text2vec
1.2.9
?? chino | Inglés | Documentos/documentos | ? Modelos/modelos

Text2Vec : Texto a Vector, obtenga incrustaciones de oraciones. La vectorización de texto, caracteriza el texto (incluidas las palabras, las oraciones y los párrafos) como una matriz vectorial.
Text2Vec implementa una variedad de modelos de representación de texto y cálculo de similitud de texto como Word2VEC, RankBM25, Bert, Forma-Bert, Cosent, y compara los efectos de cada modelo en la tarea de coincidencia semántica de texto (cálculo de similitud).
[2023/09/20] V1.2.9 Versión: Admite inferencia de múltiples tarjetas (implementación multiprocesada de inferencia multi-GPU y multi-CPU), se agrega una nueva herramienta de línea de comandos (CLI), que puede los scripts realizar vectorización de texto por lotes. Vea la versión-v1.2.9 para más detalles.
[2023/09/03] V1.2.4 Versión: Admite el entrenamiento del modelo de flagoting, y lanzó el modelo de coincidencia chino shibing624/text2vec-bge---chinese, que se supervisa y entrena utilizando el método cosent. Está entrenado en función de BAAI/bge-large-zh-noinstruct , y la evaluación del conjunto de datos coincidentes chinos ha mejorado en comparación con el modelo original. La diferencia entre el texto corto mejora significativamente. Vea la versión-v1.2.4 para más detalles.
[2023/07/17] V1.2.2 Versión: Admite capacitación de múltiples tarjetas y lanzó el modelo de correspondencia de varios idiomas shibing624/text2vec-base-multilingüe, que está entrenado utilizando el método cosent. Basado en sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 se capacita utilizando el conjunto de datos STS multilingüe manual Shibing624/NLI-ZH-ALL/Text2Vec-Base-Multilingüe-Dataset, y la evaluación en el conjunto de pruebas chinas e inglesas ha mejorado el efecto comparado con el modelo original. Vea la versión-v1.2.2 para más detalles.
[2023/06/19] V1.2.1 Versión: El modelo de coincidencia chino shibing624/text2vec-base-chinese-nli se actualiza como la nueva versión de shibing624/text2vec-base-chinessentence. Basado en la sensibilidad del cálculo de la pérdida de Cosent a la clasificación, el conjunto de datos STS de alta calidad con clasificación de correlación se seleccionó y se resolvió manualmente, lo que ha mejorado el rendimiento de cada conjunto de evaluación en comparación con eso; Se lanzó el modelo de coincidencia chino shibing624/text2vec-base-chines-paraphrase para S2P, consulte la versión-v1.2.1 para más detalles.
[2023/06/15] V1.2.0 Versión: se lanzó el modelo de coincidencia chino shibing624/text2vec-base-chinese-nli. Basado en nghuyong/ernie-3.0-base-zh , se utiliza el modelo de coincidencia de texto cosent entrenado por el conjunto de datos NLI chino Shibing624/NLI_ZH. El rendimiento en cada conjunto de evaluación mejora significativamente. Vea la versión-v1.2.0 para más detalles.
[2022/03/12] V1.1.4 Versión: Se lanza el modelo de coincidencia chino Shibing624/Text2Vec-Base-Chinese, se lanza un modelo de coincidencia cosecha basado en el conjunto de entrenamiento STS chino. Consulte la versión-v1.1.4 para más detalles
Guía
Ver Wiki: Método de representación de vectores de texto para el método de representación de vector de texto detallado
Coincidencia de texto
| Arco | Base de base | Modelo | Inglés-STS-B |
|---|---|---|---|
| Guante | Gleve | AVG_WORD_EMBEDDINGS_GLOVE_6B_300D | 61.77 |
| Bert | base-base | Bert-Base-Cls | 20.29 |
| Bert | base-base | Bert-base-first_last_avg | 59.04 |
| Bert | base-base | Bert-base-first_last_avg-whiten (NLI) | 63.65 |
| Sbert | oración-transformadores/bert-base-nli-mean-tokens | Sbert-Base-Nli-CLS | 73.65 |
| Sbert | oración-transformadores/bert-base-nli-mean-tokens | Sbert-base-nli-first_last_avg | 77.96 |
| Cosente | base-base | Cosent-base-first_last_avg | 69.93 |
| Cosente | oración-transformadores/bert-base-nli-mean-tokens | Cosent-base-nli-first_last_avg | 79.68 |
| Cosente | Transformadores de oración/parafraseo-Minilm-Minilm-L12-V2 | shibing624/text2vec-base-multilingüe | 80.12 |
| Arco | Base de base | Modelo | ATEC | Bq | LCQMC | Pawsx | STS-B | Aviso |
|---|---|---|---|---|---|---|---|---|
| Sbert | Bert-Base-china | Sbert-base-base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL/China-Macbert-Base | Sbert-macbert-base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| Sbert | HFL/China-Roberta-WWM-EXT | Sbert-Roberta-Ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| Cosente | Bert-Base-china | Cosent-base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| Cosente | HFL/China-Macbert-Base | Cosent-macbert-base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| Cosente | HFL/China-Roberta-WWM-EXT | Cosent-roBerta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
ilustrar:
SBERT-macbert-base está entrenado utilizando el método Sbert y ejecuta ejemplos/entrenador_sup_text_matching_model.py Código para entrenar el modelo.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 está entrenado con Sbert, y es una versión multilingüe del modelo paraphrase-MiniLM-L12-v2 , que admite chino, inglés, etc.| Arco | Base de base | Modelo | ATEC | Bq | LCQMC | Pawsx | STS-B | Sohu-dd | SOHU-DC | Aviso | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2vec | word2vec | W2V-Light-Tencent-chines | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-ROBERTA-BASE | Transformadores de oración/parafraseo-Minilm-Minilm-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Cosente | HFL/China-Macbert-Base | shibing624/text2vec-base-china | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| Cosente | HFL/China-Lert-Large | Ganymedenil/Text2vec-Large-chines | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| Cosente | Nghuyong/Ernie-3.0-Base-Zh | shibing624/text2vec-base-china-orientación | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| Cosente | Nghuyong/Ernie-3.0-Base-Zh | shibing624/text2vec-base-chines-paraphrass | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| Cosente | Transformadores de oración/parafraseo-Minilm-Minilm-L12-V2 | shibing624/text2vec-base-multilingüe | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| Cosente | Baai/BGE-LARGE-ZH-Noinstructo | shibing624/text2vec-bge-larga-china | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
ilustrar:
shibing624/text2vec-base-chinese está entrenado utilizando el método Cosent, entrenado en datos STS-B chinos basados en hfl/chinese-macbert-base , y se evalúa en el conjunto de pruebas STS-B chinas para lograr buenos resultados. Ejecute el código de ejemplos/entrenador_sup_text_matching_model.py para entrenar el modelo. El archivo del modelo se ha cargado en HF Model Hub. Se recomienda utilizar la tarea de coincidencia semántica general china.shibing624/text2vec-base-chinese-sentence se entrenando utilizando el método Cosent. Está entrenado en función del conjunto de datos STS chino seleccionado manualmente Shibing624/NLI-ZH-ALL/Text2Vec- nghuyong/ernie-3.0-base-zh -Chinese-Sentence-Dataset, y se evalúa en varios conjuntos de pruebas NLI chinos para lograr buenos resultados. Ejecute los ejemplos/entrenador_sup_text_matching_model_jsonl_data.py para entrenar el modelo. El archivo del modelo se ha cargado en HF Model Hub. Se recomienda usar la tarea de coincidencia semántica S2S (oración vs oración) chinashibing624/text2vec-base-chinese-paraphrase está entrenado utilizando el método Cosent. Basado en el conjunto de datos STS chino seleccionado por nghuyong/ernie-3.0-base-zh manualmente, Shibing624/NLI-ZH-ALL/Text2Vec-Base-Chines-Paraphrase-DataSet se agrega a S2P (oración) relativa a Fhibing 624/Nli-Z-ALL/Text2vec-ChineSeSeSeSeSet. Parafraseo) Los datos fortalecen su larga capacidad de representación de texto y evalúan para lograr SOTA en varios conjuntos de pruebas NLI chinos. Ejecutar ejemplos/entrenador_sup_text_matching_model_jsonl_data.py Código para entrenar el modelo. El archivo del modelo se ha cargado en HF Model Hub. Se recomienda la tarea de coincidencia semántica S2P (oración vs párrafo) china.shibing624/text2vec-base-multilingual se capacita utilizando el método cosent. Está entrenado en función de sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 utilizando el conjunto de datos multilingüe de STS seleccionado manualmente shibing624/nli-zh-all/text2vec-base-multilingüe-dataSet. Se evalúa en el conjunto de pruebas chinas e inglesas, y el efecto se mejora en comparación con el modelo original. Ejecute los ejemplos/entrenador_sup_text_matching_model_jsonl_data.py para entrenar el modelo. El archivo del modelo se ha cargado en HF Model Hub. Se recomienda utilizar la tarea de coincidencia semántica multilingüe.shibing624/text2vec-bge-large-chinese está entrenado utilizando el método cosent. Está entrenado en base a BAAI/bge-large-zh-noinstruct utilizando el conjunto de datos STS chino seleccionado manualmente Shibing624/NLI-ZH-ALL/Text2Vec-Base-Chineset-DataSet. La evaluación en el conjunto de pruebas chinas ha mejorado el efecto en comparación con el modelo original, y la diferencia en el texto corto mejora significativamente. Ejecute los ejemplos/entrenador_sup_text_matching_model_jsonl_data.py para entrenar el modelo. El archivo del modelo se ha cargado en HF Model Hub. Se recomienda usar la tarea de coincidencia semántica S2S (oración vs oración) chinaw2v-light-tencent-chinese es un modelo Word2Vec de vectores de palabras de Tencent, utilizados por la carga de CPU, adecuado para tareas de coincidencia literal china y situaciones de inicio en frío de datos faltantes--model_name hfl/chinese-macbert-base o roberta modelo: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG y EncoderType.MEAN , y los efectos de predicción de los dos son muy pequeños.examples/data y ejecutar el código Tests/Model_spearman.py para reproducir los resultados de la evaluación.Entrenamiento modelo Informe experimental: Informe experimental
Demostración oficial: https://www.mulanai.com/product/short_text_sim/
Demo de Huggingface: https://huggingface.co/spaces/shibing624/text2vec

Ejemplo de ejecución: ejemplos/gradio_demo.py para ver la demostración:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2veco
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Calcule los vectores de texto basados en pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Ejemplo: Ejemplos/Computing_embeddings_Demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )producción:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings de valor de retorno son type numpy.ndarray , la forma es (sentences_size, model_embedding_size) , y puede elegir cualquiera de los tres modelos. El primero se recomienda.shibing624/text2vec-base-chinese se obtiene mediante el entrenamiento de métodos Cosent en el conjunto de datos STS-B chino. El modelo se ha subido a la biblioteca de modelos de Huggingface Shibing624/Text2Vec-Base-chinese. Es el modelo predeterminado especificado por text2vec.SentenceModel . Se puede llamar a través del ejemplo anterior, o se puede llamar con la biblioteca Transformers como se muestra a continuación. El modelo se descargará automáticamente a la ruta nativa: ~/.cache/huggingface/transformersw2v-light-tencent-chinese es un modelo Word2Vec cargado a través de Gensim. Las palabras vectores de cada palabra se calculan utilizando la palabra tencent vector Tencent_AILab_ChineseEmbedding.tar.gz El vector de oración se promedia a través del vector de palabras. El modelo se descarga automáticamente en la ruta nativa: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec admite una inferencia de múltiples tarjetas (calcule el vector de texto): ejemplos/computing_embeddings_multi_gpu_demo.py Sin Text2Vec, puede usar el modelo como este:
Primero, pasa su aporte a través del modelo Transformer, luego debe aplicar la operación de agrupación correcta en la parte superior de las incrustaciones de palabras contextualizadas.
Ejemplo: ejemplos/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Sentence-Transformers es una biblioteca popular para calcular las densas representaciones vectoriales para oraciones.
Instalar transformadores de oraciones:
pip install -U sentence-transformersLuego cargar modelo y predecir:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word Vector Proporcione dos vectores de palabras Word2Vec , opcionalmente uno:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin momentos de los momentos.~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , Tencent Word Vector Página de inicio: https://ai.tencent.com/ailab/nlp/zh/index.html Vector Vector Dirección: Dirección::: https://ai.tencent.com/ailab/nlp/en/download.html Más Ver tencent Word Vector Introducción-WikiAdquisición de lotes de soporte de vectores de texto
Código: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
correr:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueArchivo de entrada (requerido):
input.txt, formato: texto de oración de una oración, una línea.
Ejemplo: ejemplos/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))producción:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591El rango
scoredel valor de similitud de coseno de oración es [-1, 1], y cuanto mayor sea el valor, más similar es.
En general, el texto que es más similar a la consulta se encuentra en el conjunto de candidatos del documento, y a menudo se usa para tareas, como la coincidencia de similitud de preguntas y la recuperación de similitud de texto en los escenarios de control de calidad.
Ejemplo: ejemplos/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))producción:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Biblioteca de similitudes [recomendado]
Para el cálculo de similitud de texto y las tareas de búsqueda de coincidencia de texto, se recomienda utilizar la biblioteca de similitudes, que es compatible con los modelos de lanzamiento semánticos de Word2Vec, Sbert y Cosent en este proyecto. También admite búsquedas gráficas de 100 millones de niveles y admite la deduplicación semántica de texto , deduplicación de imágenes y otras funciones.
Instalación: pip install -U similarities
Cálculo de similitud de oración:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
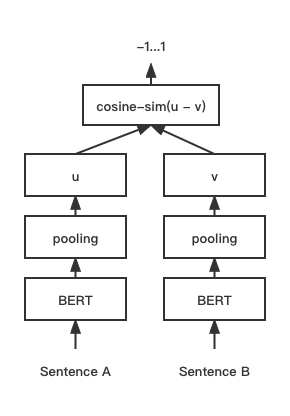
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Modelo de coincidencia de texto de cosent (coseno), mejora el esquema del vector de oración de Cosinerankloss en la oración-Bert
Estructura de red:
Capacitación:
Inferencia:
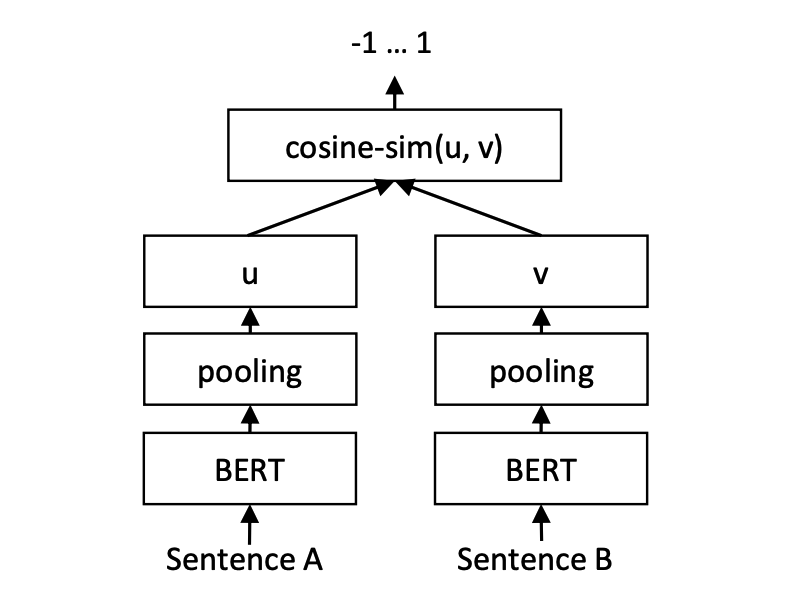
Entrenamiento y predicción de modelos Cosent:
CoSENT en el conjunto de datos STS-B chinoEjemplo: ejemplos/entrenador_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT en el conjunto de datos de coincidencia financiera de hormigas ATECApoya el uso de estos conjuntos de datos de coincidencia de chinos: 'atec', 'sts-b', 'bq', 'lcqmc', 'pawsx', para más detalles, consulte Huggingface DataSets https://huggingface.co/datasets/Shibing624/nli_zhh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentEjemplo: ejemplos/entrenador_sup_text_matching_model_mydata.py
Entrenamiento de una sola tarjeta:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictEntrenamiento de Doka:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Ejemplos de referencia/data/sts-b/sts-b.valid.data para formato de conjunto de entrenamiento
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label puede ser las etiquetas 0 y 1, y 0 significa que las dos oraciones no son similares, y 1 significa similar; También puede ser un puntaje de 0-5. Cuanto mayor sea la puntuación, más similares son las dos oraciones. Todos los modelos pueden ser compatibles.
CoSENT en el conjunto de datos STS-B inglésEjemplo: ejemplos/entrenador_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT Capacitación en un conjunto de datos NLI inglés y efecto de evaluación en el conjunto de pruebas STS-BEjemplo: ejemplos/entrenador_unsup_text_matching_model_en.py
cd examples
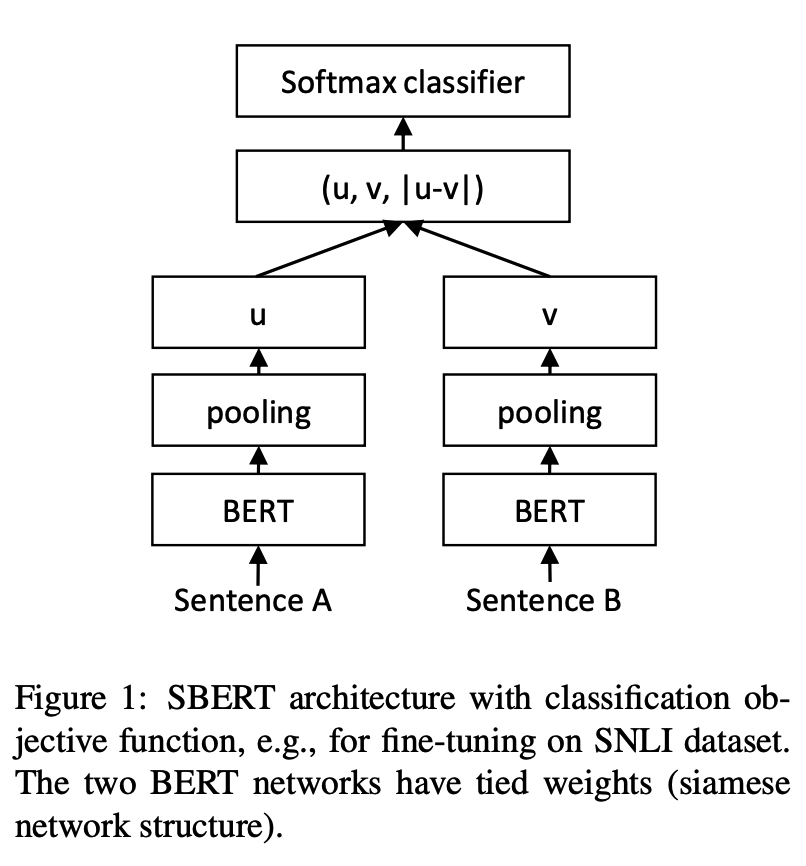
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentModelo de coincidencia de texto de oración-Bert, esquema de representación del vector de oración representativa
Estructura de red:
Capacitación:
Inferencia:
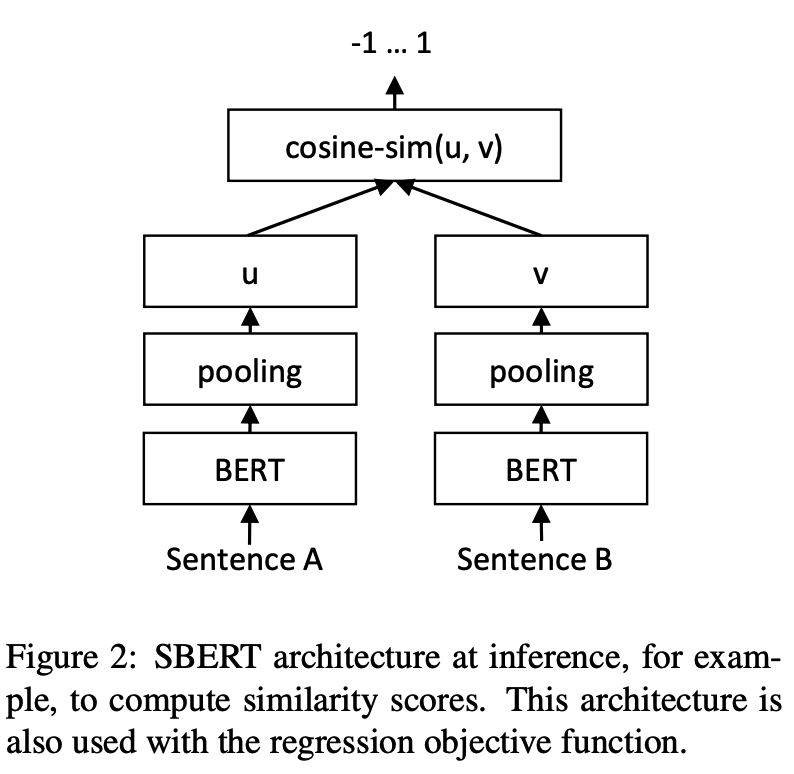
SBERT en el conjunto de datos STS-B chinoEjemplo: ejemplos/entrenador_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT en el conjunto de datos STS-B inglésEjemplo: ejemplos/entrenador_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT en un conjunto de datos NLI inglés y efecto de evaluación en el conjunto de pruebas STS-BEjemplo: ejemplos/entrenador_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertModelo de coincidencia de texto de Bert, estructura de red nativa de coincidencia de bert, modelo de coincidencia de vectores de oración interactiva
Estructura de red:
Entrenamiento e inferencia:
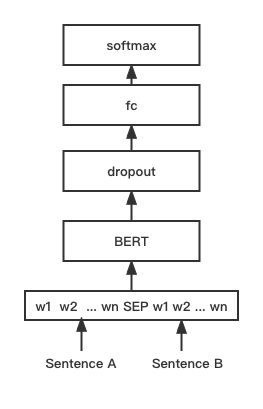
El script de entrenamiento es el mismo que el anterior ejemplos/entrenador_sup_text_matching_model.py.
BGE en el conjunto de datos STS-B chinoEjemplo: ejemplos/entrenador_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16Entrenamiento de ajuste del modelo BGE, utilizando el aprendizaje de contraste para entrenar el modelo, el formato de los datos de entrada es un triple '(consulta, positivo, negativo)'
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py genera un conjunto de capacitación triple basado en STS-B chino, con el formato de la siguiente manera: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py utiliza FAISS Match similar, lo que hace que la minería sea difícil a los ejemplos negativos.Dado que los modelos entrenados Text2Vec se pueden cargar utilizando la biblioteca de transformadores de oraciones, su método de destilación de modelo se multiplica aquí.
Proporcione dos modelos y métodos de implementación para crear servicios: 1) Cree servicios de GRPC basados en Jina [recomendado]; 2) Construya servicios HTTP nativos basados en Fastapi.
Utiliza el modo C/S para crear servicios de alto rendimiento, admite Docker Cloud Native, GRPC/HTTP/WebSocket, admite la predicción simultánea de múltiples modelos y el procesamiento de tarjetas múltiples GPU.
Instalar: pip install jina
Inicie el servicio:
Ejemplo: ejemplos/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()El método de predicción del modelo (ejecutor) se ha cargado a Jinahub, incluidos los métodos de implementación de Docker y K8s.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )Ver ejemplo: ejemplos/jina_client_demo.py para métodos de llamadas por lotes
Instalar: pip install fastapi uvicorn
Inicie el servicio:
Ejemplo: ejemplos/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Conjunto de datos | Introducción | Enlace de descarga |
|---|---|---|
| shibing624/nli-zh-all | Recopilación de datos de coincidencia semántica china, que integran 8.2 millones de datos de alta calidad para tareas como razonamiento de texto, similitud, resumen, pregunta y respuesta, instrucción ajustado y convertido en un conjunto de datos de formato coincidente | https://huggingface.co/datasets/shibing624/nli-zh-all |
| shibing624/snli-zh | Conjuntos de datos chinos SNLI y multinli, traducidos de inglés SNLI y multinli | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624/nli_zh | Conjunto de datos de coincidencia semántica china, que integran conjuntos de datos de 5 tareas, incluidos ATEC, BQ, LCQMC, PAWSX y STS-B. | https://huggingface.co/datasets/shibing624/nli_zh o Baidu NetDisk (código de extracción: QKT6) o github |
| shibing624/sts-sohu2021 | Conjunto de datos de coincidencia semántica china, 2021 Sohu Campus Text Matching Algorithm Competition DataSet DataSet | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| ATEC | Conjunto de datos ATEC chino, hormiga financiera Q-Q-Qpair DataSet | ATEC |
| Bq | Conjunto de datos chino BQ (cuestión bancaria), conjunto de datos Bank Q-Q-Qpair | Bq |
| LCQMC | DataSet LCQMC chino (Corpus de coincidencia de preguntas chinas a gran escala), conjunto de datos Q-Qpair | LCQMC |
| Pawsx | Patas chinas (adversarios parafraseados de la lucha de palabras) conjunto de datos, conjunto de datos Q-Qpair | Pawsx |
| STS-B | Conjunto de datos STS-B chino, conjunto de datos de inferencia de idioma natural chino, conjunto de datos traducido del inglés STS-B al chino | STS-B |
Conjuntos de datos de coincidencia de inglés comúnmente utilizados:
Ejemplo de uso del conjunto de datos:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])producción:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Si usa Text2Vec en su investigación, cite en el siguiente formato:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}El Acuerdo de Licencia es la Licencia APACHE 2.0, que puede usarse con fines comerciales de forma gratuita. Adjunte el enlace y el acuerdo de autorización de Text2Vec a la descripción del producto.
El código del proyecto sigue siendo muy duro. Si ha mejorado el código, puede enviarlo a este proyecto. Antes de enviar, preste atención a los siguientes dos puntos:
testspython -m pytest -v para ejecutar todas las pruebas unitarias, asegurándose de que se pasen todas las pruebas individualesPuede enviar su PR más tarde.


