text2vec
1.2.9
?? Chinois | Anglais | Documents / Docs | ? Modèles / modèles

Text2Vec : texte vers vector, obtenir des incorporations de phrases. Vectorisation de texte, caractérise le texte (y compris les mots, les phrases et les paragraphes) comme une matrice vectorielle.
Text2VEC met en œuvre une variété de modèles de calcul de représentation de texte et de similitude de texte tels que Word2Vec, RANKBM25, Bert, phrase-bert, Cosent, et compare les effets de chaque modèle sur la tâche de correspondance sémantique de texte (calcul de similitude).
[2023/09/20] V1.2.9 Version: prend en charge l'inférence multi-cartes (implémentation multi-processus de l'inférence multi-GPU et multi-CPU), un nouvel outil de ligne de commande (CLI) est ajouté, qui peut les scripts effectuer une vectorisation de texte par lots. Voir version-V1.2.9 pour plus de détails.
[2023/09/03] V1.2.4 Version: prend en charge la formation du modèle Flakemedding et a publié le modèle de correspondance chinois Shibing624 / Text2Vec-Bge-Large-chinois, qui est supervisé et formé à l'aide de la méthode Cosent. Il est formé sur la base de BAAI/bge-large-zh-noinstruct , et l'évaluation des ensembles de données de correspondance chinoise s'est améliorée par rapport au modèle d'origine. La différence entre le texte court est considérablement améliorée. Voir version-V1.2.4 pour plus de détails.
[2023/07/17] V1.2.2 Version: prend en charge la formation multi-cartes et a publié le modèle de correspondance multi-langue Shibing624 / Text2Vec-Base-Muliling, qui est formé à l'aide de la méthode Cosent. Sur la base sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 il est formé à l'aide de Shibing 624 / Nli-Zh-All / Text2Vec-Base-Base-Mulilingual, et l'évaluation de l'ensemble de test chinois et anglais a impliqué l'effet par rapport au modèle d'origine. Voir version-V1.2.2 pour plus de détails.
[2023/06/19] V1.2.1 Version: Le modèle de correspondance chinois shibing624/text2vec-base-chinese-nli est mis à jour comme la nouvelle version de Shibing624 / Text2Vec-Base-Chinese-Sentence. Sur la base de la sensibilité du calcul de la perte de Cosent au tri, l'ensemble de données STS de haute qualité avec le tri de corrélation a été sélectionné manuellement et trié, ce qui a amélioré les performances de chaque ensemble d'évaluation par rapport à cela; Le modèle de correspondance chinois Shibing624 / Text2Vec-Base-Chinese-Paraphrase pour S2P a été publié, voir la version-V1.2.1 pour plus de détails.
[2023/06/15] V1.2.0 Version: Le modèle de correspondance chinois Shibing624 / Text2Vec-Base-Chinese-NLI a été publié. Sur la base nghuyong/ernie-3.0-base-zh , le modèle de correspondance de texte Cosent formé par le jeu de données NLI chinois Shibing624 / NLI_ZH est utilisé. Les performances de chaque ensemble d'évaluation sont considérablement améliorées. Voir version-V1.2.0 pour plus de détails.
[2022/03/12] V1.1.4 Version: Le modèle de correspondance chinois Shibing624 / Text2Vec-Base-Chinese est publié, un modèle de correspondance Cosent formé basé sur l'ensemble de formation chinois STS. Voir version-v1.1.4 pour plus de détails
Guide
Voir Wiki: Méthode de représentation du vecteur de texte pour la méthode détaillée de la représentation du vecteur de texte
Correspondance de texte
| Cambre | Model de base | Modèle | Anglais-STS-B |
|---|---|---|---|
| Gant | joie | Avg_word_embeddings_glove_6b_300d | 61.77 |
| Bert | bert-base | Bert-base-CLS | 20.29 |
| Bert | bert-base | Bert-Base-First_last_avg | 59.04 |
| Bert | bert-base | Bert-Base-First_last_avg-Whiten (NLI) | 63.65 |
| Sbert | Transformateurs de phrase / Bert-Base-Nli-Mean-Tokens | Sbert-bass-nli-cls | 73.65 |
| Sbert | Transformateurs de phrase / Bert-Base-Nli-Mean-Tokens | Sbert-bass-nli-First_last_avg | 77,96 |
| Cosenti | bert-base | Cosent-Base-First_last_avg | 69,93 |
| Cosenti | Transformateurs de phrase / Bert-Base-Nli-Mean-Tokens | Cosent-Base-NLI-First_last_avg | 79.68 |
| Cosenti | Transformateurs de phrase / paraphrase-multitilingual-minimm-l12-v2 | shibing624 / text2vec-base-multitilingue | 80.12 |
| Cambre | Model de base | Modèle | Atec | Bq | LCQMC | Pawsx | STS-B | AVG |
|---|---|---|---|---|---|---|---|---|
| Sbert | bert-bassin-chinois | Base sbert-bert | 46.36 | 70.36 | 78,72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL / Chinese-Macbert-base | Sbert-Macbert-base | 47.28 | 68,63 | 79.42 | 55,59 | 64.82 | 63.15 |
| Sbert | HFL / Chinese-Roberta-WWM-EXT | Sbert-Roberta-EXT | 48.29 | 69,99 | 79.22 | 44.10 | 72.42 | 62.80 |
| Cosenti | bert-bassin-chinois | Cosent-Bert-base | 49,74 | 72.38 | 78,69 | 60,00 | 79.27 | 68.01 |
| Cosenti | HFL / Chinese-Macbert-base | Cosent-Macbert-base | 50.39 | 72.93 | 79.17 | 60,86 | 79.30 | 68,53 |
| Cosenti | HFL / Chinese-Roberta-WWM-EXT | Cosent-Roberta-EXT | 50.81 | 71.45 | 79.31 | 61,56 | 79.96 | 68.61 |
illustrer:
SBERT-macbert-base est formé à l'aide de la méthode SBERT et exécutez des exemples / Training_Sup_Text_Matching_Model.py Code pour former le modèle.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 est formé avec SBERT, et est une version multilingue du modèle paraphrase-MiniLM-L12-v2 , soutenant chinois, anglais, etc.| Cambre | Model de base | Modèle | Atec | Bq | LCQMC | Pawsx | STS-B | Sohu-dd | Sohu-dc | AVG | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2vec | word2vec | W2V-Light-Tencent-chinois | 20h00 | 31.49 | 59.46 | 2.57 | 55,78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-Roberta-base | Transformateurs de phrase / paraphrase-multitilingual-minimm-l12-v2 | 18.42 | 38,52 | 63.96 | 10.14 | 78,90 | 63.01 | 52.28 | 46.46 | 3138 |
| Cosenti | HFL / Chinese-Macbert-base | shibing624 / text2vec-bas-chinois | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| Cosenti | HFL / Lert-Lert-Lert | Ganymedenil / text2vec-chinois | 32.61 | 44,59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| Cosenti | nghuyong / ernie-3.0-bas-zh | Shibing624 / Text2Vec-Base-Chinese-Sentence | 43.37 | 61.43 | 73.48 | 38,90 | 78.25 | 70,60 | 53.08 | 59.87 | 3089 |
| Cosenti | nghuyong / ernie-3.0-bas-zh | shibing624 / text2vec-bas-chinois-paraphrase | 44.89 | 63,58 | 74.24 | 40.90 | 78,93 | 76.70 | 63.30 | 63.08 | 3066 |
| Cosenti | Transformateurs de phrase / paraphrase-multitilingual-minimm-l12-v2 | shibing624 / text2vec-base-multitilingue | 32.39 | 50.33 | 65.64 | 32,56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| Cosenti | Baai / bge-Large-zh-noinstruct | shibing624 / text2vec-bge-chinois | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59,72 | 844 |
illustrer:
shibing624/text2vec-base-chinese est formé à l'aide de la méthode Cosent, formé aux données chinoises STS-B basée sur hfl/chinese-macbert-base et évaluée dans un ensemble de tests STS-B chinois pour obtenir de bons résultats. Exécutez les exemples / formation_sup_text_matching_model.py code pour former le modèle. Le fichier modèle a été téléchargé sur HF Model Hub. Il est recommandé d'utiliser la tâche de correspondance sémantique générale chinoise.shibing624/text2vec-base-chinese-sentence Le modèle est formé à l'aide de la méthode Cosent. Il est formé sur la base du jeu de données STS chinois sélectionné manuellement 624 / NLI-ZH-ALL / Text2Vec- nghuyong/ernie-3.0-base-zh -chinese-Sentence-Dataset, et est évalué dans divers ensembles de tests NLI chinois pour obtenir de bons résultats. Exécutez les exemples / formation_sup_text_matching_model_jsonl_data.py Code pour former le modèle. Le fichier modèle a été téléchargé sur HF Model Hub. La tâche de correspondance sémantique S2S chinoise (phrase vs phrase) est recommandée pour utilisershibing624/text2vec-base-chinese-paraphrase est formé à l'aide de la méthode Cosent. Sur la base de l'ensemble de données chinois STS sélectionné par nghuyong/ernie-3.0-base-zh manuellement, Shibing624 / Nli-Zh-ALL / Text2Vec-Base-Chinese-paraphrase-dataset, l'ensemble de données est ajouté à S2P (phrase à) par rapport à Shibing624 / Nli-Zh-ALL / Text2Vec-Base-Chinese-Sentet. Paraphrase) Les données renforcent sa longue capacité de représentation de texte et évalue pour atteindre SOTA dans divers ensembles de tests NLI chinois. Exécutez des exemples / Training_Sup_Text_Matching_Model_Jsonl_Data.py Code pour former le modèle. Le fichier modèle a été téléchargé sur HF Model Hub. S2P chinois (phrase vs paragraphe) La tâche de correspondance sémantique est recommandée.shibing624/text2vec-base-multilingual est formé à l'aide de la méthode Cosent. Il est formé sur la base sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 en utilisant le jeu de données STS multilingue sélectionné manuellement 624 / nli-zh-all / text2vec-base-multitiling-dataset. Il est évalué dans l'ensemble de tests chinois et anglais, et l'effet est amélioré par rapport au modèle d'origine. Exécutez les exemples / formation_sup_text_matching_model_jsonl_data.py Code pour former le modèle. Le fichier modèle a été téléchargé sur HF Model Hub. Il est recommandé d'utiliser la tâche de correspondance sémantique multilingue.shibing624/text2vec-bge-large-chinese est formé à l'aide de la méthode Cosent. Il est formé sur la base de BAAI/bge-large-zh-noinstruct en utilisant le jeu de données STS chinois manuellement sélectionné 624 / NLI-ZH-ALL / Text2Vec-Base-Chinese-Paraphrase-Dataset. L'évaluation de l'ensemble de test chinois a amélioré l'effet par rapport au modèle d'origine, et la différence de texte court est considérablement améliorée. Exécutez les exemples / formation_sup_text_matching_model_jsonl_data.py Code pour former le modèle. Le fichier modèle a été téléchargé sur HF Model Hub. La tâche de correspondance sémantique S2S chinoise (phrase vs phrase) est recommandée pour utiliserw2v-light-tencent-chinese est un modèle Word2Vec de vecteurs de mot Tencent, utilisé par le chargement du processeur, adapté aux tâches de correspondance littérale chinoise et aux situations de démarrage à froid des données manquantes--model_name hfl/chinese-macbert-base ou Roberta Modèle: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG et EncoderType.MEAN , et les effets de prédiction des deux sont très petits.examples/data et exécuter le code Tests / Model_Spearman.py pour reproduire les résultats de l'évaluation.Rapport expérimental de formation modèle: rapport expérimental
Demo officiel: https://www.mulanai.com/product/short_text_sim/
HuggingFace Demo: https://huggingface.co/spaces/shibing624/text2vec

Exemple d'exécution: Exemples / gradio_demo.py pour voir la démo:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecou
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Calculez des vecteurs de texte basés sur pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Exemple: Exemples / Computing_embedings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )sortir:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings est de type numpy.ndarray , la forme est (sentences_size, model_embedding_size) , et vous pouvez choisir l'un des trois modèles. Le premier est recommandé.shibing624/text2vec-base-chinese est obtenu par la formation de la méthode Cosent dans l'ensemble de données STS-B chinois. Le modèle a été téléchargé dans la bibliothèque de modèles de Huggingface Shibing624 / Text2Vec-Base-Chinese. Il s'agit du modèle par défaut spécifié par text2vec.SentenceModel . Il peut être appelé via l'exemple ci-dessus, ou il peut être appelé avec la bibliothèque Transformers comme indiqué ci-dessous. Le modèle sera automatiquement téléchargé sur le chemin natif: ~/.cache/huggingface/transformersw2v-light-tencent-chinese est un modèle Word2Vec chargé via Gensim. Le mot vecteurs de chaque mot est calculé à l'aide du Vector Tencent Vector Tencent_AILab_ChineseEmbedding.tar.gz Le vecteur de phrase est moyenné par le mot de mot vecteur de mot. Le modèle est automatiquement téléchargé sur le chemin natif: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec prend en charge l'inférence multi-cartes (calculer le vecteur de texte): Exemples / Computing_embedings_multi_gpu_demo.py Sans Text2Vec, vous pouvez utiliser le modèle comme ceci:
Tout d'abord, vous transmettez votre entrée via le modèle de transformateur, vous devez ensuite appliquer la bonne opération de mise en commun des intégres de mot contextualisés.
Exemple: Exemples / use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Les transformateurs de phrase sont une bibliothèque populaire pour calculer les représentations de vecteur denses pour les phrases.
Installez les transformateurs de phrase:
pip install -U sentence-transformersPuis chargez le modèle et prédire:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Fournissez deux vecteurs Word2Vec Word, éventuellement un:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , Tencent Word Vector Home Page: https://ai.tencent.com/ailab/nlp/zh/index.html Vector de téléchargement de téléchargement: Adresse: https://ai.tencent.com/ailab/nlp/en/download.html More View Tencent Word Vector Introduction-WikiPrise en charge l'acquisition par lots de vecteurs de texte
Code: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
courir:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueFichier d'entrée (requis):
input.txt, format: texte de phrase d'une phrase, une ligne.
Exemple: Exemples / SEMANTIC_Text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))sortir:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591La plage
scorede la valeur de similitude du cosinus de la phrase est [-1, 1] et plus la valeur est grande, plus elle est similaire.
Généralement, le texte qui est le plus similaire à la requête se trouve dans l'ensemble de candidats de document, et est souvent utilisé pour des tâches telles que la correspondance de similitude de questions et la récupération de similitude du texte dans les scénarios QA.
Exemple: Exemples / SEMANTIC_SEARCH_DEMO.PY
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))sortir:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Bibliothèque de similitudes [recommandée]
Pour le calcul de la similitude du texte et les tâches de recherche de correspondance de texte, il est recommandé d'utiliser la bibliothèque de similitudes, qui est compatible avec les modèles de publication de la publication Word2Vec, Sbert et Cosent. Il prend également en charge les recherches graphiques de 100 millions de millions et prend en charge la déduplication sémantique de texte , la déduplication d'image et d'autres fonctions.
Installation: pip install -U similarities
Calcul de la similitude des phrases:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Modèle de correspondance de texte Cosent (phrase en cosinus), améliore le programme de vecteur de phrase de Cosinerankloss sur la phrase-BERT
Structure du réseau:
Entraînement:
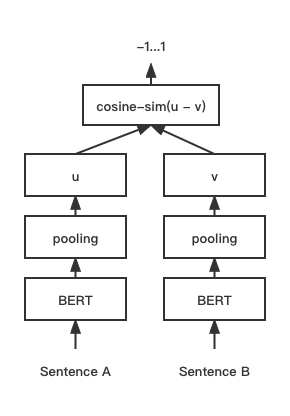
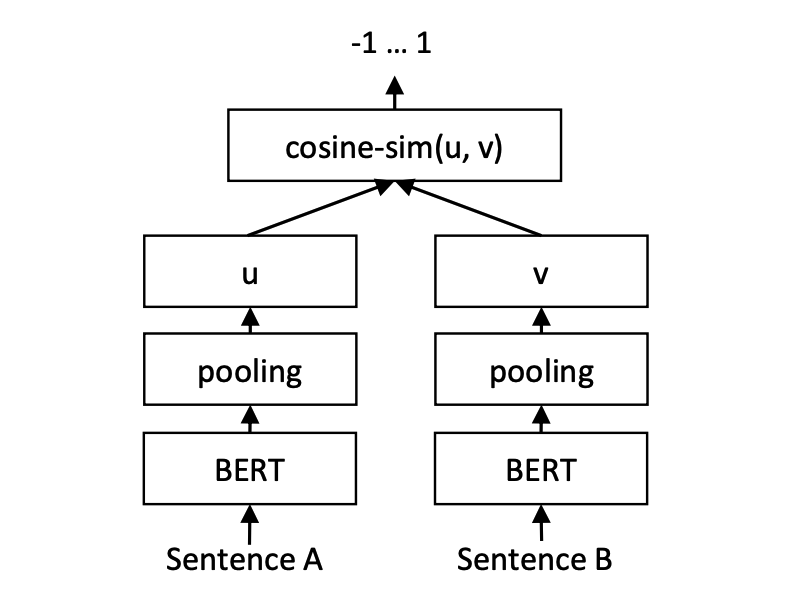
Inférence:
Formation et prédiction des modèles cosentifs:
CoSENT sur l'ensemble de données STS-B chinoisExemple: Exemples / Training_Sup_Text_Matching_Model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT sur l'ensemble de données de correspondance financière ATECPrise en charge de l'utilisation de ces ensembles de données de correspondance chinoises: 'ATEC', 'STS-B', 'BQ', 'LCQMC', 'PAWSX', Pour plus de détails, veuillez vous référer aux ensembles de données HuggingFace https://huggingface.co/datasets/shibing624/nli_zh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentExemple: Exemples / Training_Sup_Text_Matching_Model_Mydata.py
Formation par carte unique:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictFormation DAKA:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Exemples de référence / données / STS-B / STS-B.Valid.Data pour le format de l'ensemble de formation
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label peut être des étiquettes 0 et 1, et 0 signifie que les deux phrases ne sont pas similaires, et 1 signifie similaire; Il peut également s'agir d'un score de 0-5. Plus le score est élevé, plus les deux phrases sont similaires. Tous les modèles peuvent être pris en charge.
CoSENT sur l'ensemble de données STS-B anglaisExemple: Exemples / Training_Sup_Text_Matching_Model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT dans l'ensemble de données NLI anglais et évaluation de l'effet dans l'ensemble de tests STS-BExemple: exemples / formation_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentModèle d'appariement de texte de phrase, schéma de représentation de vecteur de phrase représentatif
Structure du réseau:
Entraînement:
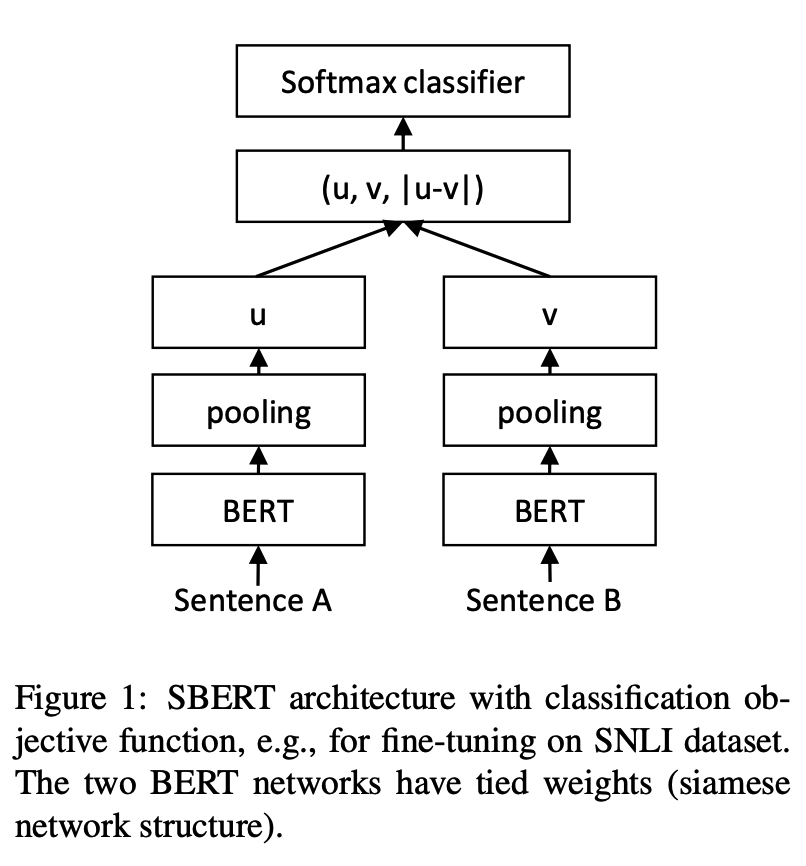
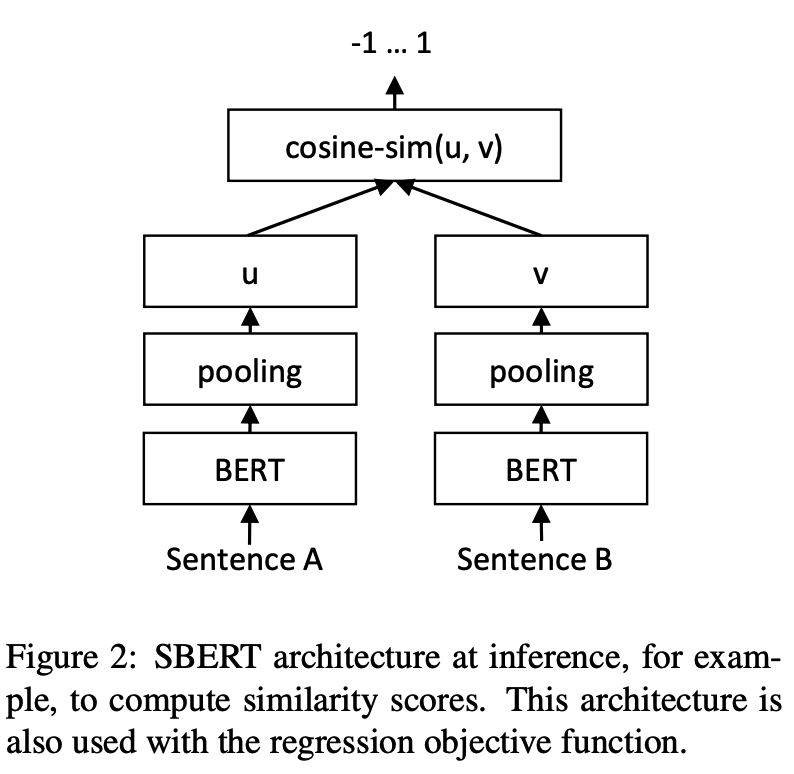
Inférence:
SBERT sur l'ensemble de données STS-B chinoisExemple: Exemples / Training_Sup_Text_Matching_Model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT sur l'ensemble de données STS-B anglaisExemple: Exemples / Training_Sup_Text_Matching_Model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT dans l'ensemble de données NLI anglais et évaluant l'effet dans l'ensemble de tests STS-BExemple: exemples / formation_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertModèle de correspondance de texte Bert, structure de réseau de correspondance de Bert native, modèle de correspondance du vecteur de phrase interactif
Structure du réseau:
Formation et inférence:
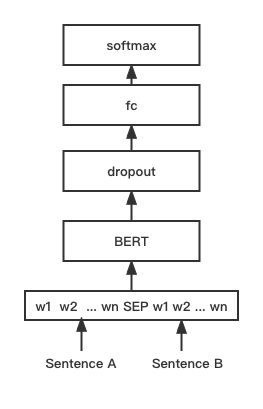
Le script de formation est le même que les exemples ci-dessus / Training_Sup_Text_Matching_Model.py.
BGE sur l'ensemble de données STS-B chinoisExemple: Exemples / Training_BGE_MODEL_MYDATA.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16Modèle BGE Formation de réglage fin, en utilisant un apprentissage du contraste pour former le modèle, le format des données d'entrée est un triple «(requête, positif, négatif)»
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py génère un ensemble de formation triple basé sur STS-B chinois, avec le format comme suit: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py utilise FAISS une correspondance similaire, ce qui rend les exemples d'exploitation difficiles à négatifs.Étant donné que les modèles formés Text2VEC peuvent être chargés à l'aide de la bibliothèque de transformateurs de phrase, sa méthode de distillation du modèle est multiplexée ici.
Fournir deux modèles de déploiement et méthodes pour créer des services: 1) créer des services GRPC basés sur Jina [recommandé]; 2) Construisez des services HTTP natifs basés sur FastAPI.
Il utilise le mode C / S pour créer des services haute performance, prend en charge Docker Cloud Native, GRPC / HTTP / WebSocket, prend en charge la prédiction simultanée de plusieurs modèles et traitement multi-cartes GPU.
Installer: pip install jina
Démarrer le service:
Exemple: Exemples / jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()La méthode de prédiction du modèle (exécuteur) a été téléchargée sur Jinahub, y compris les méthodes de déploiement de Docker et K8S.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )Voir l'exemple: Exemples / jina_client_demo.py pour les méthodes d'appel par lots
Installer: pip install fastapi uvicorn
Démarrer le service:
Exemple: exemples / fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Ensemble de données | Introduction | Lien de téléchargement |
|---|---|---|
| shibing624 / nli-zh-all | Collecte de données de correspondance sémantique chinoise, intégrant 8,2 millions de données de haute qualité pour des tâches telles que le raisonnement de texte, la similitude, le résumé, la question et la réponse, l'instruction affinement et converti en ensemble de données de format correspondant | https://huggingface.co/datasets/shibing624/nli-zh-all |
| shibing624 / snli-zh | Ensembles de données chinois SNLI et Multinli, traduits de SNLI anglais et multinli | https://huggingface.co/datasets/shibing624/snli-zh |
| shibing624 / nli_zh | Ensemble de données de correspondance sémantique chinois, intégrant des ensembles de données de 5 tâches, notamment ATEC, BQ, LCQMC, PAWSX et STS-B. | https://huggingface.co/datasets/shibing624/nli_zh ou Baidu netdisk (code d'extraction: qkt6) ou github |
| shibing624 / sts-sohu2021 | Ensemble de données de correspondance sémantique chinois, 2021 SOHU Campus Text Match Algorithm Competition Dataset | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| Atec | Ensemble de données ATEC chinois, Ant Financial Q-QPAIR Dataset | Atec |
| Bq | Ensemble de données chinois BQ (Bank Question), Bank Q-QPAIR Dataset | Bq |
| LCQMC | Ensemble de données chinois LCQMC (à grande échelle Chinese Question Corpus), jeu de données Q-QPAIR | LCQMC |
| Pawsx | Ensemble de données Chinese PAWS (paraphrase des mots de brouillage de mots), jeu de données Q-qpair | Pawsx |
| STS-B | Ensemble de données chinois STS-B, jeu de données chinois en matière d'inférence en matière de langue naturelle, traduit de données traduit de l'anglais STS-B en chinois | STS-B |
Ensembles de données correspondants en anglais couramment utilisés:
Exemple d'utilisation de l'ensemble de données:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])sortir:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Si vous utilisez Text2VEC dans votre recherche, veuillez le citer dans le format suivant:
Apa:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}Le contrat de licence est l'Apache License 2.0, qui peut être utilisé à des fins commerciales gratuitement. Veuillez joindre le lien et l'accord d'autorisation de Text2Vec à la description du produit.
Le code du projet est encore très rude. Si vous avez amélioré le code, vous êtes invités à le soumettre à ce projet. Avant de soumettre, faites attention aux deux points suivants:
testspython -m pytest -v pour exécuter tous les tests unitaires, en vous assurant que tous les tests uniques sont passésVous pouvez soumettre votre PR plus tard.


