text2vec
1.2.9
? Chinesisch | Englisch | Dokumente/Dokumente | Modelle/Modelle

Text2VEC : Text an Vektor, Satzeinbettungen erhalten. Textvektorisierung, charakterisiert Text (einschließlich Wörter, Sätze und Absätze) als Vektormatrix.
Text2VEC implementiert eine Vielzahl von Textdarstellungen und Textzeitberechnungsmodellen wie Word2VEC, Rankbm25, Bert, Sätze, Cosent, und vergleicht die Auswirkungen jedes Modells auf die Aufgabe der semantischen Übereinstimmung (Ähnlichkeitsberechnung).
[2023/09/20] V1.2.9 Version: Unterstützt Multi-Card-Inferenz (Multi-Process-Implementierung von Multi-GPU- und Multi-CPU-Inferenz), ein neues Befehlszeilen-Tool (CLI), das Skripte eine Stapeltextvektorisierung durchführen kann. Einzelheiten finden Sie unter Release-V1.2.9.
[2023/09/03] V1.2.4 Version: Unterstützt das Flagembedding-Modelltraining und veröffentlichte das chinesische Matching-Modell Shibing624/Text2VEC-Bge-large-chinese, das mit der Cosent-Methode überwacht und trainiert wird. Es wird auf der Grundlage von BAAI/bge-large-zh-noinstruct ausgebildet, und die chinesische Anpassungsdatensatzbewertung hat sich im Vergleich zum ursprünglichen Modell verbessert. Der Unterschied zwischen kurzem Text ist signifikant verbessert. Einzelheiten finden Sie unter Release-V1.2.4.
[2023/07/17] v1.2.2 Version: Unterstützt das Multi-Card-Training und veröffentlichte das multisprachige Matching-Modell Shibing624/Text2VEC-Base-Multinationual, das mit der Cosent-Methode trainiert wird. Basierend auf sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 wird es mit manuellem Multisprach-STS-Datensatz Shibing624/NLI-Zh-All/text2VEC-Base-Multinierungsdatensatz und die Bewertung des chinesischen und englischen Testsatzes im Vergleich zum ursprünglichen Modell verbessert. Einzelheiten finden Sie unter Release-V1.2.2.
[2023/06/19] V1.2.1 Version: Das chinesische Matching-Modell shibing624/text2vec-base-chinese-nli wird als neue Version von Shibing624/Text2VEC-Base-Chinese-Sentenz aktualisiert. Basierend auf der Empfindlichkeit der Verlustberechnung von Cosent gegenüber Sortierung wurde der hochwertige STS-Datensatz mit Korrelationssortierung manuell ausgewählt und aussortiert, was die Leistung jedes Bewertungssatzes im Vergleich dazu verbessert hat. Das chinesische Matching-Modell Shibing624/text2VEC-Base-Chinese-Paraphrase für S2P wurde veröffentlicht. Weitere Informationen finden Sie in Release-V1.2.1.
[2023/06/15] V1.2.0 Version: Das chinesische Matching-Modell Shibing624/Text2VEC-Base-chinese-nli wurde veröffentlicht. Basierend auf nghuyong/ernie-3.0-base-zh wird das vom chinesischen NLI-Datensatz geschulte Text-Matching-Modell Shibing624/NLI_ZH verwendet. Die Leistung in jedem Bewertungssatz ist erheblich verbessert. Einzelheiten finden Sie unter Release-V1.2.0.
[2022/03/12] V1.1.4 Version: Das chinesische Matching-Modell Shibing624/Text2VEC-Base-Chinese wird veröffentlicht, ein coent-Matching-Modell, das basierend auf dem chinesischen STS-Trainingssatz trainiert wurde. Weitere Informationen finden Sie unter Release-V1.1.4
Führung
Siehe Wiki: Textvektordarstellungsmethode für eine detaillierte Methode zur Darstellung der Textvektordarstellung
Textübereinstimmung
| Bogen | Basemodel | Modell | Englisch-STS-B |
|---|---|---|---|
| Handschuh | Gleve | Avg_word_embeddings_glove_6b_300d | 61.77 |
| Bert | Bert-Base-Unbekannt | Bert-Base-Cls | 20.29 |
| Bert | Bert-Base-Unbekannt | BERT-BASE-FIRST_LAST_AVG | 59.04 |
| Bert | Bert-Base-Unbekannt | Bert-Base-first_last_avg-Whiten (NLI) | 63,65 |
| Sbert | Satztransformer/Bert-Base-NLI-Mean-Tokens | Sbert-Base-NLI-CLS | 73,65 |
| Sbert | Satztransformer/Bert-Base-NLI-Mean-Tokens | Sbert-base-nli-first_last_avg | 77,96 |
| Cosent | Bert-Base-Unbekannt | Cosent-base-first_last_avg | 69,93 |
| Cosent | Satztransformer/Bert-Base-NLI-Mean-Tokens | Cosent-base-nli-first_last_avg | 79,68 |
| Cosent | Satztransformer/Paraphrase-multinellierende Minilm-L12-V2 | Shibing624/text2VEC-Base-multinelling | 80.12 |
| Bogen | Basemodel | Modell | Atec | Bq | LCQMC | Pawsx | STS-B | Avg |
|---|---|---|---|---|---|---|---|---|
| Sbert | Bert-Base-Chinese | Sbert-Tbert-Base | 46.36 | 70.36 | 78,72 | 46,86 | 66.41 | 61.74 |
| Sbert | HFL/Chinese-Macbert-Base | Sbert-Macbert-Base | 47,28 | 68,63 | 79,42 | 55.59 | 64,82 | 63.15 |
| Sbert | HFL/Chinese-Roberta-Wwm-Outd | Sbert-Roberta-opt | 48.29 | 69.99 | 79,22 | 44.10 | 72.42 | 62,80 |
| Cosent | Bert-Base-Chinese | Cosent-Bert-Base | 49,74 | 72.38 | 78,69 | 60.00 | 79,27 | 68.01 |
| Cosent | HFL/Chinese-Macbert-Base | Cosent-Macbert-Base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| Cosent | HFL/Chinese-Roberta-Wwm-Outd | Cosent-Roberta-opt | 50.81 | 71.45 | 79,31 | 61.56 | 79,96 | 68.61 |
veranschaulichen:
SBERT-macbert-base Modell wird unter Verwendung der Sbert-Methode trainiert und wird Beispiele ausführen/Training_SUP_TEXT_MATCHING_MODEL.PY CODE, um das Modell zu trainieren.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 Modell ist mit Sbert trainiert und ist eine mehrsprachige Version paraphrase-MiniLM-L12-v2 Modells, unterstützend Chinesisch, Englisch usw.| Bogen | Basemodel | Modell | Atec | Bq | LCQMC | Pawsx | STS-B | Sohu-dd | Sohu-dc | Avg | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2Vec | Word2Vec | W2V-Light-Tencent-Chinese | 20.00 | 31.49 | 59,46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-Roberta-Base | Satztransformer/Paraphrase-multinellierende Minilm-L12-V2 | 18.42 | 38.52 | 63,96 | 10.14 | 78,90 | 63.01 | 52.28 | 46,46 | 3138 |
| Cosent | HFL/Chinese-Macbert-Base | Shibing624/Text2VEC-Base-Chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70,27 | 50.42 | 51.61 | 3008 |
| Cosent | HFL/Chinese-Lern-Large | Ganymadenil/Text2VEC-Large-Chinese | 32.61 | 44,59 | 69.30 | 14.51 | 79,44 | 73.01 | 59.04 | 53.12 | 2092 |
| Cosent | Nghuyong/Ernie-3.0-Base-Zh | shibing624/text2VEC-Base-chinese-Sentenz | 43.37 | 61.43 | 73,48 | 38.90 | 78,25 | 70.60 | 53.08 | 59,87 | 3089 |
| Cosent | Nghuyong/Ernie-3.0-Base-Zh | Shibing624/Text2VEC-Base-Chinese-Paraphrase | 44,89 | 63,58 | 74.24 | 40.90 | 78,93 | 76,70 | 63.30 | 63.08 | 3066 |
| Cosent | Satztransformer/Paraphrase-multinellierende Minilm-L12-V2 | Shibing624/text2VEC-Base-multinelling | 32.39 | 50.33 | 65.64 | 32.56 | 74,45 | 68,88 | 51.17 | 53,67 | 3138 |
| Cosent | Baai/bge-large-zh-noinstruct | shibing624/text2VEC-BGE-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76,44 | 71.81 | 63.15 | 59.72 | 844 |
veranschaulichen:
shibing624/text2vec-base-chinese Modell wird unter Verwendung der cosent-Methode trainiert, die in chinesischen STS-B-Daten basierend auf hfl/chinese-macbert-base ausgebildet und im chinesischen STS-B-Testsatz bewertet wird, um gute Ergebnisse zu erzielen. Führen Sie die Beispiele/Training_sup_text_matching_model.py Code aus, um das Modell zu trainieren. Die Modelldatei wurde in HF Model Hub hochgeladen. Es wird empfohlen, die chinesische allgemeine semantische Matching -Aufgabe zu verwenden.shibing624/text2vec-base-chinese-sentence wird unter Verwendung der cosente Methode trainiert. Es wird basierend auf dem manuell ausgewählten chinesischen STS-Datensatz Shibing624/NLI-ZH-All/Text2VEC- nghuyong/ernie-3.0-base-zh -Chinese-Sentenzdataset und in verschiedenen chinesischen NLI-Testsätzen bewertet, um gute Ergebnisse zu erzielen. Führen Sie die Beispiele aus/Training_SUP_TEXT_MATCHING_MODEL_JSONL_DATA.PY CODE, um das Modell zu trainieren. Die Modelldatei wurde in HF Model Hub hochgeladen. Die semantische Übereinstimmung der chinesischen S2S (Satz gegen Satz) wird empfohlen, um zu verwendenshibing624/text2vec-base-chinese-paraphrase -Modell wird unter Verwendung der cosente Methode trainiert. Basierend auf dem von nghuyong/ernie-3.0-base-zh manuell ausgewählten chinesischen STS-Datensatz. Paraphrase) Daten stärken die Fähigkeit zur langen Textdarstellung und bewertet, um SOTA in verschiedenen chinesischen NLI -Testsätzen zu erreichen. Ausführen von Beispielen/Training_sup_text_matching_model_jsonl_data.py Code, um das Modell zu trainieren. Die Modelldatei wurde in HF Model Hub hochgeladen. Chinesische S2P (Satz vs Absatz) Semantische Matching -Aufgabe wird empfohlen.shibing624/text2vec-base-multilingual -Modell wird unter Verwendung der cosent-Methode trainiert. Es wird basierend auf sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 unter Verwendung des manuell ausgewählten mehrsprachigen STS-Datensatzes Shibing624/nli-Zh-All/text2VEC-Base-Multinformell-Dataset unter Verwendung der manuell ausgewählten mehrsprachigen STS-Datensatz-Dataset ausgebildet. Es wird im chinesischen und englischen Testsatz bewertet, und der Effekt wird im Vergleich zum ursprünglichen Modell verbessert. Führen Sie die Beispiele aus/Training_SUP_TEXT_MATCHING_MODEL_JSONL_DATA.PY CODE, um das Modell zu trainieren. Die Modelldatei wurde in HF Model Hub hochgeladen. Es wird empfohlen, die mehrsprachige semantische Matching -Aufgabe zu verwenden.shibing624/text2vec-bge-large-chinese Modell wird unter Verwendung der Cosent-Methode trainiert. Es wird basierend auf BAAI/bge-large-zh-noinstruct unter Verwendung des manuell ausgewählten chinesischen STS-Datensatzes Shibing624/NLI-ZH-All/Text2VEC-Base-Chinese-Paraphrase-Datenet ausgebildet. Die Bewertung im chinesischen Testsatz hat den Effekt im Vergleich zum ursprünglichen Modell verbessert, und der Unterschied im kurzen Text ist signifikant verbessert. Führen Sie die Beispiele aus/Training_SUP_TEXT_MATCHING_MODEL_JSONL_DATA.PY CODE, um das Modell zu trainieren. Die Modelldatei wurde in HF Model Hub hochgeladen. Die semantische Übereinstimmung der chinesischen S2S (Satz gegen Satz) wird empfohlen, um zu verwendenw2v-light-tencent-chinese ist ein Word2VEC-Modell von Tencent-Wortvektoren, das durch CPU-Laden verwendet wird und für chinesische buchstäbliche Matching-Aufgaben und kalte Startsituationen fehlender Daten geeignet ist--model_name hfl/chinese-macbert-base oder Roberta Modell: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG und EncoderType.MEAN ist, und die Vorhersageeffekte der beiden sind sehr gering.examples/data herunterladen und die Tests/model_spearman.py -Code ausführen, um die Bewertungsergebnisse zu reproduzieren.Modelltraining Experimentaler Bericht: Experimenteller Bericht
Offizielle Demo: https://www.mulanai.com/product/short_text_sim/
Huggingface Demo: https://huggingface.co/spaces/shibing624/text2Vec

Beispiel ausführen: Beispiele/gradio_demo.py, um die Demo zu sehen:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecoder
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Berechnen Sie Textvektoren basierend auf pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Beispiel: Beispiele/Computing_Embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )Ausgabe:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
numpy.ndarray embeddings Form ist (sentences_size, model_embedding_size) , und Sie können eines der drei Modelle auswählen. Der erste wird empfohlen.shibing624/text2vec-base-chinese Modell wird durch das cosent-Methode-Training im chinesischen STS-B-Datensatz erhalten. Das Modell wurde in die Modellbibliothek von Huggingface Shibing624/Text2VEC-Base-Chinese hochgeladen. Es ist das Standardmodell, das von text2vec.SentenceModel angegeben ist. Es kann durch das obige Beispiel aufgerufen werden oder wie unten gezeigt mit der Transformers Library aufgerufen werden. Das Modell wird automatisch auf den nativen Pfad heruntergeladen: ~/.cache/huggingface/transformersw2v-light-tencent-chinese ist ein Word2VEC-Modell, das durch Gensim geladen wird. Die Wortvektoren jedes Wortes werden unter Verwendung des Tencent Word Vector Tencent_AILab_ChineseEmbedding.tar.gz Der Satzvektor wird durch den Wort Wortvektor gemittelt. Das Modell wird automatisch auf den nativen Pfad heruntergeladen: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec unterstützt Multi-Card-Inferenz (Textvektor berechnen): Beispiele/computer-_embeddings_multi_gpu_demo.py Ohne Text2VEC können Sie das Modell wie dieses verwenden:
Zuerst übergeben Sie Ihre Eingabe über das Transformatormodell, dann müssen Sie die richtige Pooling-Operation auf dem kontextualisierten Worteinbettungen anwenden.
Beispiel: Beispiele/USE_ORIGIN_TRANSFORMERS_DEMO.PY
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Satztransformer ist eine beliebte Bibliothek, in der dichte Vektor-Darstellungen für Sätze berechnet werden.
Satztransformatoren installieren:
pip install -U sentence-transformersDann laden Sie das Modell und prognostizieren Sie:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word Vector Geben Sie zwei Word2Vec -Wortvektoren an, optional eine:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin Download.~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , Tencent Word Vector Startseite: https://ai.tencent.com/ailab/nlp/zh/index.html Word -Download -Adresse: https://ai.tencent.com/ailab/nlp/en/download.html Weitere Ansicht Tencent Word Vector Einführung-wikiUnterstützen Sie die Batch -Erwerb von Textvektoren
Code: Cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
laufen:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueEingabedatei (erforderlich):
input.txt, Format: Satztext eines Satzes, einer Zeile.
Beispiel: Beispiele/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))Ausgabe:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591Der
scoredes Gesamtwerts Cosinus-Ähnlichkeit ist [-1, 1] und je größer der Wert ist, desto ähnlicher ist er.
Im Allgemeinen finden Sie im Dokumentenkandidatensatz einen Text, der der Abfrage am ähnlichsten ist, und wird häufig für Aufgaben wie Fragen der Fragen der Fragen und der Abrufheit der Textähnlichkeit in QA -Szenarien verwendet.
Beispiel: Beispiele/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))Ausgabe:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Ähnlichkeitsbibliothek [Empfohlen]
Für die Berechnung der Textzugs und die Suchaufgaben von Textanpassungen wird empfohlen, die Ähnlichkeitsbibliothek zu verwenden, die mit den Word2VEC-, Sbert- und Cosent-ähnlichen semantischen Matching-Modellen der Veröffentlichung in diesem Projekt kompatibel ist. Es unterstützt auch eine grafische Suche in 100 Millionen Ebenen und unterstützt die semantische Deduplizierung von Text , Bilddeduplizierung und andere Funktionen.
Installation: pip install -U similarities
Satz Ähnlichkeitsberechnung:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 COSENT (Cosinus Sätze) Textübereinstimmungsmodell verbessert das Satz Vektorschema von Cosinanklos
Netzwerkstruktur:
Ausbildung:
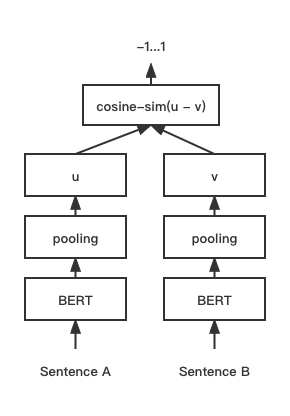
Schlussfolgerung:
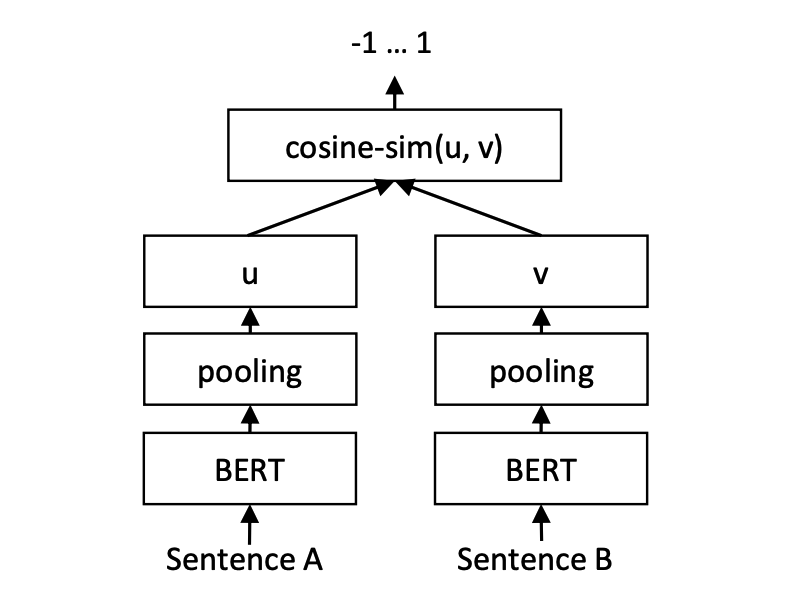
Training und Vorhersage von kosentischen Modellen:
CoSENT -Modellen im chinesischen STS-B-DatensatzBeispiel: Beispiele/Training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT -Modellen in der ANT -Finanzdatensatz -ATEC ATECUnterstützen Sie die Verwendung dieser chinesischen passenden Datensätze: 'ATEC', 'STS-B', 'BQ', 'LCQMC', 'PAWSX'. Weitere Informationen finden Sie unter den Datensätzen von Suggingface https://huggingface.co/datasets/Shibing624/nli_zhhhhhggingface.co/Datasets/Shibing624/nli_zhhhhhggingface.co/Datasets/Shibing624/nli_zhhhhhggingface.co/Datasets/Shibing624/nli_zhhhhhggingface.co/datasets
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentBeispiel: Beispiele/Training_sup_text_matching_model_mydata.py
Einzelkartentraining:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictDoka Training:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Referenzbeispiele/Daten/STS-B/STS-B.VALID.DATA für das Trainingssatzformat
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label kann Etiketten 0 und 1 sein, und 0 bedeutet, dass die beiden Sätze nicht ähnlich sind und 1 ähnlich ist; Es kann auch eine Punktzahl von 0-5 sein. Je höher die Punktzahl, desto ähnlicher sind die beiden Sätze. Alle Modelle können unterstützt werden.
CoSENT -Modellen im englischen STS-B-DatensatzBeispiel: Beispiele/Training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT Modell im englischen NLI-Datensatz und Bewertung des Effekts im STS-B-TestsatzBeispiel: Beispiele/Training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentModellpassungsmodell für Satzbericht, Repräsentation der Repräsentation des Repräsentation von Satz Vektor
Netzwerkstruktur:
Ausbildung:
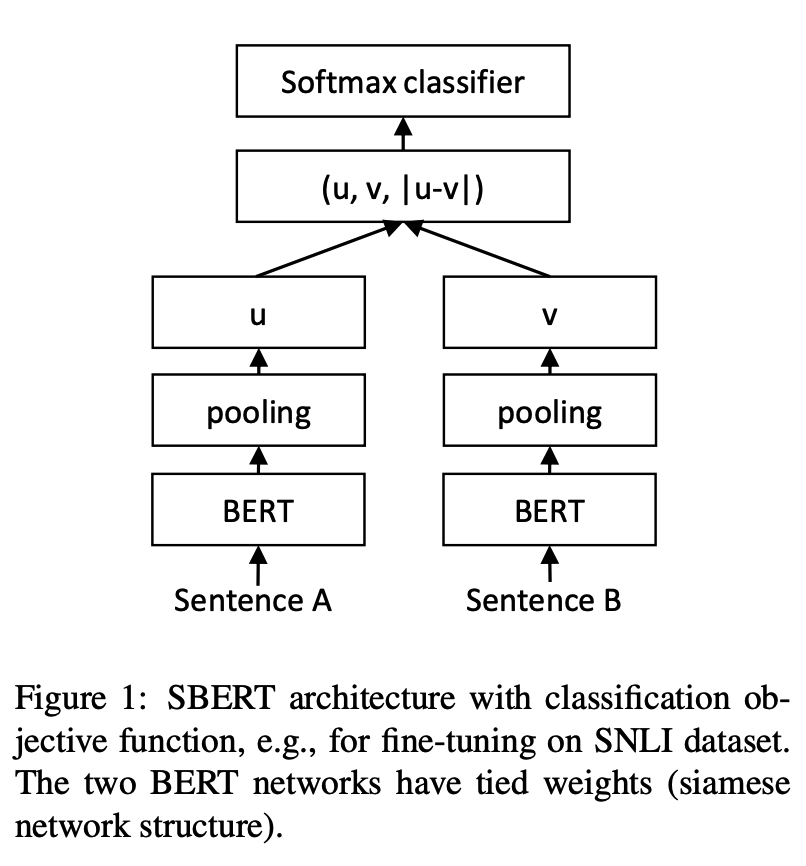
Schlussfolgerung:
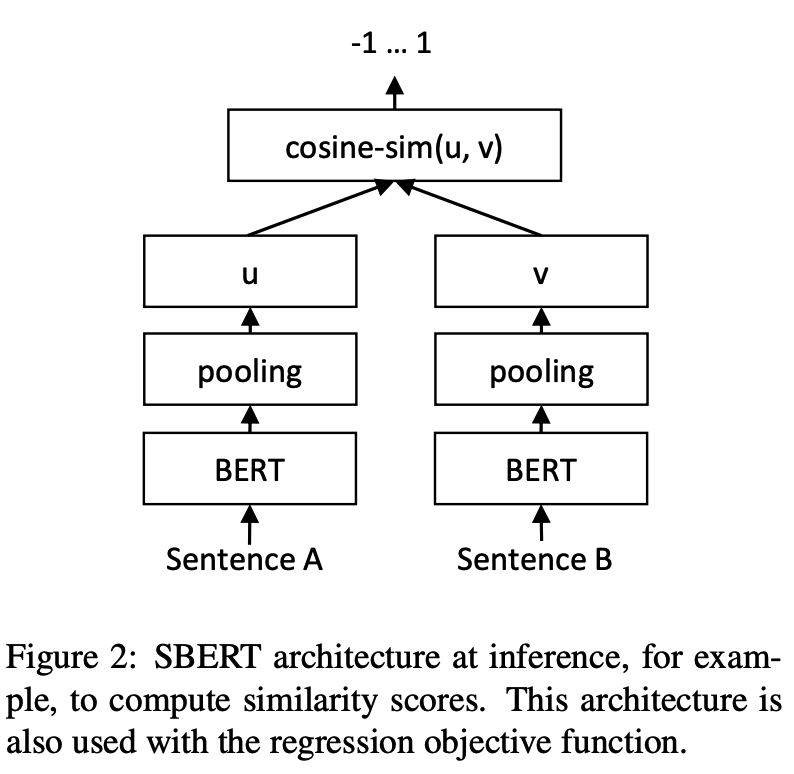
SBERT -Modellen im chinesischen STS-B-DatensatzBeispiel: Beispiele/Training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT -Modellen auf dem englischen STS-B-DatensatzBeispiel: Beispiele/Training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT -Modell im englischen NLI-Datensatz und Bewertung des Effekts im STS-B-TestsatzBeispiel: Beispiele/Training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertBert Text Matching -Modell, native Bert -Matching -Netzwerkstruktur, interaktiver Satz Vektorübereinstimmungsmodell
Netzwerkstruktur:
Training und Inferenz:
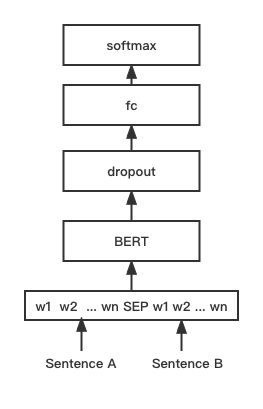
Das Trainingsskript entspricht den oben genannten Beispielen/Training_sup_text_matching_model.py.
BGE -Modellen im chinesischen STS-B-DatensatzBeispiel: Beispiele/Training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGE-Modell Feinabstimmungstraining unter Verwendung des Kontrastlernens zum Training des Modells, das Format der Eingabedaten ist ein dreifaches '(Abfrage, positiv, negativ)'.
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py generiert ein dreifaches Trainingssatz, das auf chinesischem STS-B basiert, mit dem Format wie folgt: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py verwendet eine ähnliche Übereinstimmung, wodurch das Bergbau zu negativen Beispielen schwierig ist.Da die geschulten Modelle von Text2VEC unter Verwendung der Satz-Transformatoren-Bibliothek geladen werden können, wird die Modelldestillationsmethode hier multiplexiert.
Bereitstellung von zwei Bereitstellungsmodellen und -methoden zum Erstellen von Diensten: 1) Basis von GRPC -Diensten basierend auf Jina [empfohlen]; 2) Erstellen Sie native HTTP -Dienste basierend auf Fastapi.
Der C/S-Modus erstellt Hochleistungsdienste, unterstützt Docker Cloud Native, GRPC/HTTP/WebSocket, unterstützt die gleichzeitige Vorhersage mehrerer Modelle und GPU-Multi-Card-Verarbeitung.
Installieren: pip install jina
Starten Sie den Service:
Beispiel: Beispiele/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()Die Modellvorhersagemethode (Executor) wurde auf Jinahub hochgeladen, einschließlich Docker- und K8S -Bereitstellungsmethoden.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )Siehe Beispiel: Beispiele/jina_client_demo.py für Stapelaufrufmethoden
Installieren: pip install fastapi uvicorn
Starten Sie den Service:
Beispiel: Beispiele/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Datensatz | Einführung | Link herunterladen |
|---|---|---|
| Shibing624/nli-zh-All | Chinesische semantische Übereinstimmungsdatenerfassung, integriert 8,2 Millionen hochwertige Daten für Aufgaben wie Textzüge, Ähnlichkeit, Zusammenfassung, Frage und Antwort, Befehlsgabeinstellung und konvertiert in den Datensatz für den Matching-Format | https://huggingface.co/datasets/shibing624/nli-zh-all |
| Shibing624/snli-zh | Chinesische SNLI- und Multinli -Datensätze, übersetzt aus englischer SNLI und Multinli | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624/nli_zh | Chinesische semantische Übereinstimmungsdatensatz, die Datensätze von 5 Aufgaben integrieren, darunter ATEC, BQ, LCQMC, PAWSX und STS-B. | https://huggingface.co/datasets/shibing624/nli_zh oder Baidu NetDisk (Extraktionscode: Qkt6) oder Github |
| Shibing624/STS-SOHU2021 | Chinesischer semantischer Übereinstimmungsdatensatz, 2021 Sohu Campus Text Matching Algorithmus Wettbewerbs Datensatz | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| Atec | Chinesischer ATEC-Datensatz, Ant-Finanz-Q-Qpair-Datensatz | Atec |
| Bq | Chinesischer BQ (Bankfrage) Datensatz, Bank Q-Qpair-Datensatz | Bq |
| LCQMC | Chinesischer LCQMC (groß an | LCQMC |
| Pawsx | Chinesische Pfoten (Paraphrase-Gegner aus dem Wort Scrambling) Datensatz, Q-Qpair-Datensatz | Pawsx |
| STS-B | Chinesischer STS-B-Datensatz, chinesischer Datensatz für natürliche Sprache, Datensatz von English STS-B auf Chinesisch übersetzt | STS-B |
Häufig verwendete englisch -passende Datensätze:
Beispiel für die Datensatzverwendung:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])Ausgabe:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Wenn Sie Text2Vec in Ihrer Forschung verwenden, zitieren Sie es bitte im folgenden Format:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}Die Lizenzvereinbarung ist die Apache -Lizenz 2.0, die für kommerzielle Zwecke kostenlos verwendet werden kann. Bitte fügen Sie die Link- und Autorisierungsvereinbarung von Text2VEC der Produktbeschreibung bei.
Der Projektcode ist immer noch sehr rau. Wenn Sie den Code verbessert haben, können Sie ihn gerne an dieses Projekt einreichen. Achten Sie vor der Einreichung auf die folgenden zwei Punkte:
testspython -m pytest -v um alle Einheitstests durchzuführen und sicherzustellen, dass alle einzelnen Tests bestanden werdenSie können Ihre PR später einreichen.


