Whisper Finetune
1.0.0
Chinois simplifié | Anglais
OpenAI ouvre le projet Whisper, qui prétend avoir atteint le niveau humain de la reconnaissance vocale anglaise, et il prend également en charge la reconnaissance automatique vocale dans les 98 autres langues. Les tâches automatiques de reconnaissance de la parole et de traduction fournies par Whisper peuvent transformer la parole dans diverses langues en texte, et peuvent également traduire ces textes en anglais. L'objectif principal de ce projet est de régler le modèle Whisper à l'aide de LORA, de la formation des données horodatrices de support, de la formation aux données horaires et de la formation sans voix . Actuellement, plusieurs modèles sont ouverts. Vous pouvez les voir dans Openai. Le suivant répertorie plusieurs modèles couramment utilisés. De plus, le projet prend également en charge l'inférence accélérée Ctranslate2 et l'inférence accélérée en GGML. Pour rappel, l'inférence accélérée prend en charge la conversion directe à l'aide du modèle Whisper Original et ne nécessite pas nécessairement un réglage fin. Prend en charge les applications de bureau Windows, les applications Android et le déploiement du serveur.
Tout le monde est invité à scanner le code QR pour entrer la planète de connaissance (à gauche) ou le groupe QQ (à droite) pour discussion. La planète de connaissances fournit des fichiers de modèle de projet et d'autres fichiers de modèles de projets liés des blogueurs, ainsi que d'autres ressources.
Environnement d'utilisation:
aishell.py : Faites des données de formation Aishell.finetune.py : affinez le modèle.merge_lora.py : un modèle qui fusionne Whisper et Lora.evaluation.py : Évaluez le modèle à réglage fin ou le modèle original de chuchotement.infer.py : utilisez le modèle affiné pour appeler ou le modèle Whisper sur Transformers pour prédire.infer_ct2.py : utilisez le modèle converti en Ctranslate2 pour prédire, référez-vous principalement à l'utilisation de ce programme.infer_gui.py : il y a une opération d'interface GUI, en utilisant le modèle affiné ou le modèle Whisper sur Transformers pour prédire.infer_server.py : utilisez le modèle affiné ou le modèle Whisper sur Transformers pour se déployer sur le serveur et le fournir au client pour appeler.convert-ggml.py : convertissez le modèle en modèle de format GGML pour les applications Android ou Windows.AndroidDemo : Ce répertoire stocke le code source pour déployer le modèle sur Android.WhisperDesktop : Ce répertoire stocke les programmes pour les applications de bureau Windows. | En utilisant le modèle | Spécifier la langue | Aishell_test | test_net | test_meeting | Ensemble de tests cantonais | Acquisition de modèle |
|---|---|---|---|---|---|---|
| chuchotement | Chinois | 0,31898 | 0,40482 | 0,75332 | N / A | Rejoignez la planète de connaissances pour obtenir |
| basculer | Chinois | 0.22196 | 0,30404 | 0,50378 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchoter | Chinois | 0.13897 | 0.18417 | 0,31154 | N / A | Rejoignez la planète de connaissances pour obtenir |
| murmure | Chinois | 0,09538 | 0.13591 | 0,26669 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchoter | Chinois | 0,08969 | 0.12933 | 0,23439 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v2 | Chinois | 0,08817 | 0.12332 | 0,26547 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v3 | Chinois | 0,08086 | 0,11452 | 0.19878 | 0.18782 | Rejoignez la planète de connaissances pour obtenir |
| En utilisant le modèle | Spécifier la langue | Ensemble de données | Aishell_test | test_net | test_meeting | Ensemble de tests cantonais | Acquisition de modèle |
|---|---|---|---|---|---|---|---|
| chuchotement | Chinois | Aishell | 0.13043 | 0,4463 | 0,57728 | N / A | Rejoignez la planète de connaissances pour obtenir |
| basculer | Chinois | Aishell | 0.08999 | 0,33089 | 0.40713 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchoter | Chinois | Aishell | 0,05452 | 0.19831 | 0,24229 | N / A | Rejoignez la planète de connaissances pour obtenir |
| murmure | Chinois | Aishell | 0,03681 | 0.13073 | 0.16939 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v2 | Chinois | Aishell | 0,03139 | 0.12201 | 0,15776 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v3 | Chinois | Aishell | 0,03660 | 0,09835 | 0.13706 | 0,20060 | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v3 | Cantonais | Ensemble de données cantonais | 0,06857 | 0,11369 | 0.17452 | 0,03524 | Rejoignez la planète de connaissances pour obtenir |
| chuchotement | Chinois | Wenetspeech | 0.17711 | 0,24783 | 0,39226 | N / A | Rejoignez la planète de connaissances pour obtenir |
| basculer | Chinois | Wenetspeech | 0.14548 | 0.17747 | 0,30590 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchoter | Chinois | Wenetspeech | 0,08484 | 0,11801 | 0,23471 | N / A | Rejoignez la planète de connaissances pour obtenir |
| murmure | Chinois | Wenetspeech | 0,05861 | 0,08794 | 0.19486 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v2 | Chinois | Wenetspeech | 0,05443 | 0,08367 | 0.19087 | N / A | Rejoignez la planète de connaissances pour obtenir |
| chuchotement-v3 | Chinois | Wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | Rejoignez la planète de connaissances pour obtenir |
test_long.wav , et la durée est de 3 minutes. Le programme de test est en tools/run_compute.sh .| Méthode d'accélération | minuscule | base | Petit | moyen | Grand-V2 | Grand-V3 |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1,458 | 1,671 | 2.331 | 11.071 | 4.779 | 12.826S |
Transformers ( fp16 + batch_size=16 + Compile ) | 1,477 | 1,675 | 2.357S | 11.003 | 4.799S | 12.643 |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461 | 1,676 | 2.301 | 11.062S | 4.608 | 12.505 |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436S | 1,630 | 2.258 | 10,533 | 4.344S | 11.651 |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442S | 1,686 | 2.277 | 11 000 | 4.543 | 12.592S |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409S | 1,643 | 2.220 | 10,390 | 4.377 | 11.703 |
Chuchotement plus rapide ( fp16 + beam_size=1 ) | 2.179S | 1.492S | 2.327 | 3,752 | 5.677 | 31.541 |
Chuchotement plus rapide ( 8-bit + beam_size=1 ) | 2.609S | 1,728 | 2.744S | 4.688 | 6.571 | 29.307 |
| Méthode de traitement de la liste de données | Aishell | Wenetspeech |
|---|---|---|
| Ajouter la ponctuation | Rejoignez la planète de connaissances pour obtenir | Rejoignez la planète de connaissances pour obtenir |
| Ajouter la ponctuation et les horodatages | Rejoignez la planète de connaissances pour obtenir | Rejoignez la planète de connaissances pour obtenir |
Remarque importante:
aishell_test est l'ensemble de tests d'Aishell, et test_net et test_meeting sont les ensembles de tests de wenetspeech.dataset/test_long.wav , et la durée est de 3 minutes.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Entrez ensuite l'image et montez le chemin actuel vers le répertoire /workspace du conteneur.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl L'ensemble de données de formation est le suivant, qui est une liste de données de JSONLines, c'est-à-dire que chaque ligne est une données JSON, et le format de données est le suivant. Ce projet fournit un programme aishell.py qui fait un ensemble de données Aishell. L'exécution de ce programme peut télécharger et générer automatiquement des ensembles de formation et de tests dans les formats suivants. Remarque: Ce programme peut ignorer le processus de téléchargement en spécifiant les fichiers compressés d'Aishell. S'il est téléchargé directement, ce sera très lent. Vous pouvez utiliser des téléchargeurs tels que Thunder et d'autres téléchargeurs, puis spécifier le chemin du fichier compressé téléchargé via le paramètre --filepath , tel que /home/test/data_aishell.tgz .
Conseils:
sentences .language .sentences est [] , sentence est "" et language peut ne pas exister.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Une fois les données préparées, vous pouvez commencer à affiner le modèle. Les deux paramètres les plus importants pour la formation sont: --base_model spécifie le modèle de chuchotement affiné. Cette valeur de paramètre doit exister dans HuggingFace. Cela ne nécessite pas de téléchargement anticipé. Il peut être téléchargé automatiquement lors du début de la formation. Bien sûr, il peut également être téléchargé à l'avance. Ensuite, --base_model Spécifie le chemin, et --local_files_only est défini sur true. Le deuxième --output_path est le chemin de point de contrôle LORA enregistré pendant la formation, car nous utilisons LORA pour affiner le modèle. Si vous voulez économiser suffisamment, il est préférable de définir --use_8bit sur false, afin que la vitesse d'entraînement soit beaucoup plus rapide. Pour plus d'autres paramètres, veuillez consulter ce programme.
La commande de formation à carte unique est la suivante. Le système Windows ne peut pas ajouter CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Il existe deux méthodes pour la formation multi-cartes, à savoir torchrun et accélérer. Les développeurs peuvent utiliser les méthodes correspondantes en fonction de leurs propres habitudes.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Tout d'abord, configurez les paramètres de formation. Le processus consiste à demander au développeur de répondre à plusieurs questions. Cela se fait essentiellement par défaut, mais plusieurs paramètres doivent être définis en fonction de la situation réelle.
accelerate configC'est probablement le processus:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
Une fois la configuration terminée, vous pouvez utiliser la commande suivante pour afficher la configuration.
accelerate envLa commande de formation Start est la suivante.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/Le journal de sortie est le suivant:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} Une fois le réglage fin terminé, il y aura deux modèles. Le premier est le modèle Whisper Basic et le second est le modèle LORA. Ces deux modèles doivent être fusionnés avant que les opérations suivantes puissent être effectuées. Ce programme n'a qu'à transmettre deux paramètres. --lora_model Spécifie le chemin du modèle LORA enregistré après la formation, qui est en fait le chemin du dossier de point de contrôle. Le deuxième --output_dir est le répertoire enregistré du modèle fusionné.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Les procédures suivantes sont exécutées pour évaluer le modèle, les deux paramètres les plus importants sont. Le premier --model_path spécifie le chemin du modèle fusionné et prend également en charge directement l'utilisation du modèle original de Whisper, tels que spécifiant directement openai/whisper-large-v2 , et le second est --metric spécifie la méthode d'évaluation, telle que le taux d'erreur verbale cer et le taux d'erreur de mot wer . Astuce: il n'y a pas de modèle affiné, et la sortie peut être ponctuée, affectant la précision. Pour plus d'autres paramètres, veuillez consulter ce programme.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Exécutez le programme suivant pour la reconnaissance de la parole. Cela utilise des transformateurs pour appeler directement le modèle affiné ou chuchoter la prédiction du modèle original, et prend en charge l'accélération du compilateur, l'accélération FlashAtttention2 et l'accélération BetterTransformateur de Pytorch2.0. Le premier paramètre --audio_path spécifie le chemin audio pour prédire. La seconde --model_path spécifie le chemin du modèle fusionné et prend également en charge directement l'utilisation du modèle original de Whisper, tel que spécifiant directement openai/whisper-large-v2 . Pour plus d'autres paramètres, veuillez consulter ce programme.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path Spécifie le modèle Transformers. Pour plus d'autres paramètres, veuillez consulter ce programme.
python infer_gui.py --model_path=models/whisper-tiny-finetuneL'interface après le démarrage est la suivante:
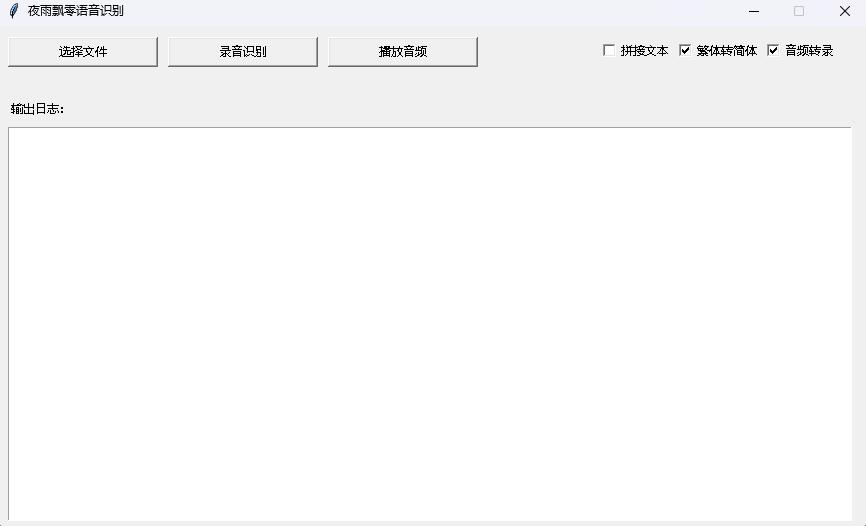
--host spécifie l'adresse du démarrage du service, qui est définie sur 0.0.0.0 , c'est-à-dire que toute adresse peut être accessible. --port spécifie le numéro de port utilisé. --model_path Spécifie le modèle Transformers. --num_workers Spécifie le nombre de threads utilisés pour l'inférence simultanée, ce qui est important dans le déploiement Web. Lorsqu'il y a plusieurs accès simultanés, il est possible de raisonner en même temps. Pour plus d'autres paramètres, veuillez consulter ce programme.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Actuellement, l'interface /recognition d'identification est fournie et les paramètres d'interface sont les suivants.
| Champs | Est-ce nécessaire | taper | valeur par défaut | illustrer |
|---|---|---|---|---|
| audio | Oui | Déposer | Fichier audio à identifier | |
| à_simple | Non | int | 1 | S'il faut passer en chinois traditionnel |
| supprimer_pun | Non | int | 0 | S'il faut supprimer les marques de ponctuation |
| tâche | Non | Chaîne | transcription | Identifier les types de tâches, supporter transcrire et traduire |
| langue | Non | Chaîne | zh | Définir la langue, l'abréviation, si aucune, détecte automatiquement la langue |
Résultat de retour:
| Champs | taper | illustrer |
|---|---|---|
| Résultats | liste | Résultats de l'identification de la segmentation |
| + Résultat | Str | Le résultat de chaque morceau de texte |
| + démarrer | int | L'heure de début de chaque tranche, unité de secondes |
| + fin | int | L'heure de fin de chaque tranche, unité de secondes |
| code | int | Code d'erreur, 0 est une identification réussie |
Les exemples sont les suivants:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Pour une compréhension facile, voici un code Python qui appelle l'interface Web. Ce qui suit est la méthode /recognition d'appel.
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )Les pages de test fournies sont les suivantes:
La page de la page d'accueil http://127.0.0.1:5000/ est la suivante:
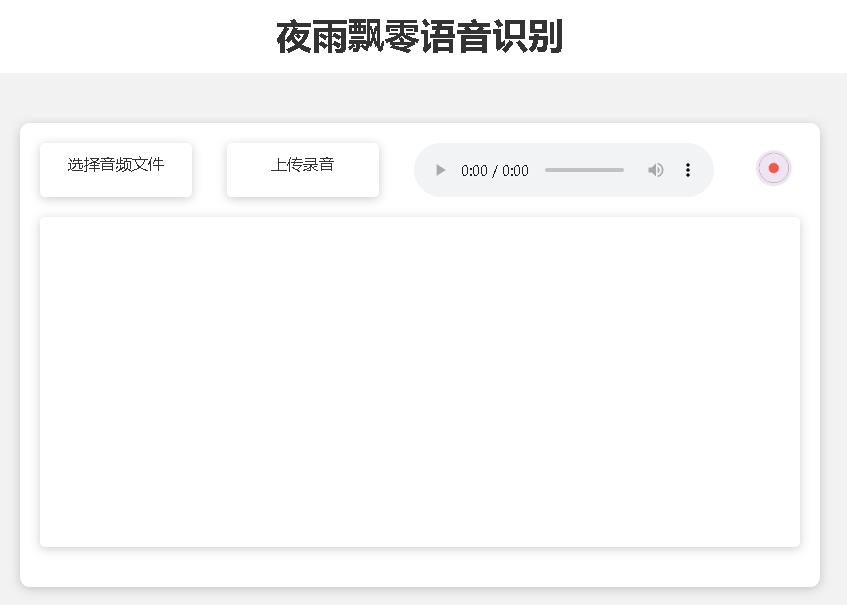
La page de document http://127.0.0.1:5000/docs est la suivante:
Voici un moyen d'accélérer le ctranslate2. Bien que la vitesse de raisonnement du pipeline d'utiliser les transformateurs soit déjà très rapide, vous devez d'abord convertir le modèle et convertir le modèle fusionné en modèle CTRANSLATE2. En tant que commande suivante, --model spécifie le chemin du modèle fusionné et prend également en charge directement l'utilisation du modèle d'origine Whisper, tel que spécifiant directement openai/whisper-large-v2 . Le paramètre --output_dir spécifie le chemin du modèle Ctranslate2 converti, et le paramètre --quantization spécifie la taille du modèle de quantification. Si vous ne voulez pas le modèle de quantification, vous pouvez supprimer directement ce paramètre.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Exécuter le programme suivant pour la reconnaissance vocale, --audio_path spécifie le chemin audio à prédire. --model_path Spécifie le modèle Ctranslate2 converti. Pour plus d'autres paramètres, veuillez consulter ce programme.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2Le résultat de sortie est le suivant:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 Le code source pour l'installation et le déploiement se trouve dans le répertoire AndroidDemo. Les documents spécifiques peuvent être affichés dans Readme.md dans ce répertoire.



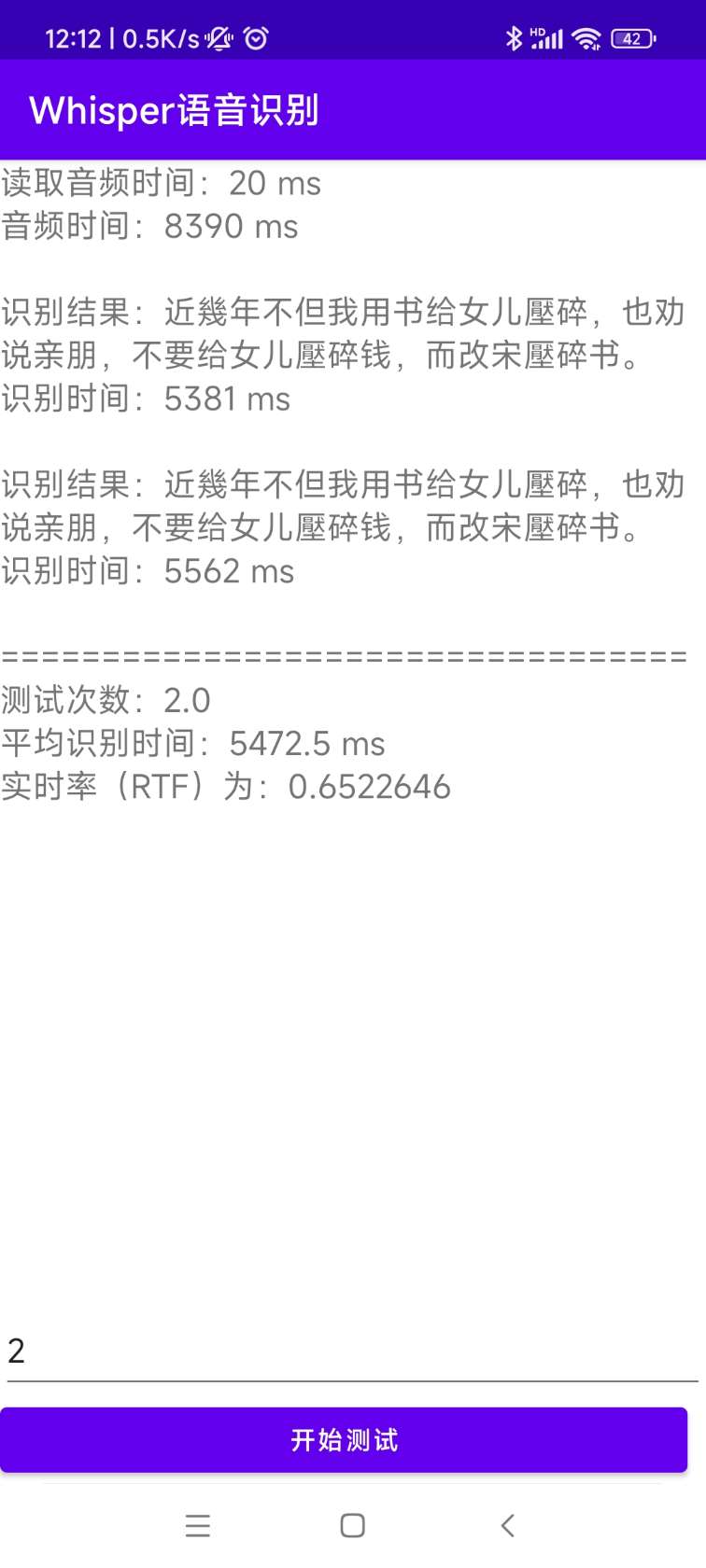
Le programme est dans le répertoire Whisperdesktop. Les documents spécifiques peuvent être consultés sur Readme.md dans ce répertoire.
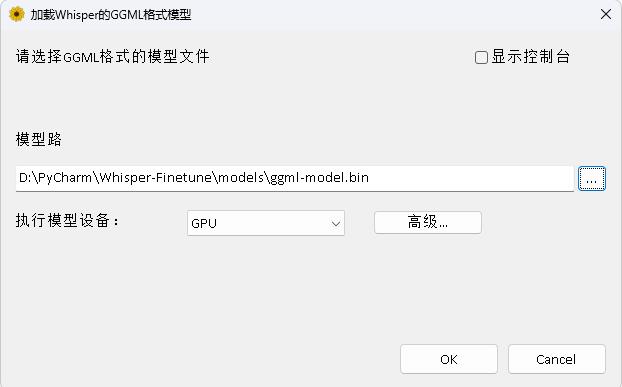
Récompensez un dollar pour soutenir l'auteur


