text2vec
1.2.9
??Chinese | English | Documents/Docs | ?Models/Models

Text2vec : Text to Vector, Get Sentence Embeddings. Text vectorization, characterizes text (including words, sentences, and paragraphs) as a vector matrix.
text2vec implements a variety of text representation and text similarity calculation models such as Word2Vec, RankBM25, BERT, Sentence-BERT, CoSENT, and compares the effects of each model on the text semantic matching (similarity calculation) task.
[2023/09/20] v1.2.9 version: Supports multi-card inference (multi-process implementation of multi-GPU and multi-CPU inference), a new command line tool (CLI) is added, which can scripts perform batch text vectorization. See Release-v1.2.9 for details.
[2023/09/03] v1.2.4 version: Supports FlagEmbedding model training, and released the Chinese matching model shibing624/text2vec-bge-large-chinese, which is supervised and trained using the CoSENT method. It is trained based on BAAI/bge-large-zh-noinstruct , and the Chinese matching data set evaluation has improved compared with the original model. The difference between short text is significantly improved. See Release-v1.2.4 for details.
[2023/07/17] v1.2.2 version: Supports multi-card training, and released the multi-language matching model shibing624/text2vec-base-multilingual, which is trained using the CoSENT method. Based on sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 it is trained using manual multi-language STS dataset shibing624/nli-zh-all/text2vec-base-multilingual-dataset, and the evaluation in the Chinese and English test set has improved the effect compared to the original model. See Release-v1.2.2 for details.
[2023/06/19] v1.2.1 version: The Chinese matching model shibing624/text2vec-base-chinese-nli is updated as the new version of shibing624/text2vec-base-chinese-sentence. Based on the sensitivity of CoSENT's loss calculation to sorting, the high-quality STS dataset with correlation sorting was manually selected and sorted out, which has improved the performance of each evaluation set compared with that; the Chinese matching model shibing624/text2vec-base-chinese-paraphrase for s2p was released, see Release-v1.2.1 for details.
[2023/06/15] v1.2.0 version: The Chinese matching model shibing624/text2vec-base-chinese-nli was released. Based on nghuyong/ernie-3.0-base-zh model, the CoSENT text matching model trained by the Chinese NLI data set shibing624/nli_zh is used. The performance in each evaluation set is significantly improved. See Release-v1.2.0 for details.
[2022/03/12] v1.1.4 version: The Chinese matching model shibing624/text2vec-base-chinese is released, a CoSENT matching model trained based on the Chinese STS training set. See Release-v1.1.4 for details
Guide
See wiki: Text vector representation method for detailed text vector representation method
Text Matching
| Arch | BaseModel | Model | English-STS-B |
|---|---|---|---|
| GloVe | gleve | Avg_word_embeddings_glove_6B_300d | 61.77 |
| BERT | bert-base-uncased | BERT-base-cls | 20.29 |
| BERT | bert-base-uncased | BERT-base-first_last_avg | 59.04 |
| BERT | bert-base-uncased | BERT-base-first_last_avg-whiten(NLI) | 63.65 |
| SBERT | sentence-transformers/bert-base-nli-mean-tokens | SBERT-base-nli-cls | 73.65 |
| SBERT | sentence-transformers/bert-base-nli-mean-tokens | SBERT-base-nli-first_last_avg | 77.96 |
| CoSENT | bert-base-uncased | CoSENT-base-first_last_avg | 69.93 |
| CoSENT | sentence-transformers/bert-base-nli-mean-tokens | CoSENT-base-nli-first_last_avg | 79.68 |
| CoSENT | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | shibing624/text2vec-base-multilingual | 80.12 |
| Arch | BaseModel | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|
| SBERT | bert-base-chinese | SBERT-bert-base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| SBERT | hfl/chinese-macbert-base | SBERT-macbert-base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| SBERT | hfl/chinese-roberta-wwm-ext | SBERT-roberta-ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| CoSENT | bert-base-chinese | CoSENT-bert-base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| CoSENT | hfl/chinese-macbert-base | CoSENT-macbert-base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| CoSENT | hfl/chinese-roberta-wwm-ext | CoSENT-roberta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
illustrate:
SBERT-macbert-base model is trained using SBert method, and run examples/training_sup_text_matching_model.py code to train the model.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 model is trained with SBert, and is a multilingual version of paraphrase-MiniLM-L12-v2 model, supporting Chinese, English, etc.| Arch | BaseModel | Model | ATEC | BQ | LCQMC | PAWSX | STS-B | SOHU-dd | SOHU-dc | Avg | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2Vec | word2vec | w2v-light-tencent-chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| SBERT | xlm-roberta-base | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| CoSENT | hfl/chinese-macbert-base | shibing624/text2vec-base-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| CoSENT | hfl/chinese-lert-large | GanymedeNil/text2vec-large-chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| CoSENT | nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-sentence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| CoSENT | nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| CoSENT | sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | shibing624/text2vec-base-multilingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| CoSENT | BAAI/bge-large-zh-noinstruct | shibing624/text2vec-bge-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
illustrate:
shibing624/text2vec-base-chinese model is trained using the CoSENT method, trained in Chinese STS-B data based on hfl/chinese-macbert-base , and evaluated in Chinese STS-B test set to achieve good results. Run the examples/training_sup_text_matching_model.py code to train the model. The model file has been uploaded to HF model hub. It is recommended to use the Chinese general semantic matching task.shibing624/text2vec-base-chinese-sentence model is trained using the CoSENT method. It is trained based on the manually selected Chinese STS dataset shibing624/nli-zh-all/text2vec- nghuyong/ernie-3.0-base-zh -chinese-sentence-dataset, and is evaluated in various Chinese NLI test sets to achieve good results. Run the examples/training_sup_text_matching_model_jsonl_data.py code to train the model. The model file has been uploaded to HF model hub. The Chinese s2s (sentence vs sentence) semantic matching task is recommended to useshibing624/text2vec-base-chinese-paraphrase model is trained using the CoSENT method. Based on the Chinese STS dataset selected by nghuyong/ernie-3.0-base-zh manually, shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset, the dataset is added to s2p (sentence to) relative to shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset. Paraphrase) data strengthens its long text representation ability, and evaluates to achieve SOTA in various Chinese NLI test sets. Run examples/training_sup_text_matching_model_jsonl_data.py code to train the model. The model file has been uploaded to HF model hub. Chinese s2p (sentence vs paragraph) semantic matching task is recommended.shibing624/text2vec-base-multilingual model is trained using the CoSENT method. It is trained based on sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 using the manually selected multilingual STS dataset shibing624/nli-zh-all/text2vec-base-multilingual-dataset. It is evaluated in the Chinese and English test set, and the effect is improved compared to the original model. Run the examples/training_sup_text_matching_model_jsonl_data.py code to train the model. The model file has been uploaded to HF model hub. It is recommended to use the multilingual semantic matching task.shibing624/text2vec-bge-large-chinese model is trained using CoSENT method. It is trained based on BAAI/bge-large-zh-noinstruct using the manually selected Chinese STS dataset shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset. The evaluation in the Chinese test set has improved the effect compared to the original model, and the difference in short text is significantly improved. Run the examples/training_sup_text_matching_model_jsonl_data.py code to train the model. The model file has been uploaded to HF model hub. The Chinese s2s (sentence vs sentence) semantic matching task is recommended to usew2v-light-tencent-chinese is a Word2Vec model of Tencent word vectors, used by CPU loading, suitable for Chinese literal matching tasks and cold start situations of missing data--model_name hfl/chinese-macbert-base or roberta model: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG and EncoderType.MEAN , and the prediction effects of the two are very small.examples/data and run the tests/model_spearman.py code to reproduce the evaluation results.Model training experimental report: experimental report
Official Demo: https://www.mulanai.com/product/short_text_sim/
HuggingFace Demo: https://huggingface.co/spaces/shibing624/text2vec

run example: examples/gradio_demo.py to see the demo:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecor
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Compute text vectors based on pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)example: examples/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )output:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings is type numpy.ndarray , shape is (sentences_size, model_embedding_size) , and you can choose any of the three models. The first one is recommended.shibing624/text2vec-base-chinese model is obtained by the CoSENT method training in the Chinese STS-B dataset. The model has been uploaded to the model library of huggingface shibing624/text2vec-base-chinese. It is the default model specified by text2vec.SentenceModel . It can be called through the above example, or it can be called with the transformers library as shown below. The model will be automatically downloaded to the native path: ~/.cache/huggingface/transformersw2v-light-tencent-chinese is a Word2Vec model loaded through gensim. The word vectors of each word are calculated using the Tencent word vector Tencent_AILab_ChineseEmbedding.tar.gz The sentence vector is averaged through the word word vector. The model is automatically downloaded to the native path: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec supports multi-card inference (calculate text vector): examples/computing_embeddings_multi_gpu_demo.py Without text2vec, you can use the model like this:
First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
example: examples/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )sentence-transformers is a popular library to compute dense vector representations for sentences.
Install sentence-transformers:
pip install -U sentence-transformersThen load model and predict:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec word vector Provide two Word2Vec word vectors, optionally one:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , Tencent Word Vector Home Page: https://ai.tencent.com/ailab/nlp/zh/index.html Word Vector Download Address: https://ai.tencent.com/ailab/nlp/en/download.html More View Tencent Word Vector Introduction-wikiSupport batch acquisition of text vectors
code: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
run:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueInput file (required):
input.txt, format: sentence text of one sentence, one line.
example: examples/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))output:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591The
scorerange of the sentence cosine similarity value is [-1, 1], and the larger the value, the more similar it is.
Generally, text that is most similar to query is found in the document candidate set, and is often used for tasks such as question similarity matching and text similarity retrieval in QA scenarios.
example: examples/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))output:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Similarities library [recommended]
For text similarity calculation and text matching search tasks, it is recommended to use the similarities library, which is compatible with the Word2vec, SBERT, and Cosent-like semantic matching models of release in this project. It also supports 100 million-level graphic searches, and supports text semantic deduplication , image deduplication and other functions.
Installation: pip install -U similarities
Sentence similarity calculation:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 CoSENT (Cosine Sentence) text matching model, improves CosineRankLoss' sentence vector scheme on Sentence-BERT
Network structure:
Training:
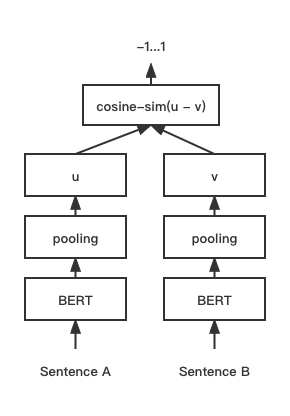
Inference:
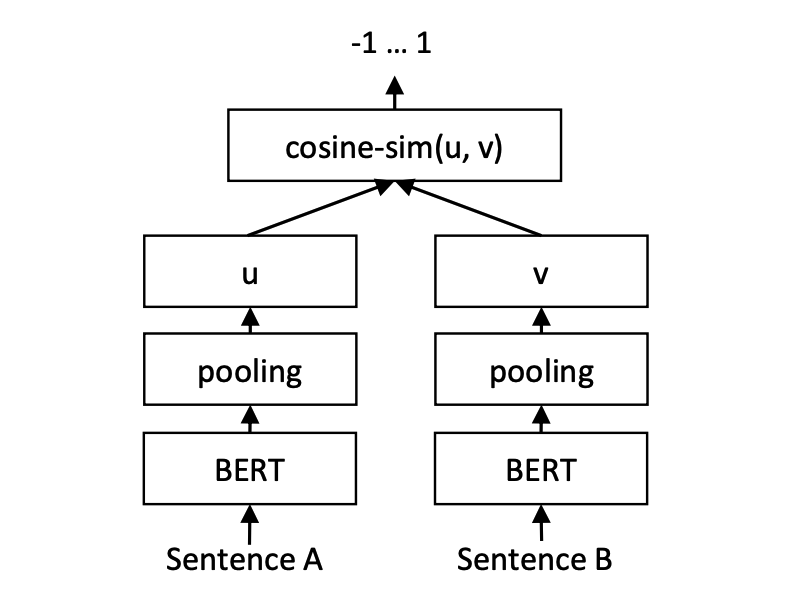
Training and prediction of CoSENT models:
CoSENT models on Chinese STS-B datasetexample: examples/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT models on Ant Financial Matching Dataset ATECSupport the use of these Chinese matching datasets: 'ATEC', 'STS-B', 'BQ', 'LCQMC', 'PAWSX', for details, please refer to HuggingFace datasets https://huggingface.co/datasets/shibing624/nli_zh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentexample: examples/training_sup_text_matching_model_mydata.py
Single card training:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictDoka training:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Reference examples/data/STS-B/STS-B.valid.data for training set format
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label can be labels 0 and 1, and 0 means that the two sentences are not similar, and 1 means similar; it can also be a score of 0-5. The higher the score, the more similar the two sentences are. All models can be supported.
CoSENT models on English STS-B datasetexample: examples/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT model in English NLI dataset and evaluating effect in STS-B test setexample: examples/training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentSentence-BERT text matching model, representational sentence vector representation scheme
Network structure:
Training:
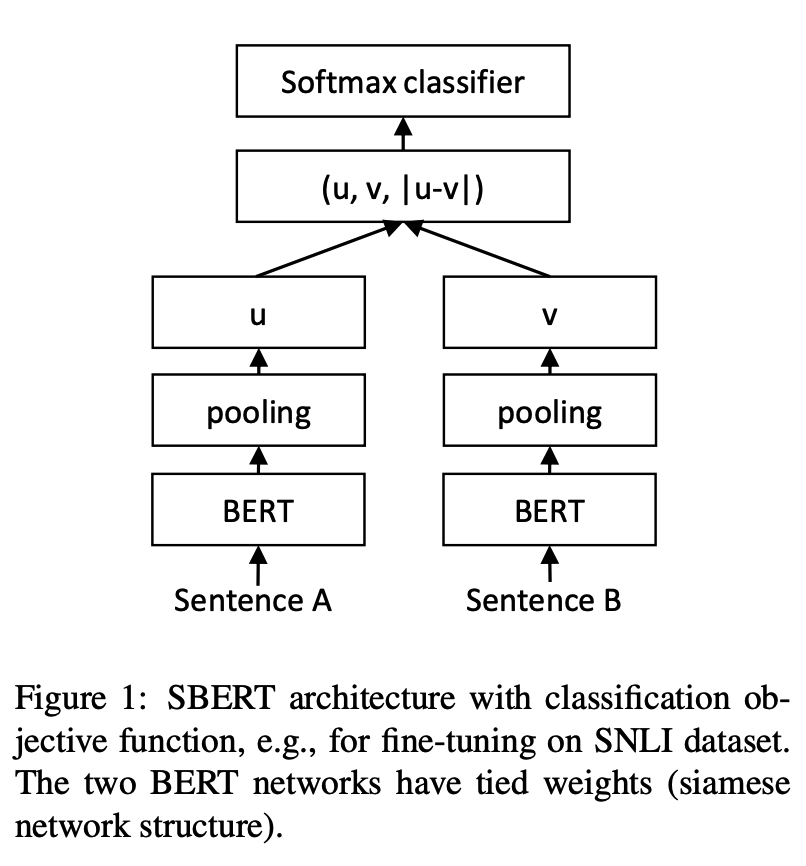
Inference:
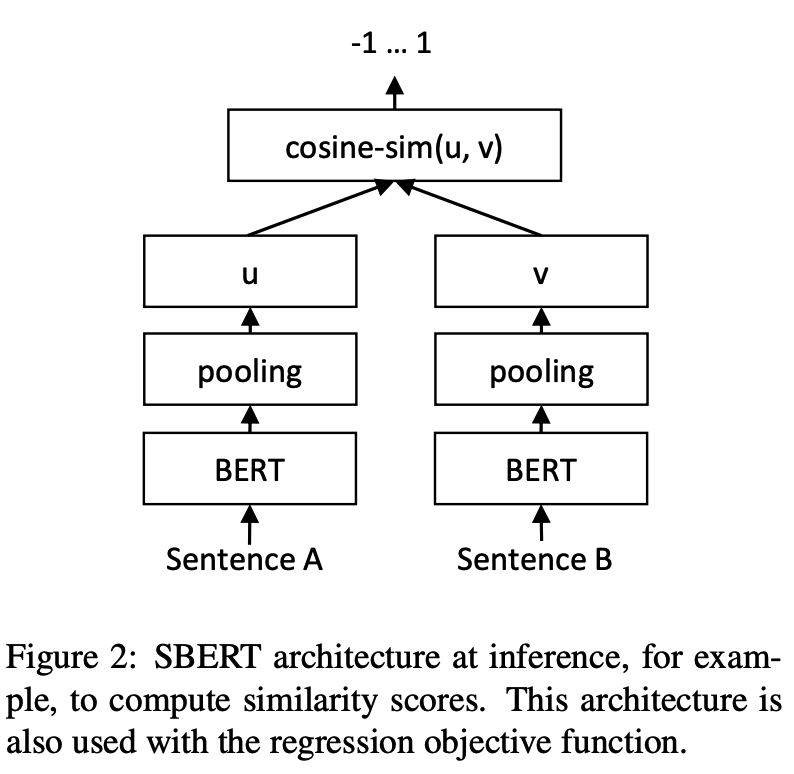
SBERT models on Chinese STS-B datasetexample: examples/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT models on English STS-B datasetexample: examples/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT model in English NLI dataset and evaluating effect in STS-B test setexample: examples/training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertBERT text matching model, native BERT matching network structure, interactive sentence vector matching model
Network structure:
Training and inference:
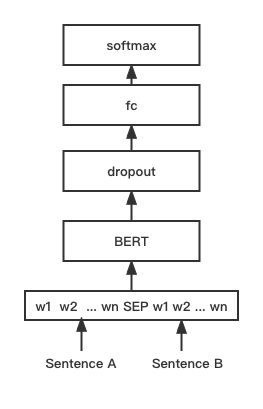
The training script is the same as above examples/training_sup_text_matching_model.py.
BGE models on Chinese STS-B datasetexample: examples/training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGE model fine-tuning training, using contrast learning to train the model, the format of the input data is a triple' (query, positive, negative)'
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py generates a triple training set based on Chinese STS-B, with the format as follows: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py uses Faiss similar match, making mining difficult to negative examples.Since the text2vec trained models can be loaded using the sentence-transformers library, its model distillation method is multiplexed here.
Provide two deployment models and methods to build services: 1) Build gRPC services based on Jina [Recommended]; 2) Build native Http services based on FastAPI.
It uses C/S mode to build high-performance services, supports docker cloud native, gRPC/HTTP/WebSocket, supports simultaneous prediction of multiple models and GPU multi-card processing.
Install: pip install jina
Start the service:
example: examples/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()The model prediction method (executor) has been uploaded to JinaHub, including docker and k8s deployment methods.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )See example: examples/jina_client_demo.py for batch calling methods
Install: pip install fastapi uvicorn
Start the service:
example: examples/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Dataset | Introduction | Download Link |
|---|---|---|
| shibing624/nli-zh-all | Chinese semantic matching data collection, integrating 8.2 million high-quality data for tasks such as text reasoning, similarity, summary, question and answer, instruction fine-tuning, and converted into matching format data set | https://huggingface.co/datasets/shibing624/nli-zh-all |
| shibing624/snli-zh | Chinese SNLI and MultiNLI datasets, translated from English SNLI and MultiNLI | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624/nli_zh | Chinese semantic matching data set, integrating data sets of 5 tasks, including ATEC, BQ, LCQMC, PAWSX, and STS-B. | https://huggingface.co/datasets/shibing624/nli_zh or Baidu Netdisk (extraction code: qkt6) or github |
| shibing624/sts-sohu2021 | Chinese semantic matching dataset, 2021 Sohu Campus Text Matching Algorithm Competition dataset | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| ATEC | Chinese ATEC dataset, Ant Financial Q-Qpair dataset | ATEC |
| BQ | Chinese BQ (Bank Question) dataset, bank Q-Qpair dataset | BQ |
| LCQMC | Chinese LCQMC (large-scale Chinese question matching corpus) dataset, Q-Qpair dataset | LCQMC |
| PAWSX | Chinese PAWS (Paraphrase Adversaries from Word Scrambling) dataset, Q-Qpair dataset | PAWSX |
| STS-B | Chinese STS-B dataset, Chinese natural language inference dataset, dataset translated from English STS-B to Chinese | STS-B |
Commonly used English matching datasets:
Example of dataset usage:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])output:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
If you use text2vec in your research, please quote it in the following format:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibTeX:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}The license agreement is The Apache License 2.0, which can be used for commercial purposes for free. Please attach the link and authorization agreement of text2vec to the product description.
The project code is still very rough. If you have improved the code, you are welcome to submit it back to this project. Before submitting, pay attention to the following two points:
testspython -m pytest -v to run all unit tests, making sure all single tests are passedYou can submit your PR later.


