Whisper Finetune
1.0.0
Упрощенный китайский | Английский
OpenAI открывает проект Whisper, который утверждает, что достиг уровня распознавания английского голоса, а также поддерживает автоматическое распознавание голоса на других 98 языках. Автоматическое распознавание речи и задачи перевода, предоставленные Whisper, могут превратить речь на различных языках в текст, а также могут перевести эти тексты на английский язык. Основная цель этого проекта-тонкая настройка модели Whisper с использованием LORA, поддержания обучения данных о том, как данные по времени, обучение данных по времени и обучение данных без речи . В настоящее время несколько моделей являются открытыми. Вы можете просмотреть их в Openai. В следующем перечислены несколько часто используемых моделей. Кроме того, проект также поддерживает ускоренный вывод CtransLate2 и ускоренный вывод GGML. В качестве напоминания, ускоренный вывод поддерживает прямое преобразование с использованием исходной модели Whisper и не обязательно требует точной настройки. Поддерживает приложения Windows Desktop, приложения Android и развертывание сервера.
Каждый приветствует, чтобы сканировать QR -код, чтобы ввести планету знаний (слева) или QQ (справа) для обсуждения. Планета знаний предоставляет файлы моделей проекта и другие файлы моделей Bloggers, а также некоторые другие ресурсы.
Среда использования:
aishell.py : Сделайте данные обучения Айшелла.finetune.py : точно настроить модель.merge_lora.py : модель, которая объединяет Whisper и Lora.evaluation.py : оценить тонкую модель или шептать оригинальную модель.infer.py : Используйте тонкую модель для вызова, или Whisper Model на трансформаторах для прогнозирования.infer_ct2.py : используйте модель, преобразованную в CTRANSLATE2 для прогнозирования, в основном обратитесь к использованию этой программы.infer_gui.py : Существует операция интерфейса графического интерфейса, используя тонкую модель или модель шепота на трансформаторах для прогнозирования.infer_server.py : используйте тонкую модель или модель Whisper на трансформаторах, чтобы развернуть на сервере и предоставить ее клиенту для вызова.convert-ggml.py : конвертировать модель в модель формата GGML для приложений Android или Windows.AndroidDemo : В этом каталоге хранится исходный код для развертывания модели для Android.WhisperDesktop : этот каталог хранит программы для настольных приложений Windows. | Используя модель | Укажите язык | aishell_test | test_net | test_meeting | Кантонский тестовый набор | Приобретение модели |
|---|---|---|---|---|---|---|
| Шепот-пятнистый | китайский | 0,31898 | 0,40482 | 0,75332 | N/a | Присоединиться к планете знаний, чтобы получить |
| шепота | китайский | 0,22196 | 0,30404 | 0,50378 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот | китайский | 0,13897 | 0,18417 | 0,31154 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-средний | китайский | 0,09538 | 0,13591 | 0,26669 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот | китайский | 0,08969 | 0,12933 | 0,23439 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-Ларж-V2 | китайский | 0,08817 | 0,12332 | 0,26547 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-широкий V3 | китайский | 0,08086 | 0,11452 | 0,19878 | 0,18782 | Присоединиться к планете знаний, чтобы получить |
| Используя модель | Укажите язык | Набор данных | aishell_test | test_net | test_meeting | Кантонский тестовый набор | Приобретение модели |
|---|---|---|---|---|---|---|---|
| Шепот-пятнистый | китайский | Айшелл | 0,13043 | 0,4463 | 0,57728 | N/a | Присоединиться к планете знаний, чтобы получить |
| шепота | китайский | Айшелл | 0,08999 | 0,33089 | 0,40713 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот | китайский | Айшелл | 0,05452 | 0,19831 | 0,24229 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-средний | китайский | Айшелл | 0,03681 | 0,13073 | 0,16939 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-Ларж-V2 | китайский | Айшелл | 0,03139 | 0,12201 | 0,15776 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-широкий V3 | китайский | Айшелл | 0,03660 | 0,09835 | 0,13706 | 0,20060 | Присоединиться к планете знаний, чтобы получить |
| Шепот-широкий V3 | Кантонский | Кантонский набор данных | 0,06857 | 0,11369 | 0,17452 | 0,03524 | Присоединиться к планете знаний, чтобы получить |
| Шепот-пятнистый | китайский | Wenetspeech | 0,17711 | 0,24783 | 0,39226 | N/a | Присоединиться к планете знаний, чтобы получить |
| шепота | китайский | Wenetspeech | 0,14548 | 0,17747 | 0,30590 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот | китайский | Wenetspeech | 0,08484 | 0,11801 | 0,23471 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-средний | китайский | Wenetspeech | 0,05861 | 0,08794 | 0,19486 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-Ларж-V2 | китайский | Wenetspeech | 0,05443 | 0,08367 | 0,19087 | N/a | Присоединиться к планете знаний, чтобы получить |
| Шепот-широкий V3 | китайский | Wenetspeech | 0,04947 | 0,10711 | 0,17429 | 0,47431 | Присоединиться к планете знаний, чтобы получить |
test_long.wav , а продолжительность составляет 3 минуты. Программа тестирования находится в tools/run_compute.sh .| Метод ускорения | крошечный | база | Маленький | середина | Большой V2 | Большой V3 |
|---|---|---|---|---|---|---|
Трансформаторы ( fp16 + batch_size=16 ) | 1.458S | 1.671S | 2.331S | 11.071S | 4.779s | 12.826S |
Трансформаторы ( fp16 + batch_size=16 + Compile ) | 1.477S | 1,675 | 2.357S | 11.003S | 4.799S | 12.643S |
Трансформаторы ( fp16 + batch_size=16 + BetterTransformer ) | 1.461S | 1,676 с | 2.301S | 11.062S | 4,608 с | 12.505S |
Трансформаторы ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436S | 1.630S | 2.258S | 10.533S | 4.344S | 11.651S |
Трансформаторы ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442S | 1.686S | 2.277S | 11 000 с | 4.543S | 12.592S |
Трансформаторы ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1.643S | 2.220S | 10.390S | 4.377S | 11.703S |
Более быстрый шепот ( fp16 + beam_size=1 ) | 2.179 с | 1.492S | 2.327S | 3.752S | 5,677 с | 31.541S |
Более быстрый шепот ( 8-bit + beam_size=1 ) | 2.609 с | 1,728 с | 2.744S | 4.688s | 6,571 с | 29.307S |
| Метод обработки списка данных | Айшелл | Wenetspeech |
|---|---|---|
| Добавить пунктуацию | Присоединиться к планете знаний, чтобы получить | Присоединиться к планете знаний, чтобы получить |
| Добавить пунктуацию и временные метки | Присоединиться к планете знаний, чтобы получить | Присоединиться к планете знаний, чтобы получить |
Важное примечание:
aishell_test - это тестовый набор Aishell, а test_net и test_meeting - это наборы тестовых наборов Wenetspeech.dataset/test_long.wav , а продолжительность - 3 минуты.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Затем введите изображение и установите текущий путь к каталогу /workspace контейнера.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl Набор данных обучения выглядит следующим образом, которое представляет собой список данных JSONLINES, то есть каждая строка является данными JSON, а формат данных выглядит следующим образом. Этот проект предоставляет программу aishell.py , которая делает набор данных Aishell. Выполнение этой программы может автоматически загружать и генерировать обучающие и тестовые наборы в следующих форматах. Примечание. Эта программа может пропустить процесс загрузки, указав сжатые файлы Айшелла. Если он загружается напрямую, это будет очень медленно. Вы можете использовать некоторые загрузчики, такие как гром и другие загрузки, а затем указать загруженный путь сжатого файла через параметр --filepath , такой как /home/test/data_aishell.tgz .
Советы:
sentences .language полевых данных.sentences [] поля sentence "" , а language поле может не существовать.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Как только данные будут подготовлены, вы можете начать тонкую настройку модели. Двумя наиболее важными параметрами для обучения являются: --base_model Указывает тонкую модель шепота. Это значение параметра должно существовать в HuggingFace. Это не требует предварительной загрузки. Его можно загрузить автоматически при начале обучения. Конечно, его также можно загрузить заранее. Затем --base_model определяет путь, а --local_files_only устанавливается на истину. Второй --output_path -это путь контрольной точки LORA, сохраненный во время обучения, потому что мы используем LORA для точной настройки модели. Если вы хотите сэкономить достаточно, лучше всего установить --use_8bit в FALSE, чтобы скорость обучения намного быстрее. Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
Команда обучения с одной картой выглядит следующим образом. Система Windows не может добавить параметр CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Существует два метода для многокартового обучения, а именно Torchrun и Accelerate. Разработчики могут использовать соответствующие методы в соответствии с их собственными привычками.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Во -первых, настроить параметры обучения. Процесс состоит в том, чтобы попросить разработчика ответить на несколько вопросов. Это в основном делается по умолчанию, но есть несколько параметров, которые необходимо установить в соответствии с фактической ситуацией.
accelerate configЭто, вероятно, процесс:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
После завершения конфигурации вы можете использовать следующую команду для просмотра конфигурации.
accelerate envКоманда начала обучения выглядит следующим образом.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/Выходной журнал выглядит следующим образом:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} После того, как тонкая настройка будет завершена, будет две модели. Первая - это модель Whisper Basic, а вторая - модель LORA. Эти две модели должны быть объединены до того, как могут быть выполнены последующие операции. Эта программа должна пройти только два параметра. --lora_model Указывает путь модели LORA, сохраненный после обучения, который на самом деле является пути папки контрольной точки. Второй --output_dir является сохраненным каталогом объединенной модели.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Следующие процедуры выполняются для оценки модели, два наиболее важных параметра являются. Первая --model_path определяет объединенный путь модели, а также поддерживает непосредственное использование исходной модели Whisper, например, непосредственно указание openai/whisper-large-v2 , а вторая- --metric определяет метод оценки, такой как cer ошибок глагола и частота ошибок wer . Совет: нет тонкой модели, и вывод может быть акцентирован, что влияет на точность. Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Выполнить следующую программу для распознавания речи. Это использует трансформаторы для непосредственного вызова тонкой модели или шепотом оригинальной прогнозирования модели, а также поддерживает ускорение компилятора, ускорение Flashattention2 и улучшение ускорения Pytorch2.0. Первый параметр --audio_path указывает аудио -путь для прогнозирования. Второй --model_path определяет объединенный путь модели, а также поддерживает непосредственное использование исходной модели Whisper, например, непосредственно определение openai/whisper-large-v2 . Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path указывает модель трансформаторов. Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
python infer_gui.py --model_path=models/whisper-tiny-finetuneИнтерфейс после запуска выглядит следующим образом:
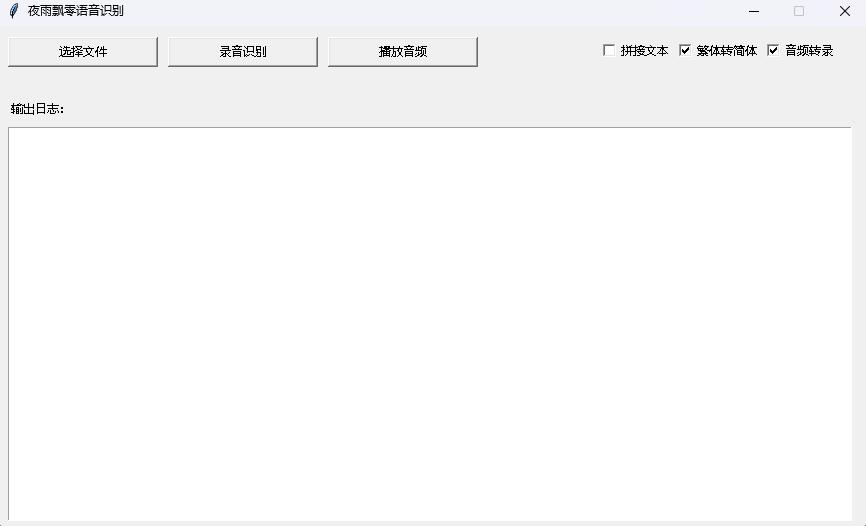
--host определяет адрес запуска службы, который устанавливается на 0.0.0.0 , то есть можно получить доступ к любому адресу. --port указывает используемый номер порта. --model_path определяет модель трансформаторов. --num_workers указывает, сколько потоков используется для одновременного вывода, что важно для веб-развертывания. Когда есть несколько параллельных доступа, можно рассуждать одновременно. Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 В настоящее время предоставляется интерфейс /recognition идентификации, а параметры интерфейса следующие.
| Поля | Это необходимо | тип | значение по умолчанию | иллюстрировать |
|---|---|---|---|---|
| аудио | да | Файл | Аудиофайл, который будет идентифицирован | |
| to_simple | нет | инт | 1 | Переключиться на традиционные китайцы |
| удалить_pun | нет | инт | 0 | Удалить отметки пунктуации |
| задача | нет | Нить | транскрипт | Определить типы задач, поддержать транскрибибель и перевести |
| язык | нет | Нить | ZH | Установить язык, аббревиатура, если нет, автоматически обнаруживает язык |
Вернуть результат:
| Поля | тип | иллюстрировать |
|---|---|---|
| Результаты | список | Результаты идентификации сегментации |
| +результат | стр | Результат каждого фрагмента текста |
| +старт | инт | Время начала каждого среза, секунды единиц |
| +конец | инт | Время окончания каждого среза, единицы секунды |
| код | инт | Код ошибки, 0 - успешная идентификация |
Примеры следующие:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Для легкого понимания, вот код Python, который вызывает веб -интерфейс. Ниже приведен метод вызова /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )Представленные тестовые страницы следующие:
Страница домашней страницы http://127.0.0.1:5000/ выглядит следующим образом:
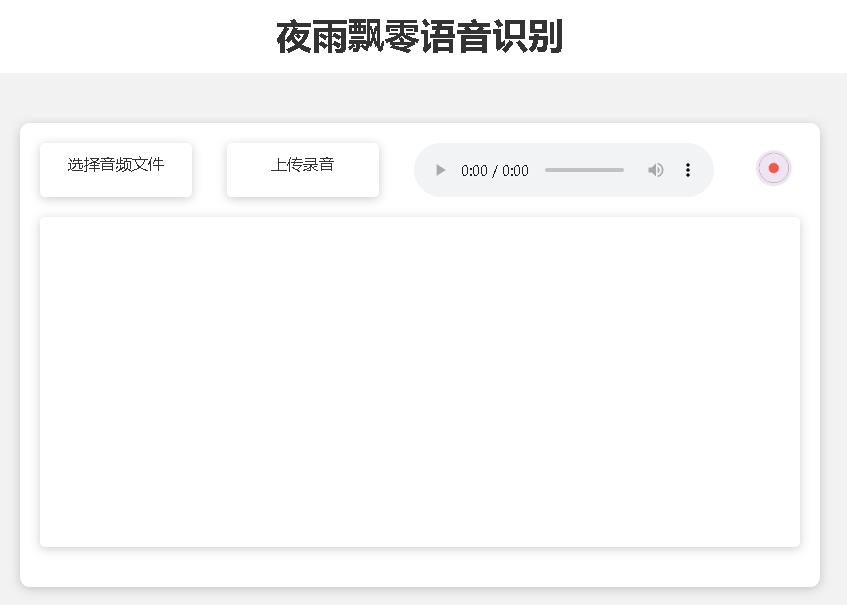
Страница документа http://127.0.0.1:5000/docs Страница следующая:
Вот способ ускорить Ctranslate2. Хотя скорость рассуждения о трубопроводе с использованием трансформаторов уже очень быстрая, вы должны сначала преобразовать модель и преобразовать объединенную модель в модель CTRANSLATE2. В качестве следующей команды параметр --model определяет путь объединенной модели, а также напрямую поддерживает использование исходной модели Whisper, например, непосредственно определение openai/whisper-large-v2 . Параметр --output_dir указывает преобразованный путь модели Ctranslate2, а параметр --quantization указывает размер модели квантования. Если вам не нужна модель квантования, вы можете напрямую удалить этот параметр.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Выполните следующую программу для распознавания речи, параметр -параметр --audio_path определяет прогнозируемый путь аудио. --model_path определяет конвертированную модель Ctranslate2. Для получения дополнительных других параметров, пожалуйста, проверьте эту программу.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2Результат вывода заключается в следующем:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 Исходной код для установки и развертывания находится в каталоге AndroidDemo. Конкретные документы можно просмотреть в readme.md в этом каталоге.



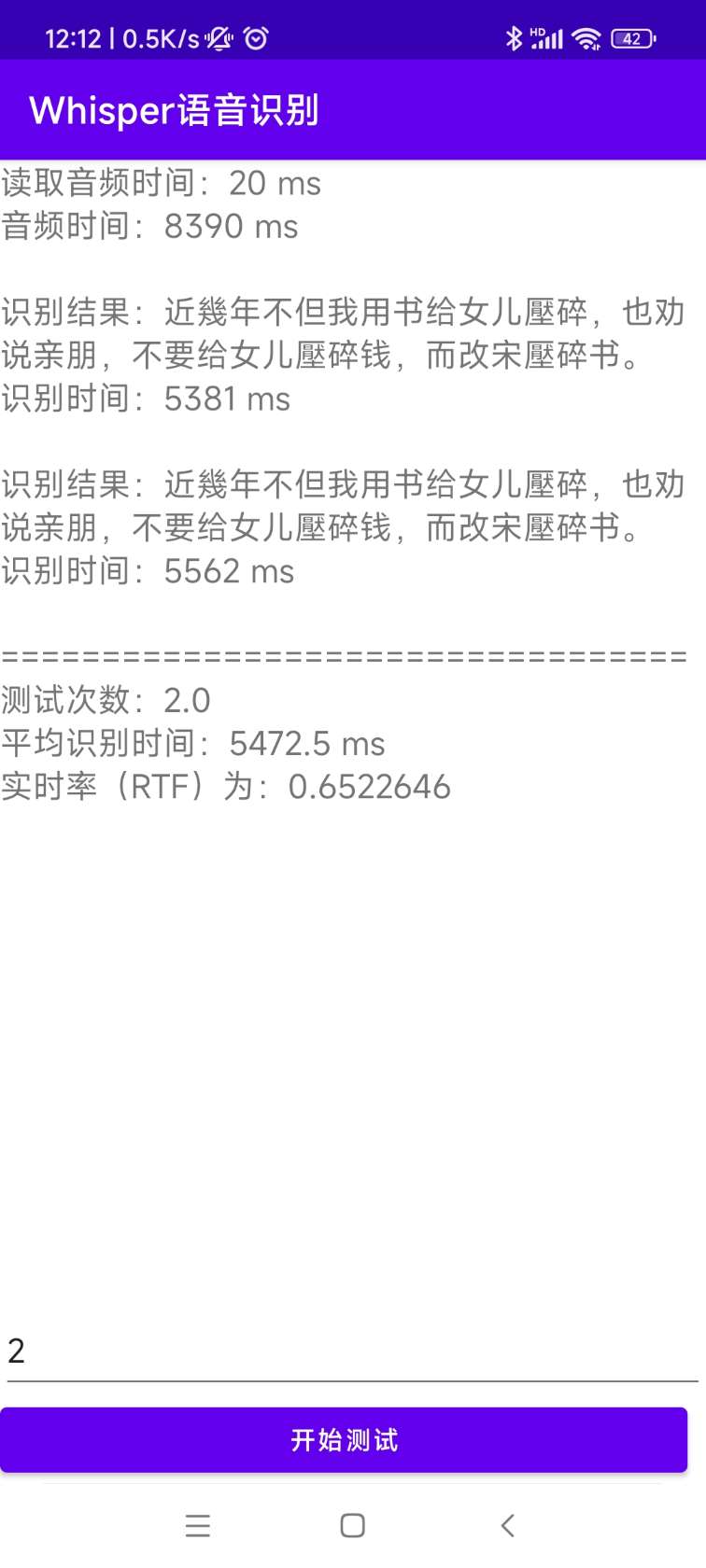
Программа находится в каталоге Whisperdesktop. Конкретные документы можно просмотреть на readme.md в этом каталоге.
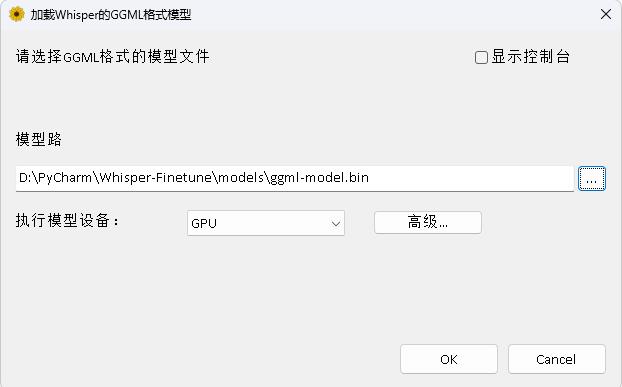
Вознаградите один доллар, чтобы поддержать автора


