Whisper Finetune
1.0.0
Chinês simplificado | Inglês
O Openai abre o projeto Whisper, que afirma ter atingido o nível humano de reconhecimento de voz em inglês, e também suporta reconhecimento automático de voz em outros 98 idiomas. As tarefas automáticas de reconhecimento de fala e tradução fornecidas pelo Whisper podem transformar a fala em vários idiomas em texto e também pode traduzir esses textos para o inglês. O principal objetivo deste projeto é ajustar o modelo Whisper usando o LORA, suportar treinamento de dados de carimbos de tempo, treinamento de dados de carimbo de hora e treinamento sem palavras . Atualmente, vários modelos são de origem aberta. Você pode vê -los no Openai. O seguinte lista vários modelos comumente usados. Além disso, o projeto também suporta a inferência acelerada do CTRANSLATE2 e a inferência acelerada do GGML. Como lembrete, a inferência acelerada suporta a conversão direta usando o modelo original do Whisper e não exige necessariamente o ajuste fino. Suporta aplicativos de desktop do Windows, aplicativos Android e implantação do servidor.
Todos são bem -vindos para digitalizar o código QR para inserir o planeta do conhecimento (à esquerda) ou o grupo QQ (à direita) para discussão. O Planeta de Conhecimento fornece arquivos de modelos de projeto e outros arquivos de modelos de projetos relacionados de blogueiros, bem como alguns outros recursos.
Ambiente de uso:
aishell.py : faça dados de treinamento Aishell.finetune.py : ajuste o modelo.merge_lora.py : Um modelo que mescla sussurra e Lora.evaluation.py : Avalie o modelo de ajuste fino ou o modelo original do Whisper.infer.py : use o modelo ajustado para chamar ou o modelo de sussurro nos transformadores para prever.infer_ct2.py : use o modelo convertido em ctranslate2 para prever, consulte principalmente o uso deste programa.infer_gui.py : existe uma operação de interface da GUI, usando o modelo de ajuste fino ou o modelo de sussurro nos transformadores para prever.infer_server.py : use o modelo ajustado ou o modelo de sussurro nos transformadores para implantar no servidor e forneça-o ao cliente para ligar.convert-ggml.py : converta o modelo para o modelo de formato GGML para aplicativos Android ou Windows.AndroidDemo : Este diretório armazena o código -fonte para implantar o modelo no Android.WhisperDesktop : Este diretório armazena programas para aplicativos de desktop do Windows. | Usando o modelo | Especifique a linguagem | aishell_test | test_net | test_meeting | Conjunto de testes cantonês | Aquisição de modelos |
|---|---|---|---|---|---|---|
| sussurro minúsculo | chinês | 0,31898 | 0,40482 | 0,75332 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro-base | chinês | 0,22196 | 0.30404 | 0,50378 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro | chinês | 0.13897 | 0,18417 | 0.31154 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Medium | chinês | 0,09538 | 0,13591 | 0,26669 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro grande | chinês | 0.08969 | 0.12933 | 0,23439 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V2 | chinês | 0,08817 | 0,12332 | 0,26547 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V3 | chinês | 0.08086 | 0.11452 | 0.19878 | 0.18782 | Junte -se ao planeta do conhecimento para obter |
| Usando o modelo | Especifique a linguagem | Conjunto de dados | aishell_test | test_net | test_meeting | Conjunto de testes cantonês | Aquisição de modelos |
|---|---|---|---|---|---|---|---|
| sussurro minúsculo | chinês | Aishell | 0.13043 | 0,4463 | 0,57728 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro-base | chinês | Aishell | 0.08999 | 0.33089 | 0,40713 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro | chinês | Aishell | 0,05452 | 0.19831 | 0,24229 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Medium | chinês | Aishell | 0,03681 | 0.13073 | 0.16939 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V2 | chinês | Aishell | 0,03139 | 0.12201 | 0.15776 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V3 | chinês | Aishell | 0,03660 | 0,09835 | 0.13706 | 0.20060 | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V3 | Cantonês | DataSet cantonês | 0,06857 | 0.11369 | 0,17452 | 0,03524 | Junte -se ao planeta do conhecimento para obter |
| sussurro minúsculo | chinês | Wenetspeech | 0.17711 | 0,24783 | 0,39226 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro-base | chinês | Wenetspeech | 0,14548 | 0,17747 | 0,30590 | N / D | Junte -se ao planeta do conhecimento para obter |
| sussurro | chinês | Wenetspeech | 0,08484 | 0.11801 | 0,23471 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Medium | chinês | Wenetspeech | 0,05861 | 0.08794 | 0.19486 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V2 | chinês | Wenetspeech | 0,05443 | 0,08367 | 0.19087 | N / D | Junte -se ao planeta do conhecimento para obter |
| Whisper-Large-V3 | chinês | Wenetspeech | 0,04947 | 0.10711 | 0,17429 | 0,47431 | Junte -se ao planeta do conhecimento para obter |
test_long.wav e a duração é de 3 minutos. O programa de teste está em tools/run_compute.sh .| Método de aceleração | pequeno | base | Pequeno | médio | Grande-v2 | Grande-v3 |
|---|---|---|---|---|---|---|
Transformers ( fp16 + batch_size=16 ) | 1.458s | 1.671s | 2.331s | 11.071s | 4.779S | 12.826s |
Transformers ( fp16 + batch_size=16 + Compile ) | 1.477s | 1.675s | 2.357s | 11.003s | 4.799S | 12.643s |
Transformers ( fp16 + batch_size=16 + BetterTransformer ) | 1.461s | 1.676s | 2.301s | 11.062s | 4.608s | 12.505s |
Transformers ( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436s | 1.630s | 2.258s | 10.533s | 4.344s | 11.651s |
Transformers ( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1.686s | 2.277s | 11.000s | 4.543s | 12.592s |
Transformadores ( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409s | 1.643s | 2.220s | 10.390s | 4.377s | 11.703s |
Sussurro mais rápido ( fp16 + beam_size=1 ) | 2.179S | 1.492s | 2.327s | 3.752s | 5.677s | 31.541s |
Sussurro mais rápido ( 8-bit + beam_size=1 ) | 2.609s | 1.728s | 2.744s | 4.688s | 6.571s | 29.307s |
| Método de processamento da lista de dados | Aishell | Wenetspeech |
|---|---|---|
| Adicione a pontuação | Junte -se ao planeta do conhecimento para obter | Junte -se ao planeta do conhecimento para obter |
| Adicione pontuação e registro de data e hora | Junte -se ao planeta do conhecimento para obter | Junte -se ao planeta do conhecimento para obter |
Nota importante:
aishell_test é o conjunto de testes de Aishell e test_net e test_meeting são os conjuntos de testes do WeNetSpeech.dataset/test_long.wav , e a duração é de 3 minutos.conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel Em seguida, digite a imagem e monte o caminho atual para o diretório /workspace do contêiner.
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl O conjunto de dados de treinamento é o seguinte, que é uma lista de dados de linhas JSON, ou seja, cada linha é um JSON Data, e o formato de dados é o seguinte. Este projeto fornece um programa aishell.py que torna o Aishell Data Set. A execução deste programa pode baixar e gerar automaticamente conjuntos de treinamento e teste nos seguintes formatos. Nota: Este programa pode pular o processo de download especificando os arquivos compactados da Aishell. Se for baixado diretamente, será muito lento. Você pode usar alguns downloaders, como Thunder e outros downloaders e, em seguida, especificar o caminho de arquivo compactado baixado através do parâmetro --filepath , como /home/test/data_aishell.tgz .
Pontas:
sentences .language .sentences é [] , sentence é "" e language pode não existir.{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
} Depois que os dados são preparados, você pode iniciar o ajuste fino do modelo. Os dois parâmetros mais importantes para o treinamento são: --base_model especifica o modelo de sussurro ajustado. Esse valor de parâmetro precisa existir no huggingface. Isso não requer download antecipado. Pode ser baixado automaticamente ao iniciar o treinamento. Obviamente, ele também pode ser baixado com antecedência. Então --base_model Especifica é o caminho e --local_files_only é definido como true. O segundo --output_path é o caminho do ponto de verificação Lora salvo durante o treinamento, porque usamos o Lora para ajustar o modelo. Se você deseja economizar o suficiente, é melhor definir --use_8bit como false, para que a velocidade de treinamento seja muito mais rápida. Para mais parâmetros, verifique este programa.
O comando de treinamento de cartão único é o seguinte. O sistema Windows não pode adicionar CUDA_VISIBLE_DEVICES .
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/Existem dois métodos para treinamento com vários cartões, ou seja, Torchrun e acelerar. Os desenvolvedores podem usar os métodos correspondentes de acordo com seus próprios hábitos.
--nproc_per_node . torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/Primeiro, configure os parâmetros de treinamento. O processo é pedir ao desenvolvedor que responda a várias perguntas. É basicamente feito por padrão, mas existem vários parâmetros que precisam ser definidos de acordo com a situação real.
accelerate configEste é provavelmente o processo:
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
Após a conclusão da configuração, você pode usar o seguinte comando para visualizar a configuração.
accelerate envO comando de treinamento inicial é o seguinte.
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/O log de saída é o seguinte:
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03} Após a conclusão do ajuste fino, haverá dois modelos. O primeiro é o modelo básico do Whisper e o segundo é o modelo Lora. Esses dois modelos precisam ser mesclados antes que as operações subsequentes possam ser executadas. Este programa precisa passar apenas dois parâmetros. --lora_model especifica o caminho do modelo Lora salvo após o treinamento, que é na verdade o caminho da pasta do ponto de verificação. O segundo --output_dir é o diretório salvo do modelo mesclado.
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/ Os procedimentos a seguir são executados para avaliar o modelo, os dois parâmetros mais importantes são. O primeiro --model_path especifica o caminho do modelo mesclado e também suporta o uso do modelo original sussurrado diretamente, como especificar diretamente openai/whisper-large-v2 , e o segundo é --metric especifica o método de avaliação, como cer de erro verbal e wer de erro. Dica: não há modelo de ajuste fino e a saída pode ser pontuada, afetando a precisão. Para mais parâmetros, verifique este programa.
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer Execute o seguinte programa para reconhecimento de fala. Isso usa Transformers para chamar diretamente o modelo ajustado ou sussurrar previsão de modelo original e suporta a aceleração do compilador, a aceleração do Flashattion2 e a aceleração do melhor transformador de pytorch2.0. O primeiro parâmetro --audio_path especifica o caminho de áudio a ser previsto. O segundo --model_path especifica o caminho do modelo mesclado e também suporta o uso do modelo original sussurro diretamente, como especificar diretamente openai/whisper-large-v2 . Para mais parâmetros, verifique este programa.
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune --model_path Especifica o modelo Transformers. Para mais parâmetros, verifique este programa.
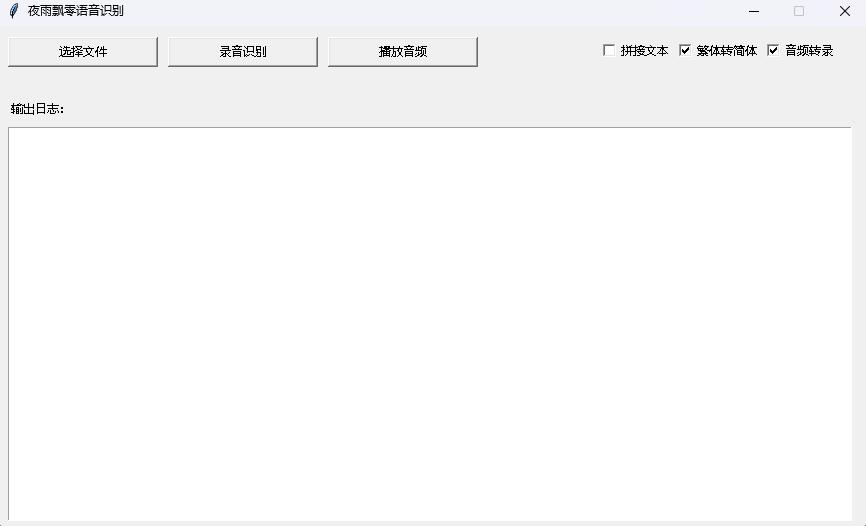
python infer_gui.py --model_path=models/whisper-tiny-finetuneA interface após a startup é a seguinte:
--host Especifica o endereço da inicialização do serviço, que é definido como 0.0.0.0 , ou seja, qualquer endereço pode ser acessado. --port Especifica o número da porta usado. --model_path Especifica o modelo Transformers. --num_workers Especifica quantos threads são usados para inferência simultânea, o que é importante na implantação da Web. Quando existem vários acessos simultâneos, é possível raciocinar ao mesmo tempo. Para mais parâmetros, verifique este programa.
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2 Atualmente, a interface /recognition de identificação é fornecida e os parâmetros da interface são os seguintes.
| Campos | É necessário | tipo | valor padrão | ilustrar |
|---|---|---|---|---|
| Áudio | sim | Arquivo | Arquivo de áudio a ser identificado | |
| to_simple | não | int | 1 | Se deve mudar para o chinês tradicional |
| remove_pun | não | int | 0 | Se deve remover os pontos de pontuação |
| tarefa | não | Corda | transcrição | Identificar tipos de tarefas, suportar transcrever e traduzir |
| linguagem | não | Corda | Zh | Defina a linguagem, abreviação, se não, detectar automaticamente automaticamente |
Resultado de retorno:
| Campos | tipo | ilustrar |
|---|---|---|
| Resultados | lista | Resultados de identificação de segmentação |
| +resultado | str | O resultado de cada pedaço de texto |
| +Iniciar | int | A hora de início de cada fatia, unidade segundos |
| +final | int | O horário final de cada fatia, unidade segundos |
| código | int | Código de erro, 0 é identificação bem -sucedida |
Exemplos são os seguintes:
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
} Para um entendimento fácil, aqui está um código Python que chama a interface da web. A seguir, é apresentado o método de chamada /recognition .
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
print ( response . text )As páginas de teste fornecidas são as seguintes:
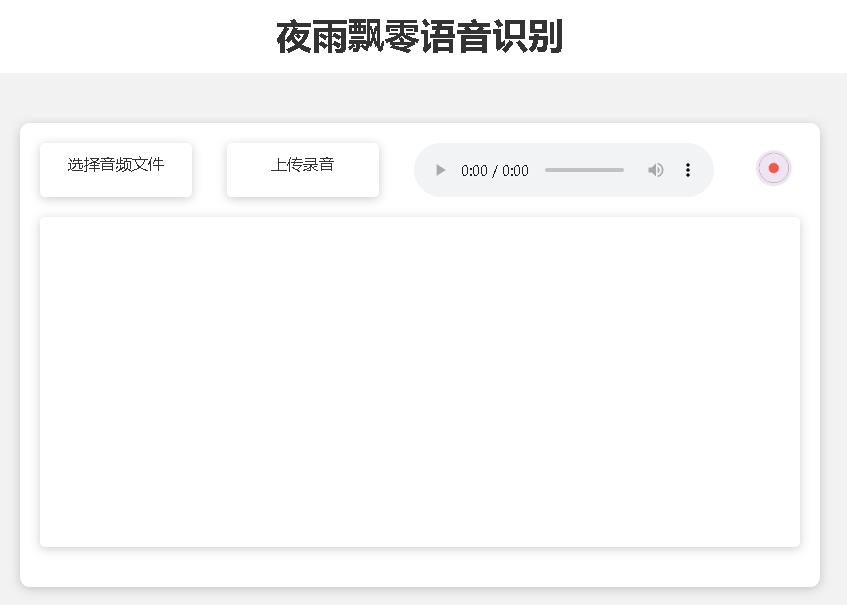
A página da página inicial http://127.0.0.1:5000/ é a seguinte:
A página do documento http://127.0.0.1:5000/docs página é a seguinte:
Aqui está uma maneira de acelerar o ctranslato2. Embora a velocidade de raciocínio do pipeline do uso de transformadores já seja muito rápida, você deve primeiro converter o modelo e converter o modelo mesclado no modelo CTranslate2. Como o comando a seguir, --model especifica o caminho do modelo mesclado e também suporta o uso do modelo original sussurrado diretamente, como especificar diretamente openai/whisper-large-v2 . O parâmetro --output_dir especifica o caminho do modelo CTRANSLATE2 convertido, e o parâmetro --quantization especifica o tamanho do modelo de quantização. Se você não deseja o modelo de quantização, poderá remover diretamente este parâmetro.
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16 Execute o seguinte programa para reconhecimento de fala, --audio_path especifica o caminho do áudio a ser previsto. --model_path Especifica o modelo CTRANSLATE2 convertido. Para mais parâmetros, verifique este programa.
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2O resultado da saída é o seguinte:
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
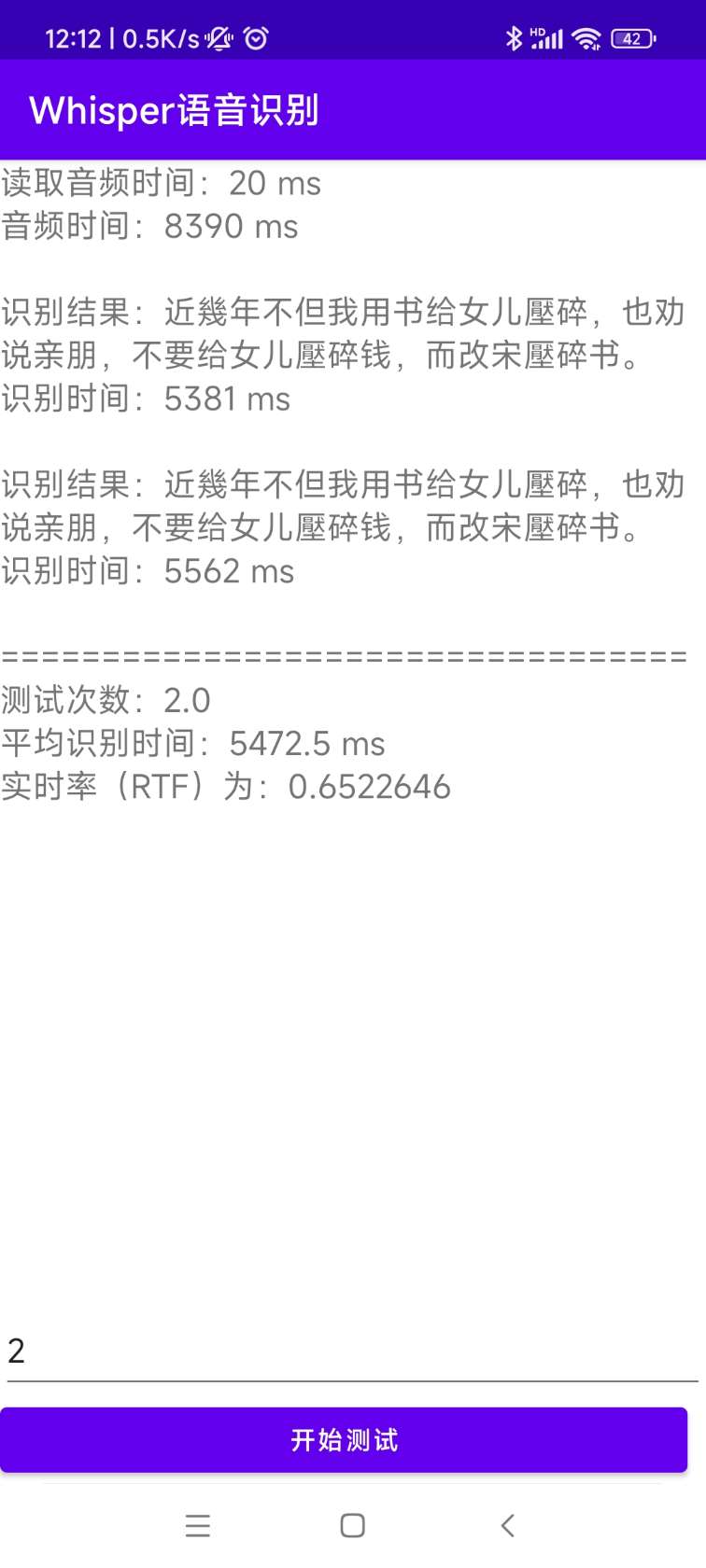
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 O código -fonte para instalação e implantação está no diretório AndroidDemo. Os documentos específicos podem ser visualizados no ReadMe.md neste diretório.



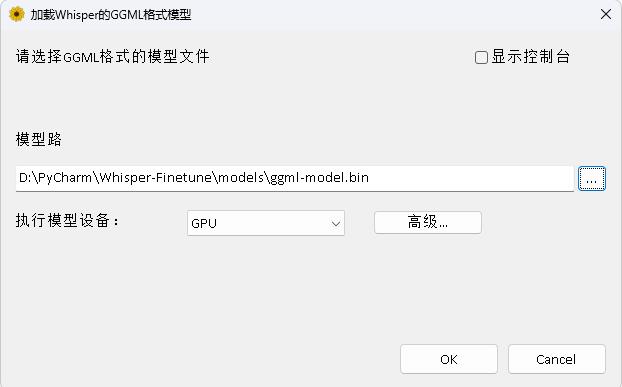
O programa está no diretório Whisperdesktop. Os documentos específicos podem ser visualizados no readme.md neste diretório.
Recompensar um dólar para apoiar o autor


