huozi
Release huozi 3.5
| บท | อธิบาย |
|---|---|
| ?? ♂ รายการโอเพ่นซอร์ส | รายชื่อโครงการโอเพนซอร์สในคลังสินค้านี้ |
| การแนะนำแบบจำลอง | บทนำสั้น ๆ เกี่ยวกับโครงสร้างและกระบวนการฝึกอบรมของแบบจำลองประเภทที่เคลื่อนย้ายได้ |
| - ดาวน์โหลดรุ่น | ลิงค์ดาวน์โหลดรุ่นที่เคลื่อนย้ายได้ |
| การให้เหตุผลแบบจำลอง | ตัวอย่างของการอนุมานแบบจำลองประเภทที่เคลื่อนย้ายได้รวมถึงกระบวนการใช้งานของกรอบการอนุมานเช่น VLLM, llama.cpp และ Ollama |
| - ประสิทธิภาพของโมเดล | ประสิทธิภาพของแบบจำลองประเภทที่เคลื่อนย้ายได้ในงานการประเมินกระแสหลัก |
| - สร้างตัวอย่าง | ตัวอย่างของผลการสร้างจริงของแบบจำลองประเภทที่เคลื่อนย้ายได้ |

รูปแบบภาษาขนาดใหญ่ (LLM) มีความคืบหน้าอย่างมีนัยสำคัญในด้านการประมวลผลภาษาธรรมชาติและแสดงให้เห็นถึงศักยภาพที่แข็งแกร่งในสถานการณ์แอปพลิเคชันที่หลากหลาย เทคโนโลยีนี้ไม่เพียง แต่ดึงดูดความสนใจอย่างกว้างขวางจากชุมชนวิชาการเท่านั้น แต่ยังกลายเป็นประเด็นร้อนแรงในอุตสาหกรรม เมื่อเทียบกับพื้นหลังนี้ศูนย์การคำนวณทางสังคมและการดึงข้อมูลของสถาบันเทคโนโลยีฮาร์บิน (HIT -SCIR) เพิ่งเปิดตัวความสำเร็จล่าสุด - Movable Type 3.5 ซึ่งมุ่งมั่นที่จะให้ความเป็นไปได้และตัวเลือกมากขึ้นสำหรับการวิจัยและการประยุกต์ใช้ภาษาธรรมชาติ
Movable Type 3.5 เป็นแบบจำลองที่ได้จากการเพิ่มประสิทธิภาพเพิ่มเติมตามประเภท Movable Type 3.0 และ Chinese-Mixtral-8x7b Movable Type 3.5 รองรับ บริบทยาว 32K สืบทอดความสามารถที่ครอบคลุมที่ทรงพลังของ Movable Type 3.0 และบรรลุการปรับปรุงประสิทธิภาพในหลาย ๆ ด้านเช่น ความรู้ภาษาจีนและภาษาอังกฤษ การให้เหตุผลทางคณิตศาสตร์ การสร้างรหัส ความสามารถในการปฏิบัติตามคำสั่ง ความปลอดภัยของเนื้อหา ฯลฯ
สำคัญ
โมเดลซีรีย์ประเภทที่เคลื่อนย้ายได้อาจยังคงสร้างการตอบกลับที่ทำให้เข้าใจผิดซึ่งมีข้อผิดพลาดจริงหรือเนื้อหาที่เป็นอันตรายที่มีอคติ/การเลือกปฏิบัติ โปรดระมัดระวังในการระบุและใช้เนื้อหาที่สร้างขึ้นและไม่กระจายเนื้อหาที่เป็นอันตรายที่สร้างขึ้นไปยังอินเทอร์เน็ต
โปรดดูเอกสารสำหรับ Movable Type 1.0 และ Movable Type 2.0 ที่นี่ โปรดดูเอกสารเกี่ยวกับ Movable Type 3.0 และ MT-Bench จีน
Movable Type 3.5 เป็นแบบจำลองผู้เชี่ยวชาญแบบไฮบริด (SMOE) แต่ละชั้นผู้เชี่ยวชาญมี 8 FFNs และการคำนวณไปข้างหน้าแต่ละครั้งจะเปิดใช้งานอย่างเบาบางโดย Top-2 Type ที่เคลื่อนย้ายได้ 3.5 มีพารามิเตอร์ทั้งหมด 46.7b ต้องขอบคุณคุณสมบัติการเปิดใช้งานที่กระจัดกระจายจึงต้องเปิดใช้งานพารามิเตอร์เพียง 13b ในระหว่างการให้เหตุผลจริงซึ่งช่วยปรับปรุงประสิทธิภาพการคำนวณและความเร็วในการประมวลผลได้อย่างมีประสิทธิภาพ
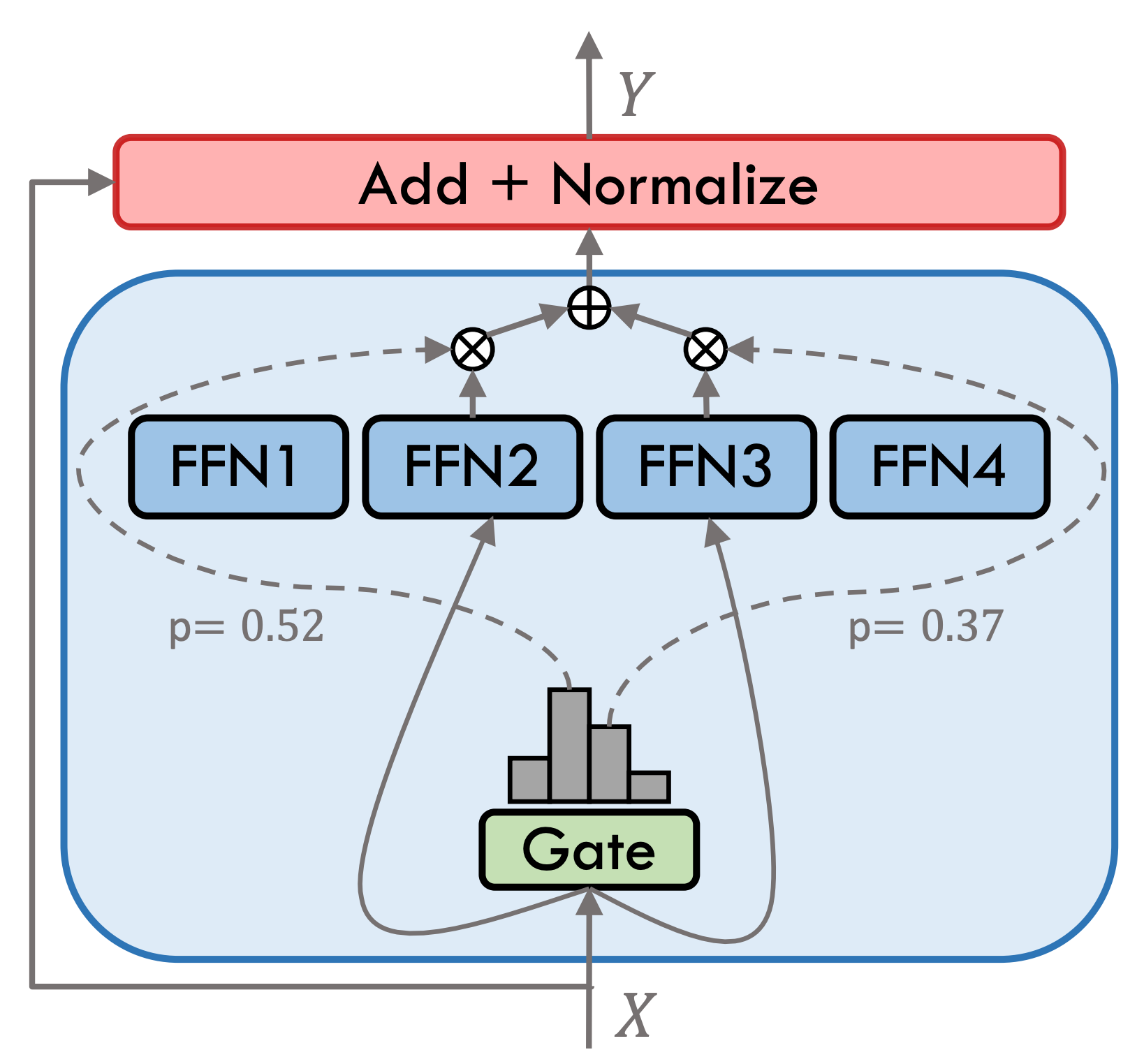
Movable Type 3.5 ได้รับการฝึกอบรมหลายขั้นตอนดังแสดงในรูปด้านล่าง:
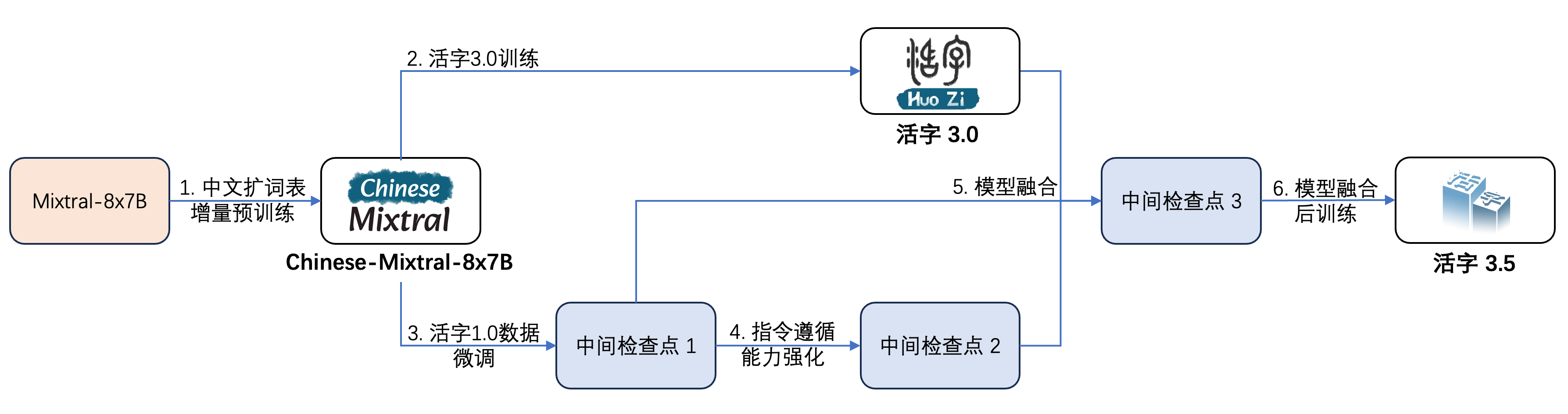
กระบวนการฝึกอบรมคือ:
| ชื่อนางแบบ | ขนาดไฟล์ | ดาวน์โหลดที่อยู่ | คำพูด |
|---|---|---|---|
| huozi3.5 | 88GB | ? huggingface ModelsCope | Movable Type 3.5 Model Complete |
| Huozi3.5-ckpt-1 | 88GB | ? huggingface ModelsCope | Movable Type 3.5 จุดตรวจสอบระดับกลาง 1 |
| Huozi3.5-ckpt-2 | 88GB | ? huggingface ModelsCope | Movable Type 3.5 จุดตรวจสอบระดับกลาง 2 |
| Huozi3.5-ckpt-3 | 88GB | ? huggingface ModelsCope | Movable Type 3.5 จุดตรวจสอบระดับกลาง 3 |
หากคุณต้องการปรับแต่ง Type 3.5 หรือจีน-Mixtral-8x7b โปรดดูรหัสการฝึกอบรมที่นี่
Movable Type 3.5 ใช้เทมเพลต propt รูปแบบ chatml รูปแบบคือ:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
รหัสตัวอย่างสำหรับการใช้เหตุผลโดยใช้ Movable Type 3.5 มีดังนี้:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5 รองรับระบบนิเวศแบบ Mixtral Model ทั้งหมดรวมถึง Transformers, VLLM, Llama.cpp, Ollama, Web UI สร้างข้อความและเฟรมเวิร์กอื่น ๆ
หากคุณมีปัญหาเครือข่ายในขณะที่ดาวน์โหลดโมเดลของคุณคุณสามารถใช้จุดตรวจที่เราให้ไว้ใน ModelsCope
Transformers Support การเพิ่มเทมเพลตแชทสำหรับ Tokenizer และรองรับการสร้างสตรีมมิ่ง รหัสตัวอย่างมีดังนี้:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)อินเทอร์เฟซของ ModelsCope นั้นคล้ายกับ Transformers เพียงแค่แทนที่ Transformers ด้วยขอบเขตของรุ่น:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))ประเภทตัวแปร 3.5 รองรับการใช้งานการเร่งความเร็วผ่าน VLLM และรหัสตัวอย่างมีดังนี้:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )ประเภท Variety Type 3.5 สามารถนำไปใช้เป็นบริการที่รองรับ OpenAI API Protocol ซึ่งช่วยให้สามารถเรียก Varies Type 3.5 ได้โดยตรงผ่าน OpenAI API
การเตรียมสิ่งแวดล้อม:
$ pip install vllm openaiเริ่มบริการ:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048ส่งคำขอโดยใช้ OpenAI API:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )นี่คือรหัสตัวอย่างที่ใช้ OpenAI API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()รูปแบบ GGUF ได้รับการออกแบบมาเพื่อโหลดและบันทึกรุ่นอย่างรวดเร็ว เปิดตัวโดยทีม Llama.cpp และเหมาะสำหรับเฟรมเวิร์กเช่น llama.cpp, Ollama ฯลฯ คุณสามารถแปลง Movable Type 3.5 ในรูปแบบ HuggingFace เป็นรูปแบบ GGUF ด้วยตนเอง
ก่อนอื่นคุณต้องดาวน์โหลดซอร์สโค้ดของ llama.cpp เราให้บริการ submodule ของ llama.cpp ในที่เก็บ LLAMA.CPP รุ่นนี้ได้รับการทดสอบแล้วและสามารถอนุมานได้สำเร็จ:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppนอกจากนี้คุณยังสามารถดาวน์โหลดซอร์สโค้ด Llama.cpp เวอร์ชันล่าสุด:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppจากนั้นจะต้องมีการรวบรวม มีความแตกต่างเล็กน้อยในคำสั่งรวบรวมขึ้นอยู่กับแพลตฟอร์มฮาร์ดแวร์ของคุณ:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 คำสั่งต่อไปนี้จะต้องอยู่ใน llama.cpp/ ไดเรกทอรี:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 คำสั่งต่อไปนี้จะต้องอยู่ใน llama.cpp/ ไดเรกทอรี:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " พารามิเตอร์ -ngl ระบุจำนวนเลเยอร์ของการถ่ายไปยัง GPU การลดค่านี้สามารถบรรเทาแรงดันหน่วยความจำวิดีโอ GPU ได้ หลังจากการทดสอบจริงของเราโมเดล Q2_K Quantized มีออฟโหลด 16 ชั้นและการใช้หน่วยความจำสามารถลดลงเหลือ 9.6GB ซึ่งสามารถเรียกใช้โมเดลบน GPU ของผู้บริโภค:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " สำหรับพารามิเตอร์เพิ่มเติมของ main คุณสามารถอ้างถึงเอกสารอย่างเป็นทางการของ llama.cpp
ใช้กรอบการทำงานของ Ollama เพื่อการให้เหตุผลคุณสามารถอ้างถึงคำแนะนำ ReadMe ของ Ollama
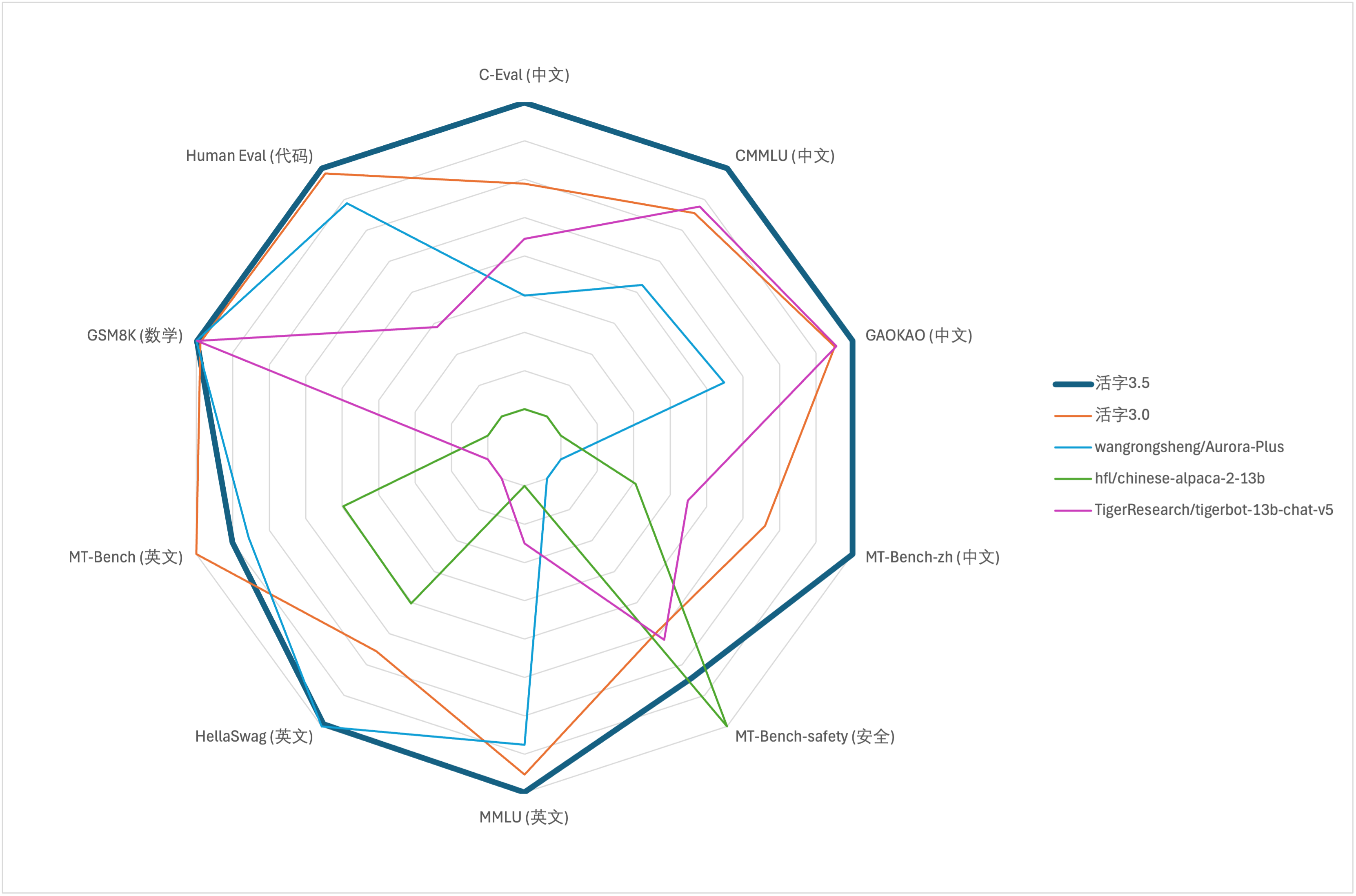
สำหรับการประเมินความสามารถที่ครอบคลุมของโมเดลขนาดใหญ่เราใช้ชุดข้อมูลการประเมินผลต่อไปนี้เพื่อประเมิน Type 3.5 ที่เคลื่อนย้ายได้ตามลำดับ:
Movable Type 3.5 เปิดใช้งานเฉพาะพารามิเตอร์ 13B เมื่อการอนุมาน ตารางต่อไปนี้แสดงผลลัพธ์ของแบบจำลองภาษาจีนของ Type 3.5 ที่เคลื่อนย้ายได้และเครื่องชั่ง 13B อื่น ๆ และรุ่นที่สามารถเคลื่อนย้ายได้ในชุดข้อมูลการประเมินผลแต่ละชุด:
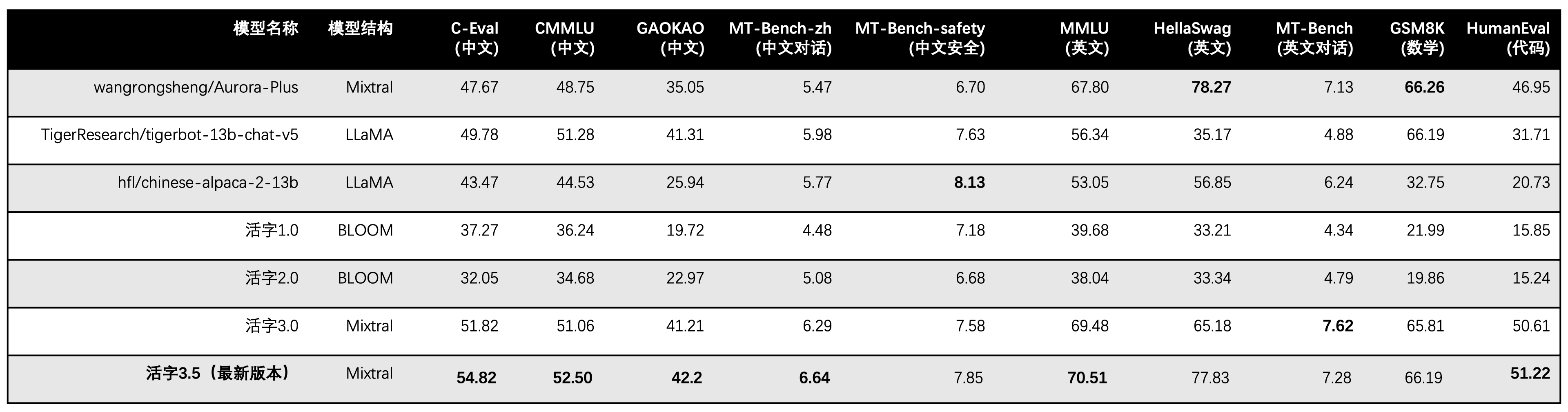
เราใช้ 5-shot ใน C-eval, CMMLU และ MMLU, GSM8K ใช้ 4-shot, Hellaswag และ Humaneval ใช้ 0-shot และ Humaneval ใช้ตัวบ่งชี้ Pass@1 การทดสอบทั้งหมดเป็นกลยุทธ์โลภ
เราใช้ OpenCompass เป็นกรอบการประเมินและการกระทำแฮชคือ 4C87E77 รหัสตรวจสอบอยู่ที่นี่
ในการประเมินประสิทธิภาพของ Movable Type 3.0 เราใช้วิธีการประเมินแบบจำลองพื้นฐานในมนุษย์ไม่ถูกต้องและผลการประเมินที่ถูกต้องได้รับการปรับปรุงในตารางด้านบน
จากผลการทดสอบในตารางข้างต้น Type 3.5 ที่เคลื่อนย้ายได้ได้รับการปรับปรุงประสิทธิภาพที่ค่อนข้างเสถียรเมื่อเทียบกับ Type 3.0 ที่เคลื่อนย้ายได้ และความรู้ภาษาจีนและภาษาอังกฤษ การใช้เหตุผลทางคณิตศาสตร์ การสร้าง รหัส ความสามารถในการปฏิบัติตามการสอนภาษาจีน และ ความปลอดภัยของเนื้อหาจีน
ต่อไปนี้คือผลการสร้างของ Type 3.5 ที่เคลื่อนย้ายได้ในชุดการประเมินผล MT-Bench-ZH:
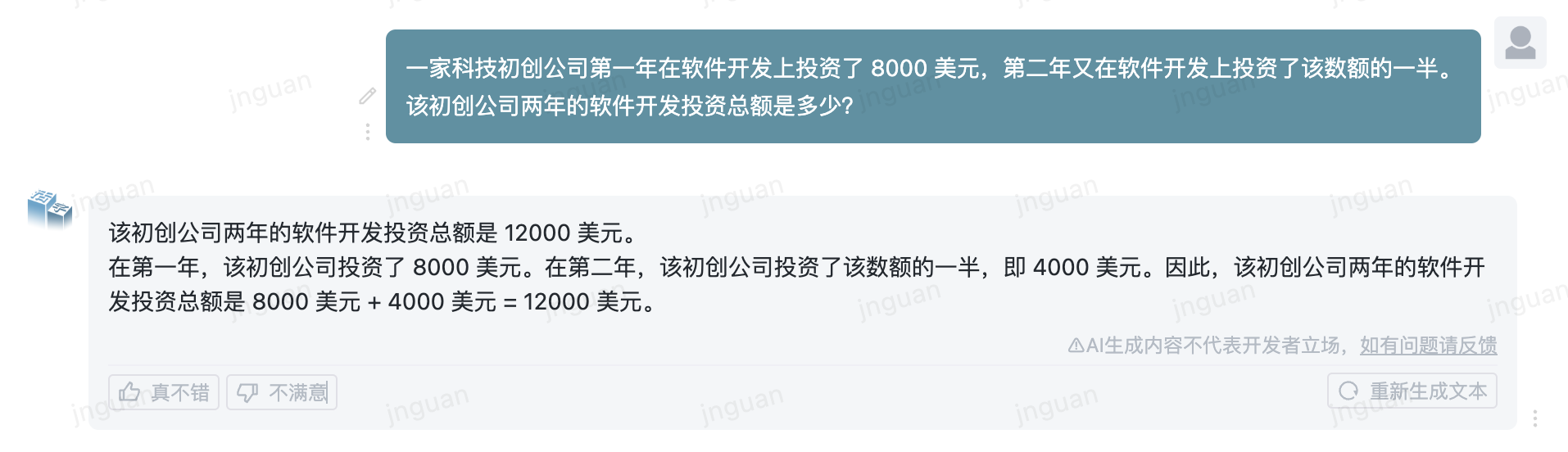



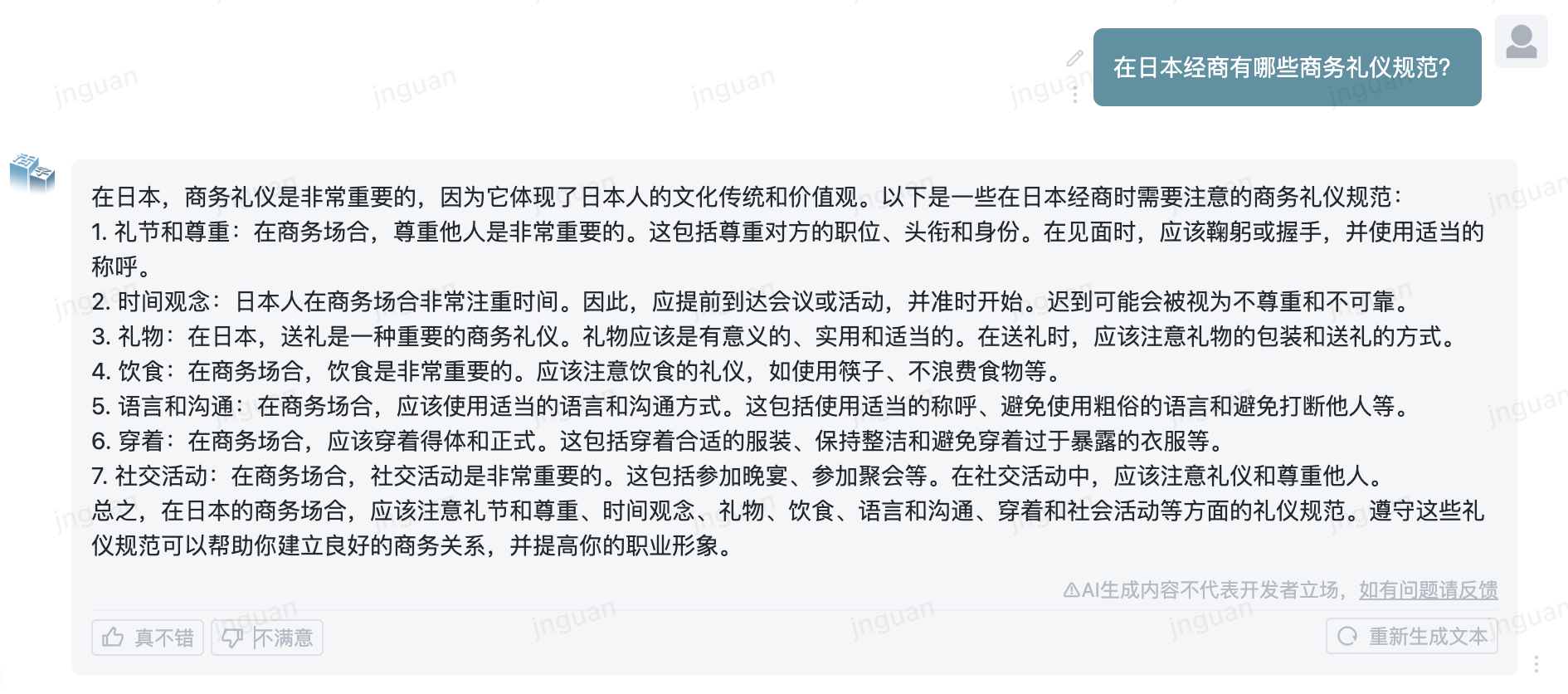
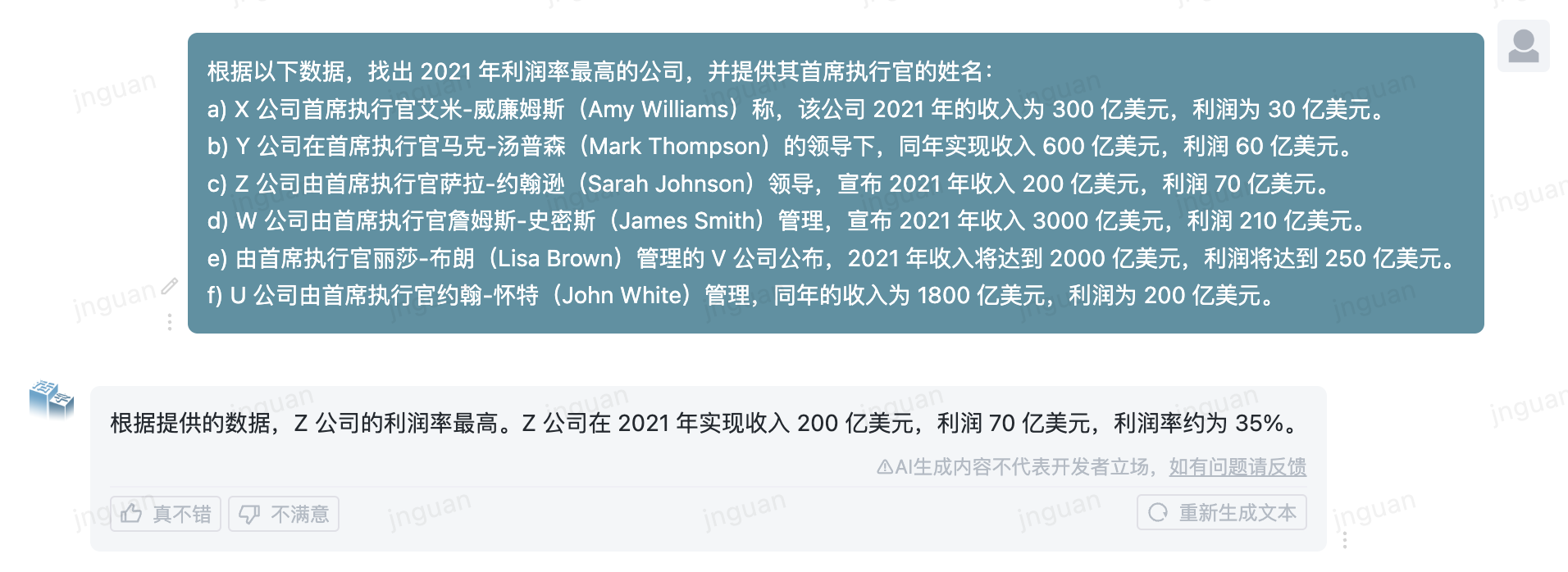
การใช้ซอร์สโค้ดที่เก็บนี้ขึ้นอยู่กับข้อตกลงใบอนุญาตโอเพ่นซอร์ส Apache 2.0
ประเภทมือถือมีวางจำหน่ายทั่วไป หากคุณใช้โมเดลประเภทที่เคลื่อนย้ายได้หรืออนุพันธ์เพื่อวัตถุประสงค์ทางการค้าโปรดติดต่อผู้ออกใบอนุญาตดังต่อไปนี้เพื่อลงทะเบียนและสมัครเป็นลายลักษณ์อักษรจากผู้ออกใบอนุญาต: ติดต่ออีเมล: [email protected]
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

