text2vec
1.2.9
؟؟ الصينية | الإنجليزية | المستندات/المستندات | نماذج/نماذج

text2vec : نص إلى المتجه ، احصل على تضمينات الجملة. تخصيص النص ، يميز النص (بما في ذلك الكلمات والجمل والفقرات) كمصفوفة متجه.
يقوم Text2Vec بتنفيذ مجموعة متنوعة من تمثيل النص ونماذج حساب تشابه النص مثل Word2VEC ، و RANKBM25 ، و BERT ، و Secend-Bert ، و COSENT ، ومقارنة آثار كل نموذج على مهمة المطابقة الدلالية (حساب التشابه).
[2023/09/20] الإصدار V1.2.9: يدعم الاستدلال متعدد البطاقات (تنفيذ متعدد العمليات لاستدلال متعدد GPU متعدد GPU و Multi-CPU) ، تتم إضافة أداة سطر أوامر جديدة (CLI) ، والتي يمكن أن تقوم برامج البرمجة النصية لإجراء ضابط نصي الدُفعات. انظر الإصدار -V1.2.9 للحصول على التفاصيل.
[2023/09/03] الإصدار V1.2.4: يدعم تدريب نموذج FlageMbedding ، وأصدر نموذج المطابقة الصينية Shibing624/Text2Vec-Bge-Large-Chinese ، والذي يتم الإشراف عليه وتدريبه باستخدام طريقة cosent. تم تدريبه على أساس BAAI/bge-large-zh-noinstruct ، وقد تحسن تقييم مجموعة البيانات المطابقة الصينية مقارنة بالنموذج الأصلي. تم تحسين الفرق بين النص القصير بشكل كبير. انظر الإصدار -V1.2.4 للحصول على التفاصيل.
[2023/07/17] الإصدار V1.2.2: يدعم التدريب متعدد البطاقات ، وأصدر نموذج مطابقة متعدد اللغات shibing624/text2vec-base-myblingual ، والذي يتم تدريبه باستخدام طريقة cosent. استنادًا إلى sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 يتم تدريبها باستخدام مجموعة بيانات STS متعددة اللغات اليدوية shibing624/nli-zh-all/text2vec-base-multingupalualset ، والتقييم في مجموعة الاختبار الصينية والإنجليزية قد تحسنت مع النموذج الأصلي. انظر الإصدار -V1.2.2 للحصول على التفاصيل.
[2023/06/19] الإصدار V1.2.1: تم تحديث نموذج المطابقة الصينية shibing624/text2vec-base-chinese-nli كإصدار جديد من shibing624/text2vec-base-chinese. استنادًا إلى حساسية حساب فقدان Cosent للفرز ، تم اختيار مجموعة بيانات STS عالية الجودة مع فرز الارتباط يدويًا وفرزها ، مما أدى إلى تحسين أداء كل مجموعة تقييم مقارنةً بذلك ؛ تم إصدار نموذج مطابقة الصينية shibing624/text2vec-base-chinese-paraphrase لـ S2P ، انظر الإصدار -V1.2.1 للحصول على التفاصيل.
[2023/06/15] الإصدار V1.2.0: تم إصدار نموذج مطابقة الصينية Shibing624/Text2Vec-Base-Chinese-NLI. استنادًا إلى نموذج nghuyong/ernie-3.0-base-zh ، يتم استخدام نموذج مطابقة النص Cosent الذي تم تدريبه بواسطة مجموعة بيانات NLI الصينية shibing624/nli_zh. تم تحسين الأداء في كل مجموعة تقييم بشكل كبير. انظر الإصدار -V1.2.0 للحصول على التفاصيل.
[2022/03/12] الإصدار V1.1.4: تم إصدار نموذج المطابقة الصينية Shibing624/Text2Vec-base-chinese ، وهو نموذج مطابقة مدرب على أساس مجموعة تدريب STS الصينية. انظر الإصدار -V1.1.4 للحصول على التفاصيل
مرشد
راجع ويكي: طريقة تمثيل ناقلات النص للحصول على طريقة تمثيل متجه النص المفصل
مطابقة النص
| قوس | قاعدة | نموذج | اللغة الإنجليزية-ب |
|---|---|---|---|
| قفاز | جليف | avg_word_embeddings_glove_6b_300d | 61.77 |
| بيرت | Bert-Base-uncared | bert-base-cls | 20.29 |
| بيرت | Bert-Base-uncared | bert-base-first_last_avg | 59.04 |
| بيرت | Bert-Base-uncared | bert-base-first_last_avg-whiten (NLI) | 63.65 |
| Sbert | محولات الجملة/bert-base-nli-mean-tokens | Sbert-Base-NLI-Cls | 73.65 |
| Sbert | محولات الجملة/bert-base-nli-mean-tokens | Sbert-base-nli-first_last_avg | 77.96 |
| cosent | Bert-Base-uncared | cosent-base-first_last_avg | 69.93 |
| cosent | محولات الجملة/bert-base-nli-mean-tokens | cosent-base-nli-first_last_avg | 79.68 |
| cosent | محولات الجملة/إعادة صياغة minilm-L12-V2 | shibing624/text2vec-base-multilingual | 80.12 |
| قوس | قاعدة | نموذج | ATEC | BQ | LCQMC | PAWSX | STS-B | متوسط |
|---|---|---|---|---|---|---|---|---|
| Sbert | بيرت-القاعدة الصينية | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| Sbert | HFL/الصينية Macbert-base | Sbert-Macbert-Base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| Sbert | HFL/الصينية-روبرتا-WWM-EXT | Sbert-Roberta-Ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| cosent | بيرت-القاعدة الصينية | cosent-bert-base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| cosent | HFL/الصينية Macbert-base | cosent-macbert-base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| cosent | HFL/الصينية-روبرتا-WWM-EXT | cosent-roberta-ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
يوضح:
SBERT-macbert-base باستخدام طريقة SBERT ، وتشغيل أمثلة/REARDING_SUP_TEXT_MATCHING_MODEL.PY لتدريب النموذج.sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 مع Sbert ، وهو نسخة متعددة اللغات من نموذج paraphrase-MiniLM-L12-v2 ، ودعم اللغة الصينية ، والإنجليزية ، وما إلى ذلك.| قوس | قاعدة | نموذج | ATEC | BQ | LCQMC | PAWSX | STS-B | sohu-dd | Sohu-DC | متوسط | QPs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Word2Vec | Word2Vec | W2V-Light-Tencent-Chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| Sbert | XLM-Roberta-base | محولات الجملة/إعادة صياغة minilm-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| cosent | HFL/الصينية Macbert-base | Shibing624/text2vec-base-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| cosent | HFL/صينية لتر | Ganymedenil/text2vec-large-chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| cosent | nghuyong/ernie-3.0-base-zh | shibing624/text2vec-base-chinese-sentence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| cosent | nghuyong/ernie-3.0-base-zh | Shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| cosent | محولات الجملة/إعادة صياغة minilm-L12-V2 | shibing624/text2vec-base-multilingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| cosent | باي/bge-large-zh-noinstruct | shibing624/text2vec-bge-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
يوضح:
shibing624/text2vec-base-chinese باستخدام طريقة cosent ، المدربين على بيانات STS-B الصينية القائمة على hfl/chinese-macbert-base ، وتقييمها في اختبار STS-B الصيني لتحقيق نتائج جيدة. قم بتشغيل أمثلة/تدريب _sup_text_matching_model.py لتدريب النموذج. تم تحميل ملف النموذج إلى HF Model Hub. يوصى باستخدام مهمة المطابقة الدلالية العامة الصينية.shibing624/text2vec-base-chinese-sentence باستخدام طريقة cosent. يتم تدريبه بناءً على مجموعة بيانات بيانات STS الصينية التي تم اختيارها يدويًا SHIBING624/NLI-ZH-All/Text2VEC- nghuyong/ernie-3.0-base-zh البيانات-ويتم تقييمها في مجموعات اختبار NLI الصينية المختلفة لتحقيق نتائج جيدة. قم بتشغيل الأمثلة/التدريب _sup_text_matching_model_jsonl_data.py لتدريب النموذج. تم تحميل ملف النموذج إلى HF Model Hub. يوصى باستخدام مهمة المطابقة الدلالية S2S الصينية (الجملة مقابل الجملة)shibing624/text2vec-base-chinese-paraphrase باستخدام طريقة cosent. استنادًا إلى مجموعة بيانات STS الصينية التي تم اختيارها بواسطة nghuyong/ernie-3.0-base-zh ، SHIBING624/NLI-ZH-ALL/TEXT2VEC-BASE-CHINESE-PARAPHRASE-DATASET ، تتم إضافة مجموعة البيانات إلى S2P (عقوبة "S2P). إعادة صياغة) تعزز البيانات قدرتها على تمثيل النص الطويل ، وتقييم لتحقيق SOTA في مختلف مجموعات اختبار NLI الصينية. قم بتشغيل أمثلة/تدريب _sup_text_matching_model_jsonl_data.py لتدريب النموذج. تم تحميل ملف النموذج إلى HF Model Hub. يوصى بمهمة المطابقة الدلالية S2P الصينية (الجملة مقابل الفقرة).shibing624/text2vec-base-multilingual على طريقة cosent. يتم تدريبه على أساس sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 باستخدام مجموعة بيانات STS متعددة اللغات التي تم اختيارها يدويًا shibing624/nli-zh-all/text2vec-base-multilingualual. يتم تقييمه في مجموعة الاختبار الصينية والإنجليزية ، ويتم تحسين التأثير مقارنة بالنموذج الأصلي. قم بتشغيل الأمثلة/التدريب _sup_text_matching_model_jsonl_data.py لتدريب النموذج. تم تحميل ملف النموذج إلى HF Model Hub. يوصى باستخدام مهمة المطابقة الدلالية متعددة اللغات.shibing624/text2vec-bge-large-chinese باستخدام طريقة cosent. يتم تدريبه على أساس BAAI/bge-large-zh-noinstruct باستخدام مجموعة بيانات STS الصينية التي تم اختيارها يدويًا Shibing624/NLI-ZH-All/Text2Vec-base-chinese-dataset. حسّن التقييم في مجموعة الاختبار الصينية التأثير مقارنة بالنموذج الأصلي ، وتحسن الفرق في النص القصير بشكل كبير. قم بتشغيل الأمثلة/التدريب _sup_text_matching_model_jsonl_data.py لتدريب النموذج. تم تحميل ملف النموذج إلى HF Model Hub. يوصى باستخدام مهمة المطابقة الدلالية S2S الصينية (الجملة مقابل الجملة)w2v-light-tencent-chinese هو نموذج Word2Vec لناقلات Tencent Word ، يستخدم بواسطة تحميل وحدة المعالجة المركزية ، ومناسبة لمهام المطابقة الحرفية الصينية وحالات البدء الباردة للبيانات المفقودة--model_name hfl/chinese-macbert-base أو Roberta Model: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVG و EncoderType.MEAN ، وتأثيرات التنبؤات من الاثنين صغيرة جدًا.examples/data وتشغيل كود الاختبارات/model_spearman.py لإعادة إنتاج نتائج التقييم.التقرير التجريبي التدريبي النموذجي: التقرير التجريبي
العرض التوضيحي الرسمي: https://www.mulanai.com/product/short_text_sim/
Huggingface Demo: https://huggingface.co/spaces/shibing624/text2vec

قم بتشغيل مثال: أمثلة/gradio_demo.py لرؤية العرض التوضيحي:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecأو
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . حساب ناقلات النص على أساس pretrained model :
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)مثال: أمثلة/computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )الإخراج:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddings قيمة الإرجاع هي type numpy.ndarray ، الشكل هو (sentences_size, model_embedding_size) ، ويمكنك اختيار أي من النماذج الثلاثة. أول واحد يوصى به.shibing624/text2vec-base-chinese من خلال تدريب طريقة cosent في مجموعة بيانات STS-B الصينية. تم تحميل النموذج على مكتبة النموذج لـ Huggingface Shibing624/text2vec-base-chinese. هذا هو النموذج الافتراضي المحدد بواسطة text2vec.SentenceModel . يمكن استدعاؤه من خلال المثال أعلاه ، أو يمكن استدعاؤه مع مكتبة Transformers كما هو موضح أدناه. سيتم تنزيل النموذج تلقائيًا على المسار الأصلي: ~/.cache/huggingface/transformersw2v-light-tencent-chinese هو نموذج Word2VEC محمله من خلال Gensim. يتم حساب ناقلات كلمة كل كلمة باستخدام Tencent Word Vector Tencent_AILab_ChineseEmbedding.tar.gz يتم حساب متوسط ناقل الجملة من خلال ناقلات الكلمات. يتم تنزيل النموذج تلقائيًا على المسار الأصلي: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vec الاستدلال متعدد البطاقات (حساب ناقل النص): أمثلة/computing_embeddings_multi_gpu_demo.py بدون Text2Vec ، يمكنك استخدام النموذج مثل هذا:
أولاً ، تقوم بتمرير مدخلاتك من خلال نموذج المحول ، ثم عليك تطبيق عملية التجميع اليمنى على قمة تضمينات الكلمة السياقية.
مثال: أمثلة/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )محولات الجملة هي مكتبة شهيرة لحساب تمثيلات المتجهات الكثيفة للجمل.
قم بتثبيت محولات الجملة:
pip install -U sentence-transformersثم تحميل النموذج والتنبؤ:
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec Word Vector قم بتوفير ناقلات Word2Vec Word ، اختياريًا واحدًا:
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bin~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt ، tencent Word Vector Home Page: https://ai.tencent.com/ailab/nlp/en/download.html المزيددعم اكتساب الدفعة من ناقلات النص
الكود: cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
يجري:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu Trueملف الإدخال (مطلوب):
input.txt، التنسيق: نص الجملة من جملة واحدة ، سطر واحد.
مثال: أمثلة/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))الإخراج:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591نطاق
scoreلقيمة تشابه جيب التمام هو [-1 ، 1] ، وكلما زادت القيمة ، زادت تشابهها.
بشكل عام ، تم العثور على نص يشبه الاستعلام في مجموعة مرشح الوثيقة ، وغالبًا ما يتم استخدامه في مهام مثل مطابقة التشابه في أسئلة واسترجاع تشابه النص في سيناريوهات ضمان الجودة.
مثال: أمثلة/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))الإخراج:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)مكتبة أوجه التشابه [الموصى بها]
بالنسبة لحساب تشابه النص ومهام البحث المطابقة للنص ، يوصى باستخدام مكتبة أوجه التشابه ، والتي تتوافق مع نماذج المطابقة الدلالية الشبيهة بـ Word2Vec و Sbert و Cosent في هذا المشروع. كما أنه يدعم 100 مليون عملية بحث رسومية على مستوى ، ويدعم إرسال نصي الدلالي ، وإلهاء الصور وغيرها من الوظائف.
التثبيت: pip install -U similarities
حساب تشابه الجملة:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 نموذج مطابقة النص (جملة جيب التمام) ، يحسن مخطط ناقل الجملة CosinerankLoss
هيكل الشبكة:
تمرين:
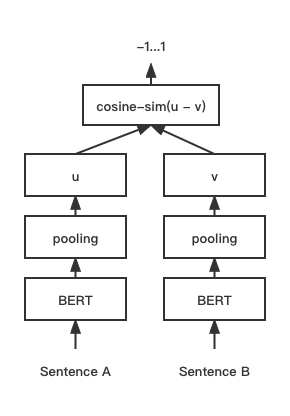
الاستدلال:
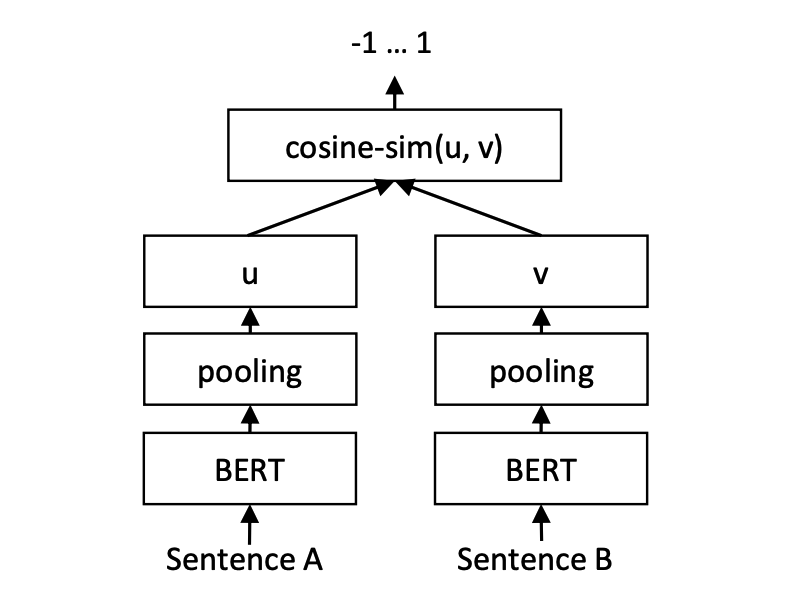
تدريب وتنبؤ نماذج cosent:
CoSENT على مجموعة بيانات STS-B الصينيةمثال: أمثلة/تدريب _sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENT على مجموعة بيانات المطابقة المالية ANTادعم استخدام مجموعات بيانات المطابقة الصينية هذه: "ATEC" ، "STS-B" ، "BQ" ، "LCQMC" ، "Pawsx" ، للحصول على تفاصيل ، يرجى الرجوع إلى مجموعات بيانات Huggingface https://huggingface.co/datasets/shibing624/nli_zh
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosentمثال: أمثلة/تدريب _sup_text_matching_model_mydata.py
تدريب على بطاقة واحدة:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictتدريب Doka:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel أمثلة مرجعية/بيانات/STS-B/STS-B.Valid.data لتنسيق مجموعة التدريب
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 يمكن أن تكون label ملصقات 0 و 1 ، و 0 يعني أن الجملتين غير متشابهتين ، و 1 يعني متشابهة ؛ يمكن أن يكون أيضا درجة 0-5. كلما ارتفعت النتيجة ، كلما كانت الجملتين أكثر تشابهًا. يمكن دعم جميع النماذج.
CoSENT على مجموعة بيانات English STS-Bمثال: أمثلة/تدريب _sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENT نموذج بيانات NLI في اللغة الإنجليزية وتقييم التأثير في مجموعة اختبار STS-Bمثال: أمثلة/تدريب _unsup_text_matching_model_en.py
cd examples
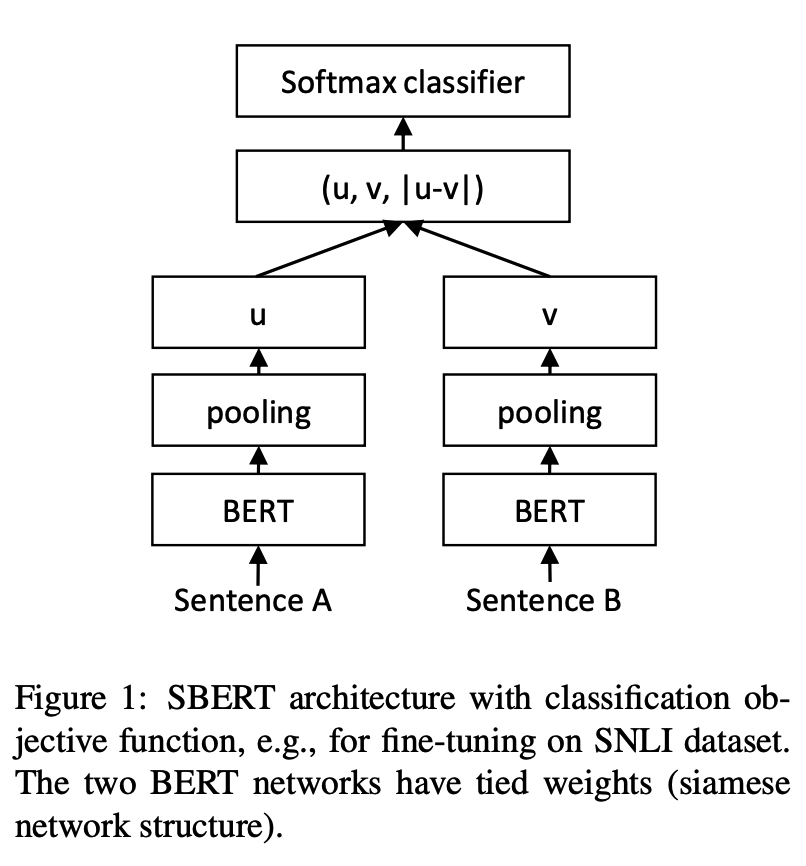
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosentنموذج مطابقة النصوص-نموذج تمثيلي ، مخطط تمثيلي تمثيل ناقلات الجملة
هيكل الشبكة:
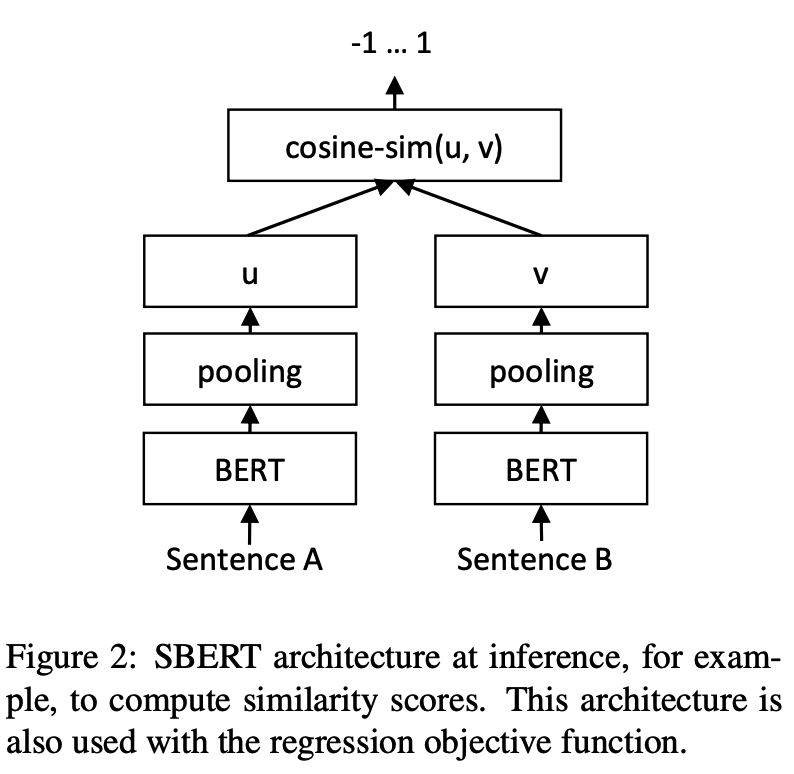
تمرين:
الاستدلال:
SBERT على مجموعة بيانات STS-B الصينيةمثال: أمثلة/تدريب _sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERT على مجموعة بيانات STS-B الإنجليزيةمثال: أمثلة/تدريب _sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERT في مجموعة بيانات NLI الإنجليزية وتقييم التأثير في مجموعة اختبار STS-Bمثال: أمثلة/تدريب _unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertنموذج مطابقة نص Bert ، بنية شبكة مطابقة Bert الأصلية ، نموذج مطابقة متجه الجملة التفاعلية
هيكل الشبكة:
التدريب والاستدلال:
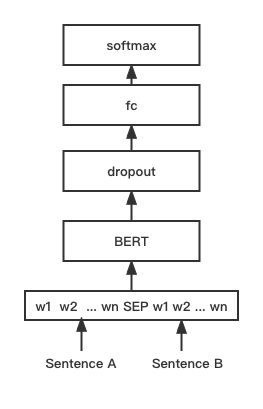
البرنامج النصي التدريبي هو نفسه كما ورد أعلاه/التدريب _sup_text_matching_model.py.
BGE على مجموعة بيانات STS-B الصينيةمثال: أمثلة/تدريب _bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGE Model Tuning Trening ، باستخدام التعلم على النقيض لتدريب النموذج ، فإن تنسيق بيانات الإدخال هو ثلاثية (استعلام ، إيجابي ، سلبي) "
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py يولد مجموعة تدريب ثلاثية تعتمد على STS-B الصينية ، مع التنسيق على النحو التالي: { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py مطابقة FAISS مماثلة ، مما يجعل من الصعب التعدين أمثلة سلبية.نظرًا لأن النماذج المدربة Text2VEC يمكن تحميلها باستخدام مكتبة محولات الجملة ، فإن طريقة التقطير النموذجية الخاصة بها تعدد الإرسال هنا.
توفير نموذجين وطرق نشر لبناء الخدمات: 1) بناء خدمات GRPC استنادًا إلى Jina [الموصى بها] ؛ 2) بناء خدمات HTTP الأصلية على أساس fastapi.
يستخدم وضع C/S لإنشاء خدمات عالية الأداء ، ويدعم Docker Cloud Native و GRPC/HTTP/WebSocket ، يدعم التنبؤ المتزامن لنماذج متعددة ومعالجة بطاقات GPU متعددة البطاقات.
تثبيت: pip install jina
ابدأ الخدمة:
مثال: أمثلة/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()تم تحميل طريقة التنبؤ النموذجية (Executor) إلى Jinahub ، بما في ذلك طرق نشر Docker و K8S.
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )انظر مثال: أمثلة/jina_client_demo.py للحصول على أساليب استدعاء الدُفعات
التثبيت: pip install fastapi uvicorn
ابدأ الخدمة:
مثال: أمثلة/fastapi_server_demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | مجموعة البيانات | مقدمة | الرابط تنزيل |
|---|---|---|
| Shibing624/NLI-ZH-All | جمع بيانات المطابقة الدلالية الصينية ، ودمج 8.2 مليون بيانات عالية الجودة للمهام مثل التفكير النصية ، والتشابه ، والملخص ، والسؤال والإجابة ، وضبط التعليمات ، وتحويلها إلى مجموعة بيانات تنسيق المطابقة | https://huggingface.co/Datasets/shibing624/nli- zh- All |
| Shibing624/snli-zh | مجموعات بيانات SNLI الصينية و multinli ، ترجمت من اللغة الإنجليزية SNLI و multinli | https://huggingface.co/Datasets/shibing624/snli- zh |
| shibing624/nli_zh | مجموعة بيانات المطابقة الدلالية الصينية ، دمج مجموعات البيانات من 5 مهام ، بما في ذلك ATEC و BQ و LCQMC و PAWSX و STS-B. | https://huggingface.co/Datasets/shibing624/nli_zh أو Baidu NetDisk (رمز الاستخراج: QKT6) أو جيثب |
| shibing624/sts-sohu2021 | مجموعة بيانات DATASING الصينية الدلالية ، 2021 SOHU CAMPUS TEXT TEXT MATINGEN | https://huggingface.co/Datasets/Shibing624/STS-OSHU2021 |
| ATEC | مجموعة بيانات ATEC الصينية ، مجموعة بيانات ANT Financial Q-QPair | ATEC |
| BQ | مجموعة بيانات BQ الصينية (سؤال البنك) ، مجموعة بيانات بنك Q-QPAIR | BQ |
| LCQMC | LCQMC الصينية (مجموعة بيانات أسئلة صينية واسعة النطاق) ، مجموعة بيانات Q-QPAIR | LCQMC |
| PAWSX | الكفوف الصينية (خصوم إعادة صياغة من مجموعة البيانات) مجموعة بيانات Q-QPair | PAWSX |
| STS-B | مجموعة بيانات STS-B الصينية ، مجموعة بيانات استنتاج اللغة الطبيعية الصينية ، مجموعة البيانات المترجمة من اللغة الإنجليزية STS-B إلى الصينية | STS-B |
مجموعات بيانات مطابقة اللغة الإنجليزية شائعة الاستخدام:
مثال على استخدام مجموعة البيانات:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])الإخراج:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
إذا كنت تستخدم Text2Vec في بحثك ، فيرجى اقتباسه بالتنسيق التالي:
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecbibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}اتفاقية الترخيص هي ترخيص Apache 2.0 ، والذي يمكن استخدامه لأغراض تجارية مجانًا. يرجى إرفاق اتفاقية الرابط والترخيص لـ Text2Vec بوصف المنتج.
لا يزال رمز المشروع خشنًا للغاية. إذا قمت بتحسين الرمز ، فأنت مرحب بك لإرساله إلى هذا المشروع. قبل تقديمه ، انتبه إلى النقطتين التاليتين:
testspython -m pytest -v لتشغيل جميع اختبارات الوحدة ، مع التأكد من اجتياز جميع الاختبارات الفرديةيمكنك تقديم العلاقات العامة الخاصة بك لاحقًا.


