Whisper Finetune
1.0.0
단순화 된 중국어 | 영어
Openai는 Whisper Project를 열어 서 영어 수준의 영어 음성 인식에 도달했다고 주장하며 다른 98 개 언어의 자동 음성 인식도 지원합니다. Whisper가 제공하는 자동 음성 인식 및 번역 작업은 다양한 언어로 연설을 텍스트로 바꿀 수 있으며 이러한 텍스트를 영어로 번역 할 수도 있습니다. 이 프로젝트의 주요 목적은 LORA를 사용하여 Whisper 모델을 미세 조정하고, 지원 타임 스탬프 데이터 교육, 타임 스탬프 데이터 교육 및 음성 데이터 교육을하는 것 입니다. 현재 여러 모델이 공개됩니다. OpenAi에서 볼 수 있습니다. 다음은 일반적으로 사용되는 몇 가지 모델을 나열합니다. 또한이 프로젝트는 CTRANSLATE2 가속 추론 및 GGML 가속 추론을 지원합니다. 알림으로, 가속화 된 추론은 Whisper Original 모델을 사용하여 직접 변환을 지원하며 반드시 미세 조정이 필요하지는 않습니다. Windows 데스크탑 응용 프로그램, Android 응용 프로그램 및 서버 배포를 지원합니다.
모든 사람은 QR 코드를 스캔하여 지식 행성 (왼쪽) 또는 QQ 그룹 (오른쪽)에 입력 할 수 있습니다. Knowledge Planet은 프로젝트 모델 파일 및 블로거의 기타 관련 프로젝트 모델 파일 및 기타 리소스를 제공합니다.
사용 환경 :
aishell.py : Aishell 교육 데이터를 만듭니다.finetune.py : 모델을 미세 조정하십시오.merge_lora.py : Whisper와 Lora를 병합하는 모델.evaluation.py : 미세 조정 모델 또는 속삭임 원래 모델을 평가합니다.infer.py : 미세 조정 된 모델을 사용하여 호출하거나 변압기의 속삭임 모델을 예측할 수 있습니다.infer_ct2.py : ctranslate2로 변환 된 모델을 사용하여 주로이 프로그램의 사용법을 참조하십시오.infer_gui.py : 트랜스포머에 미세 조정 모델 또는 Whisper 모델을 사용하여 GUI 인터페이스 작업이 있습니다.infer_server.py : 변압기의 미세 조정 모델 또는 Whisper 모델을 사용하여 서버에 배포하여 클라이언트에 전화를 제공합니다.convert-ggml.py : Android 또는 Windows 응용 프로그램의 모델을 GGML 형식 모델로 변환하십시오.AndroidDemo :이 디렉토리는 모델을 Android에 배포하기위한 소스 코드를 저장합니다.WhisperDesktop :이 디렉토리는 Windows 데스크탑 응용 프로그램을위한 프로그램을 저장합니다. | 모델 사용 | 언어를 지정하십시오 | aishell_test | test_net | test_meeting | 광동 테스트 세트 | 모델 획득 |
|---|---|---|---|---|---|---|
| 속삭임 | 중국인 | 0.31898 | 0.40482 | 0.75332 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | 0.22196 | 0.30404 | 0.50378 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | 0.13897 | 0.18417 | 0.31154 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | 0.09538 | 0.13591 | 0.26669 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | 0.08969 | 0.12933 | 0.23439 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V2 | 중국인 | 0.08817 | 0.12332 | 0.26547 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V3 | 중국인 | 0.08086 | 0.11452 | 0.19878 | 0.18782 | 지식 행성에 합류하여 얻습니다 |
| 모델 사용 | 언어를 지정하십시오 | 데이터 세트 | aishell_test | test_net | test_meeting | 광동 테스트 세트 | 모델 획득 |
|---|---|---|---|---|---|---|---|
| 속삭임 | 중국인 | Aishell | 0.13043 | 0.4463 | 0.57728 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | Aishell | 0.08999 | 0.33089 | 0.40713 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | Aishell | 0.05452 | 0.19831 | 0.24229 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | Aishell | 0.03681 | 0.13073 | 0.16939 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V2 | 중국인 | Aishell | 0.03139 | 0.12201 | 0.15776 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V3 | 중국인 | Aishell | 0.03660 | 0.09835 | 0.13706 | 0.20060 | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V3 | 광동어 | 광동어 데이터 세트 | 0.06857 | 0.11369 | 0.17452 | 0.03524 | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | wenetspeech | 0.17711 | 0.24783 | 0.39226 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | wenetspeech | 0.14548 | 0.17747 | 0.30590 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | wenetspeech | 0.08484 | 0.11801 | 0.23471 | N/A | 지식 행성에 합류하여 얻습니다 |
| 속삭임 | 중국인 | wenetspeech | 0.05861 | 0.08794 | 0.19486 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V2 | 중국인 | wenetspeech | 0.05443 | 0.08367 | 0.19087 | N/A | 지식 행성에 합류하여 얻습니다 |
| Whisper-Large-V3 | 중국인 | wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | 지식 행성에 합류하여 얻습니다 |
test_long.wav 로 사용하며 지속 시간은 3 분입니다. 테스트 프로그램은 tools/run_compute.sh 에 있습니다.| 가속 방법 | 매우 작은 | 베이스 | 작은 | 중간 | 대형 V2 | 대형 V3 |
|---|---|---|---|---|---|---|
변압기 ( fp16 + batch_size=16 ) | 1.458s | 1.671S | 2.331S | 11.071S | 4.779S | 12.826S |
변압기 ( fp16 + batch_size=16 + Compile ) | 1.477S | 1.675S | 2.357S | 11.003S | 4.799S | 12.643S |
변압기 ( fp16 + batch_size=16 + BetterTransformer ) | 1.461S | 1.676S | 2.301S | 11.062S | 4.608S | 12.505s |
변압기 ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436S | 1.630S | 2.258S | 10.533S | 4.344s | 11.651S |
변압기 ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442S | 1.686S | 2.277S | 11.000s | 4.543S | 12.592S |
변압기 ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1.643S | 2.220 | 10.390 년대 | 4.377S | 11.703 |
더 빠른 속삭임 ( fp16 + beam_size=1 ) | 2.179S | 1.492S | 2.327S | 3.752s | 5.677S | 31.541S |
더 빠른 속삭임 ( 8-bit + beam_size=1 ) | 2.609s | 1.728s | 2.744S | 4.688S | 6.571S | 29.307S |
| 데이터 목록 처리 방법 | Aishell | wenetspeech |
|---|---|---|
| 구두점을 추가하십시오 | 지식 행성에 합류하여 얻습니다 | 지식 행성에 합류하여 얻습니다 |
| 구두점과 타임 스탬프를 추가하십시오 | 지식 행성에 합류하여 얻습니다 | 지식 행성에 합류하여 얻습니다 |
중요한 참고 :
aishell_test 는 Aishell의 테스트 세트이며 test_net 및 test_meeting Wenetspeech의 테스트 세트입니다.dataset/test_long.wav 이며 지속 시간은 3 분입니다.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel 그런 다음 이미지를 입력하고 컨테이너의 /workspace 디렉토리에 현재 경로를 장착하십시오.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl 교육 데이터 세트는 다음과 같습니다. JSONLINES의 데이터 목록, 즉 각 행은 JSON 데이터이며 데이터 형식은 다음과 같습니다. 이 프로젝트는 Aishell 데이터 세트를 만드는 프로그램 aishell.py 제공합니다. 이 프로그램을 실행하면 다음 형식으로 교육 및 테스트 세트를 자동으로 다운로드하고 생성 할 수 있습니다. 참고 : 이 프로그램은 Aishell의 압축 파일을 지정하여 다운로드 프로세스를 건너 뛸 수 있습니다. 직접 다운로드하면 매우 느립니다. Thunder 및 기타 다운로더와 같은 일부 다운로더를 사용한 다음 /home/test/data_aishell.tgz 와 같은 매개 변수 인 --filepath 를 통해 다운로드 된 압축 파일 경로를 지정할 수 있습니다.
팁 :
sentences 필드에 데이터를 포함 할 수 없습니다.language 필드 데이터를 포함 할 수 없습니다.sentences 필드는 [] 이며 sentence 필드는 "" 이며 language 필드는 존재하지 않을 수 있습니다.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} 데이터가 준비되면 모델을 미세 조정하기 시작할 수 있습니다. 훈련을위한 가장 중요한 두 가지 매개 변수는 다음과 같습니다. --base_model 미세 조정 된 Whisper 모델을 지정합니다. 이 매개 변수 값은 HuggingFace에 존재해야합니다. 사전 다운로드가 필요하지 않습니다. 훈련을 시작할 때 자동으로 다운로드 할 수 있습니다. 물론 미리 다운로드 할 수도 있습니다. 그런 다음 --base_model 경로를 지정하고 --local_files_only true로 설정됩니다. 두 번째 --output_path LORA를 사용하여 모델을 미세 조정하기 때문에 훈련 중에 저장된 LORA 체크 포인트 경로입니다. 충분히 저장하려면 --use_8bit false로 설정하는 것이 가장 좋습니다. 훈련 속도가 훨씬 빠릅니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
단일 카드 교육 명령은 다음과 같습니다. Windows 시스템은 CUDA_VISIBLE_DEVICES 매개 변수를 추가 할 수 없습니다.
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/다중 카드 교육에는 Torchrun과 Accelerate의 두 가지 방법이 있습니다. 개발자는 자체 습관에 따라 해당 방법을 사용할 수 있습니다.
--nproc_per_node 를 통해 사용할 그래픽 카드 수를 지정하십시오. torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/먼저 교육 매개 변수를 구성하십시오. 이 과정은 개발자에게 몇 가지 질문에 답변하도록 요청하는 것입니다. 기본적으로 기본적으로 수행되지만 실제 상황에 따라 설정 해야하는 여러 매개 변수가 있습니다.
accelerate config이것은 아마도 과정 일 것입니다.
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
구성이 완료되면 다음 명령을 사용하여 구성을 볼 수 있습니다.
accelerate env시작 훈련 명령은 다음과 같습니다.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/출력 로그는 다음과 같습니다.
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} 미세 조정이 완료되면 두 가지 모델이 있습니다. 첫 번째는 Whisper Basic 모델이고 두 번째는 Lora 모델입니다. 이 두 모델은 후속 작업을 수행하기 전에 병합되어야합니다. 이 프로그램은 두 매개 변수 만 전달하면됩니다. --lora_model 훈련 후 저장된 LORA 모델 경로를 지정합니다. 이는 실제로 Checkpoint 폴더 경로입니다. 두 번째 --output_dir 는 병합 된 모델의 저장된 디렉토리입니다.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ 다음 절차는 모델을 평가하기 위해 실행되며 두 가지 가장 중요한 매개 변수는 다음과 같습니다. 첫 번째 --model_path 병합 된 모델 경로를 지정하고 openai/whisper-large-v2 직접 지정하는 것과 같은 Whisper Original 모델 사용을 --metric 지원하며, 두 번째는 동사 오류율 cer 및 Word wer 과 같은 평가 방법을 지정합니다. 팁 : 미세 조정 된 모델이 없으며 출력이 구두점이되어 정확도에 영향을 줄 수 있습니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer 음성 인식을 위해 다음 프로그램을 실행하십시오. 이것은 변압기를 사용하여 미세 조정 된 모델 또는 속삭임 원래 모델 예측을 직접 호출하고 컴파일러 가속도, FlashAttention2 가속 및 Pytorch2.0의 더 나은 변환기 가속도를 지원합니다. 첫 번째 --audio_path 매개 변수는 예측할 오디오 경로를 지정합니다. 두 번째 --model_path 병합 된 모델 경로를 지정하고 openai/whisper-large-v2 직접 지정하는 것과 같이 Whisper Original Model의 사용을 직접 지원합니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path 변압기 모델을 지정합니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
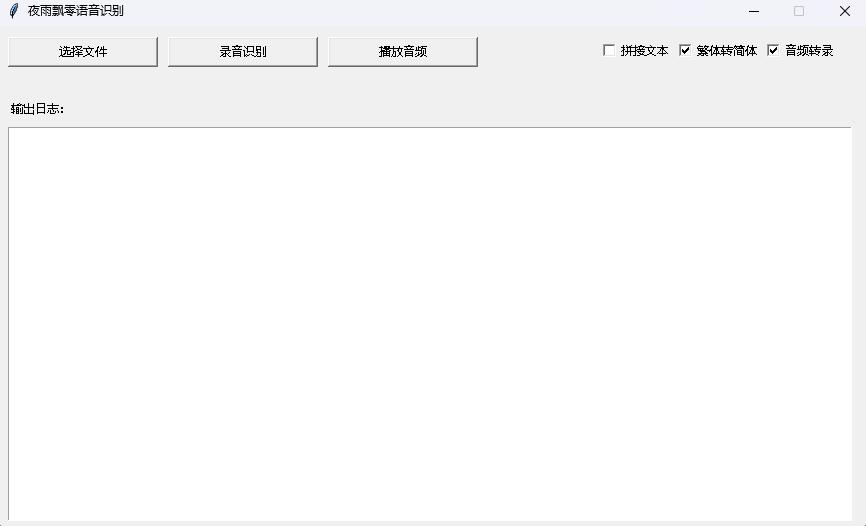
python infer_gui.py --model_path=models/whisper-tiny-finetune시작 후 인터페이스는 다음과 같습니다.
--host 서비스 시작의 주소를 지정하며,이 주소는 0.0.0.0 으로 설정됩니다. 즉, 모든 주소에 액세스 할 수 있습니다. --port 사용 된 포트 번호를 지정합니다. --model_path 변압기 모델을 지정합니다. --num_workers 웹 배포에 중요한 유추에 사용되는 스레드 수를 지정합니다. 동시 액세스가 여러 번 있으면 동시에 추론 할 수 있습니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 현재 식별 인터페이스 /recognition 제공되며 인터페이스 매개 변수는 다음과 같습니다.
| 전지 | 필요합니까? | 유형 | 기본값 | 설명 |
|---|---|---|---|---|
| 오디오 | 예 | 파일 | 식별 할 오디오 파일 | |
| to_simple | 아니요 | int | 1 | 전통적인 중국어로 전환할지 여부 |
| 제거 _pun | 아니요 | int | 0 | 구두점을 제거할지 여부 |
| 일 | 아니요 | 끈 | 성적 증명서 | 작업 유형을 식별하고 전사 및 번역을 지원합니다 |
| 언어 | 아니요 | 끈 | ZH | 언어, 약어를 설정하지 않으면 언어를 자동으로 감지하십시오 |
반품 결과 :
| 전지 | 유형 | 설명 |
|---|---|---|
| 결과 | 목록 | 세분화 식별 결과 |
| +결과 | str | 각 텍스트의 결과 |
| +시작 | int | 각 슬라이스의 시작 시간, 단위 초 |
| +끝 | int | 각 슬라이스의 종료 시간, 단위 초 |
| 암호 | int | 오류 코드, 0은 성공적인 식별입니다 |
예는 다음과 같습니다.
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} 쉽게 이해하기 위해 다음은 웹 인터페이스를 호출하는 파이썬 코드입니다. 다음은 통화 방법 /recognition 입니다.
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )제공된 테스트 페이지는 다음과 같습니다.
홈페이지의 페이지 http://127.0.0.1:5000/ 는 다음과 같습니다.
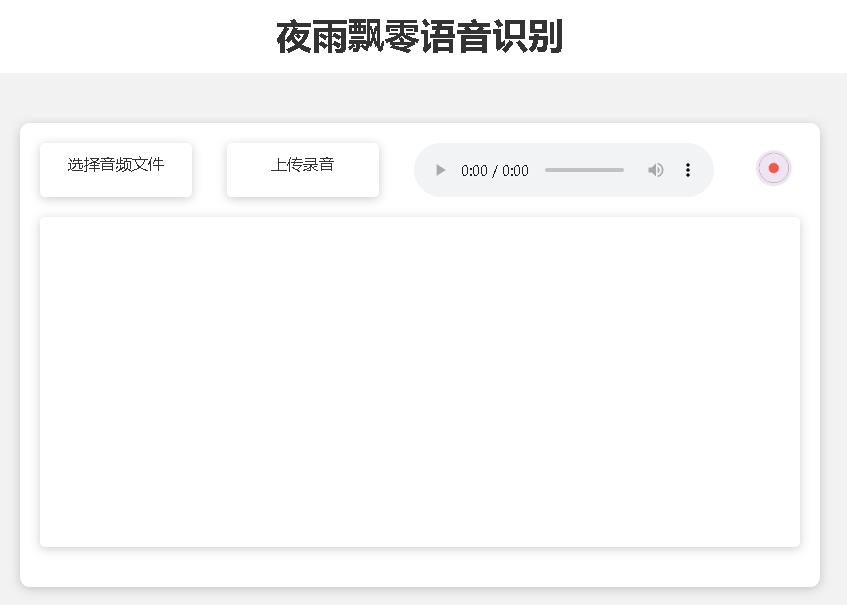
문서 페이지 http://127.0.0.1:5000/docs 페이지는 다음과 같습니다.
다음은 ctranslate2를 가속화하는 방법입니다. 트랜스포머를 사용하는 파이프 라인 추론 속도는 이미 매우 빠르지 만 먼저 모델을 변환하고 병합 된 모델을 CTRANSLATE2 모델로 변환해야합니다. 다음 명령으로 --model 매개 변수는 병합 된 모델 경로를 지정하고 openai/whisper-large-v2 직접 지정하는 것과 같이 Whisper Original Model의 사용을 직접 지원합니다. --output_dir 매개 변수는 변환 된 ctranslate2 모델 경로를 지정하고 --quantization 매개 변수는 양자화 모델 크기를 지정합니다. 양자화 모델을 원하지 않으면이 매개 변수를 직접 제거 할 수 있습니다.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 음성 인식을 위해 다음 프로그램을 실행하십시오. --audio_path 매개 변수는 예측할 오디오 경로를 지정합니다. --model_path 변환 된 ctranslate2 모델을 지정합니다. 더 많은 다른 매개 변수는이 프로그램을 확인하십시오.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2출력 결과는 다음과 같습니다.
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 설치 및 배포 소스 코드는 Androiddemo 디렉토리에 있습니다. 특정 문서는이 디렉토리의 readme.md에서 볼 수 있습니다.



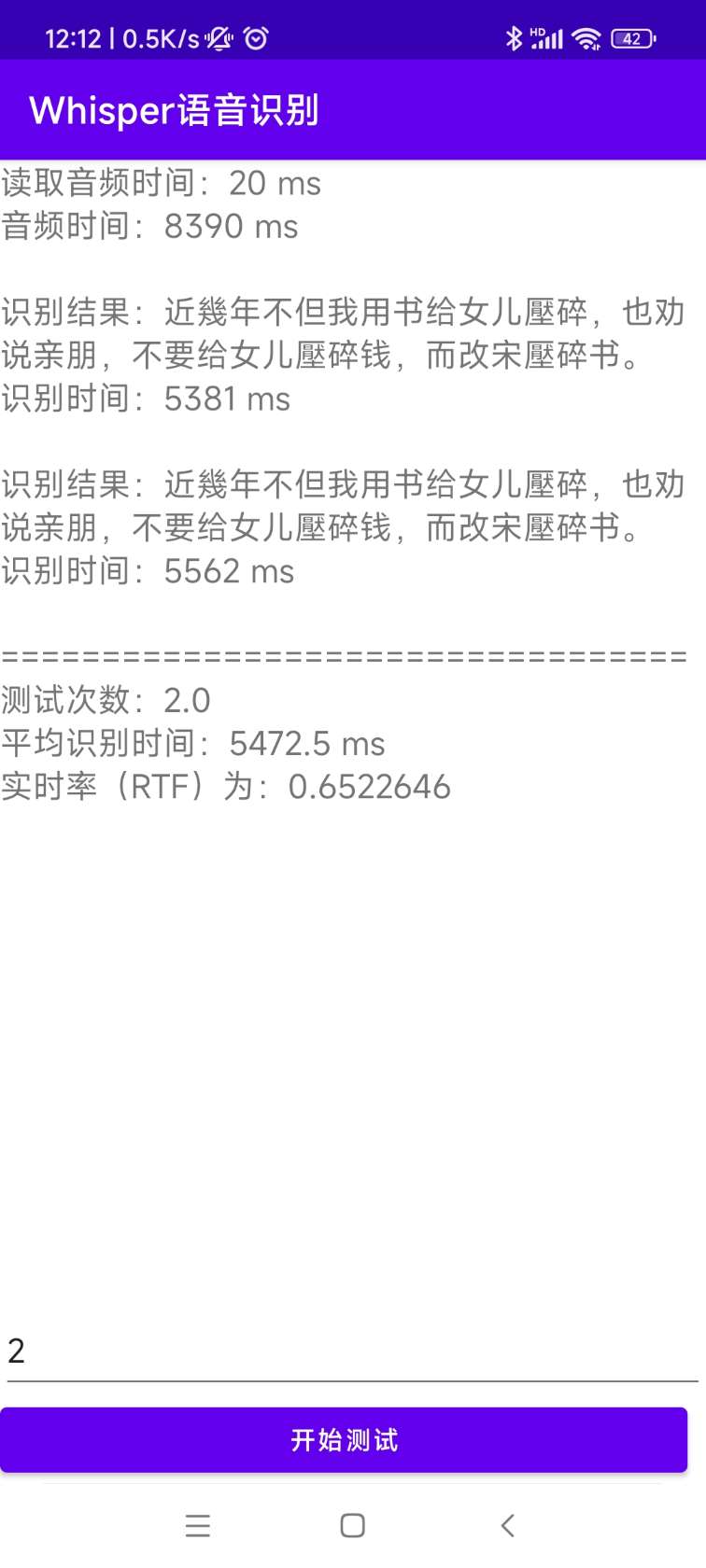
이 프로그램은 WhisperDeskTop 디렉토리에 있습니다. 특정 문서는이 디렉토리의 readme.md에서 볼 수 있습니다.
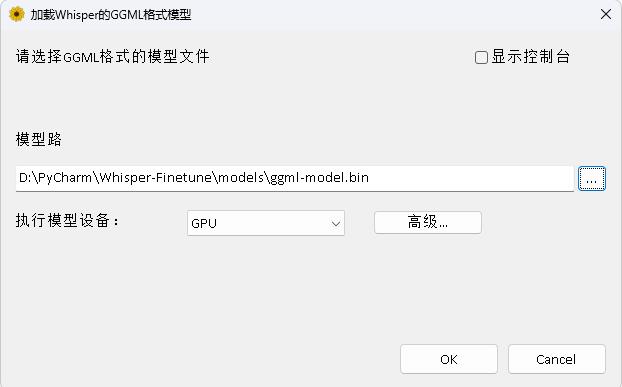
저자를 지원하기 위해 1 달러를 보상하십시오


