text2vec
1.2.9
?? Chinês | Inglês | Documentos/documentos | ? Modelos/modelos

Text2vec : texto para vetor, obtenha incorporação de sentença. Vectorização de texto, caracteriza o texto (incluindo palavras, frases e parágrafos) como uma matriz vetorial.
O Text2Vec implementa uma variedade de modelos de representação de texto e similaridade de texto, como Word2Vec, RankBM25, Bert, sentença-bert, Cosent e compara os efeitos de cada modelo na tarefa de correspondência semântica de texto (cálculo de similaridade).
[2023/09/20] V1.2.9 Versão: suporta inferência de vários cartões (implementação de multiprocessos de inferência multi-GPU e multi-CPU), é adicionada uma nova ferramenta de linha de comando (CLI), que pode executar scripts executar a vetorização de texto em lote. Consulte a Release-V1.2.9 para obter detalhes.
[2023/09/03] V1.2.4 Versão: suporta o treinamento do modelo de flagembedding e lançou o modelo de correspondência chinês Shibing624/text2vec-bge-Large-Chinese, que é supervisionado e treinado usando o método COSENT. É treinado com base na BAAI/bge-large-zh-noinstruct , e a avaliação do conjunto de dados correspondente chinesa melhorou em comparação com o modelo original. A diferença entre o texto curto é significativamente melhorada. Consulte a Release-V1.2.4 para obter detalhes.
[2023/07/17] V1.2.2 Versão: suporta treinamento com vários cartões e lançou o modelo de correspondência multi-linguagem Shibing624/text2vec-Base-multilingual, que é treinado usando o método COSENT. Based on sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 it is trained using manual multi-language STS dataset shibing624/nli-zh-all/text2vec-base-multilingual-dataset, and the evaluation in the Chinese and English test set has improved the effect compared to the original model. Consulte a Release-V1.2.2 para obter detalhes.
[2023/06/19] V1.2.1 Versão: O modelo de correspondência chinês shibing624/text2vec-base-chinese-nli é atualizado como a nova versão do Shibing624/Text2vec-Base-Chinese-frase. Com base na sensibilidade do cálculo de perdas de Cosent à classificação, o conjunto de dados STS de alta qualidade com classificação de correlação foi selecionado e classificado manualmente, o que melhorou o desempenho de cada conjunto de avaliação em comparação com isso; O modelo de correspondência chinês Shibing624/Text2vec-Base-Chinese-Paraphrase para S2P foi lançado, consulte a Release-V1.2.1 para obter detalhes.
[2023/06/15] V1.2.0 Versão: O modelo de correspondência chinês Shibing624/Text2vec-Base-Chinese-NLI foi lançado. Com base nghuyong/ernie-3.0-base-zh , é usado o modelo de correspondência de texto Cosent treinado pelo conjunto de dados NLI chinês Shibing624/NLI_ZH. O desempenho em cada conjunto de avaliação é significativamente melhorado. Consulte a Release-V1.2.0 para obter detalhes.
[2022/03/12] V1.1.4 Versão: O modelo de correspondência chinês Shibing624/text2vec-Base-chinese é lançado, um modelo de correspondência co-deente treinado com base no conjunto de treinamento chinês do STS. Consulte a Release-V1.1.4 para obter detalhes
Guia
Veja Wiki: Método de representação do vetor de texto para método detalhado de representação de vetor de texto
Correspondência de texto
| Arco | Basemodel | Modelo | English-Sts-B |
|---|---|---|---|
| Luva | Gleve | AVG_WORD_EMBEDDINGS_GLOVE_6B_300D | 61.77 |
| Bert | Bert-Base-ANSed | Bert-Base-CLS | 20.29 |
| Bert | Bert-Base-ANSed | Bert-BASE-FIRST_LAST_AVG | 59.04 |
| Bert | Bert-Base-ANSed | Bert-Base-First_last_avg-Whiten (NLI) | 63.65 |
| Sbert | Sentença-Transformers/Bert-Base-nli-Mean-Tokens | Sbert-Base-NLI-CLS | 73.65 |
| Sbert | Sentença-Transformers/Bert-Base-nli-Mean-Tokens | Sbert-Base-NLI-FIRST_LAST_AVG | 77.96 |
| Cosent | Bert-Base-ANSed | COSENT-BASE-FIRST_LAST_AVG | 69.93 |
| Cosent | Sentença-Transformers/Bert-Base-nli-Mean-Tokens | COSENT-BASE-NLI-FIRST_LAST_AVG | 79.68 |
| Cosent | Sentença-transformadores/parafrase-multilíngue-minilm-L12-V2 | shibing624/text2vec-Base-multilingual | 80.12 |
| Arco | Basemodel | Modelo | Atec | BQ | LCQMC | PAWSX | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|
| Sbert | Bert-Base-Chinese | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL/chinês-Macbert-Base | SBERT-MACBERT-BASE | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| Sbert | HFL/Chinês-Roberta-Wwm-EXT | SBERT-ROBERTA-EXT | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| Cosent | Bert-Base-Chinese | Cosent-Bert-Base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| Cosent | HFL/chinês-Macbert-Base | Cosent-Macbert-Base | 50.39 | 72.93 | 79.17 | 60,86 | 79.30 | 68.53 |
| Cosent | HFL/Chinês-Roberta-Wwm-EXT | Cosent-Roberta-EXT | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
ilustrar:
SBERT-macbert-base é treinado usando o método sbert e execute exemplos/treinamento_sup_text_matching_model.py Código para treinar o modelo.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 é treinado com Sbert e é uma versão multilíngue do modelo paraphrase-MiniLM-L12-v2 , apoiando chinês, inglês, etc.| Arco | Basemodel | Modelo | Atec | BQ | LCQMC | PAWSX | STS-B | Sohu-dd | Sohu-dc | Avg | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2vec | Word2vec | W2V-Light-Tencent-Chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-ROBERTA-BASE | Sentença-transformadores/parafrase-multilíngue-minilm-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Cosent | HFL/chinês-Macbert-Base | shibing624/text2vec-bash-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| Cosent | HFL/Chinês-Lert-Large | Ganymedenil/text2vec-Large-Chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| Cosent | Nghuyong/Ernie-3.0-Base-ZH | Shibing624/Text2vec-Base-Chinese-frase | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| Cosent | Nghuyong/Ernie-3.0-Base-ZH | shibing624/text2vec-bashe-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40,90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| Cosent | Sentença-transformadores/parafrase-multilíngue-minilm-L12-V2 | shibing624/text2vec-Base-multilingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68,88 | 51.17 | 53.67 | 3138 |
| Cosent | Baai/BGE-Large-ZH-NOINSTRUCT | shibing624/text2vec-bge-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
ilustrar:
shibing624/text2vec-base-chinese é treinado usando o método COSENT, treinado em dados chineses do STS-B com base em hfl/chinese-macbert-base e avaliado no conjunto de testes chineses do STS-B para obter bons resultados. Execute os exemplos/treinamento_sup_text_matching_model.py para treinar o modelo. O arquivo de modelo foi enviado para o HF Model Hub. Recomenda -se usar a tarefa de correspondência semântica geral chinesa.shibing624/text2vec-base-chinese-sentence é treinado usando o método COSENT. É treinado com base no conjunto de dados STS chineses selecionados manualmente Shibing624/nli-zh-all/text2vec- nghuyong/ernie-3.0-base-zh -Chinese-sentence-Dataset e é avaliado em vários conjuntos de testes de NLI chineses para obter bons resultados. Execute os exemplos/treinamento_sup_text_matching_model_jsonl_data.py Código para treinar o modelo. O arquivo de modelo foi enviado para o HF Model Hub. Recomenda -se a tarefa de correspondência semântica S2S chinesa (sentença versus)shibing624/text2vec-base-chinese-paraphrase é treinado usando o método COSENT. Com base no conjunto de dados STS chinês selecionado por nghuyong/ernie-3.0-base-zh manualmente, Shibing624/NLI-ZH-ALL/Text2vec-Base-Chinese-Paraphrase-DataSet, o conjunto de dados é adicionado a S2p (sentença) relativa ao shibing624/nli-zh-ZH-ZH-ZH-ZH-ZET-ZET-ZEN-ZET-ZH-ZET-ZH-ZEN-ZET. Parafrase) os dados fortalecem sua capacidade de representação de texto longo e avalia para obter o SOTA em vários conjuntos de testes de NLI chineses. Execute exemplos/treinamento_sup_text_matching_model_jsonl_data.py Código para treinar o modelo. O arquivo de modelo foi enviado para o HF Model Hub. Recomenda -se uma tarefa de correspondência semântica S2P chinesa (sentença vs parágrafo).shibing624/text2vec-base-multilingual é treinado usando o método COSENT. É treinado com base em sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 usando o conjunto de dados Multilingual STS multilíngue selecionado manualmente Shibing624/nli-zh-all/text2vec-bashe-multilingual-DataSet. É avaliado no conjunto de testes chinês e inglês e o efeito é melhorado em comparação com o modelo original. Execute os exemplos/treinamento_sup_text_matching_model_jsonl_data.py Código para treinar o modelo. O arquivo de modelo foi enviado para o HF Model Hub. Recomenda -se usar a tarefa de correspondência semântica multilíngue.shibing624/text2vec-bge-large-chinese é treinado usando o método COSENT. É treinado com base no BAAI/bge-large-zh-noinstruct usando o conjunto de dados STS chinês selecionado manualmente Shibing624/nli-zh-all/text2vec-bashe-chinese-paraphrase-dados. A avaliação no conjunto de testes chineses melhorou o efeito em comparação com o modelo original, e a diferença no texto curto é significativamente melhorada. Execute os exemplos/treinamento_sup_text_matching_model_jsonl_data.py Código para treinar o modelo. O arquivo de modelo foi enviado para o HF Model Hub. Recomenda -se a tarefa de correspondência semântica S2S chinesa (sentença versus)w2v-light-tencent-chinese é um modelo Word2vec de vetores de palavras tencent, usados por carregamento da CPU, adequado para tarefas de correspondência literal chinesa e situações de partida a frio dos dados ausentes--model_name hfl/chinese-macbert-base ou Roberta Modelo: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG e EncoderType.MEAN , e os efeitos de previsão dos dois são muito pequenos.examples/data e executar o código Testes/Model_Spearman.Py para reproduzir os resultados da avaliação.Relatório Experimental de Treinamento para Modelo: Relatório Experimental
Demonstração oficial: https://www.mulanai.com/product/short_text_sim/
Huggingface Demo: https://huggingface.co/spaces/shibing624/text2vec

Exemplo de execução: exemplos/gradio_demo.py para ver a demonstração:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecou
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Calcule os vetores de texto com base no pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Exemplo: Exemplos/Computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )saída:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings de valor de retorno é tipo numpy.ndarray , Shape é (sentences_size, model_embedding_size) e você pode escolher qualquer um dos três modelos. O primeiro é recomendado.shibing624/text2vec-base-chinese é obtido pelo treinamento de métodos Cosent no conjunto de dados chinês de STS-B. O modelo foi enviado para a biblioteca de modelos de huggingface shibing624/text2vec-base-chinese. É o modelo padrão especificado por text2vec.SentenceModel . Pode ser chamado através do exemplo acima, ou pode ser chamado com a biblioteca Transformers, como mostrado abaixo. O modelo será baixado automaticamente para o caminho nativo: ~/.cache/huggingface/transformersw2v-light-tencent-chinese é um modelo Word2VEC carregado através de Gensim. Os vetores da palavra de cada palavra são calculados usando o vetor de palavra tencent Tencent_AILab_ChineseEmbedding.tar.gz O vetor da frase é calculado a média através da palavra vetor. O modelo é baixado automaticamente para o caminho nativo: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec suporta inferência de vários cartões (vetor de texto Calcule): Exemplos/Computing_embeddings_multi_gpu_demo.py Sem Text2Vec, você pode usar o modelo como este:
Primeiro, você passa sua entrada através do modelo do transformador e, em seguida, deve aplicar a operação correta de operação no topo das incorporações contextualizadas do Word.
Exemplo: Exemplos/USE_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )O Frenda-Transformers é uma biblioteca popular para calcular representações vetoriais densas para sentenças.
Instale a sentença-transformadores:
pip install -U sentence-transformersEm seguida, carregue o modelo e preveja:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word Vector Forneça dois vetores Word2Vec Word, opcionalmente um:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , tencent word vector Página inicial: https://ai.tencent.com/ailab/nlp/zh/index.html https://ai.tencent.com/ailab/nlp/en/download.html Mais visualizar tencent word vetor introdução-wikiSuporte a aquisição em lote de vetores de texto
Código: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
correr:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueArquivo de entrada (requerido):
input.txt, formato: texto da frase de uma frase, uma linha.
Exemplo: Exemplos/Semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))saída:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591O alcance
scoredo valor da similaridade de cosseno de sentença é [-1, 1] e quanto maior o valor, mais semelhante é.
Geralmente, o texto mais semelhante à consulta é encontrado no conjunto de candidatos a documentos e é frequentemente usado para tarefas como correspondência de similaridade de perguntas e recuperação de similaridade de texto nos cenários de controle de qualidade.
Exemplo: exemplos/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))saída:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Biblioteca de semelhanças [recomendado]
Para o cálculo da similaridade de texto e as tarefas de pesquisa de correspondência de texto, é recomendável usar a biblioteca de semelhanças, que é compatível com os modelos de lançamento do Word2Vec, Sbert e de correspondência semântica do tipo Cosent neste projeto. Ele também suporta pesquisas gráficas de 100 milhões de níveis e suporta desduplicação semântica de texto , desduplicação de imagens e outras funções.
Instalação: pip install -U similarities
Cálculo da similaridade da frase:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Modelo de correspondência de texto Cosent (Sentença Cossene), Melhora o esquema de vetor de sentença do CosineRankloss na sentença-Bert
Estrutura de rede:
Treinamento:
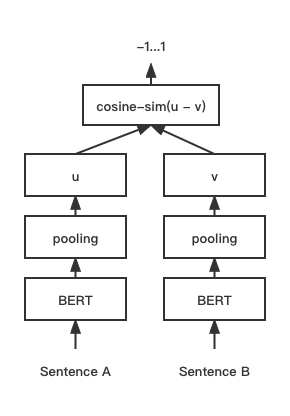
Inferência:
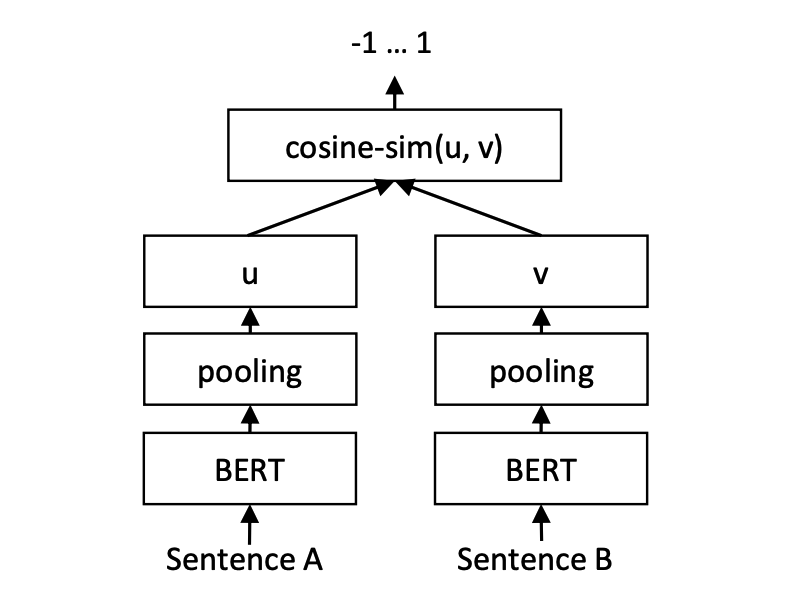
Treinamento e previsão de modelos Cosent:
CoSENT no conjunto de dados chinês de STS-BExemplo: Exemplos/Training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT no conjunto de dados de correspondência financeira ATEC ATECApoie o uso desses conjuntos de dados correspondentes chineses: 'Atec', 'STS-B', 'BQ', 'LCQMC', 'Pawsx', para obter detalhes, consulte os conjuntos de dados HuggingFace https://huggingface.co/datasets/shibing624/nli_zhh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentExemplo: Exemplos/Training_sup_text_matching_model_mydata.py
Treinamento de cartão único:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictTreinamento do Doka:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Exemplos de referência/dados/sts-b/sts-b.valid.data para formato de conjunto de treinamento
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label pode ser os rótulos 0 e 1, e 0 significa que as duas frases não são semelhantes e 1 significa semelhante; Também pode ser uma pontuação de 0-5. Quanto maior a pontuação, mais semelhantes as duas frases são. Todos os modelos podem ser suportados.
CoSENT no conjunto de dados ingleses do STS-BExemplo: Exemplos/Training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT no conjunto de dados NLI em inglês e efeito de avaliação no conjunto de testes STS-BExemplo: Exemplos/Training_unsup_text_matching_model_en.py
cd examples
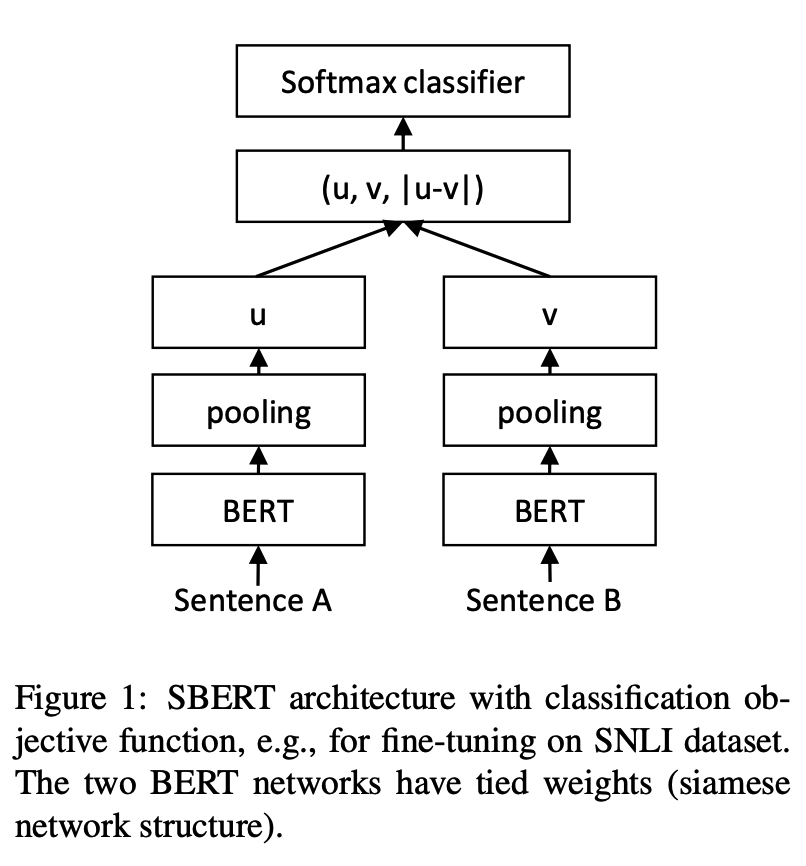
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentModelo de correspondência de texto de frase-bert, esquema de representação de vetor de sentença representacional
Estrutura de rede:
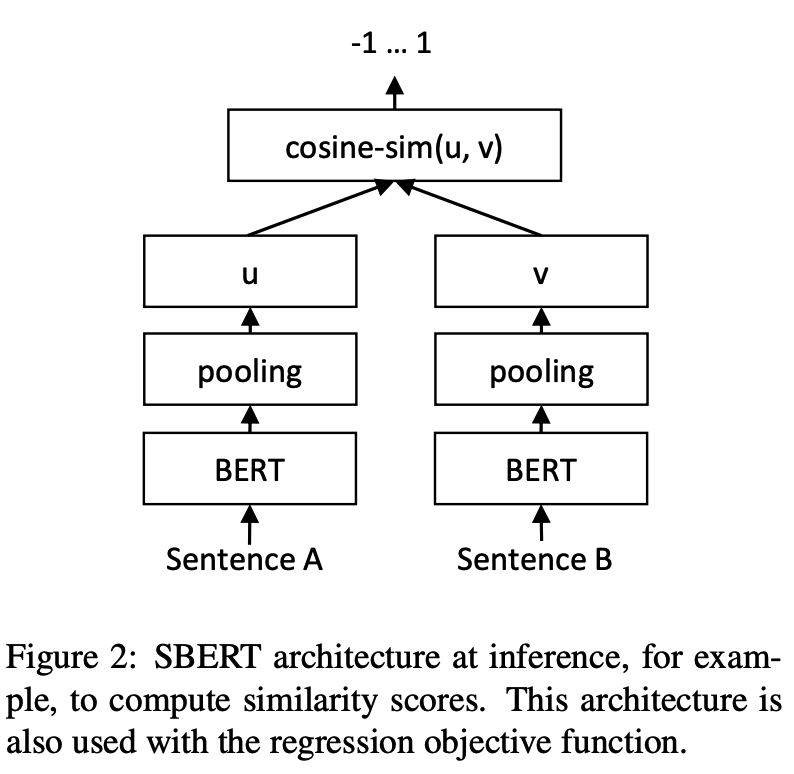
Treinamento:
Inferência:
SBERT no conjunto de dados chinês do STS-BExemplo: Exemplos/Training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT no conjunto de dados ingleses do STS-BExemplo: Exemplos/Training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT no conjunto de dados NLI em inglês e avaliação do efeito no conjunto de testes STS-BExemplo: Exemplos/Training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertModelo de correspondência de texto Bert, estrutura de rede de combinação de Bert nativa, modelo de correspondência de vetor de sentença interativa
Estrutura de rede:
Treinamento e inferência:
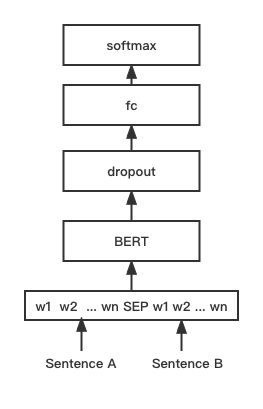
O script de treinamento é o mesmo dos exemplos acima/Treinamento_sup_text_matching_model.py.
BGE no conjunto de dados chinês de STS-BExemplo: Exemplos/Training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16Modelo BGE Treinamento de ajuste fino, usando o aprendizado de contraste para treinar o modelo, o formato dos dados de entrada é um triplo '(consulta, positivo, negativo)' '
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py gera um conjunto de treinamento triplo com base no STS-B chinês, com o formato da seguinte forma: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py usa o FAISS semelhante corresponde, dificultando a mineração de exemplos negativos.Como os modelos treinados por text2vec podem ser carregados usando a biblioteca de transformadores de frases, seu método de destilação de modelo é multiplexado aqui.
Forneça dois modelos e métodos de implantação para construir serviços: 1) Crie serviços GRPC com base em Jina [recomendado]; 2) Crie serviços HTTP nativos com base no FASTAPI.
Ele usa o modo C/S para criar serviços de alto desempenho, suporta o Docker Cloud Native, GRPC/HTTP/WebSocket, suporta a previsão simultânea de vários modelos e o processamento multi-card GPU.
Instale: pip install jina
Inicie o serviço:
Exemplo: Exemplos/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()O método de previsão do modelo (executor) foi enviado para o Jinahub, incluindo métodos de implantação do Docker e K8S.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )Veja o exemplo: Exemplos/jina_client_demo.py para métodos de chamada em lote
Instale: pip install fastapi uvicorn
Inicie o serviço:
Exemplo: Exemplos/FASTAPI_SERVER_DEMO.PY
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Conjunto de dados | Introdução | Baixar link |
|---|---|---|
| shibing624/nli-zh-all | Coleta de dados semântica em chinês, integrando 8,2 milhões de dados de alta qualidade para tarefas como raciocínio de texto, semelhança, resumo, pergunta e resposta, ajuste fino de instrução e convertido em conjunto de dados de formato correspondente | https://huggingface.co/datasets/shibing624/nli-zh-all |
| shibing624/snli-zh | Conjuntos de dados chineses snli e multinli, traduzidos de snli e multinli em inglês | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624/nli_zh | Conjunto de dados de correspondência semântica chinesa, integrando conjuntos de dados de 5 tarefas, incluindo ATEC, BQ, LCQMC, PAWSX e STS-B. | https://huggingface.co/datasets/shibing624/nli_zh ou Baidu NetDisk (Código de Extração: QKT6) ou Github |
| Shibing624/STS-SOHU2021 | Conjunto de dados de correspondência semântica chinesa, 2021 Sohu Campus Text Matching Algorithm Competition DataSet | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| Atec | Conjunto de dados do ATEC chinês, Ant Financial Q-Qpair DataSet | Atec |
| BQ | Conjunto de dados chinês de BQ (questão bancária), conjunto de dados do banco Q-Qpair | BQ |
| LCQMC | LCQMC chinês (Corpus de correspondência chinês em larga escala) | LCQMC |
| PAWSX | PAWS CHINESS (parafrase adversários da Word Scrambling) conjunto de dados, conjunto de dados Q-QPair | PAWSX |
| STS-B | Conjunto de dados chineses de STS-B, conjunto de dados de inferência de idioma natural chinês, conjunto de dados traduzido de STS-B em inglês para chinês | STS-B |
Conjuntos de dados de correspondência inglesa comumente usados:
Exemplo de uso do conjunto de dados:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])saída:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Se você usar o Text2Vec em sua pesquisa, cite -a no seguinte formato:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}O contrato de licença é o Apache License 2.0, que pode ser usado para fins comerciais gratuitamente. Anexe o link e o contrato de autorização do Text2vec à descrição do produto.
O código do projeto ainda é muito difícil. Se você melhorou o código, poderá enviá -lo de volta a este projeto. Antes de enviar, preste atenção aos dois pontos a seguir:
testspython -m pytest -v para executar todos os testes de unidade, certificando -se de que todos os testes únicos sejam passadosVocê pode enviar seu PR mais tarde.


