Whisper Finetune
1.0.0
単純化された中国人|英語
Openaiは、英語の音声認識の人間レベルに達したと主張するWhisperプロジェクトを開き、他の98言語での自動音声認識もサポートしています。ささやきが提供する自動音声認識と翻訳タスクは、さまざまな言語の音声をテキストに変えることができ、これらのテキストを英語に変換することもできます。このプロジェクトの主な目的は、LORAを使用してささやきモデルを微調整し、タイムスタンプデータトレーニング、タイムスタンプデータトレーニング、およびスピーチレスデータトレーニングをサポートすることです。現在、いくつかのモデルがオープンソースです。 Openaiで表示できます。以下には、いくつかの一般的に使用されるモデルがリストされています。さらに、このプロジェクトは、Ctranslate2加速推論とGGML加速推論もサポートしています。リマインダーとして、加速された推論は、Whisper Originalモデルを使用した直接変換をサポートし、必ずしも微調整を必要としません。 Windowsデスクトップアプリケーション、Androidアプリケーション、サーバーの展開をサポートしています。
誰もがQRコードをスキャンして、知識惑星(左)またはQQグループ(右)を入力することを歓迎します。ナレッジプラネットは、プロジェクトモデルファイルとブロガーの他の関連プロジェクトモデルファイル、および他のリソースを提供します。
使用環境:
aishell.pyのトレーニングデータを作成します。finetune.py :モデルを微調整します。merge_lora.py :ささやきとロラを融合するモデル。evaluation.py :微調整されたモデルを評価するか、元のモデルをささやきます。infer.py :微調整されたモデルを使用して呼び出し、変圧器のささやきモデルを使用して予測します。infer_ct2.pyに変換されたモデルを使用して予測します。これは、主にこのプログラムの使用を参照してください。infer_gui.py :微調整されたモデルまたは変圧器のささやきモデルを予測するGUIインターフェイス操作があります。infer_server.py :微調整されたモデルまたは変圧器のささやきモデルを使用して、サーバーに展開し、クライアントに呼び出すように提供します。convert-ggml.py :モデルをAndroidまたはWindowsアプリケーションのGGML形式モデルに変換します。AndroidDemo :このディレクトリは、モデルをAndroidに展開するためのソースコードを保存します。WhisperDesktop :このディレクトリは、Windowsデスクトップアプリケーション用のプログラムを保存しています。 | モデルを使用します | 言語を指定します | aishell_test | test_net | test_meeting | 広東語のテストセット | モデルの獲得 |
|---|---|---|---|---|---|---|
| ささやき声 | 中国語 | 0.31898 | 0.40482 | 0.75332 | n/a | 知識惑星に参加して入手してください |
| ささやきベース | 中国語 | 0.22196 | 0.30404 | 0.50378 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | 0.13897 | 0.18417 | 0.31154 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | 0.09538 | 0.13591 | 0.26669 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | 0.08969 | 0.12933 | 0.23439 | n/a | 知識惑星に参加して入手してください |
| Whisper-Large-V2 | 中国語 | 0.08817 | 0.12332 | 0.26547 | n/a | 知識惑星に参加して入手してください |
| ささやき声-V3 | 中国語 | 0.08086 | 0.11452 | 0.19878 | 0.18782 | 知識惑星に参加して入手してください |
| モデルを使用します | 言語を指定します | データセット | aishell_test | test_net | test_meeting | 広東語のテストセット | モデルの獲得 |
|---|---|---|---|---|---|---|---|
| ささやき声 | 中国語 | アイシェル | 0.13043 | 0.4463 | 0.57728 | n/a | 知識惑星に参加して入手してください |
| ささやきベース | 中国語 | アイシェル | 0.08999 | 0.33089 | 0.40713 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | アイシェル | 0.05452 | 0.19831 | 0.24229 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | アイシェル | 0.03681 | 0.13073 | 0.16939 | n/a | 知識惑星に参加して入手してください |
| Whisper-Large-V2 | 中国語 | アイシェル | 0.03139 | 0.12201 | 0.15776 | n/a | 知識惑星に参加して入手してください |
| ささやき声-V3 | 中国語 | アイシェル | 0.03660 | 0.09835 | 0.13706 | 0.20060 | 知識惑星に参加して入手してください |
| ささやき声-V3 | 広東語 | 広東データセット | 0.06857 | 0.11369 | 0.17452 | 0.03524 | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | wenetspeech | 0.17711 | 0.24783 | 0.39226 | n/a | 知識惑星に参加して入手してください |
| ささやきベース | 中国語 | wenetspeech | 0.14548 | 0.17747 | 0.30590 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | wenetspeech | 0.08484 | 0.11801 | 0.23471 | n/a | 知識惑星に参加して入手してください |
| ささやき声 | 中国語 | wenetspeech | 0.05861 | 0.08794 | 0.19486 | n/a | 知識惑星に参加して入手してください |
| Whisper-Large-V2 | 中国語 | wenetspeech | 0.05443 | 0.08367 | 0.19087 | n/a | 知識惑星に参加して入手してください |
| ささやき声-V3 | 中国語 | wenetspeech | 0.04947 | 0.10711 | 0.17429 | 0.47431 | 知識惑星に参加して入手してください |
test_long.wavとして使用し、持続時間は3分です。テストプログラムはtools/run_compute.shにあります。| 加速方法 | 小さい | ベース | 小さい | 中くらい | 大V2 | 大V3 |
|---|---|---|---|---|---|---|
トランス( fp16 + batch_size=16 ) | 1.458S | 1.671S | 2.331s | 11.071S | 4.779S | 12.826S |
トランス( fp16 + batch_size=16 + Compile ) | 1.477S | 1.675S | 2.357S | 11.003S | 4.799S | 12.643S |
トランス( fp16 + batch_size=16 + BetterTransformer ) | 1.461S | 1.676S | 2.301s | 11.062S | 4.608s | 12.505S |
トランス( fp16 + batch_size=16 + Flash Attention 2 ) | 1.436s | 1.630S | 2.258s | 10.533S | 4.344s | 11.651S |
変圧器( fp16 + batch_size=16 + Compile + BetterTransformer ) | 1.442s | 1.686S | 2.277S | 11.000秒 | 4.543s | 12.592S |
トランス( fp16 + batch_size=16 + Compile + Flash Attention 2 ) | 1.409S | 1.643S | 2.220S | 10.390S | 4.377S | 11.703S |
より速いささやき( fp16 + beam_size=1 ) | 2.179S | 1.492S | 2.327S | 3.752s | 5.677S | 31.541S |
より速いささやき( 8-bit + beam_size=1 ) | 2.609S | 1.728s | 2.744s | 4.688s | 6.571S | 29.307S |
| データリスト処理方法 | アイシェル | wenetspeech |
|---|---|---|
| 句読点を追加します | 知識惑星に参加して入手してください | 知識惑星に参加して入手してください |
| 句読点とタイムスタンプを追加します | 知識惑星に参加して入手してください | 知識惑星に参加して入手してください |
重要な注意:
aishell_test aishellのテストセットであり、 test_netとtest_meeting wenetspeechのテストセットです。dataset/test_long.wavで、期間は3分です。conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidiasudo docker pull pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel次に、画像を入力し、現在のパスをコンテナの/workspaceディレクトリにマウントします。
sudo nvidia-docker run --name pytorch -it -v $PWD :/workspace pytorch/pytorch:2.1.0-cuda11.8-cudnn8-devel /bin/bashpython -m pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simplepython -m pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whlトレーニングデータセットは次のとおりです。これはJSonlinesのデータリストです。つまり、各行はJSONデータであり、データ形式は次のとおりです。このプロジェクトは、Aishellのデータセットを作成するプログラムaishell.pyを提供します。このプログラムを実行すると、次の形式でトレーニングとテストセットを自動的にダウンロードして生成できます。注:このプログラムは、Aishellの圧縮ファイルを指定することにより、ダウンロードプロセスをスキップできます。直接ダウンロードされると、非常に遅くなります。 Thunderやその他のダウンローダーなどの一部のダウンローダーを使用してから、parameter /home/test/data_aishell.tgz test/data_aishell.tgzなどの--filepathを介してダウンロードした圧縮ファイルパスを指定できます。
ヒント:
sentencesフィールドにデータを含めることはできません。languageフィールドデータを含めることはできません。sentencesフィールドは[]であり、 sentenceフィールドは""であり、 languageフィールドは存在しない可能性があります。{
"audio" : {
"path" : " dataset/0.wav "
},
"sentence" : "近几年,不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 " ,
"language" : " Chinese " ,
"sentences" : [
{
"start" : 0 ,
"end" : 1.4 ,
"text" : "近几年, "
},
{
"start" : 1.42 ,
"end" : 8.4 ,
"text" : "不但我用书给女儿压岁,也劝说亲朋不要给女儿压岁钱,而改送压岁书。 "
}
],
"duration" : 7.37
}データが準備されたら、モデルの微調整を開始できます。トレーニングの2つの最も重要なパラメーターは次のとおりです。 --base_model 、微調整されたささやきモデルを指定します。このパラメーター値は、Huggingfaceに存在する必要があります。これには、事前ダウンロードを必要としません。トレーニングを開始するときに自動的にダウンロードできます。もちろん、事前にダウンロードすることもできます。次に、 --base_modelパスであり、 --local_files_onlyがtrueに設定されています。 2番目の--output_pathは、トレーニング中に保存されたLORAチェックポイントパスです。これは、LORAを使用してモデルを微調整するためです。十分に保存したい場合は、トレーニング速度がはるかに高速になるように、 --use_8bit falseに設定するのが最善です。その他のパラメーターについては、このプログラムを確認してください。
単一のカードトレーニングコマンドは次のとおりです。 WindowsシステムはCUDA_VISIBLE_DEVICESパラメーターを追加できません。
CUDA_VISIBLE_DEVICES=0 python finetune.py --base_model=openai/whisper-tiny --output_dir=output/マルチカードトレーニングには、TorchrunとAccelerateの2つの方法があります。開発者は、自分の習慣に応じて対応する方法を使用できます。
--nproc_per_nodeを介して使用するグラフィックカードの数を指定します。 torchrun --nproc_per_node=2 finetune.py --base_model=openai/whisper-tiny --output_dir=output/まず、トレーニングパラメーターを構成します。プロセスは、開発者にいくつかの質問に答えるように依頼することです。基本的にデフォルトで行われますが、実際の状況に従って設定する必要があるいくつかのパラメーターがあります。
accelerate configこれはおそらくプロセスです。
--------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------Which type of machine are you using?
multi-GPU
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you wish to optimize your script with torch dynamo?[yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
Do you want to use Megatron-LM ? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:
--------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /home/test/.cache/huggingface/accelerate/default_config.yaml
構成が完了したら、次のコマンドを使用して構成を表示できます。
accelerate env開始トレーニングコマンドは次のとおりです。
accelerate launch finetune.py --base_model=openai/whisper-tiny --output_dir=output/出力ログは次のとおりです。
{ ' loss ' : 0.9098, ' learning_rate ' : 0.000999046843662503, ' epoch ' : 0.01}
{ ' loss ' : 0.5898, ' learning_rate ' : 0.0009970611012927184, ' epoch ' : 0.01}
{ ' loss ' : 0.5583, ' learning_rate ' : 0.0009950753589229333, ' epoch ' : 0.02}
{ ' loss ' : 0.5469, ' learning_rate ' : 0.0009930896165531485, ' epoch ' : 0.02}
{ ' loss ' : 0.5959, ' learning_rate ' : 0.0009911038741833634, ' epoch ' : 0.03}微調整が完了した後、2つのモデルがあります。 1つ目はささやきの基本モデルで、2つ目はLORAモデルです。これらの2つのモデルは、後続の操作を実行する前にマージする必要があります。このプログラムは、2つのパラメーターのみを渡す必要があります。 --lora_modelトレーニング後に保存されたLORAモデルパスを指定します。これは実際にはチェックポイントフォルダーパスです。 2番目の--output_dirは、マージされたモデルの保存されたディレクトリです。
python merge_lora.py --lora_model=output/whisper-tiny/checkpoint-best/ --output_dir=models/モデルを評価するために、次の手順が実行されます。2つの最も重要なパラメーターは次のとおりです。最初の--model_pathマージされたモデルパスを指定し、 openai/whisper-large-v2直接指定するなど、Whisper Originalモデルの使用も直接サポートします--metric番目は、動詞エラー率cerや単語エラーレートなどの評価方法を指定しwer 。ヒント:微調整されたモデルはなく、出力が中断され、精度に影響する可能性があります。その他のパラメーターについては、このプログラムを確認してください。
python evaluation.py --model_path=models/whisper-tiny-finetune --metric=cer音声認識のために次のプログラムを実行します。これにより、トランスが微調整されたモデルを直接呼び出すか、元のモデルの予測をささやき、コンパイラアクセル、Flashattention2加速、およびPytorch2.0のより良い変換された加速度をサポートします。最初の--audio_pathパラメーターは、予測するオーディオパスを指定します。 2番目の--model_pathは、マージされたモデルパスを指定し、 openai/whisper-large-v2直接指定するなど、Whisper Original Modelの使用も直接サポートします。その他のパラメーターについては、このプログラムを確認してください。
python infer.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune--model_pathトランスモデルを指定します。その他のパラメーターについては、このプログラムを確認してください。
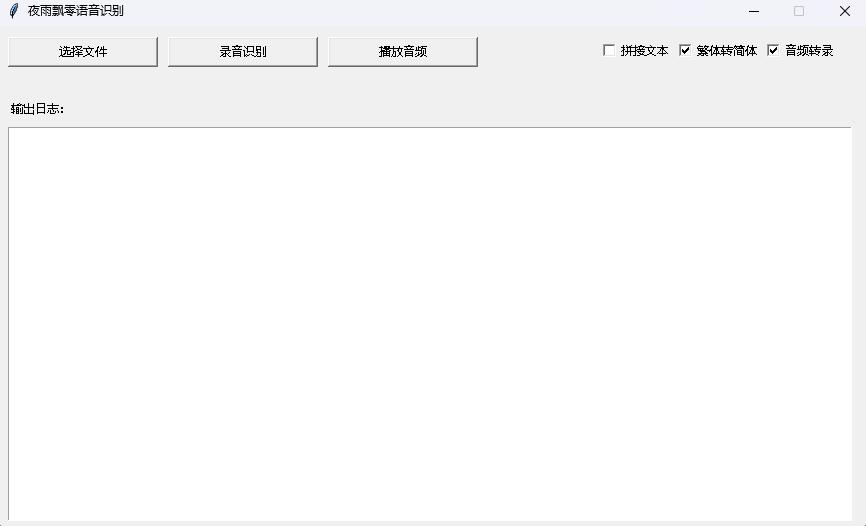
python infer_gui.py --model_path=models/whisper-tiny-finetune起動後のインターフェイスは次のとおりです。
--hostサービススタートアップのアドレスを指定します。これは0.0.0.0に設定されています。つまり、任意のアドレスにアクセスできます。 --port使用するポート番号を指定します。 --model_pathトランスモデルを指定します。 --num_workers 、同時推論に使用されるスレッドの数を指定します。これは、Web展開で重要です。複数の同時アクセスがある場合、同時に推論することが可能です。その他のパラメーターについては、このプログラムを確認してください。
python infer_server.py --host=0.0.0.0 --port=5000 --model_path=models/whisper-tiny-finetune --num_workers=2現在、識別インターフェイス/recognitionが提供されており、インターフェイスパラメーターは次のとおりです。
| フィールド | 必要ですか | タイプ | デフォルト値 | 説明します |
|---|---|---|---|---|
| オーディオ | はい | ファイル | 識別するオーディオファイル | |
| to_simple | いいえ | int | 1 | 伝統的な中国人に切り替えるかどうか |
| remove_pun | いいえ | int | 0 | 句読点を削除するかどうか |
| タスク | いいえ | 弦 | 転写産物 | タスクタイプを特定し、転写をサポートし、翻訳します |
| 言語 | いいえ | 弦 | Zh | 言語を設定し、略語を設定しない場合、言語を自動的に検出します |
返品結果:
| フィールド | タイプ | 説明します |
|---|---|---|
| 結果 | リスト | セグメンテーション識別結果 |
| +結果 | str | 各テキストの結果 |
| +開始 | int | 各スライスの開始時間、単位秒 |
| +終了 | int | 各スライスの終了時間、単位秒 |
| コード | int | エラーコード、0は成功した識別です |
例は次のとおりです。
{
"results" : [
{
"result" : "近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。 " ,
"start" : 0 ,
"end" : 8
}
],
"code" : 0
}簡単に理解するために、Webインターフェイスを呼び出すPythonコードを次に示します。以下は、 /recognitionの呼び出し方法です。
import requests
response = requests . post ( url = "http://127.0.0.1:5000/recognition" ,
files = [( "audio" , ( "test.wav" , open ( "dataset/test.wav" , 'rb' ), 'audio/wav' ))],
json = { "to_simple" : 1 , "remove_pun" : 0 , "language" : "zh" , "task" : "transcribe" }, timeout = 20 )
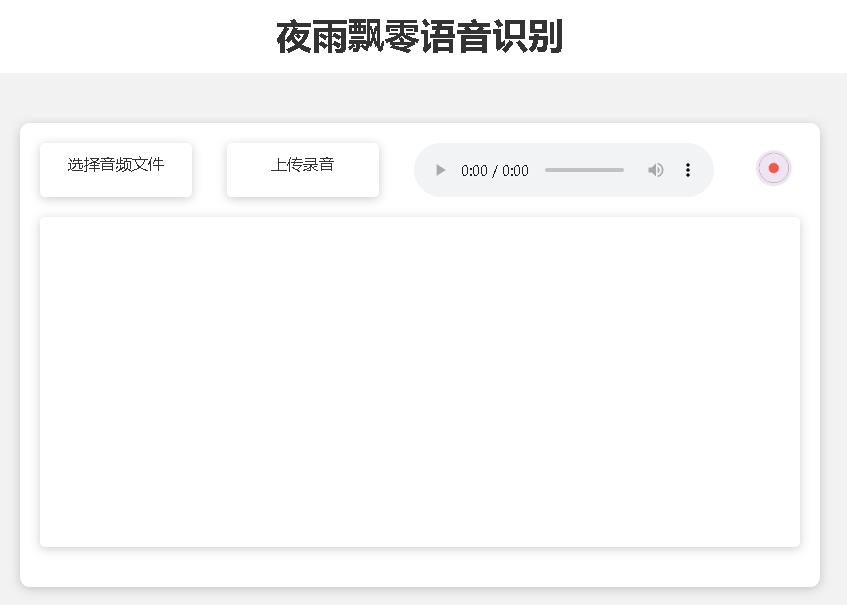
print ( response . text )提供されるテストページは次のとおりです。
ホームページのページhttp://127.0.0.1:5000/は次のとおりです。
ドキュメントページhttp://127.0.0.1:5000/docsページは次のとおりです。
Ctranslate2を加速する方法は次のとおりです。変圧器を使用するパイプラインの推論速度はすでに非常に高速ですが、最初にモデルを変換し、マージされたモデルをCtranslate2モデルに変換する必要があります。次のコマンドとして、 --modelパラメーターはマージされたモデルパスを指定し、 openai/whisper-large-v2直接指定するなど、Whisperオリジナルモデルの使用も直接サポートします。 --output_dirパラメーター変換されたCtranslate2モデルパスを指定し、 --quantizationパラメーターは量子化モデルサイズを指定します。量子化モデルが必要ない場合は、このパラメーターを直接削除できます。
ct2-transformers-converter --model models/whisper-tiny-finetune --output_dir models/whisper-tiny-finetune-ct2 --copy_files tokenizer.json preprocessor_config.json --quantization float16音声認識のために次のプログラムを実行すると、 --audio_pathパラメーターは予測されるオーディオパスを指定します。 --model_path変換されたCtranslate2モデルを指定します。その他のパラメーターについては、このプログラムを確認してください。
python infer_ct2.py --audio_path=dataset/test.wav --model_path=models/whisper-tiny-finetune-ct2出力の結果は次のとおりです。
----------- Configuration Arguments -----------
audio_path: dataset/test.wav
model_path: models/whisper-tiny-finetune-ct2
language: zh
use_gpu: True
use_int8: False
beam_size: 10
num_workers: 1
vad_filter: False
local_files_only: True
------------------------------------------------
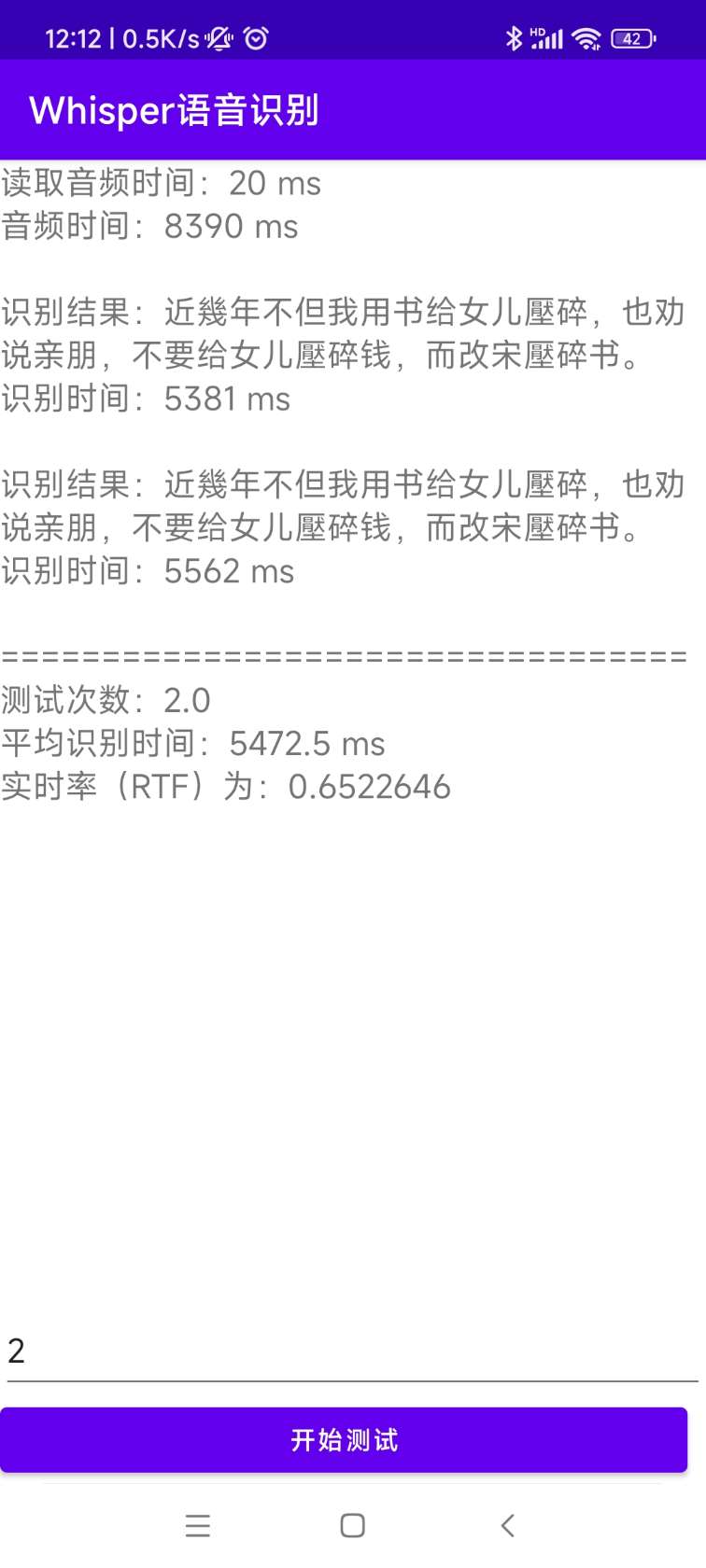
[0.0 - 8.0]:近几年,不但我用书给女儿压碎,也全说亲朋不要给女儿压碎钱,而改送压碎书。インストールと展開のソースコードは、AndroidDemoディレクトリにあります。特定のドキュメントは、このディレクトリのreadme.mdで表示できます。



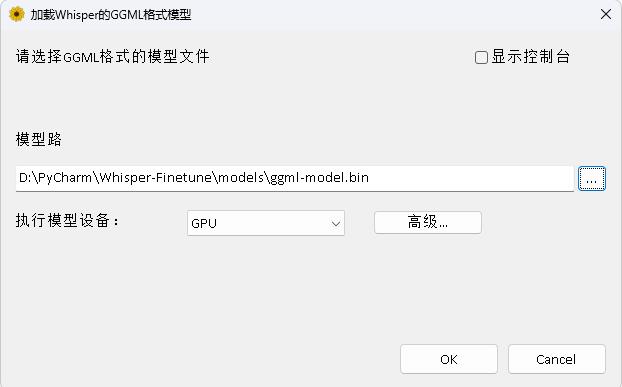
このプログラムは、whisperdesktopディレクトリにあります。特定のドキュメントは、このディレクトリのreadme.mdで表示できます。
著者をサポートするために1ドルに報いる


