text2vec
1.2.9
??中国語|英語|ドキュメント/ドキュメント| ?モデル/モデル

text2vec :テキストからベクトルへ、文の埋め込みを取得します。テキストベクトル化は、テキスト(単語、文、段落を含む)をベクトルマトリックスとして特徴付けます。
Text2VECは、Word2vec、rankbm25、bert、centebert、cosentなどのさまざまなテキスト表現とテキストの類似性計算モデルを実装し、テキストセマンティックマッチング(類似性計算)タスクに対する各モデルの効果を比較します。
[2023/09/20] v1.2.9バージョン:マルチカード推論(マルチGPUおよびマルチCPU推論のマルチプロセス実装)をサポートします。新しいコマンドラインツール(CLI)が追加されます。詳細については、リリース-V1.2.9を参照してください。
[2023/09/03] v1.2.4バージョン:Flagembedding Model Trainingをサポートし、Cosentメソッドを使用して監督および訓練された中国のマッチングモデルShibing624/Text2Vec-BGE-Large-Chineseをリリースしました。 BAAI/bge-large-zh-noinstructに基づいて訓練されており、元のモデルと比較して中国語の一致するデータセットの評価が改善されました。短いテキストの違いは大幅に改善されています。詳細については、リリース-V1.2.4を参照してください。
[2023/07/17] v1.2.2バージョン:マルチカードトレーニングをサポートし、Cosentメソッドを使用してトレーニングされているマルチ言語マッチングモデルShibing624/text2vec-base-multilingualをリリースしました。 sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2手動の多言語STSデータセットShibing624/NLI-ZH-ALL/TEXT2VEC-BASE-MULTINGUAL-DATASETを使用してトレーニングされ、中国と英語のテストセットの評価は元のモデルと比較して効果を改善しました。詳細については、リリース-V1.2.2を参照してください。
[2023/06/19] v1.2.1バージョン:中国のマッチングモデルshibing624/text2vec-base-chinese-nli shibing624/text2vec-base-chinese-sentenceの新しいバージョンとして更新されます。ソーティングに対するCosentの損失計算の感度に基づいて、相関ソートを使用した高品質のSTSデータセットが手動で選択され、ソートされたため、それと比較して各評価セットのパフォーマンスが向上しました。 S2Pの中国のマッチングモデルShibing624/Text2Vec-Base-Chinese-Paraphraseがリリースされました。詳細については、Release-V1.2.1を参照してください。
[2023/06/15] v1.2.0バージョン:中国のマッチングモデルShibing624/text2vec-base-chinese-nliがリリースされました。 nghuyong/ernie-3.0-base-zhモデルに基づいて、中国のNLIデータセットShibing624/nli_zhによって訓練されたCosentテキストマッチングモデルが使用されます。各評価セットのパフォーマンスは大幅に改善されます。詳細については、リリース-V1.2.0を参照してください。
[2022/03/12] v1.1.4バージョン:中国のマッチングモデルShibing624/text2vec-base-chineseがリリースされました。詳細については、Release-V1.1.4を参照してください
ガイド
Wikiを参照:詳細なテキストベクトル表現方法については、テキストベクトル表現方法
テキストマッチング
| アーチ | ベースモデル | モデル | English-sts-b |
|---|---|---|---|
| グローブ | グレブ | avg_word_embeddings_glove_6b_300d | 61.77 |
| バート | Bert-Base-Uncased | bert-base-cls | 20.29 |
| バート | Bert-Base-Uncased | bert-base-first_last_avg | 59.04 |
| バート | Bert-Base-Uncased | bert-base-first_last_avg-whiten(nli) | 63.65 |
| sbert | Sente-Transformers/Bert-Base-Nli-Mean-Tokens | sbert-base-nli-cls | 73.65 |
| sbert | Sente-Transformers/Bert-Base-Nli-Mean-Tokens | sbert-base-nli-first_last_avg | 77.96 |
| コセント | Bert-Base-Uncased | Cosent-base-first_last_avg | 69.93 |
| コセント | Sente-Transformers/Bert-Base-Nli-Mean-Tokens | Cosent-base-nli-first_last_avg | 79.68 |
| コセント | 文と変換器/言い換え - マルチリンガル・ミニルム-L12-V2 | Shibing624/text2vec-base-multilingual | 80.12 |
| アーチ | ベースモデル | モデル | ATEC | BQ | LCQMC | Pawsx | sts-b | 平均 |
|---|---|---|---|---|---|---|---|---|
| sbert | バート・ベース・チネーゼ | Sbert-Bert-Base | 46.36 | 70.36 | 78.72 | 46.86 | 66.41 | 61.74 |
| sbert | HFL/中国 - マクバートベース | sbert-macbert-base | 47.28 | 68.63 | 79.42 | 55.59 | 64.82 | 63.15 |
| sbert | HFL/中国 - ロベルタ-WWM-Ext | sbert-roberta-ext | 48.29 | 69.99 | 79.22 | 44.10 | 72.42 | 62.80 |
| コセント | バート・ベース・チネーゼ | Cosent-Bert-Base | 49.74 | 72.38 | 78.69 | 60.00 | 79.27 | 68.01 |
| コセント | HFL/中国 - マクバートベース | Cosent-Macbert-Base | 50.39 | 72.93 | 79.17 | 60.86 | 79.30 | 68.53 |
| コセント | HFL/中国 - ロベルタ-WWM-Ext | Cosent-Roberta-Ext | 50.81 | 71.45 | 79.31 | 61.56 | 79.96 | 68.61 |
説明:
SBERT-macbert-baseモデルは、Stbert Methodを使用してトレーニングされており、モデルをトレーニングするために例/training_sup_text_matching_model.pyコードを実行します。sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2モデルは、スバートでトレーニングされており、中国語、英語などをサポートするparaphrase-MiniLM-L12-v2モデルの多言語バージョンです。| アーチ | ベースモデル | モデル | ATEC | BQ | LCQMC | Pawsx | sts-b | sohu-dd | Sohu-dc | 平均 | QPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| word2vec | word2vec | w2v-light-tencent-chinese | 20.00 | 31.49 | 59.46 | 2.57 | 55.78 | 55.04 | 20.70 | 35.03 | 23769 |
| sbert | xlm-roberta-base | 文と変換器/言い換え - マルチリンガル・ミニルム-L12-V2 | 18.42 | 38.52 | 63.96 | 10.14 | 78.90 | 63.01 | 52.28 | 46.46 | 3138 |
| コセント | HFL/中国 - マクバートベース | Shibing624/text2vec-base-chinese | 31.93 | 42.67 | 70.16 | 17.21 | 79.30 | 70.27 | 50.42 | 51.61 | 3008 |
| コセント | HFL/中国語と主張 | Ganymedenil/text2vec-large-chinese | 32.61 | 44.59 | 69.30 | 14.51 | 79.44 | 73.01 | 59.04 | 53.12 | 2092 |
| コセント | nghuyong/ernie-3.0-base-zh | Shibing624/text2vec-base-chinese-sentence | 43.37 | 61.43 | 73.48 | 38.90 | 78.25 | 70.60 | 53.08 | 59.87 | 3089 |
| コセント | nghuyong/ernie-3.0-base-zh | Shibing624/text2vec-base-chinese-paraphrase | 44.89 | 63.58 | 74.24 | 40.90 | 78.93 | 76.70 | 63.30 | 63.08 | 3066 |
| コセント | 文と変換器/言い換え - マルチリンガル・ミニルム-L12-V2 | Shibing624/text2vec-base-multilingual | 32.39 | 50.33 | 65.64 | 32.56 | 74.45 | 68.88 | 51.17 | 53.67 | 3138 |
| コセント | baai/bge-large-zh-noinstruct | Shibing624/text2vec-bge-large-chinese | 38.41 | 61.34 | 71.72 | 35.15 | 76.44 | 71.81 | 63.15 | 59.72 | 844 |
説明:
shibing624/text2vec-base-chineseモデルは、Cosentメソッドを使用してトレーニングされ、 hfl/chinese-macbert-baseに基づいた中国のSTS-Bデータで訓練され、良好な結果を達成するために中国のSTS-Bテストセットで評価されます。例/training_sup_text_matching_model.pyコードを実行して、モデルをトレーニングします。モデルファイルは、HFモデルハブにアップロードされています。中国の一般的なセマンティックマッチングタスクを使用することをお勧めします。shibing624/text2vec-base-chinese-sentenceモデルは、Cosentメソッドを使用してトレーニングされています。手動で選択された中国のSTSデータセットSHIBING624/NLI-ZH-ALL/TEXT2VEC- nghuyong/ernie-3.0-base-zh -CINESE-SENTENCE-DATASETに基づいて訓練されており、さまざまな中国のNLIテストセットで評価され、良い結果が得られます。 examples/training_sup_text_matching_model_jsonl_data.pyコードを実行して、モデルをトレーニングします。モデルファイルは、HFモデルハブにアップロードされています。中国のS2S(文vs文)セマンティックマッチングタスクを使用することをお勧めしますshibing624/text2vec-base-chinese-paraphraseモデルは、Cosentメソッドを使用してトレーニングされています。 Based on the Chinese STS dataset selected by nghuyong/ernie-3.0-base-zh manually, shibing624/nli-zh-all/text2vec-base-chinese-paraphrase-dataset, the dataset is added to s2p (sentence to) relative to shibing624/nli-zh-all/text2vec-base-chinese-sentence-dataset.言い換え)データは、長いテキスト表現能力を強化し、さまざまな中国のNLIテストセットでSOTAを達成するために評価します。例/training_sup_text_matching_model_jsonl_data.pyコードを実行して、モデルをトレーニングします。モデルファイルは、HFモデルハブにアップロードされています。中国のS2P(文と段落)セマンティックマッチングタスクをお勧めします。shibing624/text2vec-base-multilingualモデルは、Cosentメソッドを使用してトレーニングされています。手動で選択された多言語STSデータセットShibing624/NLI-ZH-ALL/TEXT2VEC-BASE-MULTINGUAL-DATASETを使用してsentence-transformers/paraphrase-multilingual-MiniLM-L12-v2に基づいて訓練されています。中国と英語のテストセットで評価され、元のモデルと比較して効果が改善されます。 examples/training_sup_text_matching_model_jsonl_data.pyコードを実行して、モデルをトレーニングします。モデルファイルは、HFモデルハブにアップロードされています。多言語セマンティックマッチングタスクを使用することをお勧めします。shibing624/text2vec-bge-large-chineseモデルは、Cosentメソッドを使用してトレーニングされています。手動で選択された中国のSTSデータセットSHIBING624/NLI-ZH-ALL/TEXT2VEC-BASE-CHINESE-PARAPHRASE-DATASETを使用してBAAI/bge-large-zh-noinstructに基づいて訓練されています。中国のテストセットの評価により、元のモデルと比較して効果が改善され、短いテキストの違いが大幅に改善されました。 examples/training_sup_text_matching_model_jsonl_data.pyコードを実行して、モデルをトレーニングします。モデルファイルは、HFモデルハブにアップロードされています。中国のS2S(文vs文)セマンティックマッチングタスクを使用することをお勧めしますw2v-light-tencent-chinese中国の文字通りのマッチングタスクと欠落データのコールドスタート状況に適したCPUロードで使用されるTencent Word Vectorsの単語2VECモデルです。--model_name hfl/chinese-macbert-baseまたはrobertaモデル: --model_name uer/roberta-medium-wwm-chinese-cluecorpussmallEncoderType.FIRST_LAST_AVGおよびEncoderType.MEANに最適であり、2つの予測効果が非常に小さいことを示しています。examples/dataにダウンロードし、テスト/model_spearman.pyコードを実行して、評価結果を再現できます。モデルトレーニング実験レポート:実験レポート
公式デモ:https://www.mulanai.com/product/short_text_sim/
Huggingfaceデモ:https://huggingface.co/spaces/shibing624/text2vec

実行例:例/gradio_demo.pyデモを見るには:
python examples/gradio_demo.pypip install torch # conda install pytorch
pip install -U text2vecまたは
pip install torch # conda install pytorch
pip install -r requirements.txt
git clone https://github.com/shibing624/text2vec.git
cd text2vec
pip install --no-deps . pretrained modelに基づいてテキストベクトルを計算します。
>>> from text2vec import SentenceModel
>>> m = SentenceModel ()
>>> m.encode( "如何更换花呗绑定银行卡" )
Embedding shape: (768,)例:Examples/Computing_embeddings_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel
from text2vec import Word2Vec
def compute_emb ( model ):
# Embed a list of sentences
sentences = [
'卡' ,
'银行卡' ,
'如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ,
'This framework generates embeddings for each input sentence' ,
'Sentences are passed as a list of string.' ,
'The quick brown fox jumps over the lazy dog.'
]
sentence_embeddings = model . encode ( sentences )
print ( type ( sentence_embeddings ), sentence_embeddings . shape )
# The result is a list of sentence embeddings as numpy arrays
for sentence , embedding in zip ( sentences , sentence_embeddings ):
print ( "Sentence:" , sentence )
print ( "Embedding shape:" , embedding . shape )
print ( "Embedding head:" , embedding [: 10 ])
print ()
if __name__ == "__main__" :
# 中文句向量模型(CoSENT),中文语义匹配任务推荐,支持fine-tune继续训练
t2v_model = SentenceModel ( "shibing624/text2vec-base-chinese" )
compute_emb ( t2v_model )
# 支持多语言的句向量模型(CoSENT),多语言(包括中英文)语义匹配任务推荐,支持fine-tune继续训练
sbert_model = SentenceModel ( "shibing624/text2vec-base-multilingual" )
compute_emb ( sbert_model )
# 中文词向量模型(word2vec),中文字面匹配任务和冷启动适用
w2v_model = Word2Vec ( "w2v-light-tencent-chinese" )
compute_emb ( w2v_model )出力:
<class 'numpy.ndarray'> (7, 768)
Sentence: 卡
Embedding shape: (768,)
Sentence: 银行卡
Embedding shape: (768,)
...
embeddingsは、type numpy.ndarray 、shape is (sentences_size, model_embedding_size)であり、3つのモデルのいずれかを選択できます。最初のものをお勧めします。shibing624/text2vec-base-chineseモデルは、中国のSTS-BデータセットでのCOSENTメソッドトレーニングによって取得されます。このモデルは、Huggingface Shibing624/text2vec-base-chineseのモデルライブラリにアップロードされています。これは、 text2vec.SentenceModelで指定されたデフォルトモデルです。上記の例で呼び出すことも、以下に示すようにトランスライブラリで呼び出すこともできます。モデルはネイティブパスに自動的にダウンロードされます: ~/.cache/huggingface/transformersw2v-light-tencent-chinese Gensimを介してロードされるWord2Vecモデルです。各単語の単語ベクトルは、tencent word vector Tencent_AILab_ChineseEmbedding.tar.gz文ベクトルは、単語のベクトルを介して平均化されます。モデルはネイティブパスに自動的にダウンロードされます: ~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.bintext2vecマルチカード推論をサポートします(テキストベクトルの計算):Examples/computing_embeddings_multi_gpu_demo.py text2vecがなければ、次のようなモデルを使用できます。
最初に、トランスモデルを介して入力を渡し、次に、コンテキスト化された単語埋め込みの適切なプーリングオペレーションのオントップを適用する必要があります。
例:例/use_origin_transformers_demo.py
import os
import torch
from transformers import AutoTokenizer , AutoModel
os . environ [ "KMP_DUPLICATE_LIB_OK" ] = "TRUE"
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling ( model_output , attention_mask ):
token_embeddings = model_output [ 0 ] # First element of model_output contains all token embeddings
input_mask_expanded = attention_mask . unsqueeze ( - 1 ). expand ( token_embeddings . size ()). float ()
return torch . sum ( token_embeddings * input_mask_expanded , 1 ) / torch . clamp ( input_mask_expanded . sum ( 1 ), min = 1e-9 )
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer . from_pretrained ( 'shibing624/text2vec-base-chinese' )
model = AutoModel . from_pretrained ( 'shibing624/text2vec-base-chinese' )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
# Tokenize sentences
encoded_input = tokenizer ( sentences , padding = True , truncation = True , return_tensors = 'pt' )
# Compute token embeddings
with torch . no_grad ():
model_output = model ( ** encoded_input )
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling ( model_output , encoded_input [ 'attention_mask' ])
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Sente-Transformersは、文の密なベクトル表現を計算するための人気のあるライブラリです。
Sente-Transformersのインストール:
pip install -U sentence-transformers次に、モデルをロードして予測します。
from sentence_transformers import SentenceTransformer
m = SentenceTransformer ( "shibing624/text2vec-base-chinese" )
sentences = [ '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' ]
sentence_embeddings = m . encode ( sentences )
print ( "Sentence embeddings:" )
print ( sentence_embeddings )Word2Vec word vector 2つのWord2Vecワードベクトルを提供します。
~/.text2vec/datasets/light_Tencent_AILab_ChineseEmbedding.binは~/.text2vec/datasets/Tencent_AILab_ChineseEmbedding.txt 、tencent word vectorホームページ:https://ai.tencent.com/ailab/nlp/zh/index.htmlワードvector Download: https://ai.tencent.com/ailab/nlp/en/download.html詳細Tencent Word Vector Introduction-wikiを見るテキストベクトルのバッチ取得をサポートします
コード:Cli.py
> text2vec -h
usage: text2vec [-h] --input_file INPUT_FILE [--output_file OUTPUT_FILE] [--model_type MODEL_TYPE] [--model_name MODEL_NAME] [--encoder_type ENCODER_TYPE]
[--batch_size BATCH_SIZE] [--max_seq_length MAX_SEQ_LENGTH] [--chunk_size CHUNK_SIZE] [--device DEVICE]
[--show_progress_bar SHOW_PROGRESS_BAR] [--normalize_embeddings NORMALIZE_EMBEDDINGS]
text2vec cli
optional arguments:
-h, --help show this help message and exit
--input_file INPUT_FILE
input file path, text file, required
--output_file OUTPUT_FILE
output file path, output csv file, default text_embs.csv
--model_type MODEL_TYPE
model type: sentencemodel, word2vec, default sentencemodel
--model_name MODEL_NAME
model name or path, default shibing624/text2vec-base-chinese
--encoder_type ENCODER_TYPE
encoder type: MEAN, CLS, POOLER, FIRST_LAST_AVG, LAST_AVG, default MEAN
--batch_size BATCH_SIZE
batch size, default 32
--max_seq_length MAX_SEQ_LENGTH
max sequence length, default 256
--chunk_size CHUNK_SIZE
chunk size to save partial results, default 1000
--device DEVICE device: cpu, cuda, default None
--show_progress_bar SHOW_PROGRESS_BAR
show progress bar, default True
--normalize_embeddings NORMALIZE_EMBEDDINGS
normalize embeddings, default False
--multi_gpu MULTI_GPU
multi gpu, default False
走る:
pip install text2vec -U
text2vec --input_file input.txt --output_file out.csv --batch_size 128 --multi_gpu True入力ファイル(必須):
input.txt、形式:1つの文の文のテキスト、1行。
例:Examples/semantic_text_similarity_demo.py
import sys
sys . path . append ( '..' )
from text2vec import Similarity
# Two lists of sentences
sentences1 = [ '如何更换花呗绑定银行卡' ,
'The cat sits outside' ,
'A man is playing guitar' ,
'The new movie is awesome' ]
sentences2 = [ '花呗更改绑定银行卡' ,
'The dog plays in the garden' ,
'A woman watches TV' ,
'The new movie is so great' ]
sim_model = Similarity ()
for i in range ( len ( sentences1 )):
for j in range ( len ( sentences2 )):
score = sim_model . get_score ( sentences1 [ i ], sentences2 [ j ])
print ( "{} t t {} t t Score: {:.4f}" . format ( sentences1 [ i ], sentences2 [ j ], score ))出力:
如何更换花呗绑定银行卡 花呗更改绑定银行卡 Score: 0.9477
如何更换花呗绑定银行卡 The dog plays in the garden Score: -0.1748
如何更换花呗绑定银行卡 A woman watches TV Score: -0.0839
如何更换花呗绑定银行卡 The new movie is so great Score: -0.0044
The cat sits outside 花呗更改绑定银行卡 Score: -0.0097
The cat sits outside The dog plays in the garden Score: 0.1908
The cat sits outside A woman watches TV Score: -0.0203
The cat sits outside The new movie is so great Score: 0.0302
A man is playing guitar 花呗更改绑定银行卡 Score: -0.0010
A man is playing guitar The dog plays in the garden Score: 0.1062
A man is playing guitar A woman watches TV Score: 0.0055
A man is playing guitar The new movie is so great Score: 0.0097
The new movie is awesome 花呗更改绑定银行卡 Score: 0.0302
The new movie is awesome The dog plays in the garden Score: -0.0160
The new movie is awesome A woman watches TV Score: 0.1321
The new movie is awesome The new movie is so great Score: 0.9591文のコサイン類似性値の
score範囲は[-1、1]であり、値が大きいほど、より類似しています。
一般に、クエリに最も似ているテキストは、ドキュメント候補セットに記載されており、質問の類似性マッチングやQAシナリオのテキストの類似性の取得などのタスクによく使用されます。
例:Examples/semantic_search_demo.py
import sys
sys . path . append ( '..' )
from text2vec import SentenceModel , cos_sim , semantic_search
embedder = SentenceModel ()
# Corpus with example sentences
corpus = [
'花呗更改绑定银行卡' ,
'我什么时候开通了花呗' ,
'A man is eating food.' ,
'A man is eating a piece of bread.' ,
'The girl is carrying a baby.' ,
'A man is riding a horse.' ,
'A woman is playing violin.' ,
'Two men pushed carts through the woods.' ,
'A man is riding a white horse on an enclosed ground.' ,
'A monkey is playing drums.' ,
'A cheetah is running behind its prey.'
]
corpus_embeddings = embedder . encode ( corpus )
# Query sentences:
queries = [
'如何更换花呗绑定银行卡' ,
'A man is eating pasta.' ,
'Someone in a gorilla costume is playing a set of drums.' ,
'A cheetah chases prey on across a field.' ]
for query in queries :
query_embedding = embedder . encode ( query )
hits = semantic_search ( query_embedding , corpus_embeddings , top_k = 5 )
print ( " n n ====================== n n " )
print ( "Query:" , query )
print ( " n Top 5 most similar sentences in corpus:" )
hits = hits [ 0 ] # Get the hits for the first query
for hit in hits :
print ( corpus [ hit [ 'corpus_id' ]], "(Score: {:.4f})" . format ( hit [ 'score' ]))出力:
Query: 如何更换花呗绑定银行卡
Top 5 most similar sentences in corpus:
花呗更改绑定银行卡 (Score: 0.9477)
我什么时候开通了花呗 (Score: 0.3635)
A man is eating food. (Score: 0.0321)
A man is riding a horse. (Score: 0.0228)
Two men pushed carts through the woods. (Score: 0.0090)
======================
Query: A man is eating pasta.
Top 5 most similar sentences in corpus:
A man is eating food. (Score: 0.6734)
A man is eating a piece of bread. (Score: 0.4269)
A man is riding a horse. (Score: 0.2086)
A man is riding a white horse on an enclosed ground. (Score: 0.1020)
A cheetah is running behind its prey. (Score: 0.0566)
======================
Query: Someone in a gorilla costume is playing a set of drums.
Top 5 most similar sentences in corpus:
A monkey is playing drums. (Score: 0.8167)
A cheetah is running behind its prey. (Score: 0.2720)
A woman is playing violin. (Score: 0.1721)
A man is riding a horse. (Score: 0.1291)
A man is riding a white horse on an enclosed ground. (Score: 0.1213)
======================
Query: A cheetah chases prey on across a field.
Top 5 most similar sentences in corpus:
A cheetah is running behind its prey. (Score: 0.9147)
A monkey is playing drums. (Score: 0.2655)
A man is riding a horse. (Score: 0.1933)
A man is riding a white horse on an enclosed ground. (Score: 0.1733)
A man is eating food. (Score: 0.0329)類似ライブラリ[推奨]
テキストの類似性の計算とテキストマッチング検索タスクの場合、このプロジェクトでのWord2Vec、Sbert、およびCosentのようなセマンティックマッチングモデルと互換性のある類似ライブラリを使用することをお勧めします。また、1億レベルのグラフィック検索をサポートし、テキストセマンティックの重複排除、画像重複排除、その他の機能をサポートしています。
インストール: pip install -U similarities
文の類似性の計算:
from similarities import BertSimilarity
m = BertSimilarity ()
r = m . similarity ( '如何更换花呗绑定银行卡' , '花呗更改绑定银行卡' )
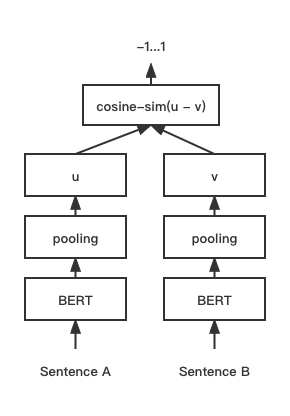
print ( f"similarity score: { float ( r ) } " ) # similarity score: 0.855146050453186 Cosent(Cosine Sente)テキストマッチングモデルは、Cosineranklossの文のベクトルスキームを改善します。
ネットワーク構造:
トレーニング:
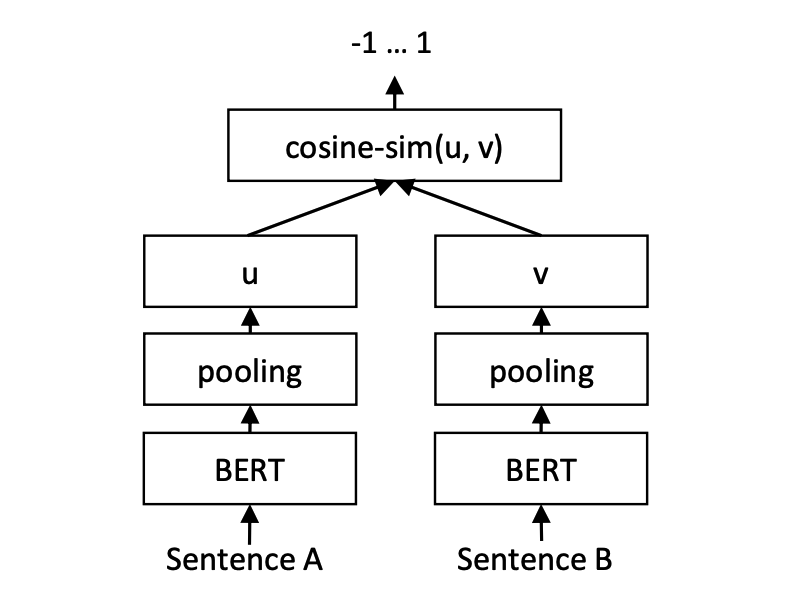
推論:
Cosentモデルのトレーニングと予測:
CoSENTモデルのトレーニングと評価例:Examples/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-cosentCoSENTトレーニングと評価これらの中国のマッチングデータセットの使用をサポートします:「ATEC」、「STS-B」、「BQ」、「LCQMC」、「Pawsx」、詳細については、huggingfaceデータセットhttps://huggingface.co/datasets/shibing624/nli_zhを参照してください
python training_sup_text_matching_model.py --task_name ATEC --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/ATEC-cosent例:Examples/training_sup_text_matching_model_mydata.py
シングルカードトレーニング:
CUDA_VISIBLE_DEVICES=0 python training_sup_text_matching_model_mydata.py --do_train --do_predictドカトレーニング:
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 training_sup_text_matching_model_mydata.py --do_train --do_predict --output_dir outputs/STS-B-text2vec-macbert-v1 --batch_size 64 --bf16 --data_parallel リファレンス例/データ/STS-B/STS-B.VALID.DATAトレーニングセット形式
sentence1 sentence2 label
一个女孩在给她的头发做发型。 一个女孩在梳头。 2
一群男人在海滩上踢足球。 一群男孩在海滩上踢足球。 3
一个女人在测量另一个女人的脚踝。 女人测量另一个女人的脚踝。 5 labelラベル0および1である可能性があり、0は2つの文が類似していないことを意味し、1は類似しています。また、0-5のスコアになることもあります。スコアが高いほど、2つの文はより似ています。すべてのモデルをサポートできます。
CoSENTモデルのトレーニングと評価例:Examples/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-cosentCoSENTモデルをトレーニングし、STS-Bテストセットで効果を評価する例:Examples/training_unsup_text_matching_model_en.py
cd examples
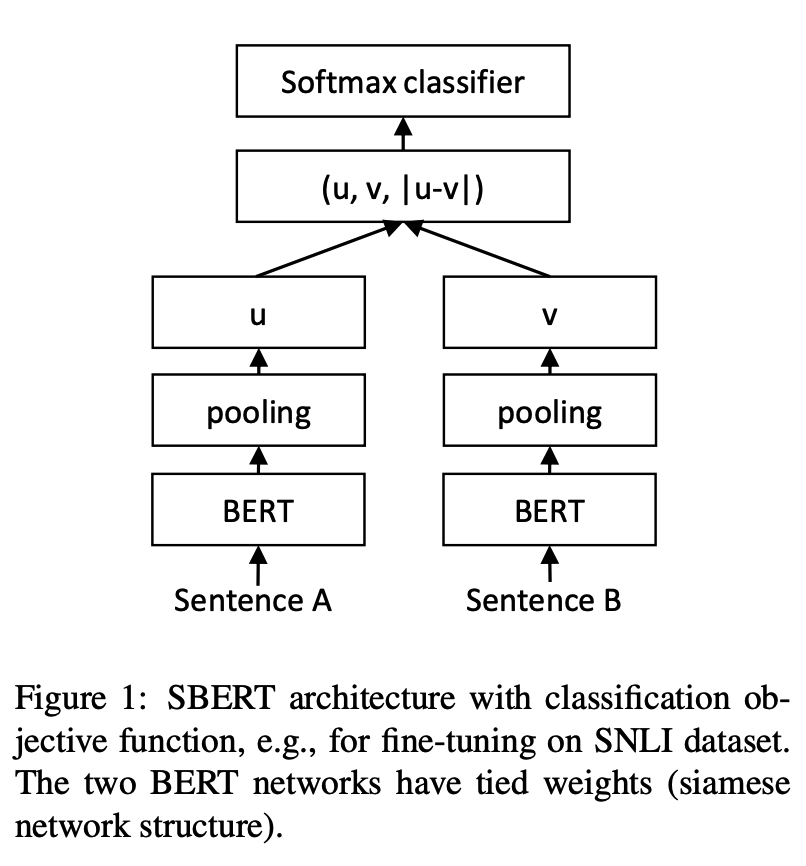
python training_unsup_text_matching_model_en.py --model_arch cosent --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-cosent文 - テキストマッチングモデル、表現文ベクトル表現スキーム
ネットワーク構造:
トレーニング:
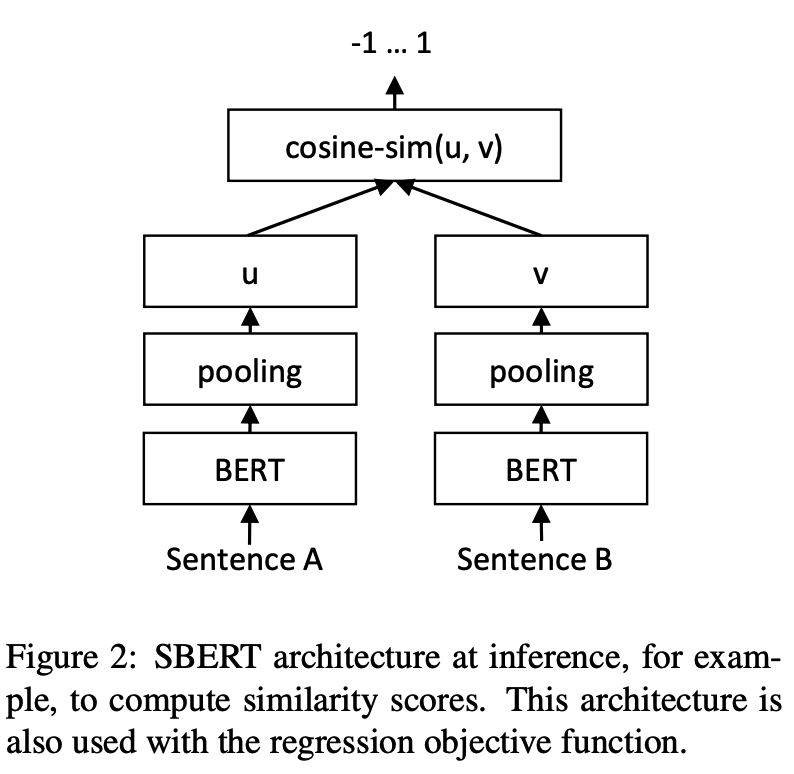
推論:
SBERTモデルのトレーニングと評価例:Examples/training_sup_text_matching_model.py
cd examples
python training_sup_text_matching_model.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name hfl/chinese-macbert-base --output_dir ./outputs/STS-B-sbertSBERTモデルのトレーニングと評価例:Examples/training_sup_text_matching_model_en.py
cd examples
python training_sup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-sbertSBERTモデルのトレーニングとSTS-Bテストセットでの効果の評価例:Examples/training_unsup_text_matching_model_en.py
cd examples
python training_unsup_text_matching_model_en.py --model_arch sentencebert --do_train --do_predict --num_epochs 10 --model_name bert-base-uncased --output_dir ./outputs/STS-B-en-unsup-sbertバートテキストマッチングモデル、ネイティブバートマッチングネットワーク構造、インタラクティブな文ベクトルマッチングモデル
ネットワーク構造:
トレーニングと推論:
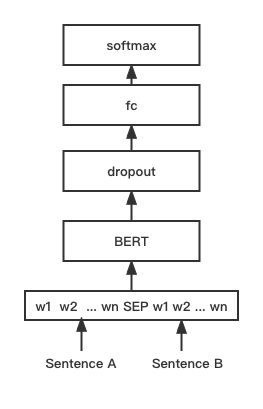
トレーニングスクリプトは、上記の例/training_sup_text_matching_model.pyと同じです。
BGEモデルのトレーニングと評価例:Examples/Training_bge_model_mydata.py
cd examples
python training_bge_model_mydata.py --model_arch bge --do_train --do_predict --num_epochs 4 --output_dir ./outputs/STS-B-bge-v1 --batch_size 4 --save_model_every_epoch --bf16BGEモデルの微調整トレーニング、コントラスト学習を使用してモデルをトレーニングする、入力データの形式はトリプル '(クエリ、ポジティブ、ネガティブ)です。
cd examples/data
python build_zh_bge_dataset.py
python hard_negatives_mine.pybuild_zh_bge_dataset.py中国のsts-bに基づいてトリプルトレーニングセットを生成し、次の形式を使用します。 { "query" : "一个男人正在往锅里倒油。 " , "pos" :[ "一个男人正在往锅里倒油。 " ], "neg" :[ "亲俄军队进入克里米亚乌克兰海军基地" , "配有木制家具的优雅餐厅。 " , "马雅瓦蒂要求总统统治查谟和克什米尔" , "非典还夺去了多伦多地区44人的生命,其中包括两名护士和一名医生。 " , "在一次采访中,身为犯罪学家的希利说,这里和全国各地的许多议员都对死刑抱有戒心。 " , "豚鼠吃胡萝卜。 " , "狗嘴里叼着一根棍子在水中游泳。 " , "拉里·佩奇说Android很重要,不是关键" , "法国、比利时、德国、瑞典、意大利和英国为印度计划向缅甸出售的先进轻型直升机提供零部件和技术。 " , "巴林赛马会在动乱中进行" ]}hard_negatives_mine.py FAISS同様の試合を使用しており、マイニングを否定的な例から困難にします。Text2VECトレーニングされたモデルは、Sente-Transformers Libraryを使用してロードできるため、モデル蒸留方法はここで多重化されています。
サービスを構築するための2つの展開モデルと方法を提供します。1)Jina [推奨]に基づいてGRPCサービスを構築します。 2)Fastapiに基づいてネイティブHTTPサービスを構築します。
C/Sモードを使用して、高性能サービスを構築し、Docker Cloudネイティブ、GRPC/HTTP/WebSocketをサポートし、複数のモデルとGPUマルチカード処理の同時予測をサポートします。
インストール: pip install jina
サービスを開始します:
例:例/jina_server_demo.py
from jina import Flow
port = 50001
f = Flow ( port = port ). add (
uses = 'jinahub://Text2vecEncoder' ,
uses_with = { 'model_name' : 'shibing624/text2vec-base-chinese' }
)
with f :
# backend server forever
f . block ()モデル予測法(エグゼキューター)は、DockerやK8Sの展開方法を含むJinahubにアップロードされています。
from jina import Client
from docarray import Document , DocumentArray
port = 50001
c = Client ( port = port )
data = [ '如何更换花呗绑定银行卡' ,
'花呗更改绑定银行卡' ]
print ( "data:" , data )
print ( 'data embs:' )
r = c . post ( '/' , inputs = DocumentArray ([ Document ( text = '如何更换花呗绑定银行卡' ), Document ( text = '花呗更改绑定银行卡' )]))
print ( r . embeddings )例を参照してください:バッチ通話方法のための例:examples/jina_client_demo.py
インストール: pip install fastapi uvicorn
サービスを開始します:
例:Examples/FastApi_Server_Demo.py
cd examples
python fastapi_server_demo.pycurl -X ' GET '
' http://0.0.0.0:8001/emb?q=hello '
-H ' accept: application/json ' | データセット | 導入 | ダウンロードリンク |
|---|---|---|
| Shibing624/nli-zh-all | 中国のセマンティックマッチングデータ収集、テキストの推論、類似性、概要、質問と回答、命令微調整、一致する形式のデータセットに変換されるなどのタスクの820万の高品質データの統合 | https://huggingface.co/datasets/shibing624/nli-zh-all |
| Shibing624/snli-zh | 中国のsnliとmultinliデータセット、英語のsnliとmultinliから翻訳 | https://huggingface.co/datasets/shibing624/snli-zh |
| Shibing624/nli_zh | ATEC、BQ、LCQMC、PAWSX、STS-Bを含む5つのタスクのデータセットを統合する中国のセマンティックマッチングデータセット。 | https://huggingface.co/datasets/shibing624/nli_zh または Baidu Netdisk(抽出コード:QKT6) または github |
| Shibing624/sts-sohu2021 | 中国のセマンティックマッチングデータセット、2021 SOHUキャンパステキストマッチングアルゴリズム競争データセット | https://huggingface.co/datasets/shibing624/sts-sohu2021 |
| ATEC | 中国のATECデータセット、Ant Financial Q-QPAIRデータセット | ATEC |
| BQ | 中国BQ(銀行質問)データセット、銀行Q-QPAIRデータセット | BQ |
| LCQMC | 中国のLCQMC(大規模な中国の質問マッチングコーパス)データセット、Q-QPAIRデータセット | LCQMC |
| Pawsx | 中国の足(単語スクランブルからの言い換え敵)データセット、Q-QPAIRデータセット | Pawsx |
| sts-b | 中国のSTS-Bデータセット、中国の自然言語推論データセット、英語STS-Bから中国語に翻訳されたデータセット | sts-b |
一般的に使用される英語のマッチングデータセット:
データセットの使用例:
pip install datasets from datasets import load_dataset
dataset = load_dataset ( "shibing624/nli_zh" , "STS-B" ) # ATEC or BQ or LCQMC or PAWSX or STS-B
print ( dataset )
print ( dataset [ 'test' ][ 0 ])出力:
DatasetDict({
train: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 5231
})
validation: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1458
})
test: Dataset({
features: [ ' sentence1 ' , ' sentence2 ' , ' label ' ],
num_rows: 1361
})
})
{ ' sentence1 ' : '一个女孩在给她的头发做发型。 ' , ' sentence2 ' : '一个女孩在梳头。 ' , ' label ' : 2}
調査でtext2vecを使用する場合は、次の形式で引用してください。
APA:
Xu, M. Text2vec: Text to vector toolkit (Version 1.1.2) [Computer software]. https://github.com/shibing624/text2vecbibtex:
@misc{Text2vec,
author = {Ming Xu},
title = {Text2vec: Text to vector toolkit},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { url {https://github.com/shibing624/text2vec}},
}ライセンス契約はApacheライセンス2.0で、商業目的で無料で使用できます。 Text2Vecのリンクと承認契約を製品の説明に添付してください。
プロジェクトコードはまだ非常にラフです。コードが改善されている場合は、このプロジェクトに送信できます。提出する前に、次の2つのポイントに注意してください。
testsに対応する単体テストを追加しますpython -m pytest -vを使用してすべての単体テストを実行し、すべての単一テストが渡されていることを確認します後でPRを送信できます。


