Whisper Finetune
1.0.0
Chino simplificado | Inglés
Openai abre el proyecto Whisper, que afirma haber alcanzado el nivel humano de reconocimiento de voz en inglés, y también admite el reconocimiento automático de voz en otros 98 idiomas. Las tareas automáticas de reconocimiento y traducción de voz proporcionadas por Whisper pueden convertir el habla en varios idiomas en texto, y también pueden traducir estos textos al inglés. El objetivo principal de este proyecto es ajustar el modelo Whisper con Lora, soportar la capacitación en datos de sellos de tiempo, capacitación en datos de sellos de tiempo y capacitación en datos sin voz . Actualmente, varios modelos son de origen abierto. Puedes verlos en OpenAi. Los siguientes enumeran varios modelos de uso común. Además, el proyecto también admite inferencia acelerada de Ctranslate2 e inferencia acelerada GGML. Como recordatorio, la inferencia acelerada admite la conversión directa utilizando el modelo original de Whisper, y no necesariamente requiere ajuste fino. Admite aplicaciones de escritorio de Windows, aplicaciones de Android e implementación del servidor.
Todos son bienvenidos a escanear el código QR para ingresar al planeta de conocimiento (izquierda) o un grupo QQ (derecha) para su discusión. El planeta de conocimiento proporciona archivos de modelos de proyectos y los otros archivos de modelos de proyectos relacionados de los bloggers, así como algunos otros recursos.
Entorno de uso:
aishell.py : hacer datos de entrenamiento de Aishell.finetune.py : ajuste el modelo.merge_lora.py : un modelo que fusiona Whisper y Lora.evaluation.py : evalúe el modelo ajustado o el modelo original de susurro.infer.py : use el modelo ajustado para llamar o el modelo Whisper en transformadores para predecir.infer_ct2.py : use el modelo convertido a Ctranslate2 para predecir, consulte principalmente el uso de este programa.infer_gui.py : hay una operación de interfaz GUI, que usa el modelo ajustado o el modelo Whisper en transformadores para predecir.infer_server.py : use el modelo ajustado o el modelo Whisper en transformadores para implementar en el servidor y proporcionarlo al cliente para llamar.convert-ggml.py : Convierta el modelo en modelo de formato GGML para aplicaciones Android o Windows.AndroidDemo : este directorio almacena el código fuente para implementar el modelo en Android.WhisperDesktop : este directorio almacena programas para aplicaciones de escritorio de Windows. | Usando el modelo | Especificar el lenguaje | aishell_test | test_net | Test_Meeting | Conjunto de pruebas cantonesas | Adquisición de modelos |
|---|---|---|---|---|---|---|
| susurro | Chino | 0.31898 | 0.40482 | 0.75332 | N / A | Únase al planeta de conocimiento para obtener |
| base de susurro | Chino | 0.22196 | 0.30404 | 0.50378 | N / A | Únase al planeta de conocimiento para obtener |
| susurro | Chino | 0.13897 | 0.18417 | 0.31154 | N / A | Únase al planeta de conocimiento para obtener |
| susmonio | Chino | 0.09538 | 0.13591 | 0.26669 | N / A | Únase al planeta de conocimiento para obtener |
| susurro | Chino | 0.08969 | 0.12933 | 0.23439 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V2 | Chino | 0.08817 | 0.12332 | 0.26547 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V3 | Chino | 0.08086 | 0.11452 | 0.19878 | 0.18782 | Únase al planeta de conocimiento para obtener |
| Usando el modelo | Especificar el lenguaje | Conjunto de datos | aishell_test | test_net | Test_Meeting | Conjunto de pruebas cantonesas | Adquisición de modelos |
|---|---|---|---|---|---|---|---|
| susurro | Chino | Aishell | 0.13043 | 0.4463 | 0.57728 | N / A | Únase al planeta de conocimiento para obtener |
| base de susurro | Chino | Aishell | 0.08999 | 0.33089 | 0.40713 | N / A | Únase al planeta de conocimiento para obtener |
| susurro | Chino | Aishell | 0.05452 | 0.19831 | 0.24229 | N / A | Únase al planeta de conocimiento para obtener |
| susmonio | Chino | Aishell | 0.03681 | 0.13073 | 0.16939 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V2 | Chino | Aishell | 0.03139 | 0.12201 | 0.15776 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V3 | Chino | Aishell | 0.03660 | 0.09835 | 0.13706 | 0.20060 | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V3 | Cantonés | Conjunto de datos cantonés | 0.06857 | 0.11369 | 0.17452 | 0.03524 | Únase al planeta de conocimiento para obtener |
| susurro | Chino | Wenetspeech | 0.17711 | 0.24783 | 0.39226 | N / A | Únase al planeta de conocimiento para obtener |
| base de susurro | Chino | Wenetspeech | 0.14548 | 0.17747 | 0.30590 | N / A | Únase al planeta de conocimiento para obtener |
| susurro | Chino | Wenetspeech | 0.08484 | 0.11801 | 0.23471 | N / A | Únase al planeta de conocimiento para obtener |
| susmonio | Chino | Wenetspeech | 0.05861 | 0.08794 | 0.19486 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V2 | Chino | Wenetspeech | 0.05443 | 0.08367 | 0.19087 | N / A | Únase al planeta de conocimiento para obtener |
| Whisper-Large-V3 | Chino | Wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | Únase al planeta de conocimiento para obtener |
test_long.wav y la duración es de 3 minutos. El programa de prueba está en tools/run_compute.sh .| Método de aceleración | diminuto | base | Pequeño | medio | V2 grande | V3 grande |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1.458S | 1.671s | 2.331s | 11.071s | 4.779S | 12.826s |
Transformers ( fp16 + batch_size=16 + Compile ) | 1.477s | 1.675s | 2.357s | 11.003S | 4.799s | 12.643S |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461s | 1.676s | 2.301S | 11.062s | 4.608S | 12.505s |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436s | 1.630s | 2.258S | 10.533s | 4.344s | 11.651s |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1.686s | 2.277s | 11,000s | 4.543S | 12.592s |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409S | 1.643S | 2.220S | 10.390s | 4.377s | 11.703S |
Whisper más rápido ( fp16 + beam_size=1 ) | 2.179S | 1.492s | 2.327s | 3.752s | 5.677s | 31.541s |
Whisper más rápido ( 8-bit + beam_size=1 ) | 2.609S | 1.728s | 2.744s | 4.688s | 6.571s | 29.307S |
| Método de procesamiento de la lista de datos | Aishell | Wenetspeech |
|---|---|---|
| Agregar puntuación | Únase al planeta de conocimiento para obtener | Únase al planeta de conocimiento para obtener |
| Agregar puntuación y marcas de tiempo | Únase al planeta de conocimiento para obtener | Únase al planeta de conocimiento para obtener |
Nota importante:
aishell_test es el conjunto de pruebas de Aishell, y test_net y test_meeting son los conjuntos de pruebas de WenetsPeech.dataset/test_long.wav , y la duración es de 3 minutos.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Luego ingrese la imagen y monte la ruta actual al directorio /workspace del contenedor.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl El conjunto de datos de capacitación es el siguiente, que es una lista de datos de JSONLINES, es decir, cada fila es un datos JSON, y el formato de datos es el siguiente. Este proyecto proporciona un programa aishell.py que fabrica datos de Aishell. La ejecución de este programa puede descargar y generar automáticamente conjuntos de capacitación y prueba en los siguientes formatos. Nota: Este programa puede omitir el proceso de descarga especificando los archivos comprimidos de Aishell. Si se descarga directamente, será muy lento. Puede usar algunos descargadores como Thunder y otros descargadores, y luego especificar la ruta de archivo comprimido descargado a través del parámetro --filepath , como /home/test/data_aishell.tgz .
Consejos:
sentences .language .sentences es [] , sentence es "" y language puede no existir.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Una vez que se preparan los datos, puede comenzar a ajustar el modelo. Los dos parámetros más importantes para el entrenamiento son: --base_model especifica el modelo de susurro ajustado. Este valor de parámetro debe existir en Huggingface. Esto no requiere una descarga anticipada. Se puede descargar automáticamente al comenzar la capacitación. Por supuesto, también se puede descargar de antemano. Entonces --base_model especifica la ruta, y --local_files_only se establece en True. El segundo --output_path es la ruta de punto de control de Lora guardada durante el entrenamiento, porque usamos Lora para ajustar el modelo. Si desea guardar lo suficiente, es mejor establecer --use_8bit a False, para que la velocidad de entrenamiento sea mucho más rápida. Para obtener más otros parámetros, consulte este programa.
El comando de entrenamiento de una sola tarjeta es el siguiente. El sistema de Windows no puede agregar CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Existen dos métodos para el entrenamiento de múltiples tarjetas, a saber, Torchrun y acelerar. Los desarrolladores pueden usar los métodos correspondientes de acuerdo con sus propios hábitos.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Primero, configure los parámetros de entrenamiento. El proceso es pedirle al desarrollador que responda varias preguntas. Básicamente se realiza por defecto, pero hay varios parámetros que deben establecerse de acuerdo con la situación real.
accelerate configEste es probablemente el proceso:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
Después de completar la configuración, puede usar el siguiente comando para ver la configuración.
accelerate envEl comando de entrenamiento de inicio es el siguiente.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/El registro de salida es el siguiente:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} Después de completar el ajuste fino, habrá dos modelos. El primero es el modelo básico Whisper y el segundo es el modelo Lora. Estos dos modelos deben fusionarse antes de que se puedan realizar operaciones posteriores. Este programa solo necesita pasar dos parámetros. --lora_model Especifica la ruta del modelo Lora guardada después del entrenamiento, que en realidad es la ruta de la carpeta de punto de control. El segundo --output_dir es el directorio guardado del modelo fusionado.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Los siguientes procedimientos se ejecutan para evaluar el modelo, los dos parámetros más importantes son. El primero --model_path especifica la ruta del modelo fusionado, y también admite el uso del modelo original Whisper directamente, como especificar directamente la tasa de error openai/whisper-large-v2 , y la segunda es --metric especifica el método de evaluación, como la tasa de error verbal cer y la tasa de error de palabras wer . Consejo: no hay un modelo ajustado, y la salida puede ser puntuada, afectando la precisión. Para obtener más otros parámetros, consulte este programa.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Ejecute el siguiente programa para el reconocimiento de voz. Esto utiliza transformadores para llamar directamente al modelo ajustado o una predicción del modelo original de susurro, y admite la aceleración del compilador, la aceleración de flashatent2 y la aceleración de mejor transformador de pytorch2.0. El primer parámetro --audio_path especifica la ruta de audio para predecir. El segundo --model_path especifica la ruta del modelo fusionado y también admite el uso del modelo original Whisper directamente, como especificar directamente openai/whisper-large-v2 . Para obtener más otros parámetros, consulte este programa.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path Especifica el modelo Transformers. Para obtener más otros parámetros, consulte este programa.
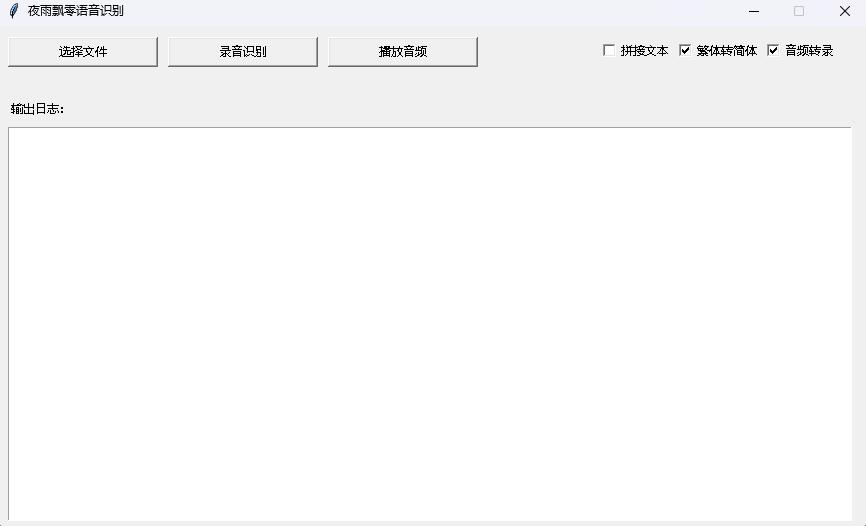
python infer_gui.py --model_path=models/whisper-tiny-finetuneLa interfaz después del inicio es la siguiente:
--host especifica la dirección del inicio del servicio, que se establece en 0.0.0.0 , es decir, se puede acceder a cualquier dirección. --port especifica el número de puerto utilizado. --model_path Especifica el modelo Transformers. --num_workers especifica cuántos hilos se utilizan para la inferencia concurrente, lo cual es importante en la implementación web. Cuando hay múltiples accesos concurrentes, es posible razonar al mismo tiempo. Para obtener más otros parámetros, consulte este programa.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Actualmente, se proporciona la interfaz /recognition de identificación, y los parámetros de la interfaz son los siguientes.
| Campos | ¿Es necesario | tipo | valor predeterminado | ilustrar |
|---|---|---|---|---|
| audio | Sí | Archivo | Archivo de audio a identificar | |
| to_simple | No | intencionalmente | 1 | Si cambiar a chino tradicional |
| eliminar_pun | No | intencionalmente | 0 | Si eliminar los signos de puntuación |
| tarea | No | Cadena | transcripción | Identificar tipos de tareas, apoyar y traducir |
| idioma | No | Cadena | zh | Establezca lenguaje, abreviatura, si ninguno, detecta automáticamente el lenguaje |
Resultado de retorno:
| Campos | tipo | ilustrar |
|---|---|---|
| Resultados | lista | Resultados de identificación de segmentación |
| +resultado | stri | El resultado de cada pieza de texto |
| +Inicio | intencionalmente | La hora de inicio de cada rebanada, unidades segundos |
| +final | intencionalmente | El tiempo de finalización de cada porción, unidades segundos |
| código | intencionalmente | Código de error, 0 es una identificación exitosa |
Los ejemplos son los siguientes:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Para una fácil comprensión, aquí hay un código de Python que llama a la interfaz web. El siguiente es el método de llamadas de /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )Las páginas de prueba proporcionadas son las siguientes:
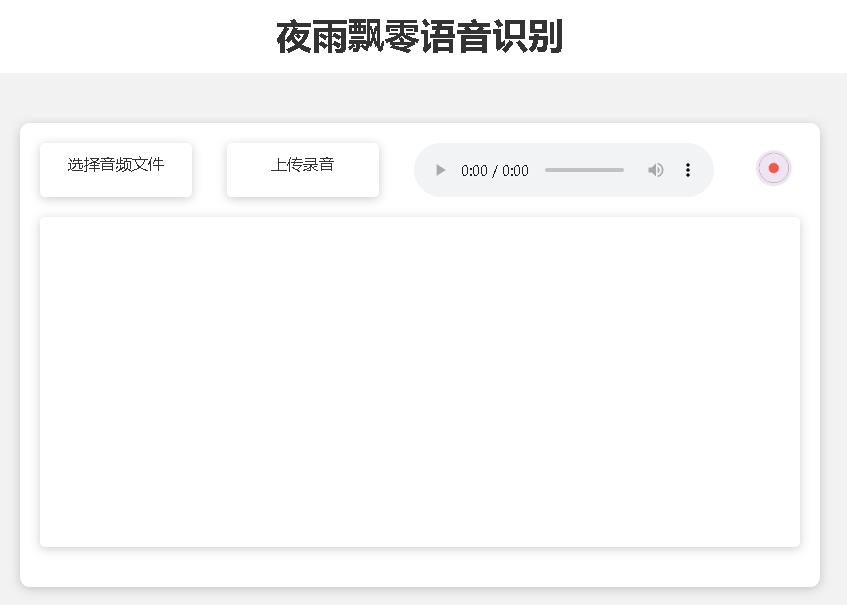
La página de la página de inicio http://127.0.0.1:5000/ es la siguiente:
La página del documento http://127.0.0.1:5000/docs página es la siguiente:
Aquí hay una forma de acelerar Ctranslate2. Aunque la velocidad de razonamiento de la tubería de usar transformadores ya es muy rápida, primero debe convertir el modelo y convertir el modelo fusionado en el modelo Ctranslate2. Como el siguiente comando, --model especifica la ruta del modelo fusionado y también admite el uso del modelo original de Whisper directamente, como especificar directamente openai/whisper-large-v2 . El parámetro --output_dir especifica la ruta del modelo Ctranslate2 convertida, y el parámetro --quantization -especifica el tamaño del modelo de cuantización. Si no desea el modelo de cuantización, puede eliminar directamente este parámetro.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Ejecute el siguiente programa para el reconocimiento de voz, --audio_path especifica la ruta de audio que se predecirá. --model_path Especifica el modelo Ctranslate2 convertido. Para obtener más otros parámetros, consulte este programa.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2El resultado de salida es el siguiente:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
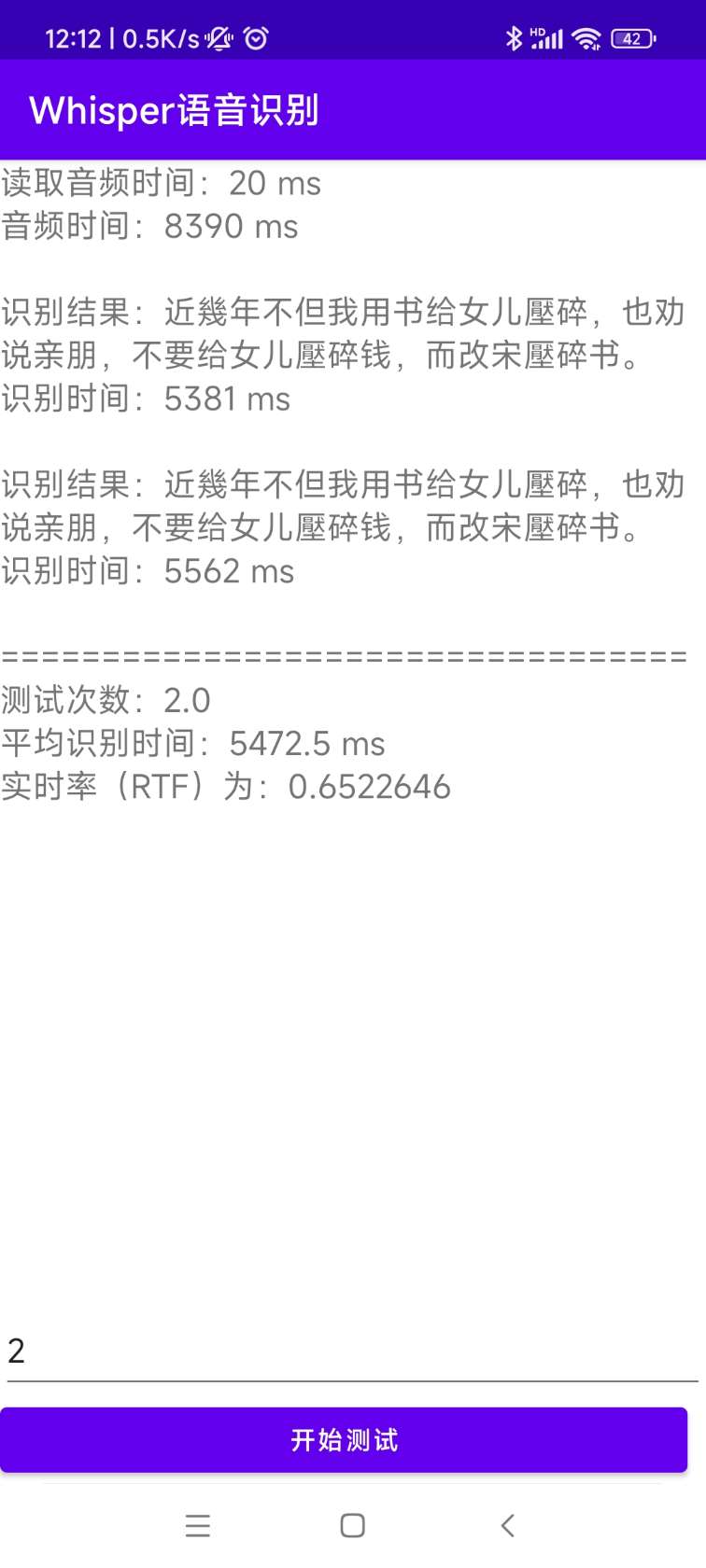
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 El código fuente para la instalación y la implementación se encuentra en el directorio de AndroidDemo. Los documentos específicos se pueden ver en ReadMe.md en este directorio.



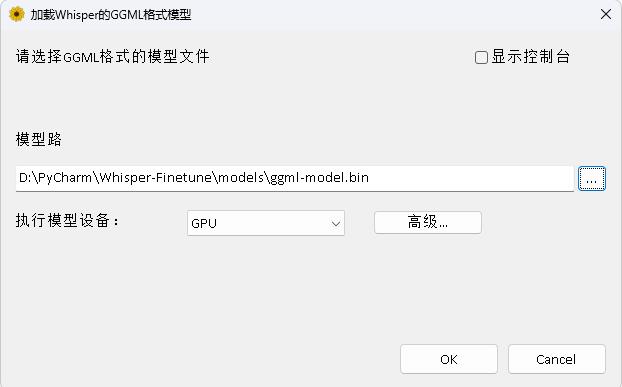
El programa está en el directorio Whisperdesktop. Los documentos específicos se pueden ver en ReadMe.md en este directorio.
Recompensa un dólar para apoyar al autor


