Whisper Finetune
1.0.0
تبسيط الصينية | إنجليزي
يفتح Openai مشروع Whisper ، الذي يدعي أنه وصل إلى المستوى البشري للتعرف على الصوت الإنجليزي ، كما يدعم التعرف التلقائي على الصوت بلغ 98 لغة أخرى. يمكن لمهام التعرف على الكلام والترجمة التلقائي التي يوفرها Whisper تحويل الكلام بلغات مختلفة إلى نص ، ويمكن أيضًا ترجمة هذه النصوص إلى اللغة الإنجليزية. الغرض الرئيسي من هذا المشروع هو ضبط نموذج الهمس باستخدام LORA ، وتدريب بيانات الطوابع الزمنية ، والتدريب على بيانات الطوابع الزمنية ، والتدريب على البيانات بدون الكلام . حاليا ، العديد من الطرز مفتوحة مصدر. يمكنك مشاهدتها في Openai. فيما يلي العديد من النماذج شائعة الاستخدام. بالإضافة إلى ذلك ، يدعم المشروع أيضًا الاستدلال المتسارع Ctranslate2 و GGML المتسارع. كتذكير ، يدعم الاستدلال المتسارع التحويل المباشر باستخدام النموذج الأصلي الهامس ، ولا يتطلب بالضرورة ضبطًا دقيقًا. يدعم تطبيقات سطح المكتب Windows وتطبيقات Android ونشر الخادم.
الجميع مرحب بهم لمسح رمز الاستجابة السريعة لإدخال كوكب المعرفة (يسار) أو مجموعة QQ (يمين) للمناقشة. يوفر Knowledge Planet ملفات طراز المشروع والمدونين المدونين الأخرى ذات الصلة ، بالإضافة إلى بعض الموارد الأخرى.
بيئة الاستخدام:
aishell.py : اجعل بيانات تدريب Aishell.finetune.py : صقل النموذج.merge_lora.py : نموذج يدمج Whisper و Lora.evaluation.py : تقييم النموذج الذي تم ضبطه أو نموذج الهمس الأصلي.infer.py : استخدم النموذج الذي تم ضبطه للاتصال أو نموذج الهمس على المحولات للتنبؤ.infer_ct2.py : استخدم النموذج الذي تم تحويله إلى ctranslate2 للتنبؤ ، والرجوع بشكل أساسي إلى استخدام هذا البرنامج.infer_gui.py : هناك عملية واجهة واجهة المستخدم الرسومية ، باستخدام النموذج الذي تم ضبطه أو نموذج الهمس على المحولات للتنبؤ بها.infer_server.py : استخدم النموذج الذي تم ضبطه أو نموذج الهمس على المحولات للنشر على الخادم وتزويده بالعميل للاتصال.convert-ggml.py : قم بتحويل النموذج إلى نموذج تنسيق GGML لتطبيقات Android أو Windows.AndroidDemo : يقوم هذا الدليل بتخزين الكود المصدري لنشر النموذج على Android.WhisperDesktop : يخزن هذا الدليل برامج لتطبيقات سطح المكتب Windows. | باستخدام النموذج | حدد اللغة | Aishell_test | test_net | test_meeting | مجموعة اختبار الكانتونية | اكتساب النموذج |
|---|---|---|---|---|---|---|
| يهمس | الصينية | 0.31898 | 0.40482 | 0.75332 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس قاعدة | الصينية | 0.22196 | 0.30404 | 0.50378 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| يهمس | الصينية | 0.13897 | 0.18417 | 0.31154 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس المتوسط | الصينية | 0.09538 | 0.13591 | 0.26669 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| يهمس | الصينية | 0.08969 | 0.12933 | 0.23439 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v2 | الصينية | 0.08817 | 0.12332 | 0.26547 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v3 | الصينية | 0.08086 | 0.11452 | 0.19878 | 0.18782 | انضم إلى كوكب المعرفة للحصول على |
| باستخدام النموذج | حدد اللغة | مجموعة البيانات | Aishell_test | test_net | test_meeting | مجموعة اختبار الكانتونية | اكتساب النموذج |
|---|---|---|---|---|---|---|---|
| يهمس | الصينية | آيل | 0.13043 | 0.4463 | 0.57728 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس قاعدة | الصينية | آيل | 0.08999 | 0.33089 | 0.40713 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| يهمس | الصينية | آيل | 0.05452 | 0.19831 | 0.24229 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس المتوسط | الصينية | آيل | 0.03681 | 0.13073 | 0.16939 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v2 | الصينية | آيل | 0.03139 | 0.12201 | 0.15776 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v3 | الصينية | آيل | 0.03660 | 0.09835 | 0.13706 | 0.20060 | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v3 | الكانتونية | مجموعة البيانات الكانتونية | 0.06857 | 0.11369 | 0.17452 | 0.03524 | انضم إلى كوكب المعرفة للحصول على |
| يهمس | الصينية | Wenetspeech | 0.17711 | 0.24783 | 0.39226 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس قاعدة | الصينية | Wenetspeech | 0.14548 | 0.17747 | 0.30590 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| يهمس | الصينية | Wenetspeech | 0.08484 | 0.11801 | 0.23471 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس المتوسط | الصينية | Wenetspeech | 0.05861 | 0.08794 | 0.19486 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v2 | الصينية | Wenetspeech | 0.05443 | 0.08367 | 0.19087 | ن/أ | انضم إلى كوكب المعرفة للحصول على |
| الهمس large-v3 | الصينية | Wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | انضم إلى كوكب المعرفة للحصول على |
test_long.wav ، والمدة 3 دقائق. برنامج الاختبار في tools/run_compute.sh .| طريقة التسارع | صغير الحجم | قاعدة | صغير | واسطة | كبير V2 | كبير V3 |
|---|---|---|---|---|---|---|
المحولات ( fp16 + batch_size=16 ) | 1.458s | 1.671S | 2.331s | 11.071S | 4.779S | 12.826s |
المحولات ( fp16 + batch_size=16 + Compile ) | 1.477s | 1.675s | 2.357s | 11.003s | 4.799s | 12.643S |
المحولات ( fp16 + batch_size=16 + BetterTransformer | 1.461s | 1.676s | 2.301s | 11.062S | 4.608s | 12.505s |
المحولات ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436s | 1.630s | 2.258s | 10.533s | 4.344S | 11.651s |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1.686s | 2.277s | 11.000s | 4.543s | 12.592S |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409S | 1.643s | 2.220s | 10.390s | 4.377s | 11.703S |
همس أسرع ( fp16 + beam_size=1 ) | 2.179s | 1.492S | 2.327s | 3.752S | 5.677s | 31.541S |
همس أسرع ( 8-bit + beam_size=1 ) | 2.609s | 1.728s | 2.744S | 4.688s | 6.571s | 29.307s |
| طريقة معالجة قائمة البيانات | آيل | Wenetspeech |
|---|---|---|
| إضافة علامات الترقيم | انضم إلى كوكب المعرفة للحصول على | انضم إلى كوكب المعرفة للحصول على |
| إضافة علامات الترقيم والجداول الزمنية | انضم إلى كوكب المعرفة للحصول على | انضم إلى كوكب المعرفة للحصول على |
ملاحظة مهمة:
aishell_test هي مجموعة اختبار Aishell ، و test_net و test_meeting هي مجموعات اختبار wenetspeech.dataset/test_long.wav ، والمدة 3 دقائق.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel ثم أدخل الصورة وقم بتركيب المسار الحالي إلى دليل /workspace للحاوية.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl مجموعة بيانات التدريب هي كما يلي ، وهي قائمة بيانات من jsonlines ، أي أن كل صف عبارة عن بيانات JSON ، وتنسيق البيانات كما يلي. يوفر هذا المشروع برنامج aishell.py الذي يجعل Aishell Data Set. يمكن تنفيذ هذا البرنامج تلقائيًا تنزيل وإنشاء مجموعات التدريب والاختبار بالتنسيقات التالية. ملاحظة: يمكن لهذا البرنامج تخطي عملية التنزيل من خلال تحديد ملفات Aishell المضغوطة. إذا تم تنزيله مباشرة ، فسيكون بطيئًا جدًا. يمكنك استخدام بعض عمليات التنزيل مثل Thunder وغيرها من عمليات التنزيل ، ثم تحديد مسار الملف المضغوط الذي تم تنزيله من خلال المعلمة --filepath ، مثل /home/test/data_aishell.tgz .
نصائح:
sentences .language .sentences هو [] ، وحقل sentence "" وقد لا يكون حقل language موجودًا.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} بمجرد تحضير البيانات ، يمكنك بدء صياغة النموذج. المعلمتين الأكثر أهمية للتدريب هما: --base_model يحدد نموذج الهمس الدقيق. يجب أن توجد قيمة المعلمة هذه في Luggingface. هذا لا يتطلب تحميل مسبق. يمكن تنزيله تلقائيًا عند بدء التدريب. بالطبع ، يمكن أيضًا تنزيله مسبقًا. ثم --base_model يحدد هو المسار ، و- --local_files_only تم ضبطه على صحيح. والثاني- --output_path هو مسار نقطة تفتيش Lora المحفوظة أثناء التدريب ، لأننا نستخدم Lora لضبط النموذج. إذا كنت ترغب في توفير ما يكفي ، فمن الأفضل ضبط --use_8bit على خطأ ، بحيث تكون سرعة التدريب أسرع بكثير. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
أمر تدريب البطاقة الفردي كما يلي. لا يمكن لنظام Windows إضافة معلمة CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/هناك طريقتان للتدريب متعدد البطاقات ، وهما Torchrun وتسريع. يمكن للمطورين استخدام الأساليب المقابلة وفقًا لعاداتهم الخاصة.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/أولاً ، تكوين معلمات التدريب. العملية هي أن تطلب من المطور الإجابة على العديد من الأسئلة. يتم ذلك بشكل أساسي افتراضيًا ، ولكن هناك العديد من المعلمات التي يجب تعيينها وفقًا للوضع الفعلي.
accelerate configربما هذه هي العملية:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
بعد اكتمال التكوين ، يمكنك استخدام الأمر التالي لعرض التكوين.
accelerate envأمر التدريب البدء على النحو التالي.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/سجل الإخراج كما يلي:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} بعد الانتهاء من الضبط ، سيكون هناك نموذجان. الأول هو النموذج الأساسي الهامس والثاني هو طراز Lora. يجب دمج هذين النموذجين قبل إجراء العمليات اللاحقة. يحتاج هذا البرنامج فقط إلى تمرير معلمتين. --lora_model يحدد مسار طراز Lora المحفوظ بعد التدريب ، وهو في الواقع مسار مجلد نقطة التفتيش. والثاني --output_dir هو الدليل المحفوظ للنموذج المدمج.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ يتم تنفيذ الإجراءات التالية لتقييم النموذج ، والمعلمتين الأكثر أهمية. يحدد أول- --model_path مسار النموذج المدمج ، ويدعم أيضًا استخدام النموذج الأصلي الهامس مباشرة ، مثل تحديد openai/whisper-large-v2 ، والثاني --metric يحدد طريقة التقييم ، مثل معدل خطأ الفعل cer ومعدل خطأ wer . نصيحة: لا يوجد نموذج دقيق ، وقد يتم ترقيم الإخراج ، مما يؤثر على الدقة. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer تنفيذ البرنامج التالي للتعرف على الكلام. يستخدم هذا المحولات للاتصال مباشرة بالنموذج الذي تم ضبطه بشكل مباشر أو التنبؤ النموذج الأصلي الهامس ، ويدعم تسريع المترجم ، وتسريع Flashattention2 ، وتسريع التحويل بشكل أفضل لـ Pytorch2.0. المعلمة الأولى --audio_path تحدد مسار الصوت للتنبؤ. يحدد المسار الثاني- --model_path مسار النموذج المدمج ، ويدعم أيضًا استخدام النموذج الأصلي الهامس مباشرة ، مثل تحديد openai/whisper-large-v2 بشكل مباشر. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path يحدد نموذج Transformers. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
python infer_gui.py --model_path=models/whisper-tiny-finetuneالواجهة بعد بدء التشغيل كما يلي:
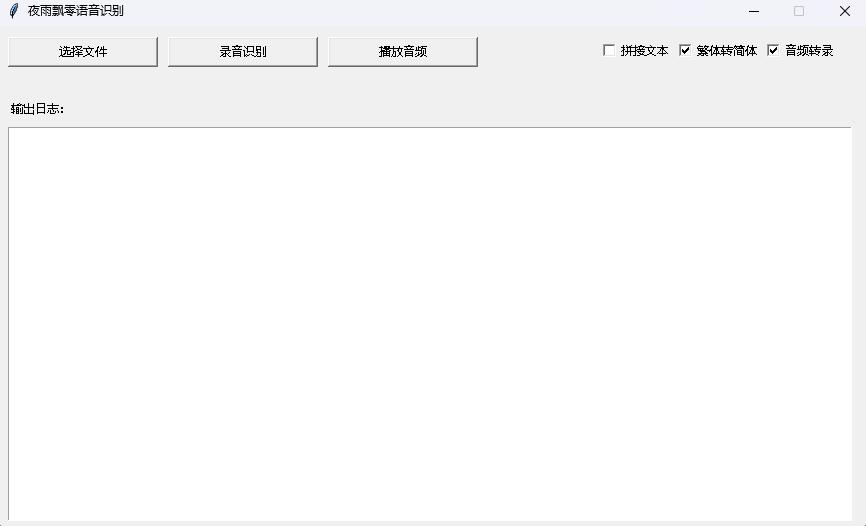
--host يحدد عنوان بدء تشغيل الخدمة ، والذي يتم تعيينه على 0.0.0.0 ، أي أنه يمكن الوصول إلى أي عنوان. -يحدد --port رقم المنفذ المستخدم. --model_path يحدد نموذج المحولات. --num_workers يحدد عدد المواضيع المستخدمة في الاستدلال المتزامن ، وهو أمر مهم في نشر الويب. عندما يكون هناك العديد من الوصول المتزامن ، من الممكن التفكير في نفس الوقت. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 حاليًا ، يتم توفير واجهة التعريف /recognition معلمات الواجهة كما يلي.
| الحقول | هل هو ضروري | يكتب | القيمة الافتراضية | يوضح |
|---|---|---|---|---|
| صوتي | نعم | ملف | يتم تحديد ملف الصوت | |
| to_simple | لا | int | 1 | سواء كنت تتحول إلى الصينيين التقليديين |
| remove_pun | لا | int | 0 | ما إذا كان لإزالة علامات الترقيم |
| مهمة | لا | خيط | نص | تحديد أنواع المهام ، والدعم نسخ وترجمة |
| لغة | لا | خيط | ZH | اضبط اللغة ، والاختصار ، إذا لم يسبق له مثيل ، اكتشاف اللغة تلقائيًا |
نتيجة العودة:
| الحقول | يكتب | يوضح |
|---|---|---|
| نتائج | قائمة | نتائج تحديد التجزئة |
| +نتيجة | شارع | نتيجة كل نص |
| +ابدأ | int | وقت بدء كل شريحة ، وحدة ثانية |
| +نهاية | int | وقت نهاية كل شريحة ، وحدة ثانية |
| شفرة | int | رمز الخطأ ، 0 هو التعريف الناجح |
الأمثلة على النحو التالي:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} لسهولة الفهم ، إليك رمز Python يدعو واجهة الويب. فيما يلي طريقة استدعاء /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )صفحات الاختبار المقدمة على النحو التالي:
صفحة الصفحة الرئيسية http://127.0.0.1:5000/ هي كما يلي:
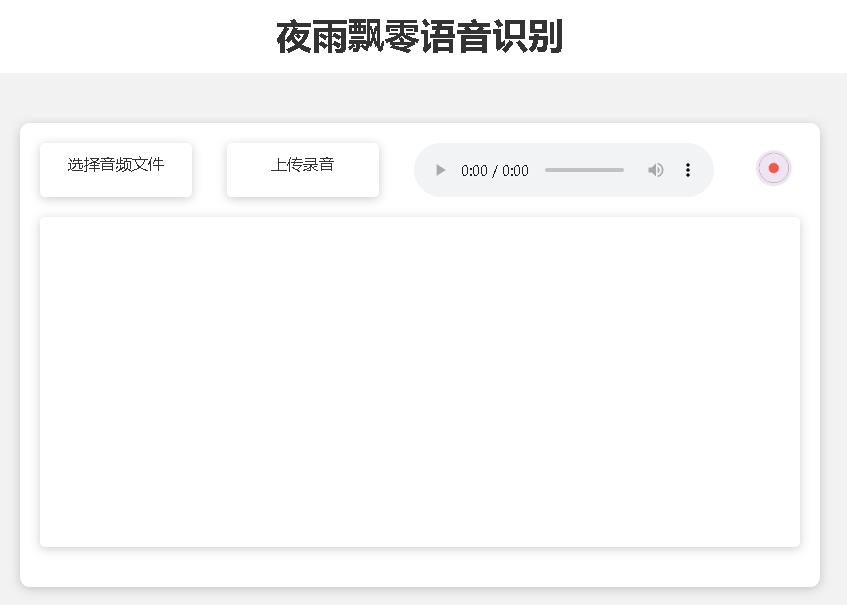
صفحة المستند http://127.0.0.1:5000/docs صفحة كما يلي:
فيما يلي طريقة لتسريع ctranslate2. على الرغم من أن سرعة التفكير في خط الأنابيب لاستخدام Transformers سريع جدًا بالفعل ، يجب عليك أولاً تحويل النموذج وتحويل النموذج المدمج إلى طراز Ctranslate2. كأمر التالي ، تحدد المعلمة --model مسار النموذج المدمج ، ويدعم أيضًا استخدام النموذج الأصلي الهامس مباشرة ، مثل تحديد openai/whisper-large-v2 مباشرة. تحدد المعلمة --output_dir مسار نموذج Ctranslate2 المحول ، ويحدد المعلمة --quantization حجم نموذج القياس. إذا كنت لا تريد نموذج القياس الكمي ، فيمكنك إزالة هذه المعلمة مباشرة.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 تنفيذ البرنامج التالي للتعرف على الكلام ، تحدد المعلمة --audio_path مسار الصوت الذي سيتم التنبؤ به. --model_path يحدد نموذج Ctranslate2 المحول. لمزيد من المعلمات الأخرى ، يرجى التحقق من هذا البرنامج.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2نتيجة الإخراج على النحو التالي:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 رمز المصدر للتثبيت والنشر موجود في دليل Androiddemo. يمكن عرض المستندات المحددة في readme.md في هذا الدليل.



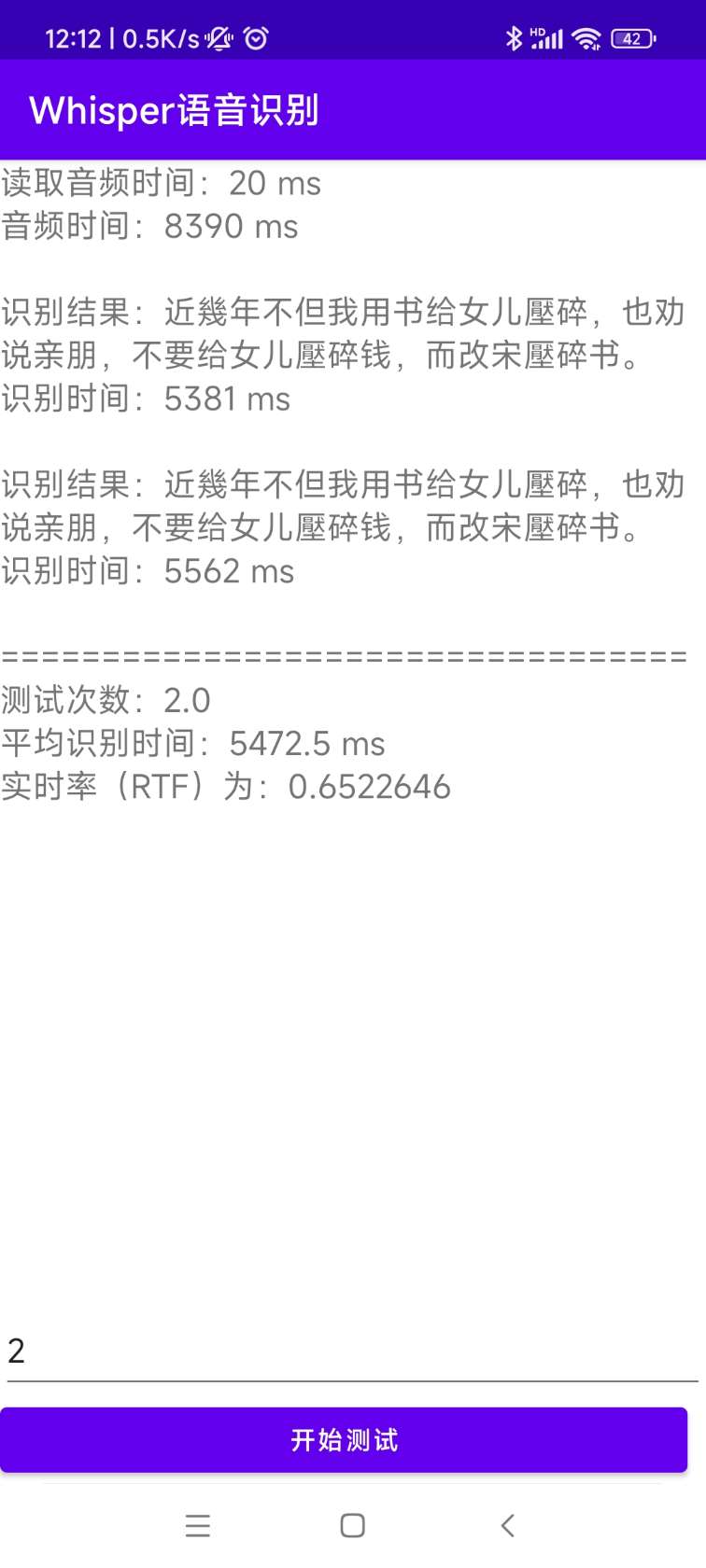
البرنامج في دليل Whisperdesktop. يمكن الاطلاع على المستندات المحددة على readme.md في هذا الدليل.
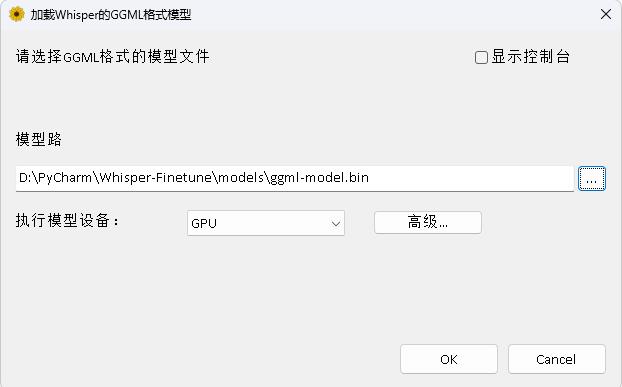
مكافأة دولار واحد لدعم المؤلف


