huozi
Release huozi 3.5
| capítulo | ilustrar |
|---|---|
| Lista de código abierto ?? | Lista de proyectos de código abierto en este almacén |
| Introducción al modelo | Breve introducción a la estructura y el proceso de entrenamiento del modelo de tipo móvil |
| ? Descargar modelo | Enlace de descarga del modelo de tipo móvil |
| Razonamiento modelo | Ejemplos de inferencia de modelos de tipo móvil, incluido el proceso de uso de marcos de inferencia como VLLM, LLAMA.CPP y Ollama. |
| ? Rendimiento del modelo | Rendimiento del modelo de tipo móvil en las tareas de evaluación convencional |
| ? Generar muestra | Ejemplos de efecto de generación real del modelo de tipo móvil |

El Modelo de lenguaje a gran escala (LLM) ha progresado significativamente en el campo del procesamiento del lenguaje natural y ha demostrado su fuerte potencial en una amplia gama de escenarios de aplicación. Esta tecnología no solo atrajo la atención generalizada de la comunidad académica, sino que también se convirtió en un tema candente en la industria. En este contexto, el Centro de Computación Social y Recuperación de Información del Instituto de Tecnología Harbin (HIT -SCIR) lanzó recientemente el último logro: el tipo móvil 3.5 , comprometido a proporcionar más posibilidades y opciones para la investigación y la aplicación práctica del procesamiento del lenguaje natural.
El tipo móvil 3.5 es un modelo obtenido por una mejora adicional del rendimiento basado en el tipo móvil 3.0 y chino-mixtral-8x7b. Tipo móvil 3.5 admite un contexto de 32k largo , hereda las poderosas capacidades integrales del tipo móvil 3.0 y logra mejoras de rendimiento en muchos aspectos, como el conocimiento chino e inglés , el razonamiento matemático , la generación de códigos , las capacidades de cumplimiento de la instrucción , la seguridad de contenido, etc.
Importante
El modelo de serie de tipo móvil aún puede generar respuestas engañosas que contienen errores objetivos o contenido dañino que contiene sesgo/discriminación. Tenga cuidado de identificar y usar el contenido generado y no difundir el contenido dañino generado a Internet.
Consulte la documentación para el tipo móvil 1.0 y el tipo móvil 2.0 aquí. Consulte aquí para la documentación sobre el tipo móvil 3.0 y el banco MT chino.
El tipo móvil 3.5 es un modelo de experto híbrido disperso (SMOE), cada capa experta contiene 8 FFN y cada cálculo hacia adelante se activa escasamente por Top-2. El tipo móvil 3.5 tiene un total de 46.7b parámetros. Gracias a sus características de activación escasa, solo se deben activar los parámetros de 13b durante el razonamiento real, lo que mejora efectivamente la eficiencia informática y la velocidad de procesamiento.
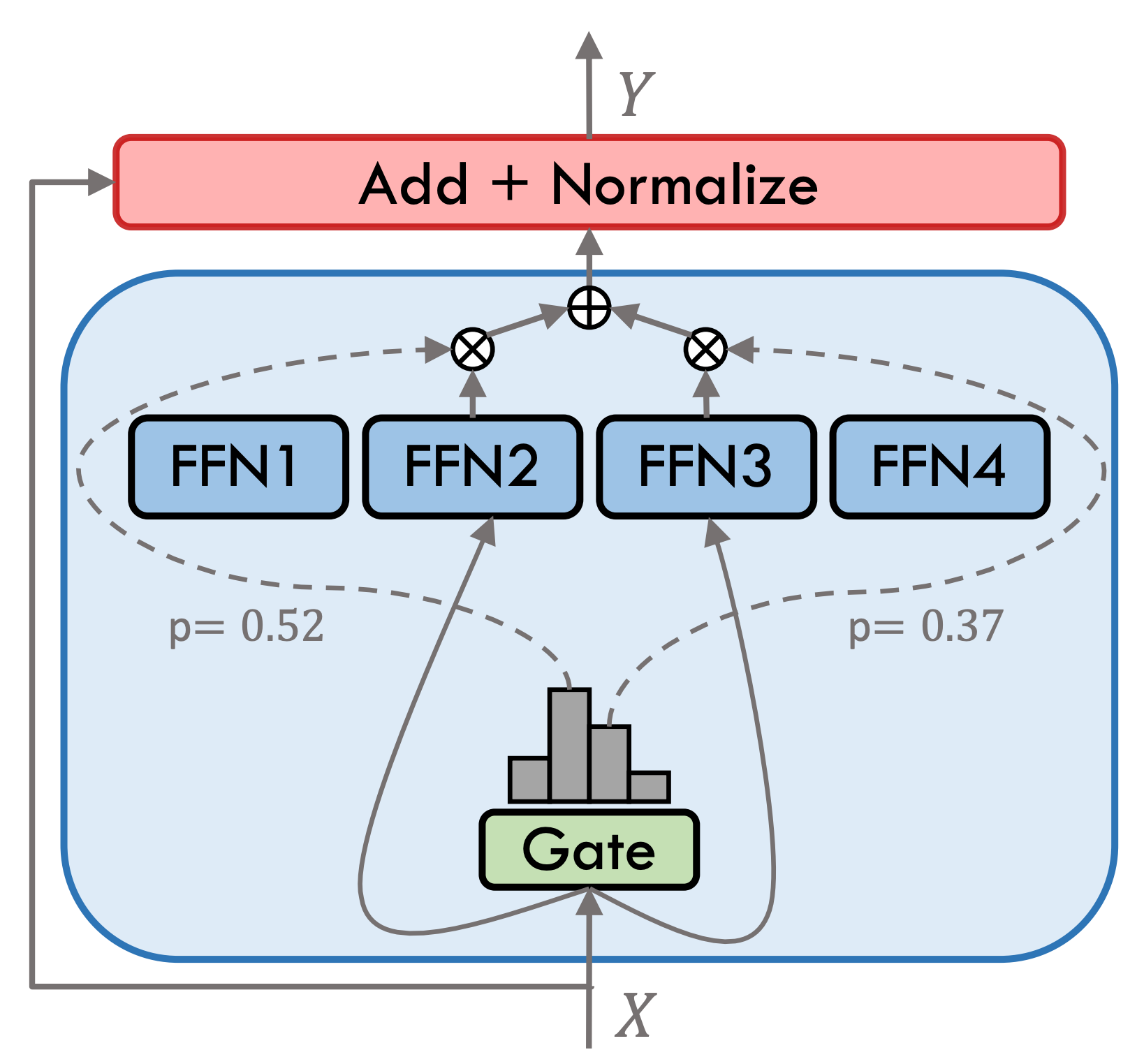
El tipo móvil 3.5 ha sufrido múltiples pasos de entrenamiento, como se muestra en la figura a continuación:
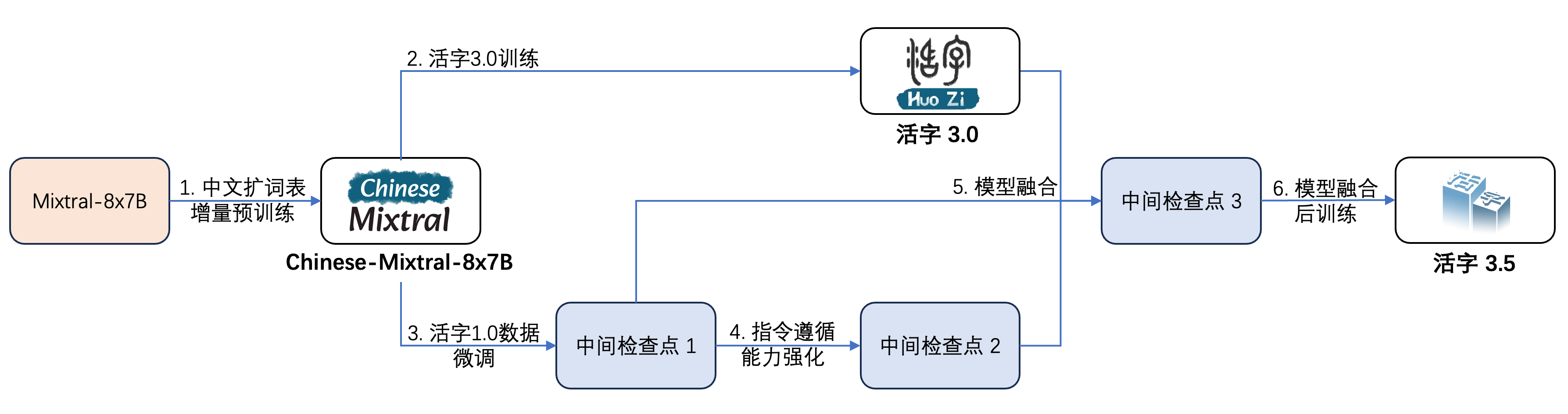
El proceso de capacitación es:
| Nombre del modelo | Tamaño de archivo | Dirección de descarga | Observación |
|---|---|---|---|
| Huozi3.5 | 88 GB | ? Modelscope | Tipo móvil 3.5 Modelo completo |
| Huozi3.5-CKPT-1 | 88 GB | ? Modelscope | Tipo móvil 3.5 Punto de control intermedio 1 |
| Huozi3.5-CKPT-2 | 88 GB | ? Modelscope | Tipo móvil 3.5 Punto de control intermedio 2 |
| Huozi3.5-CKPT-3 | 88 GB | ? Modelscope | Tipo móvil 3.5 Punto de control intermedio 3 |
Si desea ajustar el tipo móvil 3.5 o chino-mixtral-8x7b, consulte el código de entrenamiento aquí.
Tipo móvil 3.5 usa la plantilla de propt de formato chatml, el formato es:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
El código de ejemplo para razonamiento usando el tipo móvil 3.5 es el siguiente:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))El tipo móvil 3.5 admite todos los ecosistemas del modelo mixtral, incluidos Transformers, VLLM, LLAMA.CPP, OLLAMA, UI web de generación de texto y otros marcos.
Si tiene problemas de red al descargar su modelo, puede usar los puntos de control que proporcionamos en ModelsCope.
Transformers admite agregar plantillas de chat para tokenizer y admite la generación de transmisión. El código de muestra es el siguiente:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)La interfaz de ModelsCope es muy similar a los transformadores, simplemente reemplace los transformadores con el alcance del modelo:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))El tipo de variable 3.5 admite la implementación de la aceleración de inferencia a través de VLLM, y el código de muestra es el siguiente:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Variety Type 3.5 se puede implementar como un servicio que admite el Protocolo de API OpenAI, que permite que Variety Type 3.5 se llame directamente a través de la API de OpenAI.
Preparación ambiental:
$ pip install vllm openaiInicie el servicio:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Envíe solicitudes con API de OpenAI:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Aquí hay un código de muestra que usa OpenAI API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()El formato GGUF está diseñado para cargar y guardar modelos rápidamente. Es lanzado por el equipo LLAMA.CPP y es adecuado para marcos como Llama.CPP, Ollama, etc. Puede convertir manualmente el tipo móvil 3.5 en formato Huggingface en formato GGUF.
Primero, debe descargar el código fuente de Llama.cpp. Proporcionamos el submódulo de llama.cpp en el repositorio. Esta versión de llama.cpp ha sido probada y puede inferir con éxito:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppTambién puede descargar la última versión del código fuente de Llama.CPP:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppEntonces debe ser compilado. Hay diferencias sutiles en los comandos de compilación dependiendo de su plataforma de hardware:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 El siguiente comando debe estar en llama.cpp/ :
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 El siguiente comando debe estar en llama.cpp/ :
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " El parámetro -ngl indica el número de capas de descarga a la GPU. Reducir este valor puede aliviar la presión de la memoria del video GPU. Después de nuestra prueba real, el modelo cuantificado Q2_K tiene una descarga de 16 capas, y el uso de la memoria puede reducirse a 9.6GB, que puede ejecutar el modelo en las GPU del consumidor:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Para obtener más parámetros de main , puede consultar la documentación oficial de llama.cpp.
Use el marco Ollama para el razonamiento, puede consultar las instrucciones ReadMe de Ollama.
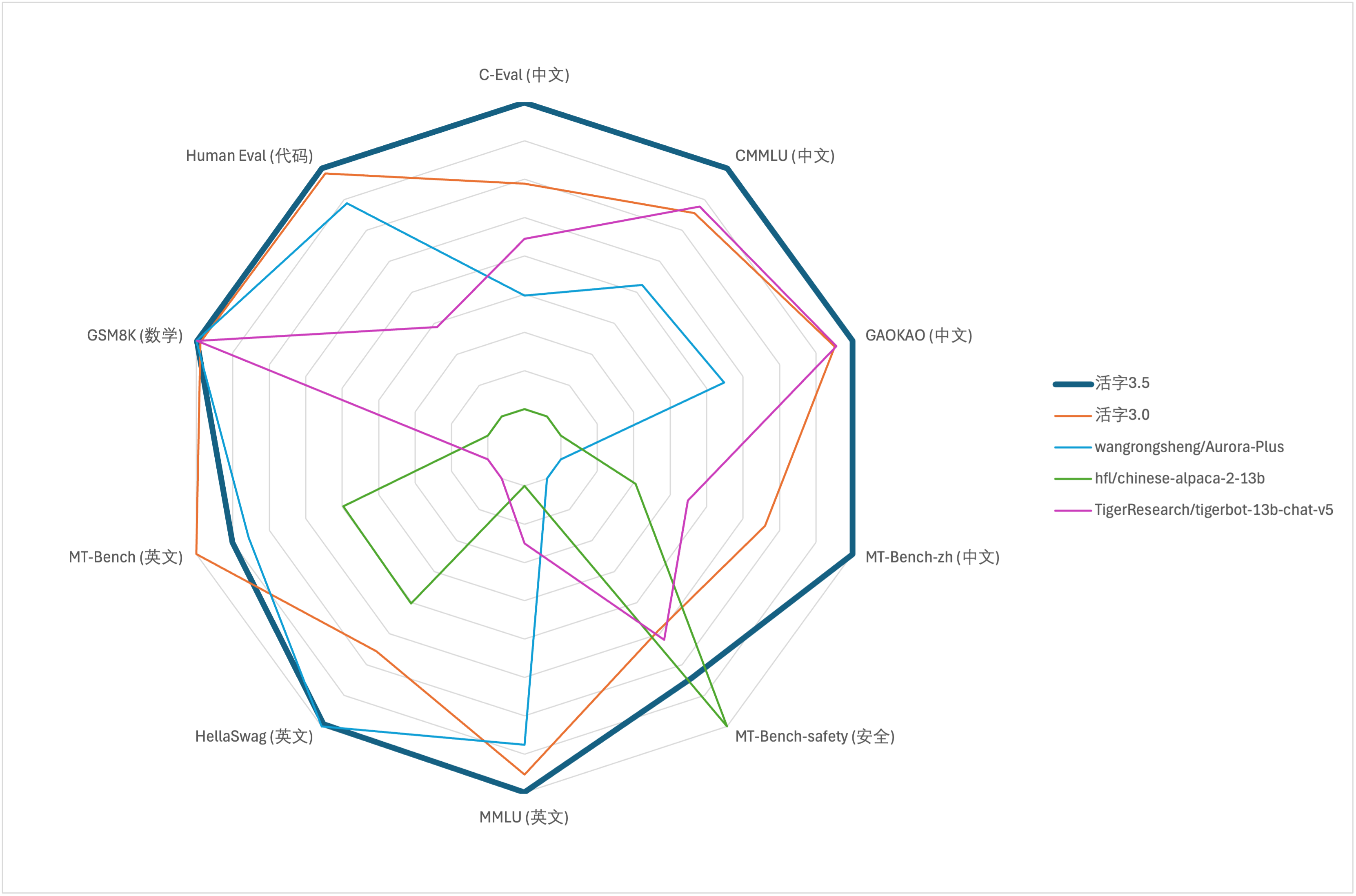
Para la evaluación de capacidad integral de modelos grandes, utilizamos el siguiente conjunto de datos de evaluación para evaluar el tipo móvil 3.5 respectivamente:
El tipo móvil 3.5 activa solo 13b parámetros cuando inferen. La siguiente tabla muestra los resultados de los modelos chinos del tipo móvil 3.5 y otras escalas 13B y la versión anterior del tipo móvil en cada conjunto de datos de evaluación:
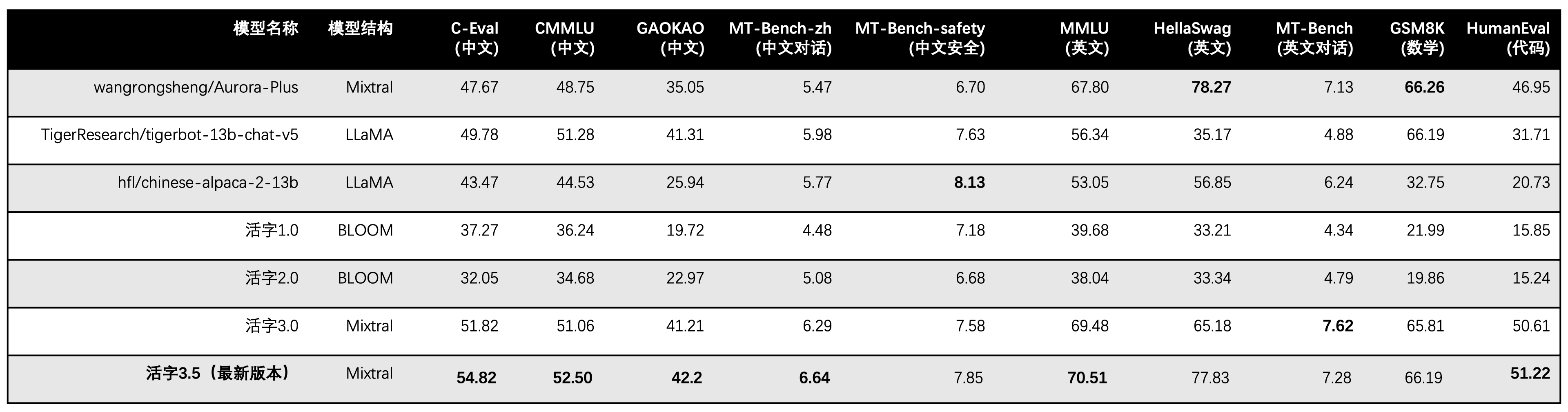
Usamos 5-shot en C-EVAL, CMMLU y MMLU, GSM8K usa 4-SHOT, HELLASWAG y Humaneval usan 0-shot, y Humaneval usa el indicador Pass@1. Todas las pruebas fueron una estrategia codiciosa.
Utilizamos OpenCompass como marco de evaluación y el hash de confirmación es 4C87E77. El código de revisión se encuentra aquí.
En la evaluación del desempeño del tipo móvil 3.0, utilizamos el método de evaluación del modelo base en humaneval incorrectamente, y los resultados de evaluación correctos se han actualizado en la tabla anterior.
De acuerdo con los resultados de la prueba en la tabla anterior, el tipo móvil 3.5 ha logrado una mejora del rendimiento relativamente estable en comparación con el tipo 3.0 móvil, y el conocimiento chino e inglés , el razonamiento matemático , la generación de códigos , la capacidad de cumplimiento de la instrucción china y la seguridad de contenido chino del tipo móvil 3.5 se han fortalecido.
El siguiente es el efecto de generación del tipo móvil 3.5 en el conjunto de evaluación MT-Bench-ZH:
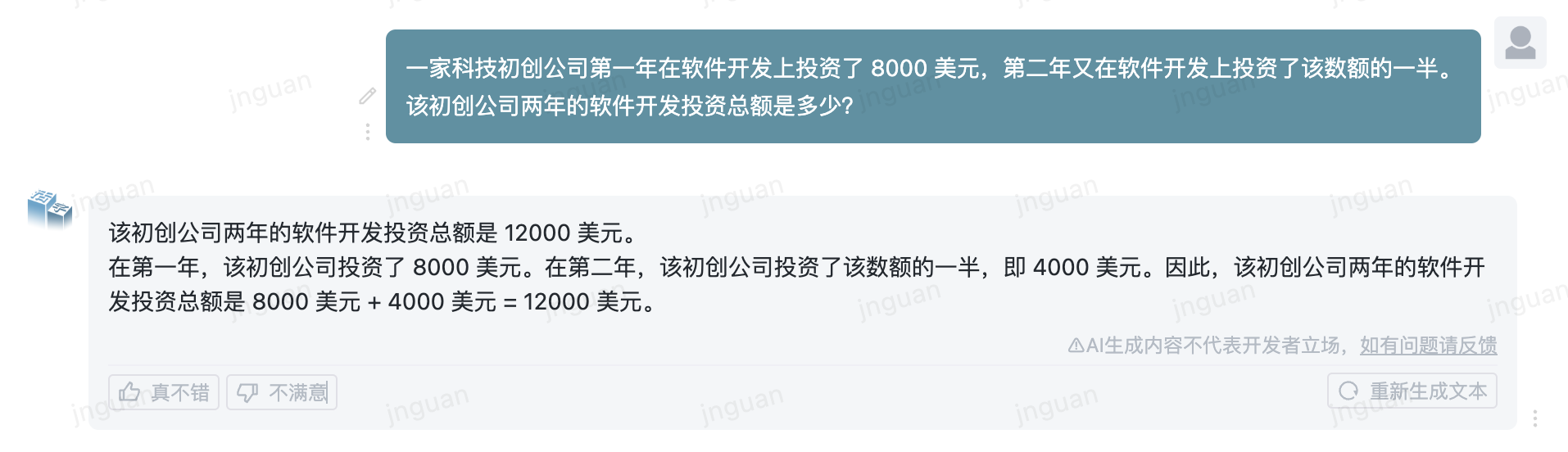



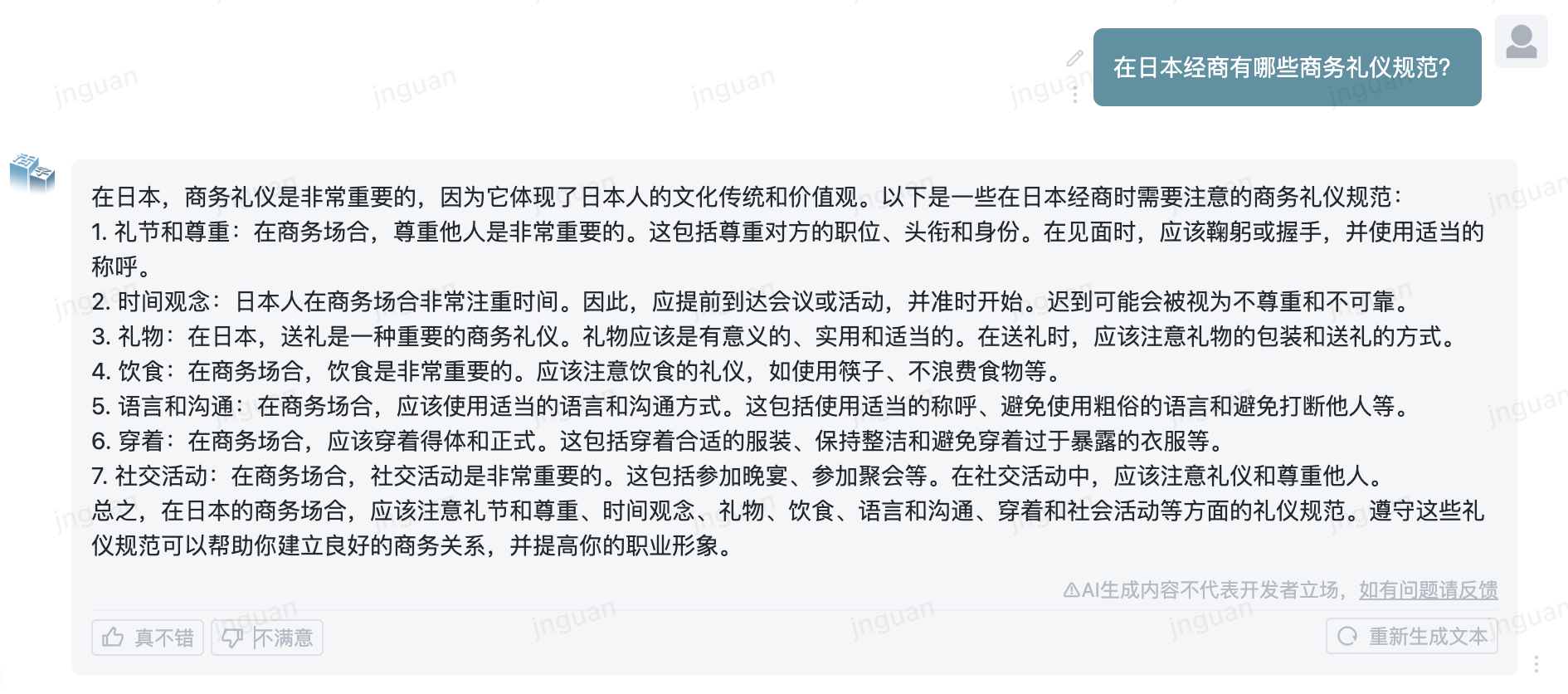
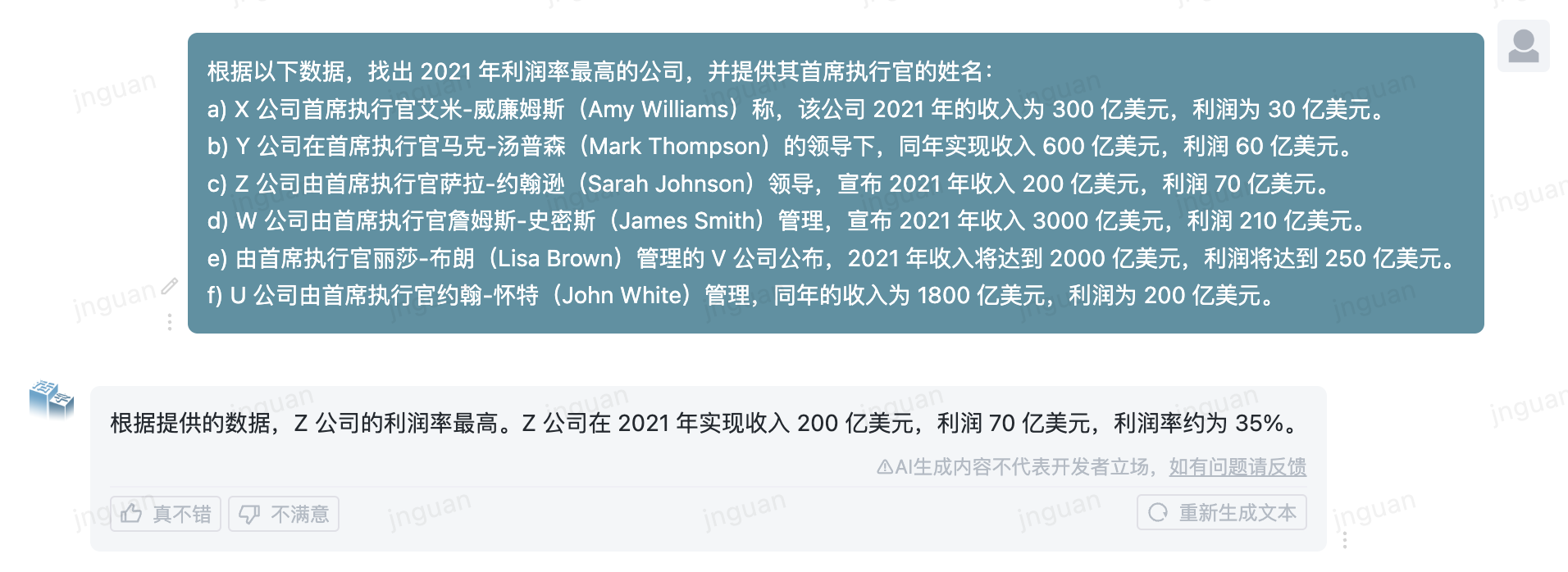
El uso de este código fuente del repositorio está sujeto al acuerdo de licencia de código abierto Apache 2.0.
El tipo móvil está disponible comercialmente. Si utiliza el modelo de tipo móvil o sus derivados para fines comerciales, comuníquese con el licenciante de la siguiente manera para registrarse y solicitar la autorización por escrito del licenciante: contacte al correo electrónico: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

