Whisper Finetune
1.0.0
China yang disederhanakan | Bahasa inggris
Openai membuka Proyek Whisper, yang mengklaim telah mencapai tingkat pengenalan suara bahasa Inggris manusia, dan juga mendukung pengenalan suara otomatis dalam 98 bahasa lainnya. Tugas pengenalan ucapan otomatis dan terjemahan yang disediakan oleh Whisper dapat mengubah ucapan dalam berbagai bahasa menjadi teks, dan juga dapat menerjemahkan teks -teks ini ke dalam bahasa Inggris. Tujuan utama dari proyek ini adalah untuk menyempurnakan model Whisper menggunakan LORA, pelatihan data cap dukungan waktu, pelatihan data cap waktu, dan pelatihan data yang tidak bisa berkata-kata . Saat ini, beberapa model bersumber terbuka. Anda dapat melihatnya di Openai. Berikut ini mencantumkan beberapa model yang umum digunakan. Selain itu, proyek ini juga mendukung inferensi Ctranslate2 yang dipercepat dan inferensi yang dipercepat GGML. Sebagai pengingat, inferensi yang dipercepat mendukung konversi langsung menggunakan model asli Whisper, dan tidak harus memerlukan penyempurnaan. Mendukung aplikasi desktop Windows, aplikasi Android, dan penyebaran server.
Setiap orang dipersilakan untuk memindai kode QR untuk memasuki planet pengetahuan (kiri) atau grup QQ (kanan) untuk diskusi. Planet Pengetahuan menyediakan file model proyek dan proyek model terkait blogger lainnya, serta beberapa sumber daya lainnya.
Lingkungan Penggunaan:
aishell.py : Buat data pelatihan Aishell.finetune.py : Fine-tune model.merge_lora.py : Model yang menggabungkan Whisper dan Lora.evaluation.py : Evaluasi model yang disesuaikan atau model asli Whisper.infer.py : Gunakan model fine-tuned untuk menelepon atau model bisikan pada transformer untuk memprediksi.infer_ct2.py : Gunakan model yang dikonversi ke Ctranslate2 untuk memprediksi, terutama merujuk pada penggunaan program ini.infer_gui.py : Ada operasi antarmuka GUI, menggunakan model fine-tuned atau model Whisper pada transformator untuk memprediksi.infer_server.py : Gunakan model yang disesuaikan atau model bisikan pada transformator untuk digunakan ke server dan memberikannya kepada klien untuk menelepon.convert-ggml.py : Konversi model ke model format GGML untuk aplikasi Android atau Windows.AndroidDemo : Direktori ini menyimpan kode sumber untuk menggunakan model ke Android.WhisperDesktop : Direktori ini menyimpan program untuk aplikasi desktop Windows. | Menggunakan model | Tentukan bahasa | Aishell_test | test_net | test_meeting | Set tes Kanton | Akuisisi model |
|---|---|---|---|---|---|---|
| Berbisik kecil | Cina | 0.31898 | 0.40482 | 0.75332 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Basis berbisik | Cina | 0.22196 | 0.30404 | 0.50378 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Small | Cina | 0.13897 | 0.18417 | 0.31154 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Medium | Cina | 0,09538 | 0.13591 | 0.26669 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Berbisik-besar | Cina | 0,08969 | 0.12933 | 0.23439 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V2 | Cina | 0.08817 | 0.12332 | 0.26547 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V3 | Cina | 0,08086 | 0.11452 | 0.19878 | 0.18782 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Menggunakan model | Tentukan bahasa | Dataset | Aishell_test | test_net | test_meeting | Set tes Kanton | Akuisisi model |
|---|---|---|---|---|---|---|---|
| Berbisik kecil | Cina | Aishell | 0.13043 | 0.4463 | 0.57728 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Basis berbisik | Cina | Aishell | 0.08999 | 0.33089 | 0.40713 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Small | Cina | Aishell | 0,05452 | 0.19831 | 0.24229 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Medium | Cina | Aishell | 0,03681 | 0.13073 | 0.16939 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V2 | Cina | Aishell | 0,03139 | 0.12201 | 0.15776 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V3 | Cina | Aishell | 0,03660 | 0.09835 | 0.13706 | 0.20060 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V3 | Orang Kanton | Dataset Kanton | 0.06857 | 0.11369 | 0.17452 | 0,03524 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Berbisik kecil | Cina | Wenetspeech | 0.17711 | 0.24783 | 0.39226 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Basis berbisik | Cina | Wenetspeech | 0.14548 | 0.17747 | 0.30590 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Small | Cina | Wenetspeech | 0.08484 | 0.11801 | 0.23471 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Medium | Cina | Wenetspeech | 0,05861 | 0,08794 | 0.19486 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V2 | Cina | Wenetspeech | 0,05443 | 0,08367 | 0.19087 | N/a | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Whisper-Large-V3 | Cina | Wenetspeech | 0,04947 | 0.10711 | 0.17429 | 0.47431 | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
test_long.wav , dan durasinya adalah 3 menit. Program pengujian ada di tools/run_compute.sh .| Metode percepatan | kecil | basis | Kecil | sedang | V2 besar | V3 besar |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1.458S | 1.671S | 2.331S | 11.071S | 4.779S | 12.826S |
Transformers ( fp16 + batch_size=16 + Compile ) | 1.477 | 1.675S | 2.357 | 11.003S | 4.799S | 12.643S |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461S | 1.676S | 2.301S | 11.062S | 4.608S | 12.505S |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436S | 1.630 -an | 2.258S | 10.533S | 4.344S | 11.651S |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442S | 1.686S | 2.277S | 11.000s | 4.543S | 12.592S |
Transformers ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409 | 1.643S | 2.220 -an | 10.390 -an | 4.377S | 11.703S |
Whisper lebih cepat ( fp16 + beam_size=1 ) | 2.179S | 1.492S | 2.327s | 3.752S | 5.677S | 31.541S |
Whisper lebih cepat ( 8-bit + beam_size=1 ) | 2.609 | 1.728S | 2.744S | 4.688S | 6.571S | 29.307S |
| Metode pemrosesan daftar data | Aishell | Wenetspeech |
|---|---|---|
| Tambahkan tanda baca | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
| Tambahkan tanda baca dan cap waktu | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan | Bergabunglah dengan Planet Pengetahuan untuk mendapatkan |
Catatan penting:
aishell_test adalah set tes Aishell, dan test_net dan test_meeting adalah set tes Wenetspeech.dataset/test_long.wav , dan durasinya adalah 3 menit.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Kemudian masukkan gambar dan pasang jalur saat ini ke direktori /workspace wadah.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl Kumpulan data pelatihan adalah sebagai berikut, yang merupakan daftar data JSONLINES, yaitu, setiap baris adalah data JSON, dan format data adalah sebagai berikut. Proyek ini menyediakan program aishell.py yang membuat data Aishell set. Melaksanakan program ini dapat secara otomatis mengunduh dan menghasilkan pelatihan dan set tes dalam format berikut. Catatan: Program ini dapat melewatkan proses pengunduhan dengan menentukan file terkompresi Aishell. Jika diunduh secara langsung, itu akan sangat lambat. Anda dapat menggunakan beberapa pengunduh seperti Thunder dan pengunduh lainnya, dan kemudian menentukan jalur file terkompresi yang diunduh melalui parameter --filepath , seperti /home/test/data_aishell.tgz .
Tips:
sentences .language .sentences adalah [] , bidang sentence adalah "" dan bidang language mungkin tidak ada.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Setelah data disiapkan, Anda dapat mulai menyempurnakan model. Dua parameter terpenting untuk pelatihan adalah: --base_model Menentukan model Whisper yang disempurnakan. Nilai parameter ini perlu ada di tempat pelukan. Ini tidak memerlukan unduhan di muka. Ini dapat diunduh secara otomatis saat memulai pelatihan. Tentu saja, itu juga dapat diunduh terlebih dahulu. Kemudian --base_model Menentukan adalah jalur, dan --local_files_only diatur ke true. Yang kedua --output_path adalah jalur pos pemeriksaan LORA yang disimpan selama pelatihan, karena kami menggunakan Lora untuk menyempurnakan model. Jika Anda ingin menabung cukup, yang terbaik adalah mengatur --use_8bit menjadi salah, sehingga kecepatan pelatihan jauh lebih cepat. Untuk lebih banyak parameter lainnya, silakan periksa program ini.
Perintah pelatihan kartu tunggal adalah sebagai berikut. Sistem Windows tidak dapat menambahkan parameter CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Ada dua metode untuk pelatihan multi-kartu, yaitu Torchrun dan Accelerate. Pengembang dapat menggunakan metode yang sesuai sesuai dengan kebiasaan mereka sendiri.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Pertama, konfigurasikan parameter pelatihan. Prosesnya adalah meminta pengembang untuk menjawab beberapa pertanyaan. Ini pada dasarnya dilakukan secara default, tetapi ada beberapa parameter yang perlu ditetapkan sesuai dengan situasi yang sebenarnya.
accelerate configIni mungkin prosesnya:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
Setelah konfigurasi selesai, Anda dapat menggunakan perintah berikut untuk melihat konfigurasi.
accelerate envPerintah pelatihan mulai adalah sebagai berikut.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/Log output adalah sebagai berikut:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} Setelah penyesuaian selesai, akan ada dua model. Yang pertama adalah model dasar Whisper dan yang kedua adalah model LORA. Kedua model ini perlu digabungkan sebelum operasi selanjutnya dapat dilakukan. Program ini hanya perlu melewati dua parameter. --lora_model Menentukan jalur model LORA yang disimpan setelah pelatihan, yang sebenarnya merupakan jalur folder pos pemeriksaan. Yang kedua --output_dir adalah direktori yang disimpan dari model gabungan.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Prosedur berikut dijalankan untuk mengevaluasi model, dua parameter yang paling penting adalah. --model_path pertama menentukan jalur model gabungan, dan juga mendukung penggunaan model asli Whisper secara langsung, seperti secara langsung menentukan openai/whisper-large-v2 , dan yang kedua adalah --metric menentukan metode evaluasi, seperti tingkat kesalahan cer kerja dan laju kesalahan kata wer . Kiat: Tidak ada model yang disempurnakan, dan output dapat diselingi, mempengaruhi akurasi. Untuk lebih banyak parameter lainnya, silakan periksa program ini.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Jalankan program berikut untuk pengenalan suara. Ini menggunakan Transformers untuk secara langsung memanggil model yang disesuaikan atau prediksi model asli, dan mendukung akselerasi kompiler, flashattentions2 akselerasi, dan akselerasi Pytorch2.0 yang lebih baik. Parameter --audio_path pertama menentukan jalur audio untuk diprediksi. Yang kedua --model_path menentukan jalur model gabungan, dan juga mendukung penggunaan model asli Whisper secara langsung, seperti secara langsung menentukan openai/whisper-large-v2 . Untuk lebih banyak parameter lainnya, silakan periksa program ini.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path Menentukan model Transformers. Untuk lebih banyak parameter lainnya, silakan periksa program ini.
python infer_gui.py --model_path=models/whisper-tiny-finetuneAntarmuka setelah startup adalah sebagai berikut:
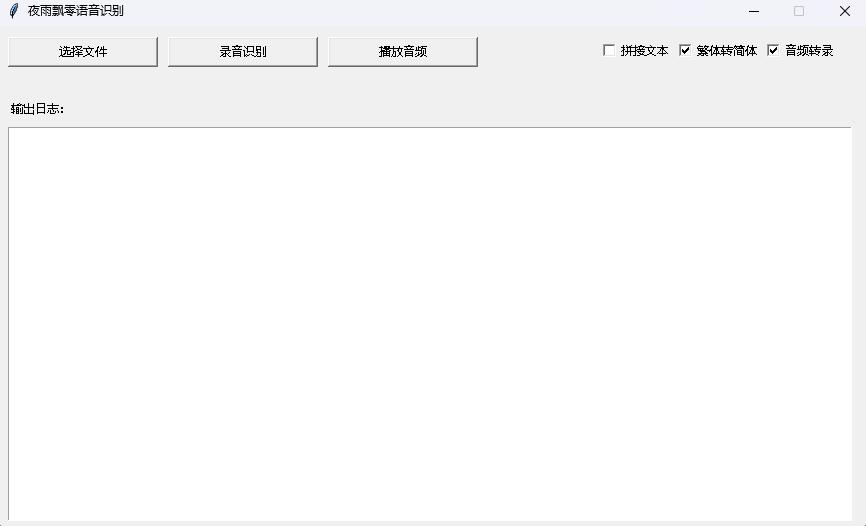
--host Menentukan alamat startup layanan, yang diatur ke 0.0.0.0 , yaitu, alamat apa pun dapat diakses. --port Menentukan nomor port yang digunakan. --model_path Menentukan model Transformers. --num_workers Menentukan berapa banyak utas yang digunakan untuk inferensi bersamaan, yang penting dalam penyebaran web. Ketika ada beberapa akses bersamaan, dimungkinkan untuk bernalar pada saat yang sama. Untuk lebih banyak parameter lainnya, silakan periksa program ini.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Saat ini, antarmuka /recognition identifikasi disediakan, dan parameter antarmuka adalah sebagai berikut.
| Bidang | Apakah perlu | jenis | nilai default | menjelaskan |
|---|---|---|---|---|
| audio | Ya | Mengajukan | File audio yang akan diidentifikasi | |
| to_simple | TIDAK | int | 1 | Apakah akan beralih ke bahasa Cina tradisional |
| lepaskan_pun | TIDAK | int | 0 | Apakah akan menghapus tanda baca |
| tugas | TIDAK | Rangkaian | salinan | Mengidentifikasi jenis tugas, mendukung transkripsi dan menerjemahkan |
| bahasa | TIDAK | Rangkaian | ZH | Atur bahasa, singkatan, jika tidak ada, secara otomatis mendeteksi bahasa |
Hasil pengembalian:
| Bidang | jenis | menjelaskan |
|---|---|---|
| Hasil | daftar | Hasil identifikasi segmentasi |
| +Hasilnya | str | Hasil dari setiap bagian teks |
| +Mulai | int | Waktu mulai dari setiap irisan, satuan detik |
| +end | int | Waktu akhir dari setiap irisan, satuan detik |
| kode | int | Kode kesalahan, 0 adalah identifikasi yang berhasil |
Contohnya adalah sebagai berikut:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Untuk pemahaman yang mudah, berikut adalah kode Python yang memanggil antarmuka web. Berikut ini adalah metode panggilan /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )Halaman uji yang disediakan adalah sebagai berikut:
Halaman beranda http://127.0.0.1:5000/ adalah sebagai berikut:
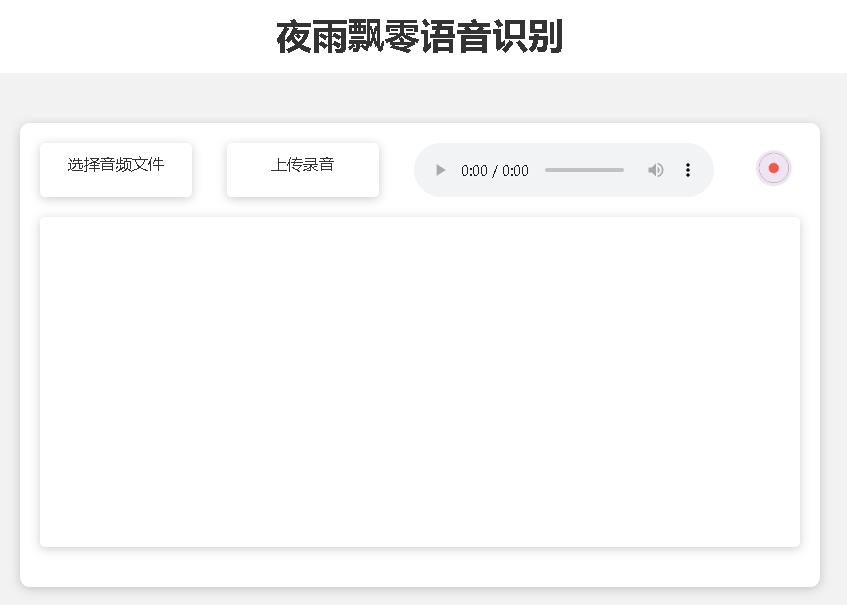
Halaman dokumen http://127.0.0.1:5000/docs halaman adalah sebagai berikut:
Berikut adalah cara untuk mempercepat Ctranslate2. Meskipun kecepatan penalaran pipa menggunakan Transformers sudah sangat cepat, Anda harus terlebih dahulu mengonversi model dan mengubah model gabungan menjadi model Ctranslate2. Sebagai perintah berikut, parameter --model menentukan jalur model gabungan, dan juga mendukung penggunaan model asli Whisper secara langsung, seperti secara langsung menentukan openai/whisper-large-v2 . Parameter --output_dir menentukan jalur model Ctranslate2 yang dikonversi, dan parameter --quantization menentukan ukuran model kuantisasi. Jika Anda tidak ingin model kuantisasi, Anda dapat secara langsung menghapus parameter ini.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Jalankan program berikut untuk pengenalan suara, parameter --audio_path menentukan jalur audio yang akan diprediksi. --model_path Menentukan model Ctranslate2 yang dikonversi. Untuk lebih banyak parameter lainnya, silakan periksa program ini.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2Hasil output adalah sebagai berikut:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
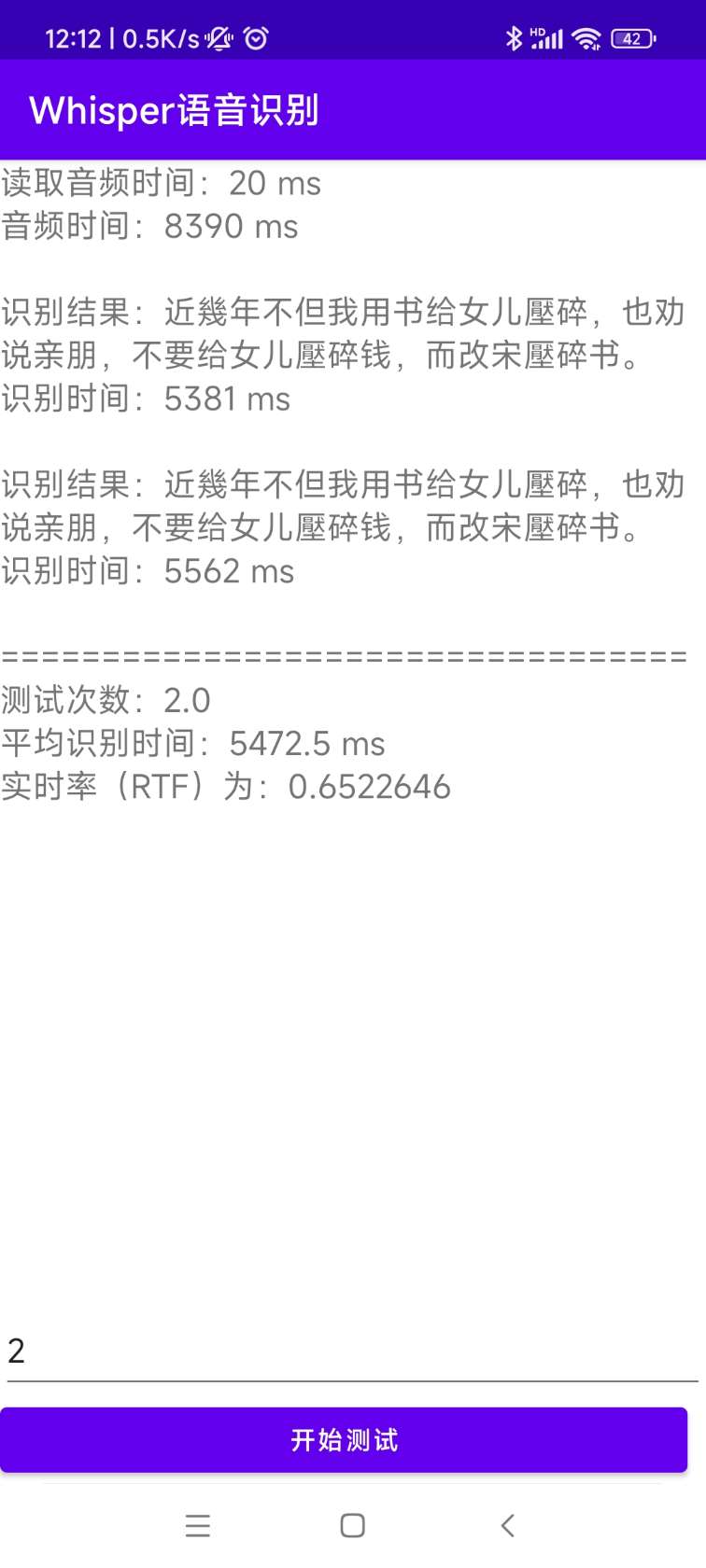
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 Kode sumber untuk instalasi dan penyebaran ada di direktori AndroidDemo. Dokumen spesifik dapat dilihat di ReadMe.md di direktori ini.



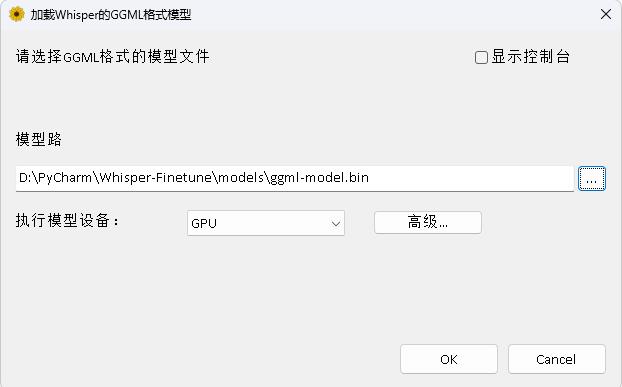
Program ini ada di direktori Whisperdesktop. Dokumen spesifik dapat dilihat di ReadMe.md di direktori ini.
Hadiah satu dolar untuk mendukung penulis


