Whisper Finetune
1.0.0
ภาษาจีนง่ายๆ | ภาษาอังกฤษ
Openai เปิดโครงการ Whisper ซึ่งอ้างว่าได้ถึงระดับมนุษย์ของการจดจำเสียงภาษาอังกฤษและยังรองรับการจดจำเสียงอัตโนมัติใน 98 ภาษาอื่น ๆ การจดจำคำพูดอัตโนมัติและงานการแปลที่จัดทำโดย Whisper สามารถเปลี่ยนคำพูดเป็นภาษาต่าง ๆ เป็นข้อความและยังสามารถแปลข้อความเหล่านี้เป็นภาษาอังกฤษได้ วัตถุประสงค์หลักของโครงการนี้คือการปรับแต่งโมเดล Whisper โดยใช้ LORA, สนับสนุนการฝึกอบรมข้อมูลการประทับเวลาการฝึกอบรมข้อมูลการประทับเวลาและการฝึกอบรมข้อมูลที่ไม่พูด ปัจจุบันมีหลายรุ่นที่เปิด คุณสามารถดูได้ใน Openai รายการต่อไปนี้มีหลายรุ่นที่ใช้กันทั่วไป นอกจากนี้โครงการยังรองรับการอนุมานแบบเร่งความเร็ว CTRANSLATE2 และการอนุมานแบบเร่งความเร็ว GGML เพื่อเป็นการเตือนความจำการอนุมานแบบเร่งรัดรองรับการแปลงโดยตรงโดยใช้โมเดลดั้งเดิมของกระซิบและไม่จำเป็นต้องมีการปรับแต่งอย่างละเอียด รองรับแอปพลิเคชันเดสก์ท็อป Windows, แอปพลิเคชัน Android และการปรับใช้เซิร์ฟเวอร์
ทุกคนยินดีที่จะสแกนรหัส QR เพื่อเข้าสู่ Planet ความรู้ (ซ้าย) หรือกลุ่ม QQ (ขวา) สำหรับการอภิปราย Planet Planet ให้ไฟล์โมเดลโครงการและไฟล์อื่น ๆ ที่เกี่ยวข้องกับบล็อกเกอร์รวมถึงทรัพยากรอื่น ๆ
สภาพแวดล้อมการใช้งาน:
aishell.py : สร้างข้อมูลการฝึกอบรม Aishellfinetune.py : ปรับแต่งโมเดลmerge_lora.py : แบบจำลองที่รวม Whisper และ Loraevaluation.py : ประเมินโมเดลที่ปรับแต่งอย่างละเอียดหรือโมเดลดั้งเดิมของกระซิบinfer.py : ใช้แบบจำลองที่ปรับแต่งเพื่อเรียกหรือโมเดล Whisper บนหม้อแปลงเพื่อทำนายinfer_ct2.py : ใช้โมเดลที่แปลงเป็น ctranslate2 เพื่อทำนายส่วนใหญ่อ้างถึงการใช้งานของโปรแกรมนี้infer_gui.py : มีการทำงานของอินเทอร์เฟซ GUI โดยใช้แบบจำลองที่ปรับแต่งหรือโมเดลกระซิบบนหม้อแปลงเพื่อทำนายinfer_server.py : ใช้โมเดลที่ปรับแต่งหรือโมเดล Whisper บน Transformers เพื่อปรับใช้กับเซิร์ฟเวอร์และมอบให้กับไคลเอนต์เพื่อโทรconvert-ggml.py : แปลงโมเดลเป็นรูปแบบรูปแบบ GGML สำหรับแอปพลิเคชัน Android หรือ WindowsAndroidDemo : ไดเรกทอรีนี้เก็บซอร์สโค้ดสำหรับการปรับใช้โมเดลกับ AndroidWhisperDesktop : ไดเรกทอรีนี้จัดเก็บโปรแกรมสำหรับแอพพลิเคชั่นเดสก์ท็อป Windows | ใช้โมเดล | ระบุภาษา | aishell_test | test_net | test_meeting | ชุดทดสอบกวางตุ้ง | การซื้อกิจการแบบจำลอง |
|---|---|---|---|---|---|---|
| เสียงกระซิบ | ชาวจีน | 0.31898 | 0.40482 | 0.75332 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| ฐานเสียงกระซิบ | ชาวจีน | 0.22196 | 0.30404 | 0.50378 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| กระซิบ | ชาวจีน | 0.13897 | 0.18417 | 0.31154 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| เสียงกระซิบ-กลาง | ชาวจีน | 0.09538 | 0.13591 | 0.26669 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| กระซิบขนาดใหญ่ | ชาวจีน | 0.08969 | 0.12933 | 0.23439 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V2 | ชาวจีน | 0.08817 | 0.12332 | 0.26547 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V3 | ชาวจีน | 0.08086 | 0.11452 | 0.19878 | 0.18782 | เข้าร่วม Planet ความรู้เพื่อรับ |
| ใช้โมเดล | ระบุภาษา | ชุดข้อมูล | aishell_test | test_net | test_meeting | ชุดทดสอบกวางตุ้ง | การซื้อกิจการแบบจำลอง |
|---|---|---|---|---|---|---|---|
| เสียงกระซิบ | ชาวจีน | ไอชิล | 0.13043 | 0.4463 | 0.57728 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| ฐานเสียงกระซิบ | ชาวจีน | ไอชิล | 0.08999 | 0.33089 | 0.40713 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| กระซิบ | ชาวจีน | ไอชิล | 0.05452 | 0.19831 | 0.24229 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| เสียงกระซิบ-กลาง | ชาวจีน | ไอชิล | 0.03681 | 0.13073 | 0.16939 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V2 | ชาวจีน | ไอชิล | 0.03139 | 0.12201 | 0.15776 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V3 | ชาวจีน | ไอชิล | 0.03660 | 0.09835 | 0.13706 | 0.20060 | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V3 | กวางตุ้ง | ชุดข้อมูลกวางตุ้ง | 0.06857 | 0.11369 | 0.17452 | 0.03524 | เข้าร่วม Planet ความรู้เพื่อรับ |
| เสียงกระซิบ | ชาวจีน | Wenetspeech | 0.17711 | 0.24783 | 0.39226 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| ฐานเสียงกระซิบ | ชาวจีน | Wenetspeech | 0.14548 | 0.17747 | 0.30590 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| กระซิบ | ชาวจีน | Wenetspeech | 0.08484 | 0.11801 | 0.23471 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| เสียงกระซิบ-กลาง | ชาวจีน | Wenetspeech | 0.05861 | 0.08794 | 0.19486 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V2 | ชาวจีน | Wenetspeech | 0.05443 | 0.08367 | 0.19087 | N/A | เข้าร่วม Planet ความรู้เพื่อรับ |
| Whisper-Large-V3 | ชาวจีน | Wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | เข้าร่วม Planet ความรู้เพื่อรับ |
test_long.wav และระยะเวลาคือ 3 นาที โปรแกรมทดสอบอยู่ใน tools/run_compute.sh| วิธีการเร่งความเร็ว | ขนาดเล็ก | ฐาน | เล็ก | ปานกลาง | ขนาดใหญ่ V2 | ขนาดใหญ่ V3 |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1.458s | 1.671s | 2.331s | 11.071s | 4.779S | 12.826S |
Transformers ( fp16 + batch_size=16 + Compile ) | 1.477S | 1.675S | 2.357s | 11.003s | 4.799S | 12.643s |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461s | 1.676S | 2.301s | 11.062s | 4.608s | 12.505s |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436S | 1.630s | 2.258s | 10.533s | 4.344S | 11.651s |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442S | 1.686s | 2.277s | 11.000s | 4.543s | 12.592S |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1.643s | 2.220s | 10.390s | 4.377s | 11.703s |
เสียงกระซิบเร็วขึ้น ( fp16 + beam_size=1 ) | 2.179s | 1.492S | 2.327s | 3.752S | 5.677s | 31.541s |
เสียงกระซิบเร็วขึ้น ( 8-bit + beam_size=1 ) | 2.609s | 1.728s | 2.744S | 4.688s | 6.571s | 29.307s |
| วิธีการประมวลผลรายการข้อมูล | ไอชิล | Wenetspeech |
|---|---|---|
| เพิ่มเครื่องหมายวรรคตอน | เข้าร่วม Planet ความรู้เพื่อรับ | เข้าร่วม Planet ความรู้เพื่อรับ |
| เพิ่มเครื่องหมายวรรคตอนและการประทับเวลา | เข้าร่วม Planet ความรู้เพื่อรับ | เข้าร่วม Planet ความรู้เพื่อรับ |
หมายเหตุสำคัญ:
aishell_test เป็นชุดทดสอบของ aishell และ test_net และ test_meeting เป็นชุดทดสอบของ Wenetspeechdataset/test_long.wav และระยะเวลาคือ 3 นาทีconda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel จากนั้นป้อนภาพและติดตั้งเส้นทางปัจจุบันไปยังไดเรกทอรี /workspace ของคอนเทนเนอร์
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl ชุดข้อมูลการฝึกอบรมมีดังนี้ซึ่งเป็นรายการข้อมูลของ JsonLines นั่นคือแต่ละแถวเป็นข้อมูล JSON และรูปแบบข้อมูลมีดังนี้ โครงการนี้ให้โปรแกรม aishell.py ที่ทำให้ชุดข้อมูล aishell การดำเนินการโปรแกรมนี้สามารถดาวน์โหลดและสร้างชุดการฝึกอบรมและทดสอบในรูปแบบต่อไปนี้โดยอัตโนมัติ หมายเหตุ: โปรแกรมนี้สามารถข้ามกระบวนการดาวน์โหลดได้โดยระบุไฟล์บีบอัดของ Aishell หากดาวน์โหลดโดยตรงมันจะช้ามาก คุณสามารถใช้ตัวดาวน์โหลดบางตัวเช่น Thunder และผู้ดาวน์โหลดอื่น ๆ จากนั้นระบุเส้นทางไฟล์ที่ถูกดาวน์โหลดที่ดาวน์โหลดผ่านพารามิเตอร์ --filepath เช่น /home/test/data_aishell.tgz
เคล็ดลับ:
sentences ได้language ได้sentences ประโยคคือ [] ฟิลด์ sentence คือ "" และอาจไม่มีฟิลด์ language{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} เมื่อข้อมูลถูกเตรียมแล้วคุณสามารถเริ่มปรับแต่งโมเดลได้อย่างละเอียด พารามิเตอร์ที่สำคัญที่สุดสองประการสำหรับการฝึกอบรมคือ: --base_model ระบุโมเดล Whisper ที่ปรับแต่งอย่างละเอียด ค่าพารามิเตอร์นี้ต้องมีอยู่ใน HuggingFace สิ่งนี้ไม่จำเป็นต้องดาวน์โหลดล่วงหน้า สามารถดาวน์โหลดได้โดยอัตโนมัติเมื่อเริ่มการฝึกอบรม แน่นอนว่าสามารถดาวน์โหลดได้ล่วงหน้า จากนั้น --base_model ระบุคือเส้นทางและ --local_files_only ถูกตั้งค่าเป็นจริง ครั้งที่สอง --output_path คือเส้นทางจุดตรวจ LORA ที่บันทึกไว้ในระหว่างการฝึกอบรมเพราะเราใช้ LORA เพื่อปรับแต่งโมเดล หากคุณต้องการประหยัดเพียงพอควรตั้ง --use_8bit เป็นเท็จเพื่อให้ความเร็วในการฝึกอบรมเร็วขึ้นมาก สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
คำสั่งการฝึกอบรมการ์ดใบเดียวมีดังนี้ ระบบ Windows ไม่สามารถเพิ่มพารามิเตอร์ CUDA_VISIBLE_DEVICES
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/มีสองวิธีสำหรับการฝึกอบรมหลายการ์ดคือการเกิดภาวะคลังและเร่งความเร็ว นักพัฒนาสามารถใช้วิธีการที่สอดคล้องกันตามนิสัยของตนเอง
--nproc_per_node torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/ขั้นแรกให้กำหนดค่าพารามิเตอร์การฝึกอบรม กระบวนการคือขอให้นักพัฒนาตอบคำถามหลายข้อ โดยทั่วไปจะทำโดยค่าเริ่มต้น แต่มีพารามิเตอร์หลายอย่างที่ต้องตั้งค่าตามสถานการณ์จริง
accelerate configนี่อาจเป็นกระบวนการ:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
หลังจากการกำหนดค่าเสร็จสมบูรณ์คุณสามารถใช้คำสั่งต่อไปนี้เพื่อดูการกำหนดค่า
accelerate envคำสั่งเริ่มต้นการฝึกอบรมมีดังนี้
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/บันทึกเอาต์พุตมีดังนี้:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} หลังจากการปรับแต่งเสร็จสมบูรณ์จะมีสองรุ่น อย่างแรกคือโมเดลพื้นฐานของ Whisper และรุ่นที่สองคือรุ่น LORA ทั้งสองรุ่นนี้จำเป็นต้องรวมกันก่อนที่จะสามารถดำเนินการต่อไปได้ โปรแกรมนี้ต้องผ่านพารามิเตอร์สองตัวเท่านั้น --lora_model ระบุเส้นทางโมเดล LORA ที่บันทึกไว้หลังจากการฝึกอบรมซึ่งเป็นเส้นทางโฟลเดอร์จุดตรวจสอบ ที่สอง --output_dir เป็นไดเรกทอรีที่บันทึกไว้ของโมเดลที่ผสาน
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ ขั้นตอนต่อไปนี้จะดำเนินการเพื่อประเมินโมเดลพารามิเตอร์ที่สำคัญที่สุดสองตัวคือ ครั้งแรก --model_path ระบุเส้นทางโมเดลที่ผสานและยังรองรับการใช้โมเดลดั้งเดิมของกระซิบโดยตรงเช่นการระบุ openai/whisper-large-v2 โดยตรงและที่สองคือ --metric ชี้วัดวิธีการประเมินเช่นอัตราความผิดพลาดของคำ cer และ wer ความผิดพลาดของคำ เคล็ดลับ: ไม่มีแบบจำลองที่ปรับแต่งได้และเอาต์พุตอาจถูกคั่นด้วยส่งผลกระทบต่อความแม่นยำ สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer ดำเนินการโปรแกรมต่อไปนี้สำหรับการรู้จำเสียงพูด สิ่งนี้ใช้ Transformers เพื่อเรียกใช้แบบจำลองที่ปรับแต่งหรือการทำนายแบบดั้งเดิมกระซิบโดยตรงและรองรับการเร่งความเร็วของคอมไพเลอร์การเร่งความเร็ว Flashattention2 และการเร่งความเร็วที่ดีกว่าของ Pytorch2.0 พารามิเตอร์แรก --audio_path ระบุเส้นทางเสียงเพื่อทำนาย ครั้งที่สอง --model_path ระบุเส้นทางโมเดลที่ผสานและยังรองรับการใช้โมเดลดั้งเดิมของกระซิบโดยตรงเช่นการระบุ openai/whisper-large-v2 โดยตรง สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path ระบุโมเดล Transformers สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
python infer_gui.py --model_path=models/whisper-tiny-finetuneอินเทอร์เฟซหลังการเริ่มต้นมีดังนี้:
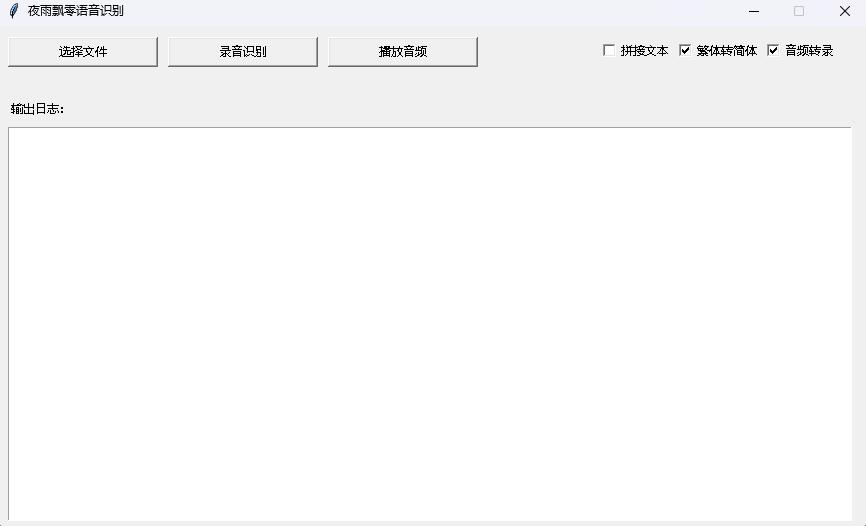
--host ระบุที่อยู่ของการเริ่มต้นบริการซึ่งตั้งค่าเป็น 0.0.0.0 นั่นคือที่อยู่ใด ๆ สามารถเข้าถึงได้ --port ระบุหมายเลขพอร์ตที่ใช้ --model_path ระบุโมเดล Transformers --num_workers ระบุจำนวนเธรดที่ใช้ในการอนุมานพร้อมกันซึ่งมีความสำคัญในการปรับใช้เว็บ เมื่อมีการเข้าถึงที่เกิดขึ้นพร้อมกันหลายครั้งอาจเป็นไปได้ที่จะให้เหตุผลในเวลาเดียวกัน สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 ขณะนี้มีการระบุอินเทอร์เฟซ /recognition การระบุและพารามิเตอร์อินเตอร์เฟสมีดังนี้
| ทุ่งนา | จำเป็นหรือไม่ | พิมพ์ | ค่าเริ่มต้น | อธิบาย |
|---|---|---|---|---|
| เสียง | ใช่ | ไฟล์ | ไฟล์เสียงที่จะระบุ | |
| to_simple | เลขที่ | int | 1 | ไม่ว่าจะเปลี่ยนเป็นภาษาจีนดั้งเดิม |
| remove_pun | เลขที่ | int | 0 | ไม่ว่าจะลบเครื่องหมายวรรคตอน |
| งาน | เลขที่ | สาย | การถอดเสียง | ระบุประเภทงานสนับสนุนการถอดความและแปล |
| ภาษา | เลขที่ | สาย | zh | ตั้งค่าภาษาตัวย่อถ้าไม่มีให้ตรวจจับภาษาโดยอัตโนมัติ |
ผลการส่งคืน:
| ทุ่งนา | พิมพ์ | อธิบาย |
|---|---|---|
| ผลลัพธ์ | รายการ | ผลการระบุการแบ่งส่วน |
| +ผลลัพธ์ | Str | ผลลัพธ์ของข้อความแต่ละชิ้น |
| +เริ่ม | int | เวลาเริ่มต้นของแต่ละชิ้นหน่วยวินาที |
| +จบ | int | เวลาสิ้นสุดของแต่ละชิ้นหน่วยวินาที |
| รหัส | int | รหัสข้อผิดพลาด 0 เป็นบัตรประจำตัวที่ประสบความสำเร็จ |
ตัวอย่างมีดังนี้:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} เพื่อความเข้าใจง่ายนี่คือรหัส Python ที่เรียกเว็บอินเตอร์เฟส ต่อไปนี้เป็นวิธีการโทรของ /recognition
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )หน้าทดสอบที่ให้ไว้มีดังนี้:
หน้าโฮมเพจ http://127.0.0.1:5000/ มีดังนี้:
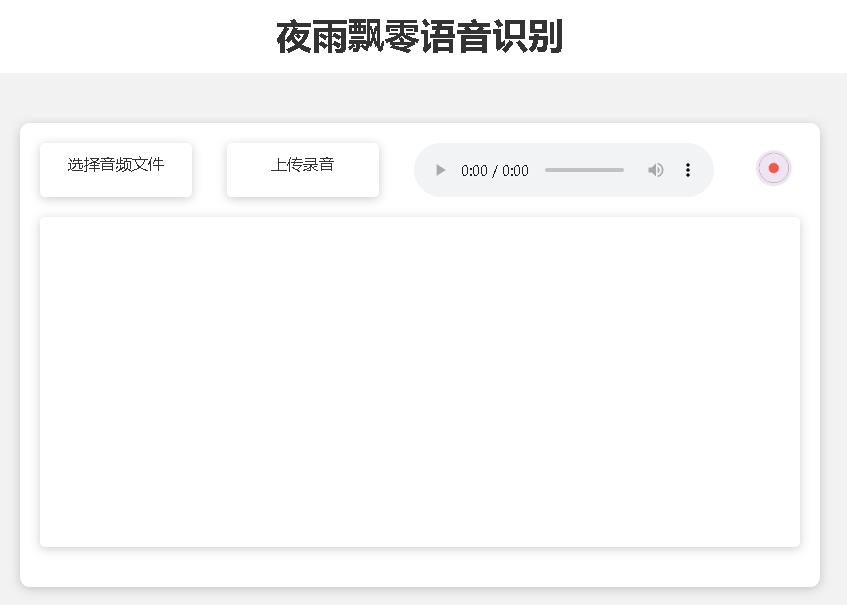
หน้าเอกสาร http://127.0.0.1:5000/docs หน้ามีดังนี้:
นี่คือวิธีเร่ง CTRANSLATE2 แม้ว่าความเร็วในการใช้เหตุผลในการใช้หม้อแปลงจะเร็วมาก แต่คุณต้องแปลงโมเดลก่อนและแปลงโมเดลที่ผสานเป็นรุ่น CTRANSLATE2 ตามคำสั่งต่อไปนี้พารามิเตอร์ --model ระบุเส้นทางโมเดลที่ผสานและยังรองรับการใช้โมเดลดั้งเดิมของกระซิบโดยตรงเช่นระบุ openai/whisper-large-v2 โดยตรง พารามิเตอร์ --output_dir ระบุเส้นทางโมเดล CTRANSLATE2 ที่แปลงแล้วและพารามิเตอร์ --quantization ระบุขนาดของโมเดล Quantization หากคุณไม่ต้องการรูปแบบการหาปริมาณคุณสามารถลบพารามิเตอร์นี้ได้โดยตรง
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 ดำเนินการโปรแกรมต่อไปนี้สำหรับการจดจำคำพูดพารามิเตอร์ --audio_path ระบุเส้นทางเสียงที่จะทำนาย --model_path ระบุรุ่น CTRANSLATE2 ที่แปลงแล้ว สำหรับพารามิเตอร์อื่น ๆ เพิ่มเติมโปรดตรวจสอบโปรแกรมนี้
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2ผลลัพธ์ผลลัพธ์มีดังนี้:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
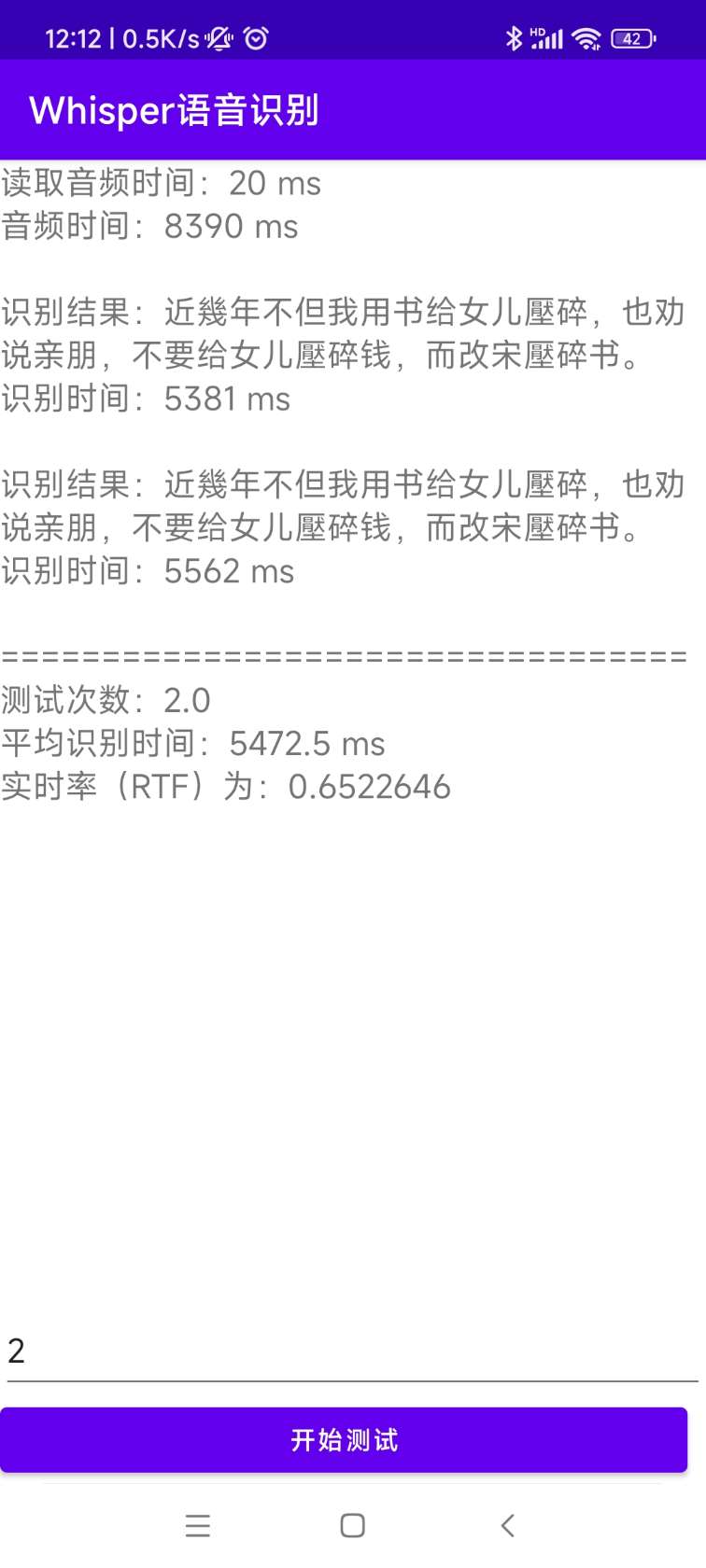
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 ซอร์สโค้ดสำหรับการติดตั้งและการปรับใช้อยู่ในไดเรกทอรี AndroidDemo เอกสารเฉพาะสามารถดูได้ใน readme.md ในไดเรกทอรีนี้



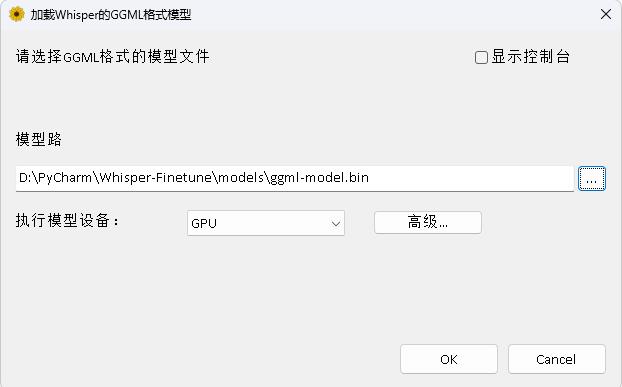
โปรแกรมอยู่ในไดเรกทอรี Whisperdesktop เอกสารเฉพาะสามารถดูได้ที่ readme.md ในไดเรกทอรีนี้
ให้รางวัลหนึ่งดอลลาร์เพื่อสนับสนุนผู้เขียน


