text2vec
1.2.9
Китайский | Английский | Документы/документы | ? Модели/Модели

Text2VEC : текст на вектор, получите предложения. Текстовая векторизация, характеризует текст (включая слова, предложения и абзацы) как векторная матрица.
Text2VEC реализует различные модели расчета текстовых представлений и сходства текста, такие как Word2VEC, RANKBM25, BERT, предложение-берт, COSENT, и сравнивает влияние каждой модели на задачу текстового семантического сопоставления (расчет сходства).
[2023/09/20] v1.2.9 Версия: поддерживает многокартовый вывод (многопроцессорная реализация мульти-GPU и мульти-CPU), добавляется новый инструмент командной строки (CLI), который может выполнять сценарии, выполнять пакетную текстовую векторизацию. См. Release-V1.2.9 для деталей.
[2023/09/03] v1.2.4 Версия: поддерживает обучение модели флагмбеддирования и выпустила модель подходящей китайской подходящей модели 624/Text2vec-bge-large-chinese, который контролируется и обучается с использованием Cosent Method. Он обучен на основе BAAI/bge-large-zh-noinstruct , а оценка набора данных китайского сопоставления улучшилась по сравнению с исходной моделью. Разница между коротким текстом значительно улучшается. См. Release-V1.2.4 для деталей.
[2023/07/17] V1.2.2 Версия: поддерживает многокартовую обучение и выпустила модель с несколькими языками Shibing624/Text2VEC-Base-MultingLyzenual, которая обучается с использованием Cosent Method. Основываясь на sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 он обучен с использованием ручного многоязычного набора данных STS Shibing624/nli-Zh-all/text2VEC-базой-мультилингвинг-датазет, а оценка в тесте китайского и английского языка улучшила эффект по сравнению с исходной моделью. См. Release-V1.2.2 для деталей.
[2023/06/19] V1.2.1 Версия: китайская подходящая модель shibing624/text2vec-base-chinese-nli обновляется как новая версия Shibing624/Text2VEC-Base-Chinese-Sentence. Основываясь на чувствительности расчета потерь Cosent к сортировке, высококачественный набор данных STS с корреляционной сортировкой был выбран вручную и сортирован, что улучшило производительность каждого набора оценки по сравнению с выполнением; Была выпущена китайская модель Shibing624/Text2VEC-Base-Chinese-Paraphrase для S2P.
[2023/06/15] V1.2.0 Версия: была выпущена китайская подходящая модель Shibing624/Text2VEC-Base-Chinese-NLI. На основе модели nghuyong/ernie-3.0-base-zh используется модель COSENT Text Satching, обученная китайским набором данных NLI Shibing624/NLI_ZH. Производительность в каждом наборе оценки значительно улучшается. См. Release-V1.2.0 для деталей.
[2022/03/12] V1.1.4 Версия: выпускается китайская подходящая модель Shibing624/Text2VEC-Base-Chinese, Cosent Satching Model, обученная на основе китайского обучающего набора STS. См. Release-V1.1.4 для получения подробной информации
Гид
См. Wiki: метод представления текстового вектора для подробного метода представления текстового вектора
Сопоставление текста
| Архи | BaseModel | Модель | АНГЛИЙСКИЙ СТС-Б |
|---|---|---|---|
| Перчатка | щит | AVG_WORD_EMBEDDINGS_GLOVE_6B_300D | 61.77 |
| БЕРТ | Берт-базовая открыта | Bert-Base-Cls | 20.29 |
| БЕРТ | Берт-базовая открыта | Bert-base-first_last_avg | 59,04 |
| БЕРТ | Берт-базовая открыта | Bert-base-first_last_avg-whiten (nli) | 63,65 |
| Сберт | ПРЕДЛОЖЕНИЯ Трансформаторы/BERT-BASE-NLI-MEAN-TOKENS | Sbert-Base-Nli-Cls | 73,65 |
| Сберт | ПРЕДЛОЖЕНИЯ Трансформаторы/BERT-BASE-NLI-MEAN-TOKENS | Sbert-base-nli-first_last_avg | 77.96 |
| Косент | Берт-базовая открыта | COSENT-BASE-FIRST_LAST_AVG | 69,93 |
| Косент | ПРЕДЛОЖЕНИЯ Трансформаторы/BERT-BASE-NLI-MEAN-TOKENS | COSENT-BASE-NLI-FIRST_LAST_AVG | 79,68 |
| Косент | Трансформаторы предложения/перефраза-мультингвинг-минильм-L12-V2 | Shibing624/Text2VEC-Base-MultingLyringual | 80.12 |
| Архи | BaseModel | Модель | Атек | Бк | LCQMC | Pawsx | STS-B | Ав |
|---|---|---|---|---|---|---|---|---|
| Сберт | БЕРТ-Базе-Китайз | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Сберт | HFL/китайская база | Sbert-Macbert-Base | 47.28 | 68.63 | 79,42 | 55,59 | 64,82 | 63,15 |
| Сберт | HFL/Китайский роберта-WWM-Ext | Sbert-Roberta-Ext | 48.29 | 69,99 | 79,22 | 44.10 | 72,42 | 62,80 |
| Косент | БЕРТ-Базе-Китайз | Cosent-Bert-Base | 49,74 | 72,38 | 78.69 | 60.00 | 79,27 | 68.01 |
| Косент | HFL/китайская база | Cosent-Macbert-Base | 50.39 | 72,93 | 79.17 | 60.86 | 79,30 | 68.53 |
| Косент | HFL/Китайский роберта-WWM-Ext | COSENT-ROBERTA-EXT | 50,81 | 71.45 | 79,31 | 61.56 | 79,96 | 68.61 |
иллюстрировать:
SBERT-macbert-base обучена с использованием метода Sbert и запускает примеры/Training_sup_text_matching_model.py код для обучения модели.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 обучены SBERT и представляют собой многоязычную версию модели paraphrase-MiniLM-L12-v2 , поддержка китайского, английского и т. Д.| Архи | BaseModel | Модель | Атек | Бк | LCQMC | Pawsx | STS-B | SOHU-DD | SOHU-DC | Ав | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2VEC | Word2VEC | W2V-Light-Tencent-Chinese | 20.00 | 31.49 | 59,46 | 2.57 | 55,78 | 55,04 | 20,70 | 35,03 | 23769 |
| Сберт | XLM-Roberta-Base | Трансформаторы предложения/перефраза-мультингвинг-минильм-L12-V2 | 18.42 | 38.52 | 63,96 | 10.14 | 78.90 | 63.01 | 52,28 | 46.46 | 3138 |
| Косент | HFL/китайская база | Shibing624/Text2VEC-Base-Chinese | 31.93 | 42,67 | 70.16 | 17.21 | 79,30 | 70.27 | 50.42 | 51.61 | 3008 |
| Косент | HFL/Китай-Лерт-широкий | Ganymedenil/Text2Vec-Large-Chinese | 32,61 | 44,59 | 69,30 | 14.51 | 79,44 | 73.01 | 59,04 | 53,12 | 2092 |
| Косент | Nghuyong/Ernie-3.0-Base-Zh | Shibing624/Text2VEC-Base-Chinese Sentence | 43,37 | 61.43 | 73,48 | 38,90 | 78.25 | 70.60 | 53,08 | 59,87 | 3089 |
| Косент | Nghuyong/Ernie-3.0-Base-Zh | Shibing624/Text2VEC-Base-Chinese-Paraphrase | 44,89 | 63,58 | 74,24 | 40,90 | 78.93 | 76.70 | 63.30 | 63,08 | 3066 |
| Косент | Трансформаторы предложения/перефраза-мультингвинг-минильм-L12-V2 | Shibing624/Text2VEC-Base-MultingLyringual | 32.39 | 50.33 | 65,64 | 32,56 | 74,45 | 68.88 | 51.17 | 53,67 | 3138 |
| Косент | Baai/bge-large-Zh-Noinstruct | Shibing624/Text2Vec-Bge-Large-Chinese | 38.41 | 61.34 | 71.72 | 35,15 | 76.44 | 71.81 | 63,15 | 59,72 | 844 |
иллюстрировать:
shibing624/text2vec-base-chinese модель обучена с использованием COSENT MEDEN, обученной китайским данным STS-B на основе hfl/chinese-macbert-base , и оценивается в китайском наборе тестов STS-B для достижения хороших результатов. Запустите примеры/training_sup_text_matching_model.py код для обучения модели. Файл модели был загружен в HF Model Hub. Рекомендуется использовать задачу общего семантического сопоставления Китая.shibing624/text2vec-base-chinese-sentence обучается с использованием COSENT. Он обучен на основе выбранного вручную китайского набора данных STS Shibing624/nli-ZH-All/Text2VEC- nghuyong/ernie-3.0-base-zh -Chinese-Sentence-Dataset и оценивается в различных китайских тестов NLI для достижения хороших результатов. Запустите примеры/training_sup_text_matching_model_jsonl_data.py код для обучения модели. Файл модели был загружен в HF Model Hub. Рекомендуется использование китайского S2S (предложение против предложения).shibing624/text2vec-base-chinese-paraphrase модель обучена с использованием Cosent Method. Based on the Chinese STS dataset selected by nghuyong/ernie-3.0-base-zh manually, shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset, the dataset is added to s2p (sentence to) relative to shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset. Перефразируя) данные усиливают его длинную способность представления текста и оцениваются для достижения SOTA в различных китайских наборах тестов NLI. Запустите примеры/training_sup_text_matching_model_jsonl_data.py код для обучения модели. Файл модели был загружен в HF Model Hub. Рекомендуется китайская S2P (предложение против абзаца).shibing624/text2vec-base-multilingual Model обучается с использованием COSENT MEDE. Он обучен на основе sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 с использованием выбранного вручную многоязычного набора данных STS Shibing624/nli-ZH-All/Text2Vec-Base-MultingLylingual-Dataset. Он оценивается в тесте Китая и английского языка, и эффект улучшается по сравнению с исходной моделью. Запустите примеры/training_sup_text_matching_model_jsonl_data.py код для обучения модели. Файл модели был загружен в HF Model Hub. Рекомендуется использовать многоязычную семантическую задачу сопоставления.shibing624/text2vec-bge-large-chinese Model обучается с использованием Cosent Method. Он обучен на основе BAAI/bge-large-zh-noinstruct с использованием выбранного вручную китайский набор данных STS Shibing624/nli-Zh-all/text2vec-base-chinese-paraphrase-dataset. Оценка в китайском испытательном наборе улучшила эффект по сравнению с исходной моделью, и разница в коротком тексту значительно улучшается. Запустите примеры/training_sup_text_matching_model_jsonl_data.py код для обучения модели. Файл модели был загружен в HF Model Hub. Рекомендуется использование китайского S2S (предложение против предложения).w2v-light-tencent-chinese -это модель Word2VEC векторов Tencent Word, используемая при загрузке ЦП, подходящая для китайских буквальных задач и холодных запусков отсутствующих данных--model_name hfl/chinese-macbert-base или Роберта Модель: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG и EncoderType.MEAN , и эффекты прогнозирования этих двух очень малы.examples/data и запустить код tests/model_spearman.py, чтобы воспроизвести результаты оценки.Обучение модельной тренировочной эксперимента: экспериментальный отчет
Официальная демонстрация: https://www.mulanai.com/product/short_text_sim/
Demo Guggingface: https://huggingface.co/spaces/shibing624/text2vec

Запустите пример: примеры/gradio_demo.py, чтобы увидеть демонстрацию:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecили
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Вычислить текстовые векторы на основе pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Пример: примеры/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )выход:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings возвращаемого значения тип numpy.ndarray , Shape IS (sentences_size, model_embedding_size) , и вы можете выбрать любую из трех моделей. Первый рекомендуется.shibing624/text2vec-base-chinese модель получается с помощью Cosent Method Training в китайском наборе данных STS-B. Модель была загружена в модель библиотеки HuggingFace Shibing624/Text2VEC-базовая китайца. Это модель по умолчанию, указанная text2vec.SentenceModel . Это может быть вызвано через приведенный выше пример, или его можно вызвать с библиотекой трансформаторов, как показано ниже. Модель будет автоматически загружена на собственный путь: ~/.cache/huggingface/transformersw2v-light-tencent-chinese -это модель Word2VEC, загруженная через Gensim. Слово векторы каждого слова рассчитываются с использованием Tencent Word Vector Tencent_AILab_ChineseEmbedding.tar.gz Вектор предложений усредняется через слово «вектор слов». Модель автоматически загружается на собственный путь: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec поддерживает многокартовый вывод (рассчитайте текстовый вектор): Примеры/Computing_embeddings_multi_gpu_demo.py Без текста2VEC вы можете использовать модель таким образом:
Сначала вы передаете свой ввод через модель трансформатора, затем вы должны применить правильный находки на топ контекстуализированных встроенных слов.
Пример: примеры/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Трансформаторы предложения-популярная библиотека для вычисления плотных векторных представлений для предложений.
Установите предложения-трансформаторы:
pip install -U sentence-transformersЗатем загрузите модель и предсказайте:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word Vector Предоставьте два вектора Word2Vec Word, опционально один:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , Tencent Word Vector Home Page: https://ai.tencent.com/ailab/nlp/zh/index.html Word Vector Загрузить адрес: адрес: адрес: адрес: адрес: адрес: адрес: адрес: адрес: адрес: https://ai.tencent.com/ailab/nlp/en/download.html Подробнее просмотреть Tencent Word VectПоддержка пакета приобретения текстовых векторов
Код: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
бегать:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueВходной файл (требуется):
input.txt, формат: текст предложения одного предложения, одна строка.
Пример: примеры/semantic_text_similality_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))выход:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591Диапазон
scoreзначения сходства косинуса предложения составляет [-1, 1], и чем больше значение, тем больше оно похоже.
Как правило, текст, который наиболее похож на запрос, находится в наборе кандидатов в документ и часто используется для таких задач, как сопоставление сходства вопросов и поиск сходства текста в сценариях QA.
Пример: примеры/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))выход:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Библиотека сходств [Рекомендуется]
Для расчета сходства текста и соответствия текста задач поиска рекомендуется использовать библиотеку сходств, которая совместима с Word2VEC, Sbert и Cosent-подобным семантическим сопоставлением моделей выпуска в этом проекте. Он также поддерживает графические поиски на 100 миллионов и поддерживает текстовую семантическую дедупликацию , дедупликацию изображений и другие функции.
Установка: pip install -U similarities
Расчет сходства предложений:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
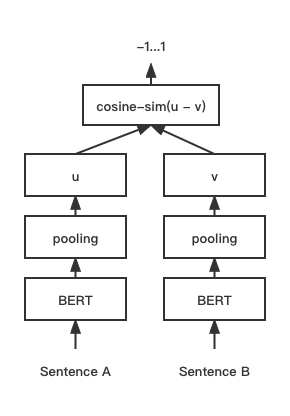
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Cosent (косинусное предложение) модель сопоставления текста, улучшает схему вектора предложений Cosinerankloss на предложении-берте
Структура сети:
Обучение:
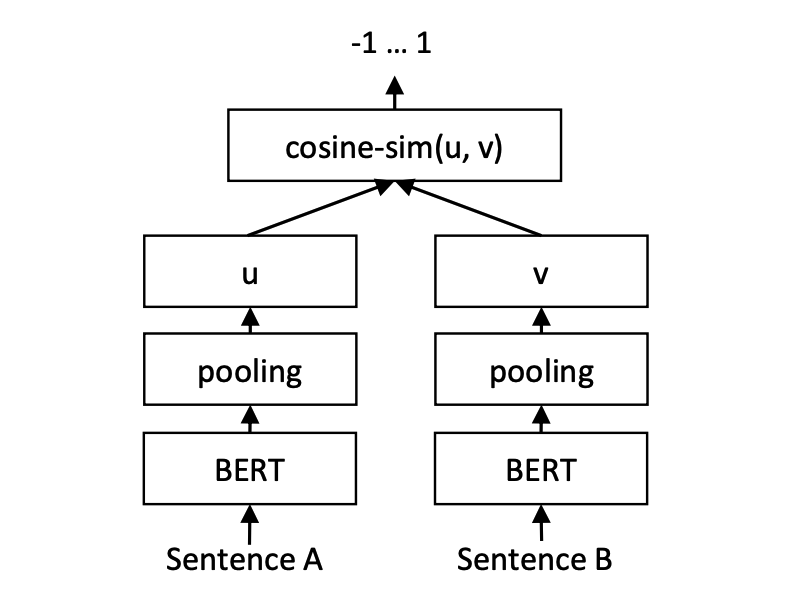
Вывод:
Обучение и прогнозирование Cosent Models:
CoSENT Models на наборе данных китайского STS-BПример: примеры/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT Models на наборе данных ANT Financial Matching ATECПоддержите использование этих наборов данных китайского сопоставления: 'ATEC', 'STS-B', 'BQ', 'LCQMC', 'PAWSX', для получения подробной информации, пожалуйста, см.
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentПример: примеры/training_sup_text_matching_model_mydata.py
ОБУЧЕНИЕ ОДНОГО КАРТА:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictОбучение дока:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Справочные примеры/data/sts-b/sts-b.valid.data для учебного набора формата
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label может быть метки 0 и 1, а 0 означает, что эти два предложения не похожи, а 1 означает аналогичные; Это также может быть оценка 0-5. Чем выше оценка, тем более похожими являются два предложения. Все модели могут быть поддержаны.
CoSENT Models на наборе данных английского STS-BПример: примеры/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT Model в английском наборе данных NLI и оценка эффекта в наборе тестов STS-BПример: примеры/training_unsup_text_matching_model_en.py
cd examples
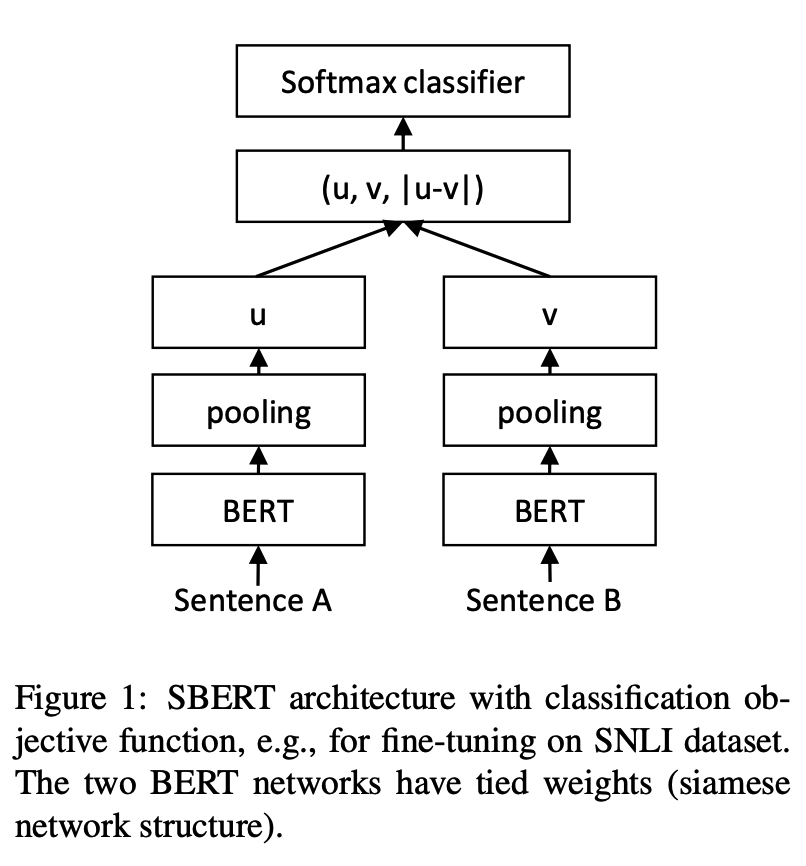
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentМодель сопоставления текста с предложением, схема представления репрезентативного предложения векторного предложения
Структура сети:
Обучение:
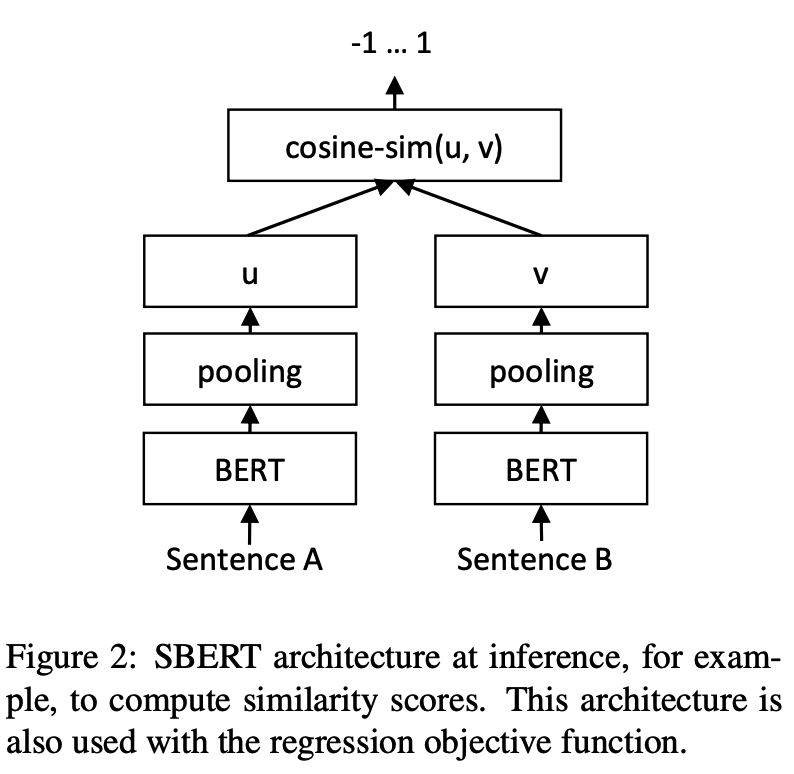
Вывод:
SBERT на наборе данных китайского STS-BПример: примеры/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT на наборе данных английского STS-BПример: примеры/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT на наборе данных английского NLI и оценка эффекта в наборе тестов STS-BПример: примеры/training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertМодель сопоставления текста BERT, Нативная сетевая структура BERT, модель интерактивного вектора предложений.
Структура сети:
Обучение и вывод:
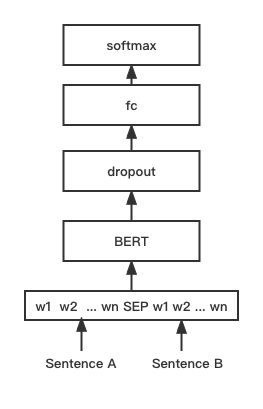
Сценарий обучения такой же, как выше примеры/training_sup_text_matching_model.py.
BGE в китайском наборе данных STS-BПример: примеры/training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGE MODEL TRIN-настройка, используя контрастное обучение для обучения модели, формат входных данных-тройной '(запрос, положительный, отрицательный)'
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py генерирует тройной учебный набор на основе китайского STS-B, с форматом следующим образом: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py использует аналогичный матч, что делает добычу трудным для отрицательных примеров.Поскольку обученные модели Text2VEC могут быть загружены с использованием библиотеки преобразователей предложений, ее метод дистилляции модели здесь мультиплексирован.
Предоставить две модели развертывания и методы для создания услуг: 1) Создание услуг GRPC на основе JINA [Рекомендуется]; 2) Создайте собственные услуги HTTP на основе FASTAPI.
Он использует режим C/S для создания высокопроизводительных служб, поддерживает Docker Cloud Canial, GRPC/HTTP/WebSocket, поддерживает одновременное прогноз нескольких моделей и многокартовой обработки GPU.
Установка: pip install jina
Начните сервис:
Пример: примеры/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()Метод прогнозирования модели (исполнитель) был загружен в Jinahub, включая методы развертывания Docker и K8S.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )См. Пример: Примеры/JINA_CLIENT_DEMO.PY для методов пакетного вызова
Установка: pip install fastapi uvicorn
Начните сервис:
Пример: примеры/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Набор данных | Введение | Скачать ссылку |
|---|---|---|
| Shibing624/nli-Zh-All | Китайский семантический сбор данных сбора данных, интегрируя 8,2 млн. Высококачественных данных для таких задач, как рассуждение текста, сходство, краткое изложение, вопросы и ответ, точная настройка инструкции и преобразованные в набор данных в соответствии с соответствующим форматом | https://huggingface.co/datasets/shibing624/nli-Zh-all |
| Shibing624/snli-Zh | Китайские наборы данных SNLI и Multinli, переведенные с английского SNLI и Multinli | https://huggingface.co/datasets/shibing624/snli-Zh |
| Shibing624/nli_zh | Китайский набор данных с семантическим сопоставлением, интеграция наборов данных из 5 задач, включая ATEC, BQ, LCQMC, PAWSX и STS-B. | https://huggingface.co/datasets/shibing624/nli_zh или Baidu NetDisk (код извлечения: QKT6) или GitHub |
| Shibing624/STS-SOHU2021 | Набор данных китайского семантического сопоставления, 2021 г. Набор данных соревнований в кампусе Sohu | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| Атек | Китайский набор данных ATEC, набор данных Ant Financial Q-QPAIR | Атек |
| Бк | Китайский набор данных BQ (Bank Question), набор данных банка Q-Qpair | Бк |
| LCQMC | Китайский набор данных LCQMC (крупномасштабный набор данных по сопоставлению вопросов), набор данных Q-QPAIR | LCQMC |
| Pawsx | Набор данных китайских лапов (набор данных о перефразировании от Word Scrambling), набор данных Q-QPAIR | Pawsx |
| STS-B | Китайский набор данных STS-B, набор данных по выводу на естественном языке, набор данных, переведенный с английского STS-B на китайский | STS-B |
Обычно используются наборы данных по английскому языку:
Пример использования набора данных:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])выход:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Если вы используете Text2VEC в своем исследовании, укажите его в следующем формате:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}Лицензионное соглашение - это лицензия Apache 2.0, которая может использоваться в коммерческих целях бесплатно. Пожалуйста, прикрепите ссылку и соглашение о разрешении Text2VEC к описанию продукта.
Код проекта все еще очень грубый. Если вы улучшили код, вы можете отправить его обратно в этот проект. Перед отправкой обратите внимание на следующие два балла:
testspython -m pytest -v чтобы запустить все модульные тесты, убедившись, что все отдельные тесты проходятВы можете отправить свой PR позже.


