Whisper Finetune
1.0.0
Simplified Chinese | English
OpenAI opens the Whisper project, which claims to have reached the human level of English voice recognition, and it also supports automatic voice recognition in other 98 languages. The automatic speech recognition and translation tasks provided by Whisper can turn speech in various languages into text, and can also translate these texts into English. The main purpose of this project is to fine-tune the Whisper model using Lora, support time stamp data training, time stamp data training, and speechless data training . Currently, several models are open sourced. You can view them in openai. The following lists several commonly used models. In addition, the project also supports CTranslate2 accelerated inference and GGML accelerated inference. As a reminder, accelerated inference supports direct conversion using Whisper original model, and does not necessarily require fine-tuning. Supports Windows desktop applications, Android applications and server deployment.
Everyone is welcome to scan the QR code to enter the Knowledge Planet (left) or QQ group (right) for discussion. The Knowledge Planet provides project model files and bloggers' other related projects model files, as well as some other resources.
Usage environment:
aishell.py : Make AIShell training data.finetune.py : fine-tune the model.merge_lora.py : A model that merges Whisper and Lora.evaluation.py : Evaluate the fine-tuned model or Whisper original model.infer.py : Use the fine-tuned model to call or the Whisper model on transformers to predict.infer_ct2.py : Use the model converted to CTranslate2 to predict, mainly refer to the usage of this program.infer_gui.py : There is a GUI interface operation, using the fine-tuned model or the Whisper model on transformers to predict.infer_server.py : Use the fine-tuned model or the Whisper model on transformers to deploy to the server and provide it to the client to call.convert-ggml.py : Convert the model to GGML format model for Android or Windows applications.AndroidDemo : This directory stores the source code for deploying the model to Android.WhisperDesktop : This directory stores programs for Windows desktop applications. | Using the model | Specify language | aishell_test | test_net | test_meeting | Cantonese test set | Model acquisition |
|---|---|---|---|---|---|---|
| whisper-tiny | Chinese | 0.31898 | 0.40482 | 0.75332 | N/A | Join the knowledge planet to obtain |
| whisper-base | Chinese | 0.22196 | 0.30404 | 0.50378 | N/A | Join the knowledge planet to obtain |
| whisper-small | Chinese | 0.13897 | 0.18417 | 0.31154 | N/A | Join the knowledge planet to obtain |
| whisper-medium | Chinese | 0.09538 | 0.13591 | 0.26669 | N/A | Join the knowledge planet to obtain |
| whisper-large | Chinese | 0.08969 | 0.12933 | 0.23439 | N/A | Join the knowledge planet to obtain |
| whisper-large-v2 | Chinese | 0.08817 | 0.12332 | 0.26547 | N/A | Join the knowledge planet to obtain |
| whisper-large-v3 | Chinese | 0.08086 | 0.11452 | 0.19878 | 0.18782 | Join the knowledge planet to obtain |
| Using the model | Specify language | Dataset | aishell_test | test_net | test_meeting | Cantonese test set | Model acquisition |
|---|---|---|---|---|---|---|---|
| whisper-tiny | Chinese | AIShell | 0.13043 | 0.4463 | 0.57728 | N/A | Join the knowledge planet to obtain |
| whisper-base | Chinese | AIShell | 0.08999 | 0.33089 | 0.40713 | N/A | Join the knowledge planet to obtain |
| whisper-small | Chinese | AIShell | 0.05452 | 0.19831 | 0.24229 | N/A | Join the knowledge planet to obtain |
| whisper-medium | Chinese | AIShell | 0.03681 | 0.13073 | 0.16939 | N/A | Join the knowledge planet to obtain |
| whisper-large-v2 | Chinese | AIShell | 0.03139 | 0.12201 | 0.15776 | N/A | Join the knowledge planet to obtain |
| whisper-large-v3 | Chinese | AIShell | 0.03660 | 0.09835 | 0.13706 | 0.20060 | Join the knowledge planet to obtain |
| whisper-large-v3 | Cantonese | Cantonese dataset | 0.06857 | 0.11369 | 0.17452 | 0.03524 | Join the knowledge planet to obtain |
| whisper-tiny | Chinese | WenetSpeech | 0.17711 | 0.24783 | 0.39226 | N/A | Join the knowledge planet to obtain |
| whisper-base | Chinese | WenetSpeech | 0.14548 | 0.17747 | 0.30590 | N/A | Join the knowledge planet to obtain |
| whisper-small | Chinese | WenetSpeech | 0.08484 | 0.11801 | 0.23471 | N/A | Join the knowledge planet to obtain |
| whisper-medium | Chinese | WenetSpeech | 0.05861 | 0.08794 | 0.19486 | N/A | Join the knowledge planet to obtain |
| whisper-large-v2 | Chinese | WenetSpeech | 0.05443 | 0.08367 | 0.19087 | N/A | Join the knowledge planet to obtain |
| whisper-large-v3 | Chinese | WenetSpeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | Join the knowledge planet to obtain |
test_long.wav , and the duration is 3 minutes. The test program is in tools/run_compute.sh .| Acceleration method | tiny | base | Small | medium | Large-v2 | Large-v3 |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1.458s | 1.671s | 2.331s | 11.071s | 4.779s | 12.826s |
Transformers ( fp16 + batch_size=16 + Compile ) | 1.477s | 1.675s | 2.357s | 11.003s | 4.799s | 12.643s |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461s | 1.676s | 2.301s | 11.062s | 4.608s | 12.505s |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436s | 1.630s | 2.258s | 10.533s | 4.344s | 11.651s |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1.686s | 2.277s | 11.000s | 4.543s | 12.592s |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1.643s | 2.220s | 10.390s | 4.377s | 11.703s |
Faster Whisper ( fp16 + beam_size=1 ) | 2.179s | 1.492s | 2.327s | 3.752s | 5.677s | 31.541s |
Faster Whisper ( 8-bit + beam_size=1 ) | 2.609s | 1.728s | 2.744s | 4.688s | 6.571s | 29.307s |
| Data list processing method | AiShell | WenetSpeech |
|---|---|---|
| Add punctuation | Join the knowledge planet to obtain | Join the knowledge planet to obtain |
| Add punctuation and timestamps | Join the knowledge planet to obtain | Join the knowledge planet to obtain |
Important Note:
aishell_test is the test set of AIShell, and test_net and test_meeting are the test sets of WenetSpeech.dataset/test_long.wav , and the duration is 3 minutes.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Then enter the image and mount the current path to the /workspace directory of the container.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl The training data set is as follows, which is a data list of jsonlines, that is, each row is a JSON data, and the data format is as follows. This project provides a program aishell.py that makes AIShell data set. Executing this program can automatically download and generate training and test sets in the following formats. Note: This program can skip the download process by specifying AIShell's compressed files. If it is downloaded directly, it will be very slow. You can use some downloaders such as Thunder and other downloaders, and then specify the downloaded compressed file path through the parameter --filepath , such as /home/test/data_aishell.tgz .
Tips:
sentences field.language field data.sentences field is [] , sentence field is "" and language field may not exist.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Once the data is prepared, you can start fine-tuning the model. The two most important parameters for training are: --base_model specifies the fine-tuned Whisper model. This parameter value needs to exist in HuggingFace. This does not require advance download. It can be downloaded automatically when starting training. Of course, it can also be downloaded in advance. Then --base_model specifies is the path, and --local_files_only is set to True. The second --output_path is the Lora checkpoint path saved during training, because we use Lora to fine-tune the model. If you want to save enough, it is best to set --use_8bit to False, so that the training speed is much faster. For more other parameters, please check this program.
The single card training command is as follows. The Windows system can not add CUDA_VISIBLE_DEVICES parameter.
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/There are two methods for multi-card training, namely torchrun and accelerate. Developers can use the corresponding methods according to their own habits.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/First, configure the training parameters. The process is to ask the developer to answer several questions. It is basically done by default, but there are several parameters that need to be set according to the actual situation.
accelerate configThis is probably the process:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
After the configuration is complete, you can use the following command to view the configuration.
accelerate envThe start training command is as follows.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/The output log is as follows:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} After the fine-tuning is completed, there will be two models. The first is the Whisper basic model and the second is the Lora model. These two models need to be merged before subsequent operations can be performed. This program only needs to pass two parameters. --lora_model specifies the Lora model path saved after training, which is actually the checkpoint folder path. The second --output_dir is the saved directory of the merged model.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ The following procedures are executed to evaluate the model, the two most important parameters are. The first --model_path specifies the merged model path, and also supports the use of Whisper original model directly, such as directly specifying openai/whisper-large-v2 , and the second is --metric specifies the evaluation method, such as verb error rate cer and word error rate wer . Tip: There is no fine-tuned model, and the output may be punctuated, affecting the accuracy. For more other parameters, please check this program.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Execute the following program for speech recognition. This uses transformers to directly call the fine-tuned model or Whisper original model prediction, and supports compiler acceleration, FlashAttention2 acceleration, and BetterTransformer acceleration of Pytorch2.0. The first --audio_path parameter specifies the audio path to predict. The second --model_path specifies the merged model path, and also supports the use of Whisper original model directly, such as directly specifying openai/whisper-large-v2 . For more other parameters, please check this program.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path specifies the Transformers model. For more other parameters, please check this program.
python infer_gui.py --model_path=models/whisper-tiny-finetuneThe interface after startup is as follows:
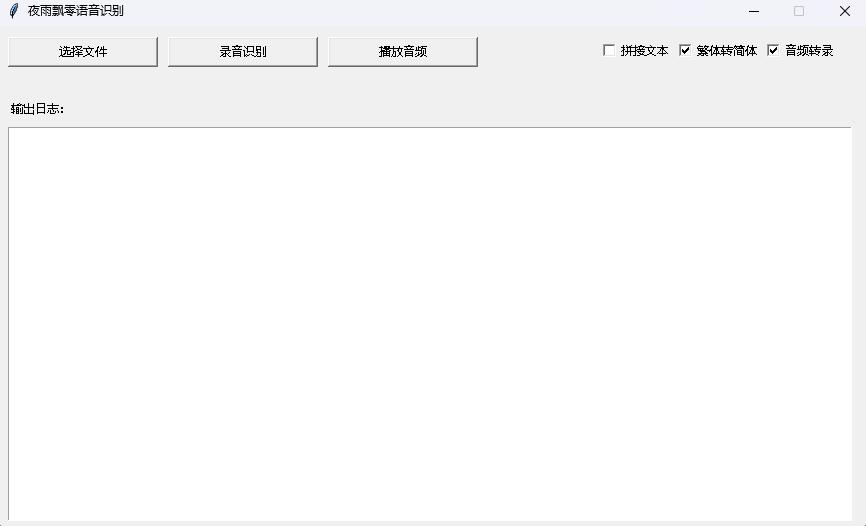
--host specifies the address of the service startup, which is set to 0.0.0.0 , that is, any address can be accessed. --port specifies the port number used. --model_path specifies Transformers model. --num_workers specifies how many threads are used to concurrent inference, which is important in web deployment. When there are multiple concurrent accesses, it is possible to reason at the same time. For more other parameters, please check this program.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Currently, the identification interface /recognition is provided, and the interface parameters are as follows.
| Fields | Is it necessary | type | default value | illustrate |
|---|---|---|---|---|
| audio | yes | File | Audio file to be identified | |
| to_simple | no | int | 1 | Whether to switch to traditional Chinese |
| remove_pun | no | int | 0 | Whether to remove punctuation marks |
| task | no | String | transcript | Identify task types, support transcribe and translate |
| language | no | String | zh | Set language, abbreviation, if None, automatically detect language |
Return result:
| Fields | type | illustrate |
|---|---|---|
| Results | list | Segmentation identification results |
| +result | str | The result of each piece of text |
| +start | int | The start time of each slice, unit seconds |
| +end | int | The end time of each slice, unit seconds |
| code | int | Error code, 0 is successful identification |
Examples are as follows:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} For easy understanding, here is a Python code that calls the web interface. The following is the call method of /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )The test pages provided are as follows:
The page of home page http://127.0.0.1:5000/ is as follows:
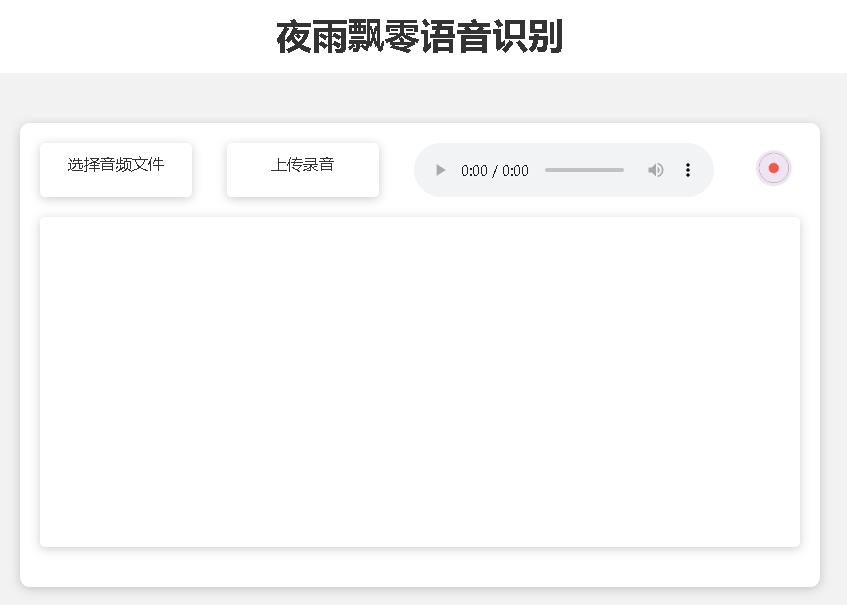
The document page http://127.0.0.1:5000/docs page is as follows:
Here is a way to accelerate CTranslate2. Although the pipeline reasoning speed of using Transformers is already very fast, you must first convert the model and convert the merged model into the CTranslate2 model. As the following command, --model parameter specifies the merged model path, and also supports the use of Whisper original model directly, such as directly specifying openai/whisper-large-v2 . The --output_dir parameter specifies the converted CTranslate2 model path, and the --quantization parameter specifies the quantization model size. If you do not want the quantization model, you can directly remove this parameter.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Execute the following program for speech recognition, --audio_path parameter specifies the audio path to be predicted. --model_path specifies the converted CTranslate2 model. For more other parameters, please check this program.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2The output result is as follows:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 The source code for installation and deployment is in the AndroidDemo directory. The specific documents can be viewed in README.md in this directory.



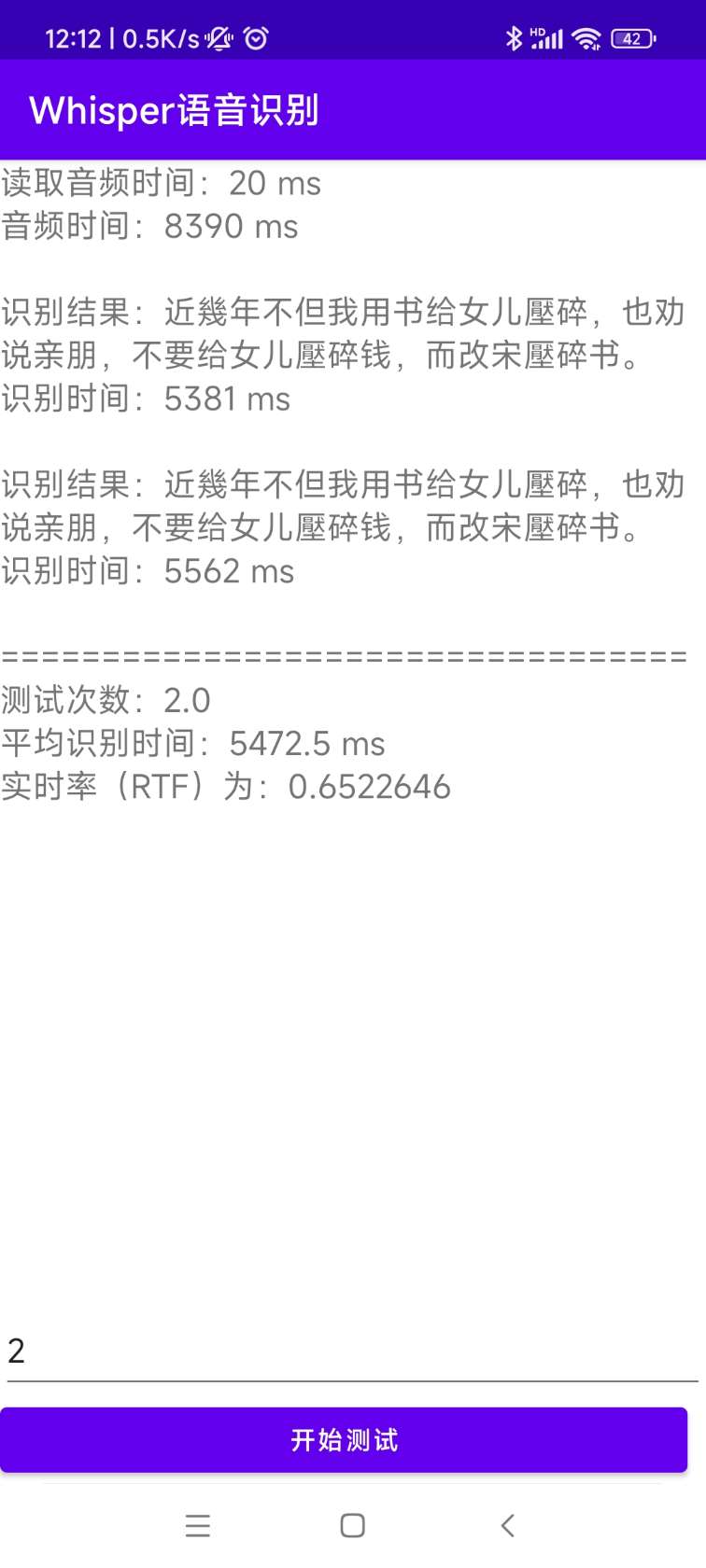
The program is in the WhisperDesktop directory. The specific documents can be viewed at README.md in this directory.
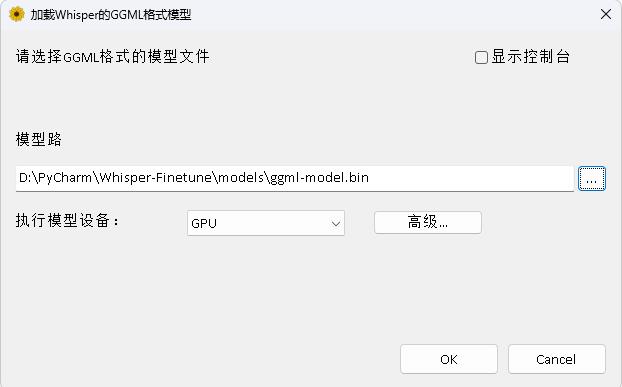
Reward one dollar to support the author


