these records will be searched. If the similarity score is above 0.9, they will be offered as examples and included in the prompt (in a one-shot learning scenario)
df_onthology: bool - If True, the onthology defined in the module `df_onthology.py` will be used to inform LLM of the dataframe structure, metrics, record frequency, keys, joins, abstract functions etc. The onthology is custom for each dataframe type, and needs to be defined by the user. Sample onthology is included. This feature signifficantly improves performance, and quality of the solutions.
exploratory: bool - If set to True, the LLM will evaluate the user's question and select an "Expert" that is best suited to address the question (experts: Research Specialist, Data Analyst). In addition, if the task involves code generation/execution, it will generate a task list detailing the steps, which will subsequently be sent to the LLM as a part of the prompt for the next action. This method is particularly effective for vague user prompts, but it might not perform as efficiently with more specific prompts. The default setting is True.
e.g. bamboo = BambooAI(df, debug=True, vector_db=True, search_tool=True, exploratory=True)
bamboo = BambooAI(df,debug=False, vector_db=False, exploratory=True, search_tool=True)
PEMBERITAHUAN PEMBERITAHUAN (25 Oktober 2023): Harap dicatat bahwa "llm", "local_code_model", "llm_switch_plan", dan parameter "llm_switch_code" telah telah diamerikan pada v 0.3.29. Penugasan model dan parameter model untuk agen sekarang ditangani melalui llm_config. Ini dapat ditetapkan sebagai variabel lingkungan atau melalui file llm_config.json di direktori kerja. Silakan lihat detailnya di bawah
Konfigurasi LLM spesifik agen disimpan dalam variabel lingkungan LLM_CONFIG , atau dalam file "llm_config.json yang perlu disimpan dalam direktori kerja bambooai. Konfigurasi dalam bentuk json dan menentukan nama model, suhu, suhu, suhu, dan maxon. Konfigurasi untuk mencerminkan preferensi Anda. Jika tidak ada "Env var" maupun "llm_config.json", Bambooai akan menggunakan konfigurasi hardcoded default yang menggunakan "GPT-3.5-turbo" untuk semua agen.
Perpustakaan Bambooai menggunakan set templat prompt yang hardcoded default untuk masing -masing agen. Jika Anda ingin bereksperimen dengan mereka, Anda dapat memodifikasi file "prompt_templates_sample.json" yang disediakan, menghapus "_Sample dari namanya dan menyimpan di direktori kerja. Selanjutnya, konten yang dimodifikasi" Anda dapat dikembalikan.
# Run in a loop remembering the conversation history
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse()
# Run programaticaly (Single execution).
import pandas as pd
from bambooai import BambooAI
df = pd.read_csv('test_activity_data.csv')
bamboo = BambooAI(df)
bamboo.pd_agent_converse("Calculate 30, 50, 75 and 90 percentiles of the heart rate column")
Variabel Lingkungan
Perpustakaan memerlukan akun API OpenAI dan kunci API untuk terhubung ke OpenAI LLMS. Kunci API OpenAI perlu disimpan dalam variabel lingkungan OPENAI_API_KEY . Kuncinya dapat diperoleh dari sini: https://platform.openai.com/account/api-keys.
Selain model OpenAI, pilihan model dari penyedia yang berbeda juga didukung (GROQ, Gemini, Mistral, Anthropic). Kunci API perlu disimpan dalam variabel lingkungan dalam format berikut <VENDOR_NAME>_API_KEY . Anda perlu menggunakan GEMINI_API_KEY untuk model Google Gemini.
Seperti disebutkan di atas, konfigurasi LLM dapat disimpan dalam format string dalam variabel lingkungan LLM_CONFIG . Anda dapat menggunakan konten LLM_Config_Sample.json yang disediakan sebagai titik awal dan memodifikasi ke preferensi Anda, tergantung pada model apa yang Anda akses.
DB vektor pincone adalah opsional. Jika Anda tidak ingin menggunakannya, Anda tidak perlu melakukan apa pun. Jika Anda memiliki akun dengan Pinecone dan ingin menggunakan basis pengetahuan dan fitur peringkat, Anda akan diminta untuk mengatur variabel lingkungan PINECONE_API_KEY , dan atur parameter 'Vector_DB' ke True. Indeks DB vektor dibuat pada saat eksekusi pertama.
Pencarian Google juga opsional. Jika Anda tidak ingin menggunakannya, Anda tidak perlu melakukan apa pun. Jika Anda memiliki akun dengan Serper dan ingin menggunakan fungsionalitas pencarian Google, Anda akan diminta untuk mengatur dan akun dengan ": https://serper.dev/", dan mengatur variabel lingkungan SERPER_API_KEY , dan mengatur parameter 'search_tool' ke true. Secara default Bambooai hanya dapat mengikis situs web dengan konten HTML. Namun itu juga mampu menggunakan selenium dengan chromedriver, yang jauh lebih kuat. Untuk mengaktifkan fungsionalitas ini, Anda perlu memang -ngas mendownload versi ChromedRiver yang cocok dengan versi Anda dari browser Chrome, menyimpannya pada sistem file dan membuat variabel lingkungan SELENIUM_WEBDRIVER_PATH dengan jalur ke chromedriver Anda. Bambooai akan mengambilnya secara otomatis, dan menggunakan selenium untuk semua tugas pengikis.
Model Sumber Terbuka Lokal
Perpustakaan saat ini secara langsung mendukung model sumber terbuka berikut. Saya telah memilih model yang saat ini mendapat skor tertinggi pada tolok ukur manusia.
Jika Anda ingin menggunakan model lokal untuk agen tertentu, ubah konten LLM_CONFIG menggantikan nama model OpenAI dengan nama model lokal dan ubah nilai penyedia menjadi 'lokal'. misalnya. {"agent": "Code Generator", "details": {"model": "Phind-CodeLlama-34B-v2", "provider":"local","max_tokens": 2000, "temperature": 0}} Kode yang disarankan pada saat ini. Model pilihan openai. Model ini diunduh dari Huggingface dan Discached Localy untuk eksekusi berikutnya. Untuk kinerja yang wajar, ia membutuhkan GPU yang diaktifkan CUDA dan pustaka Pytorch yang kompatibel dengan versi CUDA. Di bawah ini adalah perpustakaan yang diperlukan yang tidak termasuk dalam paket dan perlu diinstal secara independen:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 (Adjust to match your CUDA version. This library is already included in Colab notebooks)
pip install auto-gptq (Only required if using WizardCoder-15B-1.0-GPTQ model)
pip install accelerate
pip install einops
pip install xformers
pip install bitsandbytes
Pengaturan dan parameter untuk model lokal terletak di modul local_models.py dan dapat disesuaikan agar sesuai dengan konfigurasi atau preferensi khusus Anda.
Ollama
Perpustakaan juga mendukung penggunaan Ollama https://ollama.com/ dan semua modelnya. Jika Anda ingin menggunakan model Ollama lokal untuk agen tertentu, ubah konten LLM_CONFIG menggantikan nama model OpenAI dengan nama model Ollama dan ubah nilai penyedia menjadi 'ollama'. misalnya. {"agent": "Code Generator", "details": {"model": "llama3:70b", "provider":"ollama","max_tokens": 2000, "temperature": 0}}
Logging
Semua interaksi LLM (lokal atau melalui API) dicatat dalam file bambooai_consolidated_log.json . Ketika ukuran file log mencapai 5 MB, file log baru dibuat. Sebanyak 3 file log disimpan pada sistem file sebelum file tertua ditimpa.
Detail berikut ditangkap:
Struktur log:
- chain_id: 1695375585
├─ chain_details (LLM Calls)
│ ├─ List of Dictionaries (Multiple Steps)
│ ├─ Call 1
│ │ ├─ agent (String)
│ │ ├─ chain_id (Integer)
│ │ ├─ timestamp (String)
│ │ ├─ model (String)
│ │ ├─ messages (List)
│ │ │ └─ role (String)
│ │ │ └─ content (String)
│ │ └─ Other Fields (content, prompt_tokens, completion_tokens, total_tokens, elapsed_time, tokens_per_second, cost)
│ ├─ Call 2
│ │ └─ ... (Similar Fields)
│ └─ ... (Call 3, Call 4, Call 5 ...)
│
├─ chain_summary
│ ├─ Dictionary
│ ├─ Total LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
│
├─ summary_per_model
├─ Dictionary
├─ LLM 1 (Dictionary)
│ ├─ LLM Calls (Integer)
│ ├─ Prompt Tokens (Integer)
│ ├─ Completion Tokens (Integer)
│ ├─ Total Tokens (Integer)
│ ├─ Total Time (Float)
│ ├─ Tokens per Second (Float)
│ ├─ Total Cost (Float)
├─ LLM 2
| └─ ... (Similar Fields)
└─ ... (LLM 3, LLM 4, LLM 5 ...)
Tugas: Rancang model pembelajaran mesin untuk memprediksi kelangsungan hidup penumpang di Titanic. Output harus mencakup keakuratan model dan visualisasi matriks kebingungan, matriks korelasi, dan metrik terkait lainnya.
Dataset: Titanic.csv
Model: GPT-4-Turbo
| Metrik | Nilai |
|---|---|
| Waktu pelaksanaan | 77.12 detik |
| Input token | 7128 |
| Token output | 1215 |
| Total biaya | $ 0,1077 |
| Metrik | Nilai |
|---|---|
| Waktu pelaksanaan | 47.39 detik |
| Input token | 722 |
| Token output | 931 |
| Total biaya | $ 0,0353 |
Penilaian Objektif Alat AI untuk Analisis Data Olahraga_ Maxwell-V2 vs Generic LLMs.pdf
Kontribusi dipersilakan; Silakan membuka permintaan tarik. Perlu diingat bahwa tujuan kami adalah mempertahankan basis kode ringkas dengan keterbacaan tinggi.


