Whisper Finetune
1.0.0
Vereinfachtes Chinesisch | Englisch
OpenAI öffnet das Whisper -Projekt, das behauptet, die menschliche Ebene der englischen Spracherkennung erreicht zu haben, und unterstützt auch die automatische Spracherkennung in anderen 98 Sprachen. Die automatischen Spracherkennungs- und Übersetzungsaufgaben von Whisper können Sprache in verschiedenen Sprachen in Text verwandeln und diese Texte auch ins Englische übersetzen. Der Hauptzweck dieses Projekts besteht darin, das Flüstermodell mit LORA, dem Time Stamp Data-Training, dem Zeitstempeldaten Training und dem sprachlosen Datentraining zu optimieren. Derzeit sind mehrere Modelle offen. Sie können sie in Openai anzeigen. Die folgenden Listen sind mehrere häufig verwendete Modelle. Darüber hinaus unterstützt das Projekt auch Ctranslate2 beschleunigte Inferenz und GGML -beschleunigte Inferenz. Als Erinnerung unterstützt eine beschleunigte Inferenz eine direkte Konvertierung mithilfe von Whisper-Originalmodell und erfordert nicht unbedingt eine Feinabstimmung. Unterstützt Windows Desktop -Anwendungen, Android -Anwendungen und Serverbereitstellung.
Jeder ist herzlich eingeladen, den QR -Code zu scannen, um den Knowledge Planet (links) oder die QQ -Gruppe (rechts) zur Diskussion einzugeben. Der Knowledge Planet bietet Projektmodelldateien und andere verwandte Projektdateien von Bloggern sowie einige andere Ressourcen.
Nutzungsumgebung:
aishell.py : Machen Sie Aishell -Trainingsdaten.finetune.py : Feinstimmen Sie das Modell.merge_lora.py : Ein Modell, das Flüster und Lora zusammenführt.evaluation.py : Bewerten Sie das fein abgestimmte Modell oder das ursprüngliche Flüstermodell.infer.py : Verwenden Sie das fein abgestimmte Modell, um oder das Flüstermodell auf Transformatoren vorherzusagen.infer_ct2.py : Verwenden Sie das in ctranslate2 konvertierte Modell, um vorherzusagen, hauptsächlich auf die Verwendung dieses Programms.infer_gui.py : Es gibt eine GUI-Schnittstellenoperation unter Verwendung des feinstimmigen Modells oder des Flüstermodells für Transformatoren, um vorherzusagen.infer_server.py : Verwenden Sie das feinstimmige Modell oder das Flüstermodell auf Transformatoren, um sie auf dem Server bereitzustellen und es dem Client zur Anruf anzugeben.convert-ggml.py : Konvertieren Sie das Modell in das GGML-Formatmodell für Android- oder Windows-Anwendungen.AndroidDemo : Dieses Verzeichnis speichert den Quellcode für die Bereitstellung des Modells für Android.WhisperDesktop : Dieses Verzeichnis speichert Programme für Windows -Desktop -Anwendungen. | Verwenden des Modells | Sprache angeben | Aishell_test | test_net | test_meeting | Kantonesischer Testsatz | Modellakquisition |
|---|---|---|---|---|---|---|
| flüstere | chinesisch | 0,31898 | 0,40482 | 0,75332 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüsterbasis | chinesisch | 0,22196 | 0,30404 | 0,50378 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüstern | chinesisch | 0,13897 | 0,18417 | 0,31154 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüstermedium | chinesisch | 0,09538 | 0,13591 | 0,26669 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüstern | chinesisch | 0,08969 | 0,12933 | 0,23439 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v2 | chinesisch | 0,08817 | 0,12332 | 0,26547 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v3 | chinesisch | 0,08086 | 0,11452 | 0,19878 | 0,18782 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Verwenden des Modells | Sprache angeben | Datensatz | Aishell_test | test_net | test_meeting | Kantonesischer Testsatz | Modellakquisition |
|---|---|---|---|---|---|---|---|
| flüstere | chinesisch | Aishell | 0,13043 | 0,4463 | 0,57728 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüsterbasis | chinesisch | Aishell | 0,08999 | 0,33089 | 0,40713 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüstern | chinesisch | Aishell | 0,05452 | 0,19831 | 0,24229 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüstermedium | chinesisch | Aishell | 0,03681 | 0,13073 | 0,16939 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v2 | chinesisch | Aishell | 0,03139 | 0,12201 | 0,15776 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v3 | chinesisch | Aishell | 0,03660 | 0,09835 | 0,13706 | 0,20060 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v3 | Kantonesisch | Kantonesischer Datensatz | 0,06857 | 0,11369 | 0,17452 | 0,03524 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüstere | chinesisch | Wenetspeech | 0,17711 | 0,24783 | 0,39226 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüsterbasis | chinesisch | Wenetspeech | 0,14548 | 0,17747 | 0,30590 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüstern | chinesisch | Wenetspeech | 0,08484 | 0,11801 | 0,23471 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Flüstermedium | chinesisch | Wenetspeech | 0,05861 | 0,08794 | 0,19486 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v2 | chinesisch | Wenetspeech | 0,05443 | 0,08367 | 0,19087 | N / A | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| flüsterlarge-v3 | chinesisch | Wenetspeech | 0,04947 | 0,10711 | 0,17429 | 0,47431 | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
test_long.wav und die Dauer 3 Minuten. Das Testprogramm befindet sich in tools/run_compute.sh .| Beschleunigungsmethode | winzig | Base | Klein | Medium | Large-V2 | Large-V3 |
|---|---|---|---|---|---|---|
Transformatoren ( fp16 + batch_size=16 ) | 1,458s | 1,671s | 2.331s | 11.071s | 4.779s | 12.826s |
Transformatoren ( fp16 + batch_size=16 + Compile ) | 1.477s | 1,675s | 2.357s | 11.003s | 4.799s | 12.643s |
Transformatoren ( fp16 + batch_size=16 + BetterTransformer ) | 1.461s | 1,676s | 2.301s | 11.062s | 4.608s | 12.505s |
Transformatoren ( fp16 + batch_size=16 + Flash Attention 2 ) | 1,436s | 1.630s | 2.258s | 10.533s | 4.344s | 11.651s |
Transformatoren ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1,686s | 2.277s | 11.000S | 4,543s | 12.592s |
Transformatoren ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1,643S | 2.220s | 10.390s | 4.377s | 11.703s |
Schnelleres Flüsterung ( fp16 + beam_size=1 ) | 2.179s | 1.492s | 2.327s | 3.752s | 5.677s | 31.541s |
Schnelleres Flüstern ( 8-bit + beam_size=1 ) | 2.609s | 1,728s | 2.744s | 4.688s | 6.571s | 29.307s |
| Datenlistenverarbeitungsmethode | Aishell | Wenetspeech |
|---|---|---|
| Interpunktion hinzufügen | Schließen Sie sich dem Wissensplanet an, um zu erhalten | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
| Zeichensetzung und Zeitstempel hinzufügen | Schließen Sie sich dem Wissensplanet an, um zu erhalten | Schließen Sie sich dem Wissensplanet an, um zu erhalten |
Wichtiger Hinweis:
aishell_test ist der Testsatz von Aishell, und test_net und test_meeting sind die Testsätze von Wenetspeech.dataset/test_long.wav und die Dauer 3 Minuten.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Geben Sie dann das Bild ein und montieren Sie den aktuellen Pfad zum Verzeichnis /workspace des Containers.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl Der Trainingsdatensatz lautet wie folgt, eine Datenliste von JSONLINES, dh jeder Zeile ist ein JSON -Daten, und das Datenformat lautet wie folgt. Dieses Projekt bietet ein Programm aishell.py , das den Aishell -Datensatz macht. Durch Ausführen dieses Programms können automatisch Trainings- und Testsätze in den folgenden Formaten heruntergeladen und generiert werden. Hinweis: Dieses Programm kann den Download -Prozess überspringen, indem die komprimierten Dateien von Aishell angegeben werden. Wenn es direkt heruntergeladen wird, ist es sehr langsam. Sie können einige Downloader wie Donner und andere Downloader verwenden und dann den heruntergeladenen komprimierten Dateipfad über den Parameter --filepath wie /home/test/data_aishell.tgz angeben.
Tipps:
sentences einbeziehen.language enthalten.sentences [] , sentence Satzfeld ist "" und language ist möglicherweise nicht vorhanden.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Sobald die Daten erstellt wurden, können Sie das Modell mit der Feinabstimmung beginnen. Die beiden wichtigsten Parameter für das Training sind: --base_model gibt das fein abgestimmte Flüstermodell an. Dieser Parameterwert muss in der Umarmung vorhanden sein. Dies erfordert keinen Vorab -Download. Es kann automatisch heruntergeladen werden, wenn Sie mit dem Training beginnen. Natürlich kann es auch im Voraus heruntergeladen werden. Dann --base_model gibt an, ist der Pfad, und --local_files_only ist auf true eingestellt. Der zweite --output_path ist der Lora-Checkpoint-Pfad, der während des Trainings gespeichert ist, da wir Lora verwenden, um das Modell zu optimieren. Wenn Sie genug sparen möchten, ist es am besten, --use_8bit zu False, damit die Trainingsgeschwindigkeit viel schneller ist. Weitere weitere Parameter finden Sie in diesem Programm.
Der Einzelkartentrainingsbefehl lautet wie folgt. Das Windows -System kann CUDA_VISIBLE_DEVICES nicht hinzufügen.
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Es gibt zwei Methoden zum Multi-Karten-Training, nämlich Torchrun und Beschleunigung. Entwickler können die entsprechenden Methoden entsprechend ihren eigenen Gewohnheiten anwenden.
--nproc_per_node zu verwenden. torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Konfigurieren Sie zunächst die Trainingsparameter. Der Prozess besteht darin, den Entwickler zu bitten, mehrere Fragen zu beantworten. Dies erfolgt im Grunde standardmäßig, aber es gibt mehrere Parameter, die gemäß der tatsächlichen Situation festgelegt werden müssen.
accelerate configDies ist wahrscheinlich der Prozess:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
Nach Abschluss der Konfiguration können Sie den folgenden Befehl verwenden, um die Konfiguration anzuzeigen.
accelerate envDer Start -Training -Befehl lautet wie folgt.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/Das Ausgabeprotokoll lautet wie folgt:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} Nach Abschluss der Feinabstimmung wird es zwei Modelle geben. Das erste ist das Whisper Basic -Modell und das zweite ist das Lora -Modell. Diese beiden Modelle müssen zusammengeführt werden, bevor nachfolgende Operationen durchgeführt werden können. Dieses Programm muss nur zwei Parameter übergeben. --lora_model gibt den nach dem Training gespeicherten LORA-Modellpfad an, der eigentlich der Checkpoint-Ordnerpfad ist. Das zweite --output_dir ist das gespeicherte Verzeichnis des fusionierten Modells.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Die folgenden Verfahren werden ausgeführt, um das Modell zu bewerten, die beiden wichtigsten Parameter. Der erste- --model_path gibt den fusionierten Modellpfad an und unterstützt auch die Verwendung von Whisper openai/whisper-large-v2 Originalmodell --metric , wer cer TIPP: Es gibt kein fein abgestimmtes Modell, und die Ausgabe kann unterbrochen werden, was die Genauigkeit beeinflusst. Weitere weitere Parameter finden Sie in diesem Programm.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Führen Sie das folgende Programm zur Spracherkennung aus. Dadurch wird Transformatoren verwendet, um das feine Modell- oder Flüsternungs-Originalmodellvorhersage direkt aufzurufen und Compiler Acceleration, Flashattention2 Acceleration und BetterTransformer Acceleration von Pytorch2.0 zu unterstützen. Der erste Parameter --audio_path gibt den Audio -Pfad an, der vorherzusagen ist. Der zweite- --model_path gibt den fusionierten Modellpfad an und unterstützt auch die Verwendung von Whisper-Originalmodell direkt, z openai/whisper-large-v2 Weitere weitere Parameter finden Sie in diesem Programm.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path gibt das Transformators-Modell an. Weitere weitere Parameter finden Sie in diesem Programm.
python infer_gui.py --model_path=models/whisper-tiny-finetuneDie Schnittstelle nach dem Start lautet wie folgt:
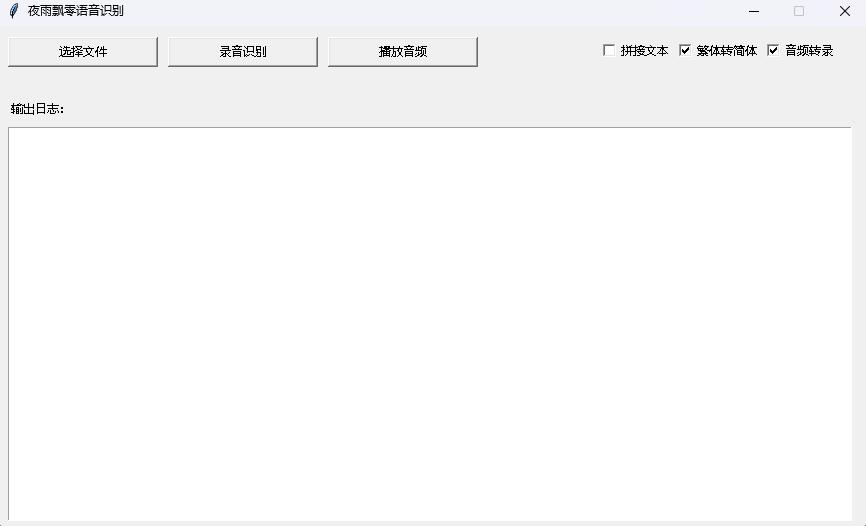
--host gibt die Adresse des Service-Startups an, das auf 0.0.0.0 festgelegt ist, dh auf jede Adresse zugegriffen werden kann. --port Gibt die verwendete Portnummer an. --model_path gibt Transformatorenmodell an. --num_workers gibt an, wie viele Threads zur gleichzeitigen Inferenz verwendet werden, was für die Webbereitstellung wichtig ist. Wenn es mehrere gleichzeitige Zugriffe gibt, ist es möglich, gleichzeitig zu argumentieren. Weitere weitere Parameter finden Sie in diesem Programm.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Derzeit wird die Identifikationsschnittstelle /recognition bereitgestellt, und die Schnittstellenparameter sind wie folgt.
| Felder | Ist es notwendig? | Typ | Standardwert | veranschaulichen |
|---|---|---|---|---|
| Audio- | Ja | Datei | Audio -Datei zu identifizieren | |
| to_Simple | NEIN | int | 1 | Ob Sie auf traditionelle Chinesisch wechseln sollten |
| remove_pun | NEIN | int | 0 | Ob Interpunktionsmarken entfernen sollen |
| Aufgabe | NEIN | Saite | Transkript | Identifizieren Sie Aufgabentypen, unterstützen Sie Transkribe und übersetzen |
| Sprache | NEIN | Saite | Zh | Setzen Sie Sprache, Abkürzung, wenn keine, die Sprache automatisch erkennen |
Rückgabeergebnis:
| Felder | Typ | veranschaulichen |
|---|---|---|
| Ergebnisse | Liste | Segmentierungsidentifizierungsergebnisse |
| +Ergebnis | str | Das Ergebnis jedes Textstücks |
| +Start | int | Die Startzeit jedes Scheibens, Einheitensekunden |
| +Ende | int | Die Endzeit jedes Scheibens, Einheitensekunden |
| Code | int | Fehlercode, 0 ist eine erfolgreiche Identifizierung |
Beispiele sind wie folgt:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Für das einfache Verständnis finden Sie hier einen Python -Code, der die Weboberfläche aufruft. Das Folgende ist die Anrufmethode von /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )Die bereitgestellten Testseiten sind wie folgt:
Die Seite der Homepage http://127.0.0.1:5000/ lautet wie folgt:
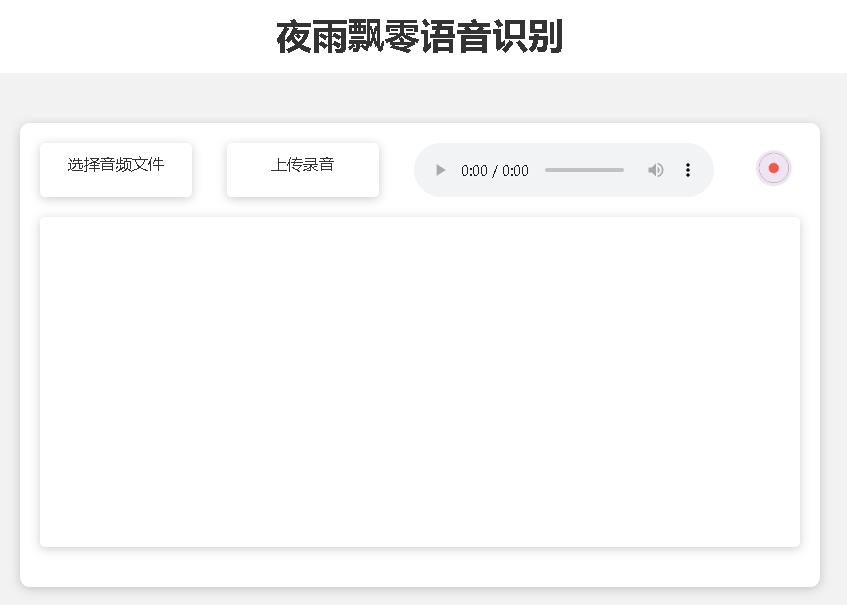
Die Dokumentseite http://127.0.0.1:5000/docs ist wie folgt:
Hier ist eine Möglichkeit, Ctranslate2 zu beschleunigen2. Obwohl die Pipeline -Argumentationsgeschwindigkeit der Verwendung von Transformatoren bereits sehr schnell ist, müssen Sie zunächst das Modell umwandeln und das fusionierte Modell in das Ctranslate2 -Modell umwandeln. Als folgender Befehl gibt --model den fusionierten Modellpfad an und unterstützt auch die Verwendung von Whisper-Originalmodell direkt, z openai/whisper-large-v2 Der Parameter --output_dir gibt den konvertierten Ctranslate2 -Modellpfad an, und der Parameter --quantization gibt die Quantisierungsmodellgröße an. Wenn Sie das Quantisierungsmodell nicht möchten, können Sie diesen Parameter direkt entfernen.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Führen Sie das folgende Programm für die Spracherkennung aus, --audio_path gibt den zu vorhergesagten Audiopfad an. --model_path gibt das konvertierte ctranslate2-Modell an. Weitere weitere Parameter finden Sie in diesem Programm.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2Das Ausgabeergebnis ist wie folgt:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
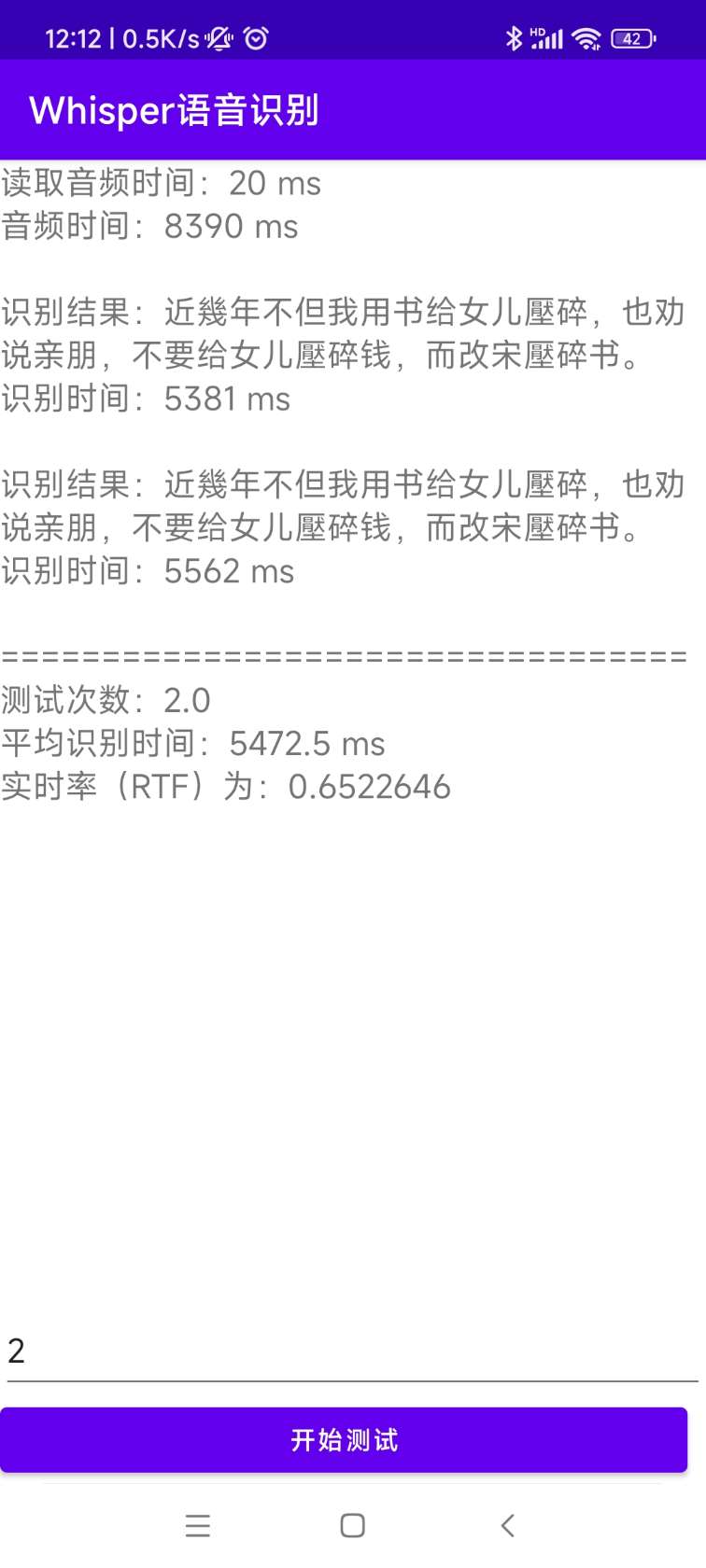
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 Der Quellcode für die Installation und Bereitstellung befindet sich im Androiddemo -Verzeichnis. Die spezifischen Dokumente können in diesem Verzeichnis in Readme.md angezeigt werden.



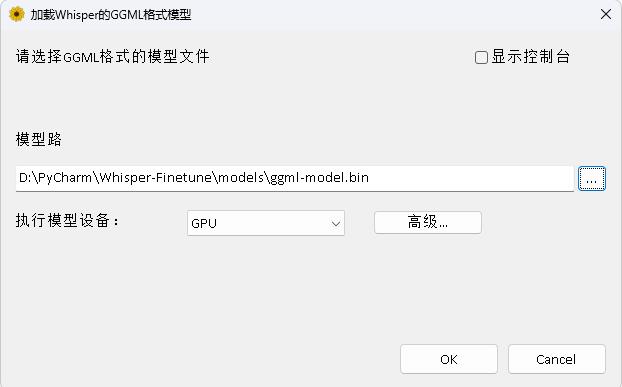
Das Programm befindet sich im Verzeichnis whisperDesktop. Die spezifischen Dokumente können in diesem Verzeichnis bei Readme.md angezeigt werden.
Belohnen Sie einen Dollar, um den Autor zu unterstützen


