text2vec
1.2.9
?? 중국어 | 영어 | 문서/문서 | ? 모델/모델

Text2Vec : 텍스트 벡터, 문장 임베드를 받으십시오. 텍스트 벡터화는 텍스트 (단어, 문장 및 단락 포함)를 벡터 행렬로 특성화합니다.
Text2Vec은 Word2Vec, RankBM25, Bert, Sentence-Bert, Cosent와 같은 다양한 텍스트 표현 및 텍스트 유사성 계산 모델을 구현하며 각 모델의 텍스트 의미 론적 매칭 (유사성 계산) 작업에 미치는 영향을 비교합니다.
[2023/09/20] v1.2.9 버전 : 멀티 카드 추론 (멀티 GPU 및 멀티 -CPU 추론의 다중 프로세스 구현)을 지원합니다. 새로운 명령 줄 도구 (CLI)가 추가되어 스크립트가 배치 텍스트 벡터화를 수행 할 수 있습니다. 자세한 내용은 릴리스 V1.2.9를 참조하십시오.
[2023/09/03] V1.2.4 버전 : Flagembedding 모델 교육을 지원하고 중국 일치 모델 Shibing624/Text2Vec-Bge-Large-Chinese를 발표했습니다. BAAI/bge-large-zh-noinstruct 기반으로 교육을 받았으며, 중국 일치 데이터 세트 평가는 원래 모델과 비교하여 개선되었습니다. 짧은 텍스트의 차이가 크게 향상되었습니다. 자세한 내용은 릴리스 -V1.2.4를 참조하십시오.
[2023/07/17] v1.2.2 버전 : 멀티 카드 교육을 지원하고 COSENT 방법을 사용하여 훈련 된 다중 언어 매칭 모델 Shibing624/Text2Vec-Base-Multingual을 출시했습니다. sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 수동 다중 언어 STS 데이터 세트 Shibing624/NLI-ZH-ALL/TEXT2VEC-BASE-MULTILUAL-DATASET을 사용하여 교육을 받았으며 중국 및 영어 테스트 세트의 평가는 원래 모델과 비교하여 효과를 향상 시켰습니다. 자세한 내용은 릴리스 V1.2.2를 참조하십시오.
[2023/06/19] v1.2.1 버전 : 중국 일치 모델 shibing624/text2vec-base-chinese-nli 새 버전의 Shibing624/Text2Vec-Base-Chinese-Sentence로 업데이트됩니다. 정렬에 대한 COSENT의 손실 계산의 민감도에 기초하여, 상관 관계 정렬을 갖는 고품질 STS 데이터 세트를 수동으로 선택하고 정렬하여 각 평가 세트의 성능을 개선시켰다. S2P에 대한 중국 일치 모델 Shibing624/Text2Vec-Base-Chinese-Paraphrase가 출시되었습니다 (자세한 내용은 릴리스 -V1.2.1 참조).
[2023/06/15] V1.2.0 버전 : 중국 일치 모델 Shibing624/Text2Vec-Base-Chinese-NLI가 출시되었습니다. nghuyong/ernie-3.0-base-zh 모델을 기반으로, 중국 NLI 데이터 세트 Shibing624/NLI_ZH에 의해 훈련 된 COSENT 텍스트 일치 모델이 사용됩니다. 각 평가 세트의 성능이 크게 향상되었습니다. 자세한 내용은 릴리스 V1.2.0을 참조하십시오.
[2022/03/12] v1.1.4 버전 : 중국 일치 모델 Shibing624/Text2Vec-Base-Chinese가 출시되며, 중국 STS 훈련 세트를 기반으로 훈련 된 코스 센트 매칭 모델. 자세한 내용은 릴리스 V1.1.4를 참조하십시오
가이드
자세한 텍스트 벡터 표현 방법에 대한 Wiki : Text Vector 표현 방법 참조
텍스트 일치
| 아치 | 베이스 모드 | 모델 | 영어 STS-B |
|---|---|---|---|
| 장갑 | 글리브 | avg_word_embeddings_glove_6b_300d | 61.77 |
| 버트 | 베르트-베이스에 배치 | 버트-베이스 -Cls | 20.29 |
| 버트 | 베르트-베이스에 배치 | Bert-base-first_last_avg | 59.04 |
| 버트 | 베르트-베이스에 배치 | Bert-base-first_last_avg-whiten (NLI) | 63.65 |
| Sbert | 문장 전환자/Bert-Base-Nli-Mean-Tokens | Sbert-Base-Nli-Cls | 73.65 |
| Sbert | 문장 전환자/Bert-Base-Nli-Mean-Tokens | sbert-base-nli-first_last_avg | 77.96 |
| COSENT | 베르트-베이스에 배치 | COSENT-BASE-FIRST_LAST_AVG | 69.93 |
| COSENT | 문장 전환자/Bert-Base-Nli-Mean-Tokens | COSENT-BASE-NLI-FIRST_LAST_AVG | 79.68 |
| COSENT | 문장 전달 자/낙하-다면-문화-미닐름 L12-V2 | Shibing624/Text2Vec-Base-Multingual | 80.12 |
| 아치 | 베이스 모드 | 모델 | ATEC | BQ | LCQMC | pawsx | STS-B | avg |
|---|---|---|---|---|---|---|---|---|
| Sbert | 베르트-베이스-차이나 | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL/중국-맥버트베이스 | Sbert-Macbert-Base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| Sbert | HFL/중국-로베르타 -WWM-EXT | Sbert-Roberta-ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| COSENT | 베르트-베이스-차이나 | COSENT-BERT-BASE | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| COSENT | HFL/중국-맥버트베이스 | COSENT-MACBERT-BASE | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| COSENT | HFL/중국-로베르타 -WWM-EXT | COSENT-ROBERTA-EXT | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
설명 :
SBERT-macbert-base MODEL은 SBERT 메소드를 사용하여 교육을 받았으며 예제/Training_SUP_TEXT_MATCHING_MODEL.PY 코드를 실행하여 모델을 훈련시킵니다.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 모델은 SBERT로 훈련되었으며, 다국어 버전의 paraphrase-MiniLM-L12-v2 모델, 중국어, 영어 등을 지원합니다.| 아치 | 베이스 모드 | 모델 | ATEC | BQ | LCQMC | pawsx | STS-B | SOHU-DD | SOHU-DC | avg | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2vec | Word2vec | W2V-Light-Tencent-Chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-ROBERTA-BASE | 문장 전달 자/낙하-다면-문화-미닐름 L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| COSENT | HFL/중국-맥버트베이스 | Shibing624/Text2Vec-Base-Chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| COSENT | HFL/중국어-르기 | Ganymedenil/Text2Vec-Large-Chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| COSENT | Nghuyong/Ernie-3.0-Base-ZH | Shibing624/Text2Vec-Base-Chinese-entence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| COSENT | Nghuyong/Ernie-3.0-Base-ZH | Shibing624/Text2Vec-Base-Chinese-Paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| COSENT | 문장 전달 자/낙하-다면-문화-미닐름 L12-V2 | Shibing624/Text2Vec-Base-Multingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| COSENT | Baai/bge-large-zh-nointruct | Shibing624/Text2Vec-Bge-Large-Chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
설명 :
shibing624/text2vec-base-chinese 모델은 COSENT 방법을 사용하여 훈련을 받고 hfl/chinese-macbert-base 기반으로 중국 STS-B 데이터로 교육을 받았으며 중국 STS-B 테스트 세트에서 평가하여 좋은 결과를 달성했습니다. 모델을 훈련시키기 위해 예제/training_sup_text_matching_model.py 코드를 실행하십시오. 모델 파일이 HF Model Hub에 업로드되었습니다. 중국 일반 시맨틱 매칭 작업을 사용하는 것이 좋습니다.shibing624/text2vec-base-chinese-sentence 모델은 COSENT 메소드를 사용하여 교육을받습니다. 수동으로 선택된 중국 STS 데이터 세트 Shibing624/NLI-ZH-ALL/TEXT2VEC- nghuyong/ernie-3.0-base-zh -CHINESE-SENTENCE-DATASET을 기반으로 교육을 받고 다양한 중국 NLI 테스트 세트에서 평가되어 좋은 결과를 얻습니다. 모델을 훈련시키기 위해 예제/training_sup_text_matching_model_jsonl_data.py 코드를 실행하십시오. 모델 파일이 HF Model Hub에 업로드되었습니다. 중국 S2S (문장 대 문장) 시맨틱 매칭 작업을 사용하는 것이 좋습니다.shibing624/text2vec-base-chinese-paraphrase 모델은 COSENT 방법을 사용하여 교육을받습니다. nghuyong/ernie-3.0-base-zh 수동으로 선택한 중국 STS 데이터 세트, Shibing624/nli-Zh-all/Text2Vec-Base-Chinese-Paraphrase-Dataset를 기반으로, 데이터 세트는 Shibing6224/nli-zh-base-chin-sentes-sensected6224에 대해 S2P (문장)에 추가됩니다. Paraphrase) 데이터는 긴 텍스트 표현 능력을 강화하고 다양한 중국 NLI 테스트 세트에서 SOTA를 달성하도록 평가합니다. 실행 예/Training_SUP_TEXT_MATCHING_MODEL_JSONL_DATA.PY 코드를 실행하여 모델을 훈련시킵니다. 모델 파일이 HF Model Hub에 업로드되었습니다. 중국 S2P (문장 대 단락) 시맨틱 매칭 작업이 권장됩니다.shibing624/text2vec-base-multilingual 모델은 COSENT 메소드를 사용하여 교육을받습니다. 수동으로 선택된 다국어 STS 데이터 세트 Shibing624/NLI-ZH-ALL/TEXT2VEC-BASE-MULTILUAL-DATASET을 사용하여 sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 기반으로 훈련됩니다. 중국 및 영어 테스트 세트에서 평가되며 원래 모델에 비해 효과가 향상됩니다. 모델을 훈련시키기 위해 예제/training_sup_text_matching_model_jsonl_data.py 코드를 실행하십시오. 모델 파일이 HF Model Hub에 업로드되었습니다. 다국어 시맨틱 매칭 작업을 사용하는 것이 좋습니다.shibing624/text2vec-bge-large-chinese 모델은 COSENT 방법을 사용하여 교육을받습니다. 수동으로 선택된 중국 STS 데이터 세트 Shibing624/Nli-Zh-all/Text2Vec-Base-Chinese-Paraphrase-Dataset을 사용하여 BAAI/bge-large-zh-noinstruct 기반으로 교육을받습니다. 중국 테스트 세트의 평가는 원래 모델과 비교하여 효과를 향상 시켰으며 짧은 텍스트의 차이가 크게 향상되었습니다. 모델을 훈련시키기 위해 예제/training_sup_text_matching_model_jsonl_data.py 코드를 실행하십시오. 모델 파일이 HF Model Hub에 업로드되었습니다. 중국 S2S (문장 대 문장) 시맨틱 매칭 작업을 사용하는 것이 좋습니다.w2v-light-tencent-chinese CPU 로딩에 사용되는 Tencent Word Vectors의 Word2Vec 모델입니다.--model_name hfl/chinese-macbert-base 또는 Roberta Model : --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG 및 EncoderType.MEAN 에 가장 적합한 선택이며,이 둘의 예측 효과는 매우 작습니다.examples/data 로 다운로드하고 테스트/model_spearman.py 코드를 실행하여 평가 결과를 재현 할 수 있습니다.모델 교육 실험 보고서 : 실험 보고서
공식 데모 : https://www.mulanai.com/product/short_text_sim/
huggingface 데모 : https://huggingface.co/spaces/shibing624/text2vec

실행 예 : 예제/gradio_demo.py 데모를 보려면 :
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vec또는
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . pretrained model 기반으로 텍스트 벡터 계산 :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)예 : 예/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )산출:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings numpy.ndarray 유형이며, shape is (sentences_size, model_embedding_size) 이며 세 가지 모델 중 하나를 선택할 수 있습니다. 첫 번째는 권장됩니다.shibing624/text2vec-base-chinese 모델은 중국 STS-B 데이터 세트의 COSENT 방법 교육에 의해 얻어진다. 이 모델은 624/Text2Vec-Base-Chinese의 Huggingface 모델 라이브러리에 업로드되었습니다. text2vec.SentenceModel 로 지정된 기본 모델입니다. 위의 예를 통해 호출하거나 아래와 같이 Transformers 라이브러리로 호출 할 수 있습니다. 모델은 기본 경로로 자동 다운로드됩니다 : ~/.cache/huggingface/transformersw2v-light-tencent-chinese Gensim을 통해로드 된 Word2Vec 모델입니다. 각 단어의 단어 벡터는 Tencent Word 벡터 Tencent_AILab_ChineseEmbedding.tar.gz 문장 벡터는 단어 단어 벡터를 통해 평균화됩니다. 모델 ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin 기본 경로로 자동 다운로드됩니다.text2vec 다중 카드 추론 (텍스트 벡터 계산)을 지원합니다. 예/computing_embeddings_multi_gpu_demo.py Text2Vec가 없으면 다음과 같은 모델을 사용할 수 있습니다.
먼저 변압기 모델을 통해 입력을 전달한 다음 상황에 맞는 단어 임베딩의 올바른 풀링 수용을 적용해야합니다.
예 : 예제/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )문장 변환자는 문장에 대한 조밀 한 벡터 표현을 계산하는 인기있는 라이브러리입니다.
문장 변환기 설치 :
pip install -U sentence-transformers그런 다음 모델을로드하고 예측합니다.
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word 벡터 두 개의 Word2Vec Word 벡터를 제공합니다.
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin 에 자동으로 다운로드합니다.~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt 과 같습니다. https://ai.tencent.com/ailab/nlp/en/download.html more tencent word vector 소개-wiki텍스트 벡터의 배치 획득 지원
코드 : cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
달리다:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu True입력 파일 (필수) :
input.txt, 형식 : 한 줄의 한 줄, 한 줄의 문장 텍스트.
예 : 예 : 예/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))산출:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591문장 코사인 유사성 값의
score범위는 [-1, 1]이고 값이 클수록 비슷합니다.
일반적으로 쿼리와 가장 유사한 텍스트는 문서 후보 세트에서 찾을 수 있으며 QA 시나리오에서 질문 유사성 일치 및 텍스트 유사성 검색과 같은 작업에 종종 사용됩니다.
예 : 예제/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))산출:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)유사성 라이브러리 [권장]
텍스트 유사성 계산 및 텍스트 일치하는 검색 작업의 경우이 프로젝트에서 Word2Vec, SBERT 및 COSENT와 같은 의미 론적 일치 모델과 호환되는 유사성 라이브러리를 사용하는 것이 좋습니다. 또한 1 억 수준의 그래픽 검색을 지원하며 텍스트 시맨틱 중복 제거 , 이미지 중복 제거 및 기타 기능을 지원합니다.
설치 : pip install -U similarities
문장 유사성 계산 :
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 COSENT (COSINE SELTENCE) 텍스트 일치 모델, COSINERANKLOSS의 문장 벡터 구성표를 Sentence-Bert에서 향상시킵니다.
네트워크 구조 :
훈련:
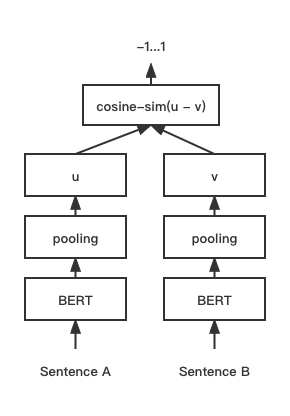
추론:
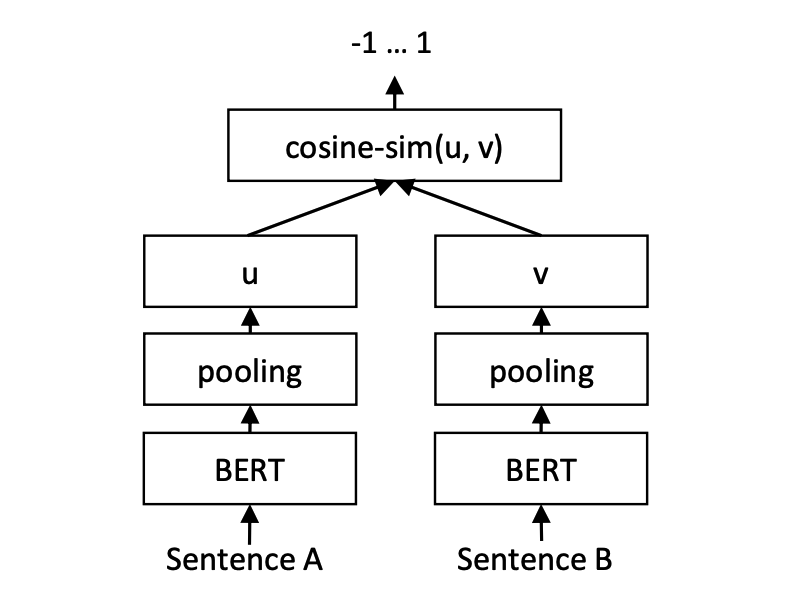
COSENT 모델의 훈련 및 예측 :
CoSENT 모델의 교육 및 평가예 : 예/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT 교육 및 평가이 중국 일치하는 데이터 세트의 사용 지원 : 'atec', 'sts-b', 'bq', 'lcqmc', 'pawsx', 자세한 내용은 htgingface datasets https://huggingface.co/datasets/shibing624/nli_zh를 참조하십시오.
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosent예 : 예/trainples_sup_text_matching_model_mydata.py
단일 카드 교육 :
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predict도카 훈련 :
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel 교육 세트 형식에 대한 참조 예제/data/sts-b/sts-b.valid.data
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 label 레이블 0 및 1 일 수 있고 0은 두 문장이 유사하지 않으며 1은 유사하다는 것을 의미합니다. 0-5 점수 일 수도 있습니다. 점수가 높을수록 두 문장이 비슷합니다. 모든 모델을 지원할 수 있습니다.
CoSENT 모델의 교육 및 평가예 : 예/trainples_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT 모델 교육 및 STS-B 테스트 세트의 효과 평가 효과예 : 예 : 예/Training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosent문장-베르트 텍스트 일치 모델, 표현 문장 벡터 표현 체계
네트워크 구조 :
훈련:
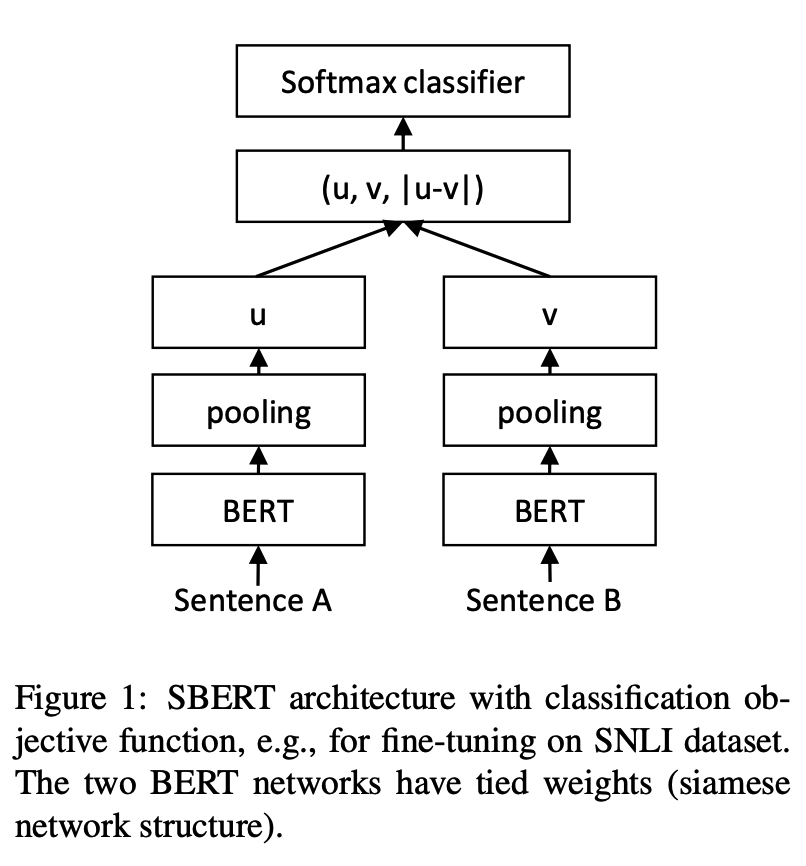
추론:
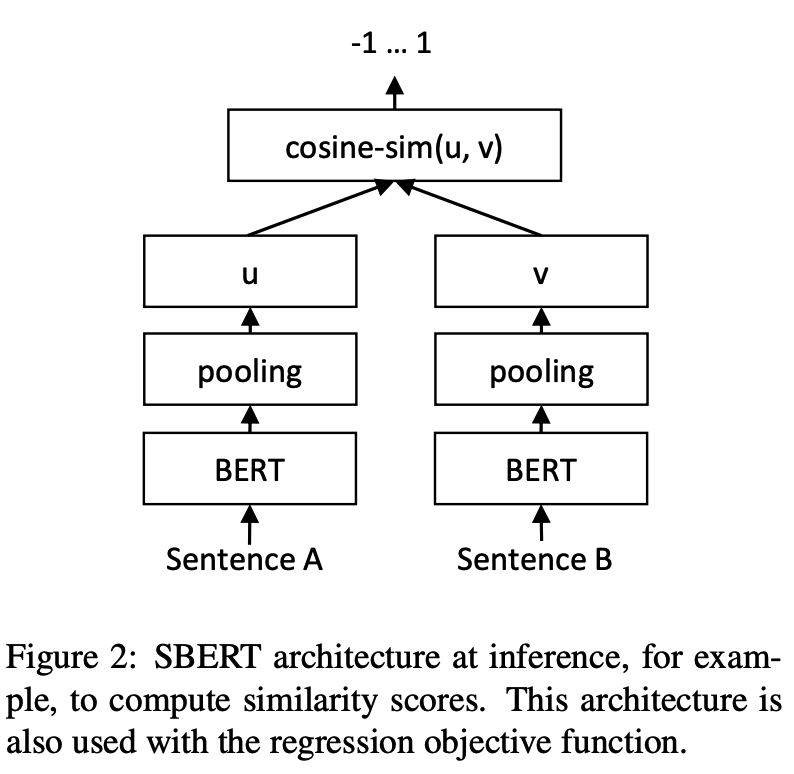
SBERT 모델의 교육 및 평가예 : 예/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT 모델의 교육 및 평가예 : 예/trainples_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT 모델 교육 및 STS-B 테스트 세트의 효과 평가 효과예 : 예 : 예/Training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbert버트 텍스트 매칭 모델, 네이티브 버트 매칭 네트워크 구조, 대화식 문장 벡터 일치 모델
네트워크 구조 :
훈련 및 추론 :
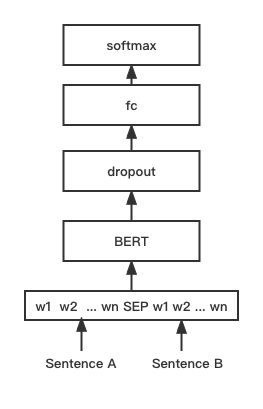
교육 스크립트는 위의 예와 동일합니다.
BGE 모델의 교육 및 평가예 : 예/training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGE 모델 미세 조정 교육, 대비 학습을 사용하여 모델을 훈련시키는 입력 데이터의 형식은 트리플 '(쿼리, 양성, 부정)'입니다.
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py 중국 STS-B를 기반으로 트리플 트레이닝 세트를 생성하며 다음과 같이 형식을 생성합니다. { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py faiss 유사한 일치를 사용하여 마이닝이 부정적인 예를 사용하기 어렵습니다.Text2Vec 훈련 된 모델은 문장 변환기 라이브러리를 사용하여로드 할 수 있으므로 모델 증류 방법은 여기서 다중화됩니다.
서비스 구축을위한 두 가지 배포 모델과 방법을 제공합니다. 1) JINA [권장]을 기반으로 GRPC 서비스 구축; 2) Fastapi를 기반으로 기본 HTTP 서비스를 구축하십시오.
C/S 모드를 사용하여 고성능 서비스를 구축하고 Docker Cloud Native, GRPC/HTTP/WebSocket을 지원하며 여러 모델 및 GPU 멀티 카드 처리의 동시 예측을 지원합니다.
설치 : pip install jina
서비스 시작 :
예 : 예제/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()모델 예측 방법 (Executor)은 Docker 및 K8S 배포 방법을 포함하여 Jinahub에 업로드되었습니다.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )예를 참조하십시오 : 예제/jina_client_demo.py 배치 호출 방법은 예를 참조하십시오
설치 : pip install fastapi uvicorn
서비스 시작 :
예 : 예제/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | 데이터 세트 | 소개 | 링크 다운로드 |
|---|---|---|
| Shibing624/nli-zh-all | 중국 시맨틱 매칭 데이터 수집, 텍스트 추론, 유사성, 요약 및 답변, 명령 미세 조정 및 일치 형식 데이터 세트와 같은 작업에 820 만 개의 고품질 데이터를 통합합니다. | https://huggingface.co/datasets/shibing624/nli-zh-all |
| Shibing624/snli-zh | 영어 snli 및 multinli에서 번역 된 중국 snli 및 multinli 데이터 세트 | https://huggingface.co/datasets/shibing624/snli-zh |
| Shibing624/nli_zh | ATEC, BQ, LCQMC, PAWSX 및 STS-B를 포함한 5 가지 작업의 데이터 세트를 통합하는 중국 시맨틱 매칭 데이터 세트. | https://huggingface.co/datasets/shibing624/nli_zh 또는 Baidu NetDisk (추출 코드 : QKT6) 또는 github |
| Shibing624/STS-SOHU2021 | 중국 시맨틱 매칭 데이터 세트, 2021 Sohu 캠퍼스 텍스트 일치 알고리즘 경쟁 데이터 세트 | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| ATEC | 중국 ATEC 데이터 세트, Ant Financial Q-QPair 데이터 세트 | ATEC |
| BQ | 중국 BQ (은행 질문) 데이터 세트, 은행 Q-QPair 데이터 세트 | BQ |
| LCQMC | 중국 LCQMC (대규모 중국어 질문 일치 코퍼스) 데이터 세트, Q-QPair 데이터 세트 | LCQMC |
| pawsx | 중국 발 | pawsx |
| STS-B | 중국 STS-B 데이터 세트, 중국 자연 언어 추론 데이터 세트, 영어 STS-B에서 중국어까지 번역 된 데이터 세트 | STS-B |
일반적으로 사용되는 영어 일치 데이터 세트 :
데이터 세트 사용의 예 :
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])산출:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
연구에서 Text2Vec을 사용하는 경우 다음 형식으로 인용하십시오.
APA :
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecBibtex :
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}라이센스 계약은 Apache License 2.0으로, 상업적 목적으로 무료로 사용할 수 있습니다. Text2Vec의 링크 및 승인 계약을 제품 설명에 첨부하십시오.
프로젝트 코드는 여전히 매우 거칠다. 코드를 개선 한 경우이 프로젝트에 다시 제출할 수 있습니다. 제출하기 전에 다음 두 가지 점에주의하십시오.
tests 에 해당 단위 테스트를 추가하십시오python -m pytest -v 사용하여 모든 단위 테스트를 실행하여 모든 단일 테스트가 통과되었는지 확인하십시오.나중에 PR을 제출할 수 있습니다.


