text2vec
1.2.9
?? จีน | ภาษาอังกฤษ | เอกสาร/เอกสาร | รุ่น/รุ่น

Text2Vec : ข้อความถึงเวกเตอร์รับการฝังประโยค ข้อความ vectorization แสดงลักษณะข้อความ (รวมถึงคำประโยคและย่อหน้า) เป็นเมทริกซ์เวกเตอร์
Text2VEC ใช้ความหลากหลายของการแสดงข้อความและรูปแบบการคำนวณความคล้ายคลึงกันของข้อความเช่น Word2vec, RankBM25, Bert, Sentence-Bert, Cosent และเปรียบเทียบผลกระทบของแต่ละรุ่นในการจับคู่ความหมายของข้อความ (การคำนวณความคล้ายคลึงกัน)
[2023/09/20] V1.2.9 เวอร์ชัน: รองรับการอนุมานหลายการ์ด (การใช้งานหลายกระบวนการของ Multi-GPU และ Multi-CPU การอนุมาน), เครื่องมือบรรทัดคำสั่งใหม่ (CLI) ดูรายละเอียด REEASE-V1.2.9
[2023/09/03] v1.2.4 เวอร์ชัน: รองรับการฝึกอบรมรูปแบบการตั้งค่าสถานะและปล่อยโมเดลการจับคู่จีน Shibing624/text2VEC-BGE-LARGE-Chinese ซึ่งได้รับการดูแลและผ่านการฝึกอบรมโดยใช้วิธี COSENT ได้รับการฝึกฝนตาม BAAI/bge-large-zh-noinstruct และการประเมินชุดข้อมูลการจับคู่จีนได้ดีขึ้นเมื่อเทียบกับรุ่นดั้งเดิม ความแตกต่างระหว่างข้อความสั้น ๆ ดีขึ้นอย่างมีนัยสำคัญ ดูที่ REALE-V1.2.4 สำหรับรายละเอียด
[2023/07/17] v1.2.2 เวอร์ชัน: รองรับการฝึกอบรมหลายการ์ดและเปิดตัวโมเดลการจับคู่แบบหลายภาษา Shibing624/text2Vec-Base-Multilingual ซึ่งได้รับการฝึกฝนโดยใช้วิธี COSENT ขึ้นอยู่กับ sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 ได้รับการฝึกฝนโดยใช้ชุดข้อมูล STS หลายภาษาด้วยตนเอง Shibing624/NLI-ZH-all/text2Vec-base-base-multilingual-dataset และการประเมินผลในชุดทดสอบภาษาจีนและภาษาอังกฤษ ดูที่ REALE-V1.2.2 สำหรับรายละเอียด
[2023/06/19] v1.2.1 เวอร์ชัน: รุ่นการจับคู่จีน shibing624/text2vec-base-chinese-nli ได้รับการอัปเดตเป็นเวอร์ชันใหม่ของ Shibing624/text2Vec-base-chinese-sentence ขึ้นอยู่กับความไวของการคำนวณการสูญเสียของ Cosent ในการเรียงลำดับชุดข้อมูล STS คุณภาพสูงที่มีการเรียงลำดับสหสัมพันธ์ได้รับการคัดเลือกด้วยตนเองและแยกออกซึ่งได้ปรับปรุงประสิทธิภาพของชุดการประเมินแต่ละชุดเมื่อเทียบกับนั้น รูปแบบการจับคู่จีน Shibing624/text2Vec-base-chinese-paraphrase สำหรับ S2P ได้รับการปล่อยตัวดูการเปิดตัว V1.2.1 สำหรับรายละเอียด
[2023/06/15] v1.2.0 เวอร์ชัน: รุ่นการจับคู่จีน Shibing624/Text2Vec-Base-Chinese-NLI ได้รับการปล่อยตัวออกมา ขึ้นอยู่กับโมเดล nghuyong/ernie-3.0-base-zh โมเดลการจับคู่ข้อความ Cosent ที่ได้รับการฝึกฝนโดยชุดข้อมูล NLI จีน Shibing624/NLI_ZH ใช้ ประสิทธิภาพในแต่ละชุดการประเมินผลดีขึ้นอย่างมีนัยสำคัญ ดู REEASE-V1.2.0 สำหรับรายละเอียด
[2022/03/12] v1.1.4 เวอร์ชัน: รุ่นการจับคู่จีน Shibing624/text2vec-base-chinese เปิดตัวรุ่นการจับคู่ Cosent ที่ผ่านการฝึกอบรมตามชุดการฝึกอบรม STS จีน โปรดดูรายละเอียด release-v1.1.4
แนะนำ
ดูวิกิ: วิธีการแสดงเวกเตอร์ข้อความสำหรับวิธีการแสดงเวกเตอร์ข้อความโดยละเอียด
การจับคู่ข้อความ
| โค้ง | เบส | แบบอย่าง | ภาษาอังกฤษ sts-b |
|---|---|---|---|
| ถุงมือ | จาง | avg_word_embeddings_glove_6b_300d | 61.77 |
| เบิร์ต | เบิร์ตเบส | Bert-base-cls | 20.29 |
| เบิร์ต | เบิร์ตเบส | bert-base-first_last_avg | 59.04 |
| เบิร์ต | เบิร์ตเบส | bert-base-first_last_avg-whiten (nli) | 63.65 |
| เซิร์ต | ประโยค-transformers/bert-base-nli-mean-tokens | Sbert-base-nli-cls | 73.65 |
| เซิร์ต | ประโยค-transformers/bert-base-nli-mean-tokens | sbert-base-nli-first_last_avg | 77.96 |
| เกี่ยวกับความเป็นไปได้ | เบิร์ตเบส | cosent-base-first_last_avg | 69.93 |
| เกี่ยวกับความเป็นไปได้ | ประโยค-transformers/bert-base-nli-mean-tokens | cosent-base-nli-first_last_avg | 79.68 |
| เกี่ยวกับความเป็นไปได้ | ประโยค-transformers/paraphrase-multiling-minilm-L12-V2 | shibing624/text2vec-base-multilingual | 80.12 |
| โค้ง | เบส | แบบอย่าง | atec | BQ | LCQMC | pawsx | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|
| เซิร์ต | เบิร์ตเบส-จีน | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| เซิร์ต | HFL/Chinese-Macbert-base | Sbert-Macbert-base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| เซิร์ต | hfl/chinese-roberta-wwm-ext | Sbert-Roberta-ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| เกี่ยวกับความเป็นไปได้ | เบิร์ตเบส-จีน | Cosent-Bert-Base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| เกี่ยวกับความเป็นไปได้ | HFL/Chinese-Macbert-base | Cosent-Macbert-Base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| เกี่ยวกับความเป็นไปได้ | hfl/chinese-roberta-wwm-ext | cosent-roberta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
ภาพประกอบ:
SBERT-macbert-base ได้รับการฝึกฝนโดยใช้วิธี Sbert และเรียกใช้ตัวอย่าง/Training_Sup_Text_Matching_Model.py รหัสเพื่อฝึกอบรมโมเดลsentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 แบบจำลองได้รับการฝึกฝนด้วย SBERT และเป็นรุ่นที่พูดถึง paraphrase-MiniLM-L12-v2 รุ่นหลายภาษาสนับสนุนภาษาจีนอังกฤษ ฯลฯ ฯลฯ| โค้ง | เบส | แบบอย่าง | atec | BQ | LCQMC | pawsx | STS-B | SOHU-DD | SOHU-DC | AVG | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2Vec | Word2Vec | W2V-light-tencent-chinese | 20.00 น | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| เซิร์ต | XLM-Roberta-base | ประโยค-transformers/paraphrase-multiling-minilm-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| เกี่ยวกับความเป็นไปได้ | HFL/Chinese-Macbert-base | shibing624/text2vec-base-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| เกี่ยวกับความเป็นไปได้ | HFL/Lert-Large | Ganymedenil/text2vec-large-chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| เกี่ยวกับความเป็นไปได้ | Nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-base-chinese-sentence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| เกี่ยวกับความเป็นไปได้ | Nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| เกี่ยวกับความเป็นไปได้ | ประโยค-transformers/paraphrase-multiling-minilm-L12-V2 | shibing624/text2vec-base-multilingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| เกี่ยวกับความเป็นไปได้ | Baai/bge-large-zh-noinstruct | shibing624/text2vec-bge-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
ภาพประกอบ:
shibing624/text2vec-base-chinese ได้รับการฝึกฝนโดยใช้วิธี COSENT ซึ่งได้รับการฝึกฝนในข้อมูล STS-B ของจีนโดยใช้ hfl/chinese-macbert-base และประเมินผลในการทดสอบ STS-B ของจีนเพื่อให้ได้ผลลัพธ์ที่ดี เรียกใช้ตัวอย่าง/training_sup_text_matching_model.py รหัสเพื่อฝึกอบรมโมเดล ไฟล์รุ่นได้รับการอัปโหลดไปยัง HF Model Hub ขอแนะนำให้ใช้งานการจับคู่ความหมายทั่วไปของจีนshibing624/text2vec-base-chinese-sentence ได้รับการฝึกฝนโดยใช้วิธี Cosent ได้รับการฝึกฝนตามชุดข้อมูล STS ของจีนที่เลือกด้วยตนเอง Shibing624/NLI-ZH-ALL/TEXT2VEC- nghuyong/ernie-3.0-base-zh -CHINESE-SENTENTENT-DATASET และได้รับการประเมินในชุดทดสอบ NLI จีนต่างๆเพื่อให้ได้ผลลัพธ์ที่ดี รันตัวอย่าง/training_sup_text_matching_model_jsonl_data.py รหัสเพื่อฝึกอบรมรุ่น ไฟล์รุ่นได้รับการอัปโหลดไปยัง HF Model Hub แนะนำให้ใช้งานการจับคู่ความหมาย S2S ของจีน (ประโยคกับประโยค)shibing624/text2vec-base-chinese-paraphrase ได้รับการฝึกฝนโดยใช้วิธี Cosent ขึ้นอยู่กับชุดข้อมูล STS ของจีนที่เลือกโดย nghuyong/ernie-3.0-base-zh ด้วยตนเอง, Shibing624/Nli-ZH-all/text2vec-base-chinese-paraphrase-dataset, ชุดข้อมูลทั้งหมดใน S2P การถอดความ) ข้อมูลเสริมสร้างความสามารถในการแสดงข้อความที่ยาวนานและประเมินผลเพื่อให้บรรลุ SOTA ในชุดทดสอบ NLI จีนต่างๆ รันตัวอย่าง/การฝึกอบรม _sup_text_matching_model_jsonl_data.py รหัสเพื่อฝึกอบรมรุ่น ไฟล์รุ่นได้รับการอัปโหลดไปยัง HF Model Hub แนะนำให้ใช้งานการจับคู่ความหมาย S2P ของจีน (ประโยคเทียบกับวรรค)shibing624/text2vec-base-multilingual ได้รับการฝึกฝนโดยใช้วิธี COSENT ได้รับการฝึกฝนขึ้นอยู่กับ sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 โดยใช้ชุดข้อมูล STS หลายภาษาที่เลือกด้วยตนเอง Shibing624/NLI-ZH-all/text2Vec-base-multilingual-Dataset ได้รับการประเมินในชุดทดสอบภาษาจีนและภาษาอังกฤษและเอฟเฟกต์ได้รับการปรับปรุงเมื่อเทียบกับโมเดลดั้งเดิม รันตัวอย่าง/training_sup_text_matching_model_jsonl_data.py รหัสเพื่อฝึกอบรมรุ่น ไฟล์รุ่นได้รับการอัปโหลดไปยัง HF Model Hub ขอแนะนำให้ใช้งานการจับคู่ความหมายหลายภาษาshibing624/text2vec-bge-large-chinese ได้รับการฝึกฝนโดยใช้วิธี Cosent ได้รับการฝึกฝนตาม BAAI/bge-large-zh-noinstruct โดยใช้ชุดข้อมูล STS ของจีนที่เลือกด้วยตนเอง Shibing624/NLI-ZH-all/text2Vec-base-chinese-paraphrase-dataset การประเมินผลในชุดทดสอบจีนได้ปรับปรุงผลกระทบเมื่อเทียบกับโมเดลดั้งเดิมและความแตกต่างของข้อความสั้น ๆ นั้นดีขึ้นอย่างมีนัยสำคัญ รันตัวอย่าง/training_sup_text_matching_model_jsonl_data.py รหัสเพื่อฝึกอบรมรุ่น ไฟล์รุ่นได้รับการอัปโหลดไปยัง HF Model Hub แนะนำให้ใช้งานการจับคู่ความหมาย S2S ของจีน (ประโยคกับประโยค)w2v-light-tencent-chinese--model_name hfl/chinese-macbert-base หรือ Roberta รุ่น: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG และ EncoderType.MEAN และผลการทำนายของทั้งสองมีขนาดเล็กมากexamples/data และเรียกใช้การทดสอบ/model_spearman.py รหัสเพื่อทำซ้ำผลลัพธ์การประเมินรายงานการฝึกอบรมแบบจำลองการทดลอง: รายงานการทดลอง
ตัวอย่างอย่างเป็นทางการ: https://www.mulanai.com/product/short_text_sim/
การสาธิต HuggingFace: https://huggingface.co/spaces/shibing624/text2vec

รันตัวอย่าง: ตัวอย่าง/gradio_demo.py เพื่อดูการสาธิต:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecหรือ
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . คำนวณเวกเตอร์ข้อความตาม pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)ตัวอย่าง: ตัวอย่าง/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )เอาท์พุท:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings ค่าส่งคืนคือ type numpy.ndarray , รูปร่างคือ (sentences_size, model_embedding_size) และคุณสามารถเลือกรุ่นใดก็ได้ในสามรุ่น แนะนำคนแรกshibing624/text2vec-base-chinese ได้รับจากการฝึกอบรมวิธี COSENT ในชุดข้อมูล STS-B ของจีน โมเดลได้รับการอัปโหลดไปยังห้องสมุดโมเดลของ HuggingFace Shibing624/Text2Vec-Base-Chinese เป็นรุ่นเริ่มต้นที่ระบุโดย text2vec.SentenceModel มันสามารถเรียกผ่านตัวอย่างข้างต้นหรือสามารถเรียกได้ด้วยไลบรารี Transformers ดังที่แสดงด้านล่าง รุ่นจะถูกดาวน์โหลดโดยอัตโนมัติไปยังเส้นทางดั้งเดิม: ~/.cache/huggingface/transformersw2v-light-tencent-chinese เป็นรุ่น Word2vec ที่โหลดผ่าน Gensim คำว่าเวกเตอร์ของแต่ละคำคำนวณโดยใช้ tencent word vector Tencent_AILab_ChineseEmbedding.tar.gz เวกเตอร์ประโยคเฉลี่ยผ่านคำว่าเวกเตอร์คำ โมเดลจะถูกดาวน์โหลดโดยอัตโนมัติไปยังเส้นทางดั้งเดิม: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec รองรับการอนุมานหลายการ์ด (คำนวณเวกเตอร์ข้อความ): ตัวอย่าง/computing_embeddings_multi_gpu_demo.py หากไม่มี text2vec คุณสามารถใช้โมเดลเช่นนี้:
ก่อนอื่นคุณจะส่งผ่านอินพุตของคุณผ่านโมเดลหม้อแปลงจากนั้นคุณต้องใช้การรวมการรวมที่เหมาะสมของคำที่ฝังบริบท
ตัวอย่าง: ตัวอย่าง/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )SESTENCE-TRANSFORMERS เป็นห้องสมุดยอดนิยมในการคำนวณการเป็นตัวแทนเวกเตอร์หนาแน่นสำหรับประโยค
ติดตั้ง SENTENCE-TRANSFORMERS:
pip install -U sentence-transformersจากนั้นโหลดโมเดลและทำนาย:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec word vector ระบุเวกเตอร์ Word2Vec สองคำเลือกหนึ่งตัวเลือก:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin รุ่นดั้งเดิม) เรียกใช้โปรแกรมและดาวน์โหลดโดยอัตโนมัติ~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , tencent word home หน้าแรก: https://ai.tencent.com/ailab/nlp/zh/index.html คำดาวน์โหลด https://ai.tencent.com/ailab/nlp/en/download.html ดูเพิ่มเติม Tencent word vector บทนำ wikiรองรับการได้มาซึ่งแบทช์ของเวกเตอร์ข้อความ
รหัส: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
วิ่ง:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu Trueไฟล์อินพุต (จำเป็น):
input.txt, รูปแบบ: ข้อความประโยคหนึ่งประโยคหนึ่งบรรทัด
ตัวอย่าง: ตัวอย่าง/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))เอาท์พุท:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591ช่วง
scoreของค่าความคล้ายคลึงกันของโคไซน์ประโยคคือ [-1, 1] และค่าที่ใหญ่กว่านั้นยิ่งมีความคล้ายคลึงกันมากขึ้นเท่านั้น
โดยทั่วไปข้อความที่คล้ายกับการสืบค้นมากที่สุดพบได้ในชุดผู้สมัครเอกสารและมักจะใช้สำหรับงานเช่นการจับคู่ความคล้ายคลึงกันของคำถามและการดึงข้อความที่คล้ายคลึงกันในสถานการณ์ QA
ตัวอย่าง: ตัวอย่าง/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))เอาท์พุท:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)ห้องสมุดที่คล้ายคลึงกัน [แนะนำ]
สำหรับการคำนวณความคล้ายคลึงกันของข้อความและงานค้นหาการจับคู่ข้อความขอแนะนำให้ใช้ไลบรารีความคล้ายคลึงกันซึ่งเข้ากันได้กับ Word2vec, Sbert และโมเดลการจับคู่แบบความหมายแบบ cosent-like ในโครงการนี้ นอกจากนี้ยังรองรับการค้นหากราฟิกระดับ 100 ล้านระดับและรองรับ การซ้ำซ้อนของข้อความความหมาย การซ้ำซ้อน การขจัดข้อมูลซ้ำซ้อน และฟังก์ชั่นอื่น ๆ
การติดตั้ง: pip install -U similarities
การคำนวณความคล้ายคลึงกันของประโยค:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 โมเดลการจับคู่ข้อความ Cosent (Cosine Sentence) ปรับปรุงโครงการเวกเตอร์ประโยค Cosinerankloss 'ในประโยค-เบิร์ต
โครงสร้างเครือข่าย:
การฝึกอบรม:
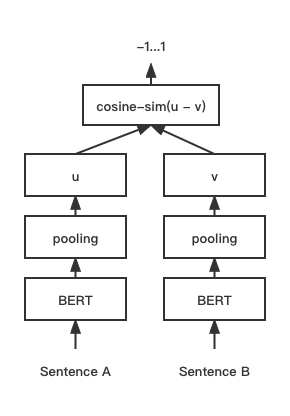
การอนุมาน:
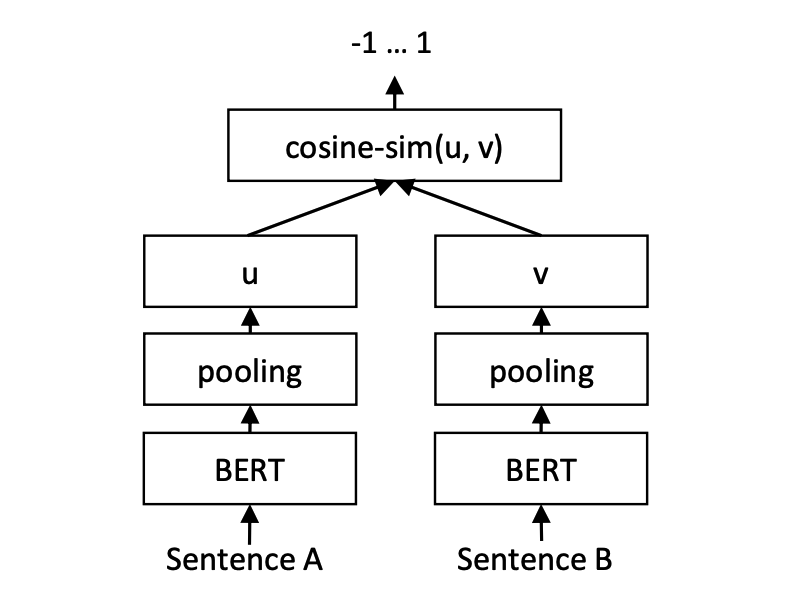
การฝึกอบรมและการทำนายของแบบจำลอง Cosent:
CoSENT ในชุดข้อมูล STS-B ของจีนตัวอย่าง: ตัวอย่าง/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT ในชุดข้อมูลการจับคู่ทางการเงินของ ATECสนับสนุนการใช้ชุดข้อมูลการจับคู่ภาษาจีนเหล่านี้: 'ATEC', 'STS-B', 'BQ', 'LCQMC', 'PAWSX' สำหรับรายละเอียดโปรดดูชุดข้อมูล HUGGGEDFACE
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentตัวอย่าง: ตัวอย่าง/training_sup_text_matching_model_mydata.py
การฝึกการ์ดใบเดียว:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictการฝึกอบรม Doka:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel ตัวอย่างอ้างอิง/ข้อมูล/sts-b/sts-b.valid.data สำหรับรูปแบบชุดการฝึกอบรม
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label สามารถเป็นป้ายกำกับ 0 และ 1 และ 0 หมายความว่าทั้งสองประโยคไม่คล้ายกันและ 1 หมายถึงคล้ายกัน; นอกจากนี้ยังสามารถเป็นคะแนน 0-5 ยิ่งคะแนนสูงเท่าไหร่ทั้งสองประโยคก็ยิ่งคล้ายกันมากขึ้นเท่านั้น ทุกรุ่นสามารถรองรับได้
CoSENT ในชุดข้อมูล STS-B ภาษาอังกฤษตัวอย่าง: ตัวอย่าง/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT ในชุดข้อมูล NLI ภาษาอังกฤษและการประเมินผลกระทบในชุดทดสอบ STS-Bตัวอย่าง: ตัวอย่าง/การฝึกอบรม _unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentรูปแบบการจับคู่ข้อความประโยค-เบิร์ตโครงการตัวแทนการเป็นตัวแทนของการเป็นตัวแทนเวกเตอร์
โครงสร้างเครือข่าย:
การฝึกอบรม:
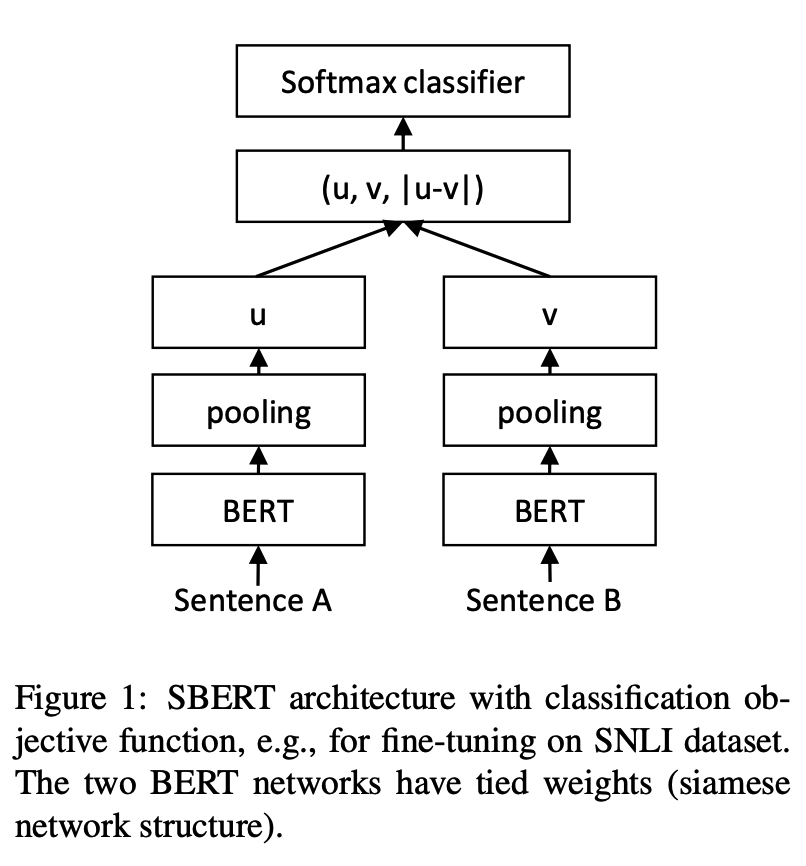
การอนุมาน:
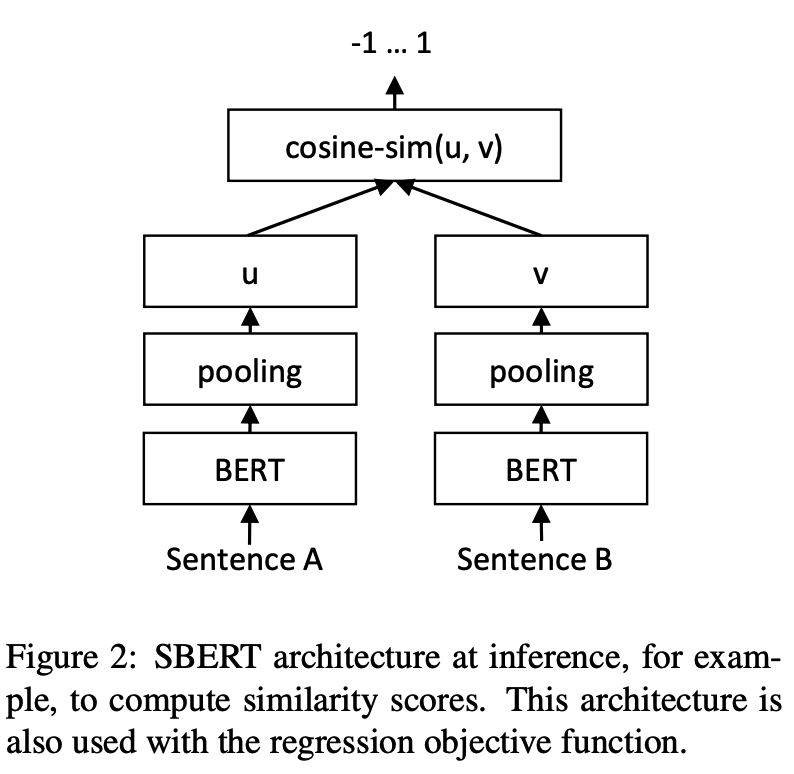
SBERT ในชุดข้อมูล STS-B จีนตัวอย่าง: ตัวอย่าง/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT ในชุดข้อมูล STS-B ภาษาอังกฤษตัวอย่าง: ตัวอย่าง/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT Model ในชุดข้อมูล NLI ภาษาอังกฤษและการประเมินผลกระทบในชุดทดสอบ STS-Bตัวอย่าง: ตัวอย่าง/การฝึกอบรม _unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertโมเดลการจับคู่ข้อความ Bert, โครงสร้างเครือข่ายการจับคู่เบิร์ตดั้งเดิม, โมเดลการจับคู่เวกเตอร์แบบโต้ตอบ
โครงสร้างเครือข่าย:
การฝึกอบรมและการอนุมาน:
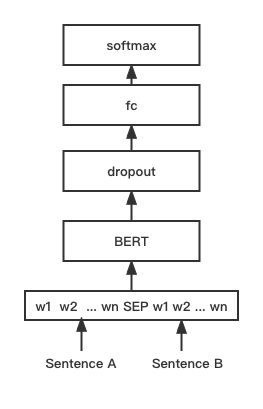
สคริปต์การฝึกอบรมเหมือนกับตัวอย่างข้างต้น/การฝึกอบรม _sup_text_matching_model.py
BGE ในชุดข้อมูล STS-B ของจีนตัวอย่าง: ตัวอย่าง/training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16การฝึกอบรมการปรับจูนแบบจำลอง BGE โดยใช้การเรียนรู้ความคมชัดเพื่อฝึกอบรมแบบจำลองรูปแบบของข้อมูลอินพุตคือสาม '(แบบสอบถามบวกลบ)'
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py สร้างชุดฝึกอบรมสามชุดตาม STS-B จีนโดยมีรูปแบบดังนี้: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py ใช้การจับคู่ที่คล้ายกันของ faiss ทำให้การขุดยากต่อตัวอย่างเชิงลบเนื่องจากโมเดลที่ผ่านการฝึกอบรม Text2Vec สามารถโหลดได้โดยใช้ไลบรารีการแปลงประโยควิธีการกลั่นแบบจำลองของมันจึงมีมัลติเพล็กซ์ที่นี่
จัดเตรียมรูปแบบการปรับใช้สองแบบและวิธีการในการสร้างบริการ: 1) สร้างบริการ GRPC ตาม Jina [แนะนำ]; 2) สร้างบริการ HTTP ดั้งเดิมตาม fastapi
มันใช้โหมด C/S เพื่อสร้างบริการประสิทธิภาพสูงรองรับ Docker Cloud Native, GRPC/HTTP/WebSocket รองรับการทำนายพร้อมกันของหลายรุ่นและการประมวลผลหลายการ์ด GPU
ติดตั้ง: pip install jina
เริ่มบริการ:
ตัวอย่าง: ตัวอย่าง/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()วิธีการทำนายแบบจำลอง (ผู้ดำเนินการ) ได้รับการอัปโหลดไปยัง Jinahub รวมถึงวิธีการปรับใช้ Docker และ K8S
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )ดูตัวอย่าง: ตัวอย่าง/jina_client_demo.py สำหรับวิธีการเรียกแบทช์
ติดตั้ง: pip install fastapi uvicorn
เริ่มบริการ:
ตัวอย่าง: ตัวอย่าง/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | ชุดข้อมูล | การแนะนำ | ลิงค์ดาวน์โหลด |
|---|---|---|
| Shibing624/nli-zh-all | การรวบรวมข้อมูลการจับคู่ความหมายของจีนการรวมข้อมูลคุณภาพสูง 8.2 ล้านรายการสำหรับงานต่าง ๆ เช่นการใช้เหตุผลข้อความความคล้ายคลึงกันสรุปคำถามและคำตอบการปรับแต่งการเรียนการสอนและแปลงเป็นชุดข้อมูลรูปแบบการจับคู่ | https://huggingface.co/datasets/shibing624/nli-zh-all |
| shibing624/snli-zh | ชุดข้อมูล SNLI ของจีนและ MultinLI แปลจากภาษาอังกฤษ SNLI และ Multinli | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624/nli_zh | ชุดข้อมูลการจับคู่ความหมายของจีนการรวมชุดข้อมูล 5 งานรวมถึง ATEC, BQ, LCQMC, PAWSX และ STS-B | https://huggingface.co/datasets/shibing624/nli_zh หรือ Baidu NetDisk (รหัสการสกัด: QKT6) หรือ คนอื่น ๆ |
| Shibing624/STS-SOHU2021 | ชุดข้อมูลการจับคู่ความหมายของจีน, 2021 SOHU Campus Text Text การจับคู่อัลกอริทึมชุดข้อมูลการแข่งขันอัลกอริทึม | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| atec | ชุดข้อมูล ATEC ของจีนชุดข้อมูล q-qpair Ant Financial | atec |
| BQ | ชุดข้อมูล BQ Chinese BQ (คำถามธนาคาร) ชุดข้อมูล Q-qpair ของธนาคาร | BQ |
| LCQMC | LCQMC จีน (ชุดข้อมูลการจับคู่คำถามจีนขนาดใหญ่) ชุดข้อมูลชุดข้อมูล Q-QPAIR | LCQMC |
| pawsx | Paws จีน (ฝ่ายตรงข้ามถอดความจาก Word Scrambling) ชุดข้อมูลชุดข้อมูล Q-qpair | pawsx |
| STS-B | ชุดข้อมูล STS-B ภาษาจีนชุดข้อมูลการอนุมานภาษาธรรมชาติจีนชุดข้อมูลที่แปลจากภาษาอังกฤษ STS-B เป็นภาษาจีน | STS-B |
ชุดข้อมูลการจับคู่ภาษาอังกฤษที่ใช้กันทั่วไป:
ตัวอย่างการใช้ชุดข้อมูล:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])เอาท์พุท:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
หากคุณใช้ Text2VEC ในการวิจัยของคุณโปรดอ้างอิงในรูปแบบต่อไปนี้:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecbibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}ข้อตกลงใบอนุญาตคือ Apache License 2.0 ซึ่งสามารถใช้เพื่อวัตถุประสงค์ทางการค้าได้ฟรี โปรดแนบลิงค์และข้อตกลงการอนุญาตของ Text2VEC กับคำอธิบายผลิตภัณฑ์
รหัสโครงการยังคงหยาบมาก หากคุณปรับปรุงรหัสแล้วคุณสามารถส่งกลับไปยังโครงการนี้ได้ ก่อนส่งให้ให้ความสนใจกับสองประเด็นต่อไปนี้:
testspython -m pytest -v เพื่อเรียกใช้การทดสอบหน่วยทั้งหมดตรวจสอบให้แน่ใจว่าผ่านการทดสอบเดี่ยวทั้งหมดคุณสามารถส่ง PR ของคุณได้ในภายหลัง


