text2vec
1.2.9
?? Cina | Bahasa Inggris | Dokumen/dokumen | ? Model/model

Text2vec : teks ke vektor, dapatkan embeddings kalimat. Vektorisasi teks, mencirikan teks (termasuk kata -kata, kalimat, dan paragraf) sebagai matriks vektor.
Text2Vec mengimplementasikan berbagai model perhitungan teks dan kesamaan teks seperti Word2Vec, RANKBM25, Bert, Kalimat-Bert, Cosent, dan membandingkan efek dari masing-masing model pada tugas pencocokan semantik teks (Perhitungan Kesamaan).
[2023/09/20] V1.2.9 Versi: Mendukung inferensi multi-kartu (implementasi multi-proses dari multi-GPU dan inferensi multi-CPU), alat baris perintah baru (CLI) ditambahkan, yang dapat membuat skrip melakukan vektorisasi teks batch. Lihat Release-V1.2.9 untuk detailnya.
[2023/09/03] V1.2.4 Versi: Mendukung pelatihan model flagembedding, dan merilis model pencocokan Cina Shibing624/text2vec-bge-large-Chinese, yang diawasi dan dilatih menggunakan metode cosent. Ini dilatih berdasarkan BAAI/bge-large-zh-noinstruct , dan evaluasi data yang cocok dengan China telah meningkat dibandingkan dengan model asli. Perbedaan antara teks pendek meningkat secara signifikan. Lihat Release-V1.2.4 untuk detailnya.
[2023/07/17] Versi v1.2.2: Mendukung pelatihan multi-kartu, dan merilis model pencocokan multi-bahasa Shibing624/text2vec-base-multipilingal, yang dilatih menggunakan metode cosent. Berdasarkan sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 dilatih menggunakan dataset STS multi-bahasa manual Shibing624/nli-zh-all/text2vec-base-base-dataset, dan evaluasi dalam tes Cina dan Inggris telah meningkatkan efeknya dibandingkan dengan efeknya. Lihat Release-V1.2.2 untuk detailnya.
[2023/06/19] V1.2.1 Versi: Model pencocokan Cina shibing624/text2vec-base-chinese-nli diperbarui sebagai versi baru dari Shibing624/text2vec-base-Chinese-sentimen. Berdasarkan sensitivitas perhitungan kerugian Cosent terhadap penyortiran, dataset STS berkualitas tinggi dengan penyortiran korelasi dipilih dan disortir secara manual, yang telah meningkatkan kinerja setiap set evaluasi dibandingkan dengan itu; Model pencocokan Cina Shibing624/Text2Vec-Base-Chinese-Paraphrase untuk S2P dirilis, lihat Release-V1.2.1 untuk detailnya.
[2023/06/15] Versi v1.2.0: Model pencocokan Cina Shibing624/text2vec-base-chinese-nli dirilis. Berdasarkan model nghuyong/ernie-3.0-base-zh , model pencocokan teks cosent yang dilatih oleh set data NLI Cina Shibing624/NLI_ZH digunakan. Kinerja dalam setiap set evaluasi meningkat secara signifikan. Lihat Release-V1.2.0 untuk detailnya.
[2022/03/12] V1.1.4 Versi: Model pencocokan Cina Shibing624/text2vec-base-Chinese dirilis, model pencocokan cosent yang dilatih berdasarkan set pelatihan STS Cina. Lihat Release-V1.1.4 untuk detailnya
Memandu
Lihat Wiki: Metode representasi vektor teks untuk metode representasi vektor teks terperinci
Pencocokan teks
| Lengkungan | Basemodel | Model | Bahasa Inggris-Sts-B |
|---|---|---|---|
| Sarung tangan | Gleve | AVG_WORD_EMBEDDING_GLOVE_6B_300D | 61.77 |
| Bert | Bert-Base-Incased | Bert-base-Cls | 20.29 |
| Bert | Bert-Base-Incased | Bert-base-first_last_avg | 59.04 |
| Bert | Bert-Base-Incased | Bert-base-first_last_avg-whiten (NLI) | 63.65 |
| Sbert | Kalimat-transformer/Bert-base-nli-mean-tokens | SBERT-BASE-NLI-CLS | 73.65 |
| Sbert | Kalimat-transformer/Bert-base-nli-mean-tokens | SBT-BASE-NLI-FIRST_LAST_AVG | 77.96 |
| Cosent | Bert-Base-Incased | Cosent-base-first_last_avg | 69.93 |
| Cosent | Kalimat-transformer/Bert-base-nli-mean-tokens | Cosent-base-nli-first_last_avg | 79.68 |
| Cosent | Transformer kalimat/parafrase-multipiling-minilm-L12-V2 | Shibing624/text2vec-base-multipilingal | 80.12 |
| Lengkungan | Basemodel | Model | ATEC | Bq | LCQMC | Pawsx | STS-B | Rata -rata |
|---|---|---|---|---|---|---|---|---|
| Sbert | Bert-Base-Chinese | SBERT-BERT-BASE | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL/China-Macbert-Base | SBERT-MACBERT-BASE | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| Sbert | hfl/cina-roberta-wwm-ext | Sbert-Roberta-Ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| Cosent | Bert-Base-Chinese | Cosent-Bert-Base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| Cosent | HFL/China-Macbert-Base | Cosent-Macbert-Base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| Cosent | hfl/cina-roberta-wwm-ext | Cosent-roberta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
menjelaskan:
SBERT-macbert-base dilatih menggunakan metode Sbert, dan menjalankan contoh/pelatihan_sup_text_matching_model.py kode untuk melatih model.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 dilatih dengan Sbert, dan merupakan versi multibahasa dari model paraphrase-MiniLM-L12-v2 , mendukung bahasa Cina, Inggris, dll.| Lengkungan | Basemodel | Model | ATEC | Bq | LCQMC | Pawsx | STS-B | Sohu-dd | SOHU-DC | Rata -rata | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2vec | word2vec | W2V-light-tencent-Chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-Roberta-Base | Transformer kalimat/parafrase-multipiling-minilm-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| Cosent | HFL/China-Macbert-Base | Shibing624/text2vec-base-Chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| Cosent | HFL/China-Lert-Large | Ganymedenil/text2vec-large-Chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| Cosent | Nghuyong/Ernie-3.0-Base-Zh | shibing624/text2vec-base-chinese-konsenten | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| Cosent | Nghuyong/Ernie-3.0-Base-Zh | shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| Cosent | Transformer kalimat/parafrase-multipiling-minilm-L12-V2 | Shibing624/text2vec-base-multipilingal | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| Cosent | Baai/BGE-Large-ZH-Noinstruct | Shibing624/Text2Vec-BGE-Large-Chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
menjelaskan:
shibing624/text2vec-base-chinese dilatih menggunakan metode cosent, dilatih dalam data STS-B Cina berdasarkan hfl/chinese-macbert-base , dan dievaluasi dalam uji STS-B Cina untuk mencapai hasil yang baik. Jalankan kode Contoh/Pelatihan_SUP_TEXT_MATCHING_MODEL.py untuk melatih model. File model telah diunggah ke HF Model Hub. Disarankan untuk menggunakan tugas pencocokan semantik umum Cina.shibing624/text2vec-base-chinese-sentence Model dilatih menggunakan metode cosent. Ini dilatih berdasarkan dataset STS Cina yang dipilih secara manual Shibing624/nli-zh-all/text2vec- nghuyong/ernie-3.0-base-zh -datas-data-data, dan dievaluasi dalam berbagai set tes NLI Cina untuk mencapai hasil yang baik. Jalankan contoh/pelatihan_sup_text_matching_model_jsonl_data.py kode untuk melatih model. File model telah diunggah ke HF Model Hub. Tugas pencocokan semantik S2 (kalimat vs kalimat) yang disarankan untuk digunakanshibing624/text2vec-base-chinese-paraphrase Model dilatih menggunakan metode cosent. Based on the Chinese STS dataset selected by nghuyong/ernie-3.0-base-zh manually, shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset, the dataset is added to s2p (sentence to) relative to shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset. Parafrase) data memperkuat kemampuan representasi teks panjangnya, dan mengevaluasi untuk mencapai SOTA dalam berbagai set uji NLI Cina. Jalankan contoh/pelatihan_sup_text_matching_model_jsonl_data.py kode untuk melatih model. File model telah diunggah ke HF Model Hub. Tugas pencocokan semantik S2P (kalimat vs paragraf) yang disarankan.shibing624/text2vec-base-multilingual Model dilatih menggunakan metode cosent. Ini dilatih berdasarkan sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 menggunakan dataset STS multibahasa yang dipilih secara manual shibing624/nli-zh-all/text2vec-base-multipilingual-dataset. Ini dievaluasi dalam set tes Cina dan Inggris, dan efeknya ditingkatkan dibandingkan dengan model aslinya. Jalankan contoh/pelatihan_sup_text_matching_model_jsonl_data.py kode untuk melatih model. File model telah diunggah ke HF Model Hub. Disarankan untuk menggunakan tugas pencocokan semantik multibahasa.shibing624/text2vec-bge-large-chinese Model dilatih menggunakan metode cosent. Ini dilatih berdasarkan BAAI/bge-large-zh-noinstruct menggunakan dataset STS Cina yang dipilih secara manual Shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-Dataset. Evaluasi dalam set tes Cina telah meningkatkan efek dibandingkan dengan model asli, dan perbedaan dalam teks pendek secara signifikan meningkat. Jalankan contoh/pelatihan_sup_text_matching_model_jsonl_data.py kode untuk melatih model. File model telah diunggah ke HF Model Hub. Tugas pencocokan semantik S2 (kalimat vs kalimat) yang disarankan untuk digunakanw2v-light-tencent-chinese adalah model Word2Vec dari vektor kata tencent, yang digunakan oleh pemuatan CPU, cocok untuk tugas pencocokan literal Cina dan situasi awal yang dingin dari data yang hilang--model_name hfl/chinese-macbert-base atau roBol model: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG dan EncoderType.MEAN , dan efek prediksi keduanya sangat kecil.examples/data dan menjalankan kode tes/model_spearman.py untuk mereproduksi hasil evaluasi.Laporan Eksperimental Pelatihan Model: Laporan Eksperimental
Demo resmi: https://www.mulanai.com/product/short_text_sim/
Demo HuggingFace: https://huggingface.co/spaces/shibing624/text2vec

Jalankan Contoh: Contoh/gradio_demo.py untuk melihat demo:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecatau
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . Hitung vektor teks berdasarkan pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)Contoh: Contoh/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )keluaran:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings Nilai Pengembalian adalah Type numpy.ndarray , Shape is (sentences_size, model_embedding_size) , dan Anda dapat memilih salah satu dari tiga model. Yang pertama direkomendasikan.shibing624/text2vec-base-chinese diperoleh dengan pelatihan metode cosent dalam dataset STS-B Cina. Model ini telah diunggah ke perpustakaan model Huggingface Shibing624/Text2Vec-Base-Chinese. Ini adalah model default yang ditentukan oleh text2vec.SentenceModel . Ini dapat dipanggil melalui contoh di atas, atau dapat dipanggil dengan pustaka Transformers seperti yang ditunjukkan di bawah ini. Model akan diunduh secara otomatis ke jalur asli: ~/.cache/huggingface/transformersw2v-light-tencent-chinese adalah model Word2VEC yang dimuat melalui gensim. Kata vektor dari masing -masing kata dihitung menggunakan tencent kata vektor Tencent_AILab_ChineseEmbedding.tar.gz Vektor kalimat dirata -rata melalui kata kata vektor. Model ini secara otomatis diunduh ke jalur asli: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec mendukung inferensi multi-kartu (menghitung vektor teks): Contoh/computing_embeddings_multi_gpu_demo.py Tanpa text2vec, Anda dapat menggunakan model seperti ini:
Pertama, Anda melewati input Anda melalui model transformator, maka Anda harus menerapkan operasi pengumpulan yang tepat di atas dari kata embeddings yang dikontekstualisasikan.
Contoh: Contoh/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Kalimat-Transformers adalah perpustakaan populer untuk menghitung representasi vektor padat untuk kalimat.
Instal Transformers Kalimat:
pip install -U sentence-transformersKemudian muat model dan prediksi:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Menyediakan dua vektor kata Word2Vec , opsional satu:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt , tencent kata vektor halaman beranda: https://ai.tencent.com/ailab/nlp/zh/index.html kata vektor: https://ai.tencent.com/ailab/nlp/en/download.html Lebih Banyak Lihat tencent kata vektor pengantar-wikiDukung akuisisi batch vektor teks
Kode: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
berlari:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu TrueFile Input (Diperlukan):
input.txt, Format: Kalimat Teks dari satu kalimat, satu baris.
Contoh: Contoh/semantik_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))keluaran:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591Kisaran
scoredari nilai kesamaan kosinus adalah [-1, 1], dan semakin besar nilainya, semakin mirip.
Secara umum, teks yang paling mirip dengan kueri ditemukan dalam set kandidat dokumen, dan sering digunakan untuk tugas -tugas seperti pencocokan kesamaan pertanyaan dan pengambilan kesamaan teks dalam skenario QA.
Contoh: Contoh/semantik_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))keluaran:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)Perpustakaan Kesamaan [Direkomendasikan]
Untuk perhitungan kesamaan teks dan tugas pencarian teks, disarankan untuk menggunakan pustaka kesamaan, yang kompatibel dengan model rilis rilis Word2Vec, Sbert, dan Cosent seperti cosent dalam proyek ini. Ini juga mendukung 100 juta pencarian grafis tingkat, dan mendukung deduplikasi semantik teks , deduplikasi gambar dan fungsi lainnya.
Instalasi: pip install -U similarities
Perhitungan kesamaan kalimat:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
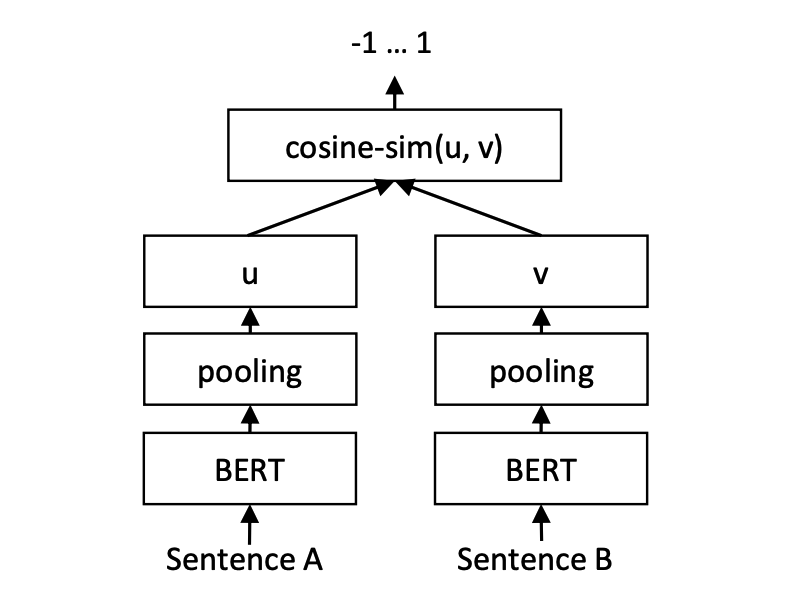
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Model pencocokan teks cosent (kalimat cosine), meningkatkan skema vektor kalimat cosinerankloss pada kalimat-kalimat
Struktur Jaringan:
Pelatihan:
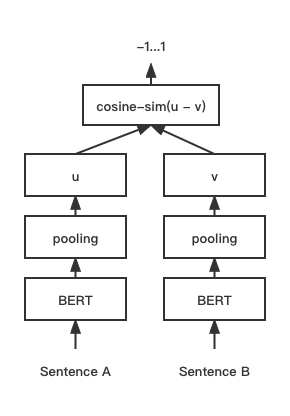
Kesimpulan:
Pelatihan dan prediksi model cosent:
CoSENT pada dataset STS-B CinaContoh: Contoh/pelatihan_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT pada dataset pencocokan keuangan semut atecDukung penggunaan kumpulan data yang cocok dengan Cina ini: 'atec', 'sts-b', 'bq', 'lcqmc', 'pawsx', untuk detailnya, silakan merujuk ke dataset HUGGINGFACE https://huggingface.co/datasets/shibing624/nli_zhh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentContoh: Contoh/pelatihan_sup_text_matching_model_mydata.py
Pelatihan kartu tunggal:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictPelatihan Doka:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel Contoh referensi/data/sts-b/sts-b.valid.data untuk format set pelatihan
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label dapat berupa label 0 dan 1, dan 0 berarti bahwa kedua kalimat tidak serupa, dan 1 berarti serupa; Ini juga bisa menjadi skor 0-5. Semakin tinggi skor, semakin mirip kedua kalimatnya. Semua model dapat didukung.
CoSENT pada dataset STS-B bahasa InggrisContoh: Contoh/pelatihan_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT dalam dataset NLI bahasa Inggris dan efek evaluasi dalam set tes STS-BContoh: Contoh/pelatihan_unsup_text_matching_model_en.py
cd examples
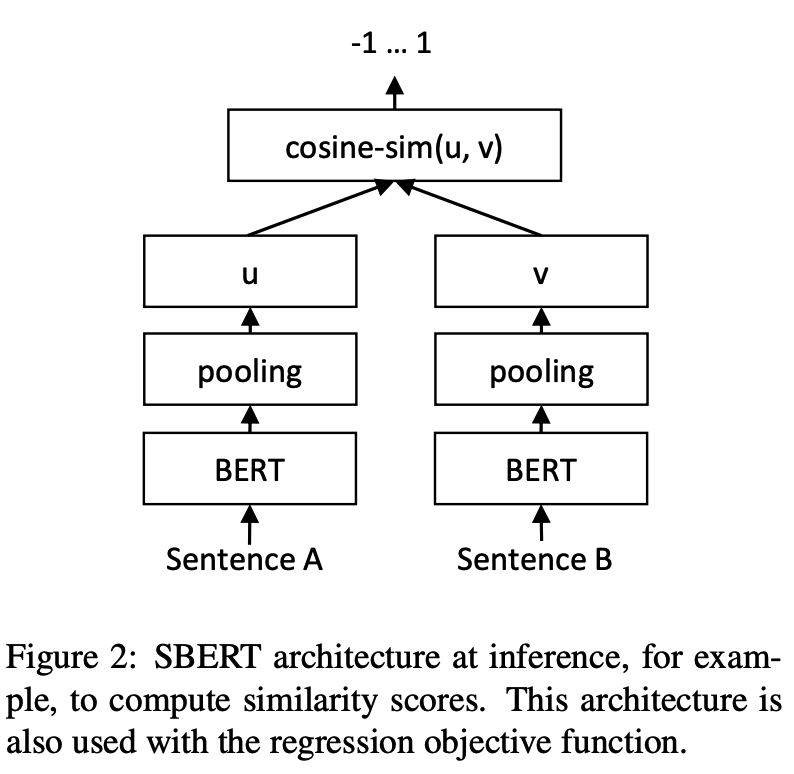
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentModel Pencocokan Teks Kalimat-Bert, Skema Representasi Vektor Kalimat Representasional
Struktur Jaringan:
Pelatihan:
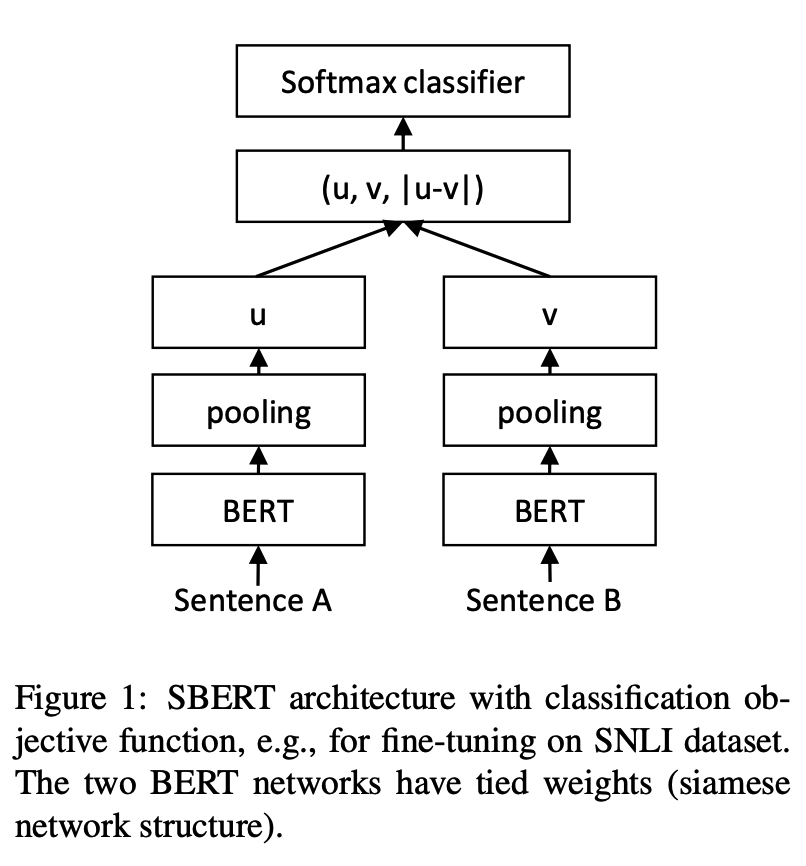
Kesimpulan:
SBERT pada Dataset STS-B CinaContoh: Contoh/pelatihan_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT pada Dataset STS-B EnglishContoh: Contoh/pelatihan_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT Model dalam Dataset NLI Bahasa Inggris dan Efigurasi Efek dalam STS-B Test SetContoh: Contoh/pelatihan_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertModel pencocokan teks Bert, struktur jaringan pencocokan Bert asli, model pencocokan vektor kalimat interaktif
Struktur Jaringan:
Pelatihan dan Inferensi:
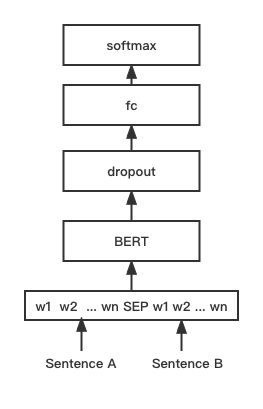
Script pelatihan sama dengan contoh di atas/pelatihan_sup_text_matching_model.py.
BGE pada dataset STS-B CinaContoh: Contoh/pelatihan_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16Pelatihan fine-tuning model BGE, menggunakan pembelajaran kontras untuk melatih model, format data input adalah triple '(kueri, positif, negatif)'
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py menghasilkan set pelatihan tiga berdasarkan STS-B Cina, dengan format sebagai berikut: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py menggunakan pertandingan serupa FAISS, membuat penambangan sulit untuk contoh negatif.Karena model yang dilatih Text2Vec dapat dimuat menggunakan perpustakaan Transformers Kalimat, metode distilasi modelnya multiplexed di sini.
Menyediakan dua model dan metode penyebaran untuk membangun layanan: 1) membangun layanan GRPC berdasarkan Jina [disarankan]; 2) Membangun layanan HTTP asli berdasarkan FastAPI.
Ini menggunakan mode C/S untuk membangun layanan berkinerja tinggi, mendukung Docker Cloud Native, GRPC/HTTP/WebSocket, mendukung prediksi simultan beberapa model dan pemrosesan multi-kartu GPU.
Instal: pip install jina
Mulai Layanan:
Contoh: Contoh/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()Metode prediksi model (pelaksana) telah diunggah ke Jinahub, termasuk metode penyebaran Docker dan K8S.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )Lihat Contoh: Contoh/jina_client_demo.py untuk metode panggilan batch
Instal: pip install fastapi uvicorn
Mulai Layanan:
Contoh: Contoh/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | Dataset | Perkenalan | Tautan unduh |
|---|---|---|
| shibing624/nli-zh-all | Pengumpulan Data Pencocokan Semantik Cina, mengintegrasikan 8,2 juta data berkualitas tinggi untuk tugas-tugas seperti penalaran teks, kesamaan, ringkasan, tanya jawab dan jawaban, penyesuaian instruksi, dan dikonversi menjadi set data format yang cocok | https://huggingface.co/datasets/shibing624/nli-zh-all |
| Shibing624/snli-zh | Dataset SNLI dan Multinli Cina, diterjemahkan dari bahasa Inggris SNLI dan Multinli | https://huggingface.co/datasets/shibing624/snli-zh |
| Shibing624/nli_zh | Set data pencocokan semantik Cina, mengintegrasikan set data 5 tugas, termasuk ATEC, BQ, LCQMC, PAWSX, dan STS-B. | https://huggingface.co/datasets/shibing624/nli_zh atau Baidu Netdisk (Kode Ekstraksi: QKT6) atau GitHub |
| Shibing624/STS-SOHU2021 | Dataset Pencocokan Semantik Cina, 2021 Sohu Campus Pencocokan Teks Kompetisi Kompetisi Dataset | https://huggingface.co/datasets/shibing624/sts-soHu2021 |
| ATEC | Dataset ATEC Cina, Dataset Q-QPair Financial Ant | ATEC |
| Bq | Dataset BQ (Pertanyaan Bank) Cina, Dataset Bank Q-Qpair | Bq |
| LCQMC | Dataset LCQMC (Corpus Pencocokan Pertanyaan Tiongkok Skala Besar), Dataset Q-Qpair Q-Qpair | LCQMC |
| Pawsx | Paws China (musuh parafrase dari Word Scrambling) Dataset, Dataset Q-QPair | Pawsx |
| STS-B | Dataset STS-B Cina, Dataset Inferensi Bahasa Alami Cina, Dataset Diterjemahkan dari Bahasa Inggris STS-B ke Cina | STS-B |
Dataset pencocokan bahasa Inggris yang umum digunakan:
Contoh Penggunaan Dataset:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])keluaran:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
Jika Anda menggunakan Text2Vec dalam riset Anda, silakan mengutipnya dalam format berikut:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}Perjanjian lisensi adalah Lisensi Apache 2.0, yang dapat digunakan untuk tujuan komersial secara gratis. Harap lampirkan tautan dan perjanjian otorisasi Text2Vec ke deskripsi produk.
Kode proyek masih sangat kasar. Jika Anda telah meningkatkan kode, Anda dipersilakan untuk mengirimkannya kembali ke proyek ini. Sebelum mengirimkan, perhatikan dua poin berikut:
testspython -m pytest -v untuk menjalankan semua tes unit, pastikan semua tes tunggal dilewatkanAnda dapat mengirimkan PR Anda nanti.


