huozi
Release huozi 3.5
| 장 | 설명 |
|---|---|
| ?? .담 오픈 소스 목록 | 이 창고의 오픈 소스 프로젝트 목록 |
| 모델 소개 | 이동식 유형 모델의 구조 및 훈련 과정에 대한 간단한 소개 |
| ? 모델 다운로드 | 이동식 유형 모델 다운로드 링크 |
| 모델 추론 | VLLM, LLAMA.CPP 및 OLLAMA와 같은 추론 프레임 워크의 사용 프로세스를 포함한 이동식 유형 모델 추론의 예. |
| ? 모델 성능 | 주류 평가 작업에 대한 이동식 유형 모델의 성능 |
| ? 샘플을 생성하십시오 | 이동식 유형 모델의 실제 생성 효과의 예 |

대규모 언어 모델 (LLM)은 자연 언어 처리 분야에서 상당한 진전을 보였으며 광범위한 응용 시나리오에서 강력한 잠재력을 보여주었습니다. 이 기술은 학계의 광범위한 관심을 끌었을뿐만 아니라 업계에서 인기있는 주제가되었습니다. 이러한 배경에 비해 Harbin Institute of Technology (Hit -Scir)의 소셜 컴퓨팅 및 정보 검색 센터는 최근 자연 언어 처리의 연구 및 실질적인 적용을위한 더 많은 가능성과 선택을 제공하기 위해 최신 업적 인 Movable Type 3.5를 시작했습니다.
이동식 유형 3.5는 이동식 유형 3.0 및 중국-믹스 트랄 -8x7b를 기반으로 추가 성능 향상에 의해 얻어진 모델입니다. 이동식 유형 3.5는 32k 길이의 컨텍스트를 지원하고 이동식 유형 3.0의 강력한 포괄적 인 기능을 상속하며 중국어 및 영어 지식 , 수학적 추론 , 코드 생성 , 지침 준수 기능 , 컨텐츠 보안 등과 같은 여러 측면에서 성능 향상을 달성합니다.
중요한
Movable Type Series 모델은 여전히 편견/차별을 포함하는 사실적인 오류 또는 유해한 콘텐츠를 포함하는 오해의 소지가있는 답장을 생성 할 수 있습니다. 생성 된 컨텐츠를 식별하고 사용하고 생성 된 유해한 콘텐츠를 인터넷에 전파하지 마십시오.
이동식 유형 1.0 및 이동식 유형 2.0에 대한 설명서를 참조하십시오. Movable Type 3.0 및 Chinese MT-Bench에 대한 설명서는 여기를 참조하십시오.
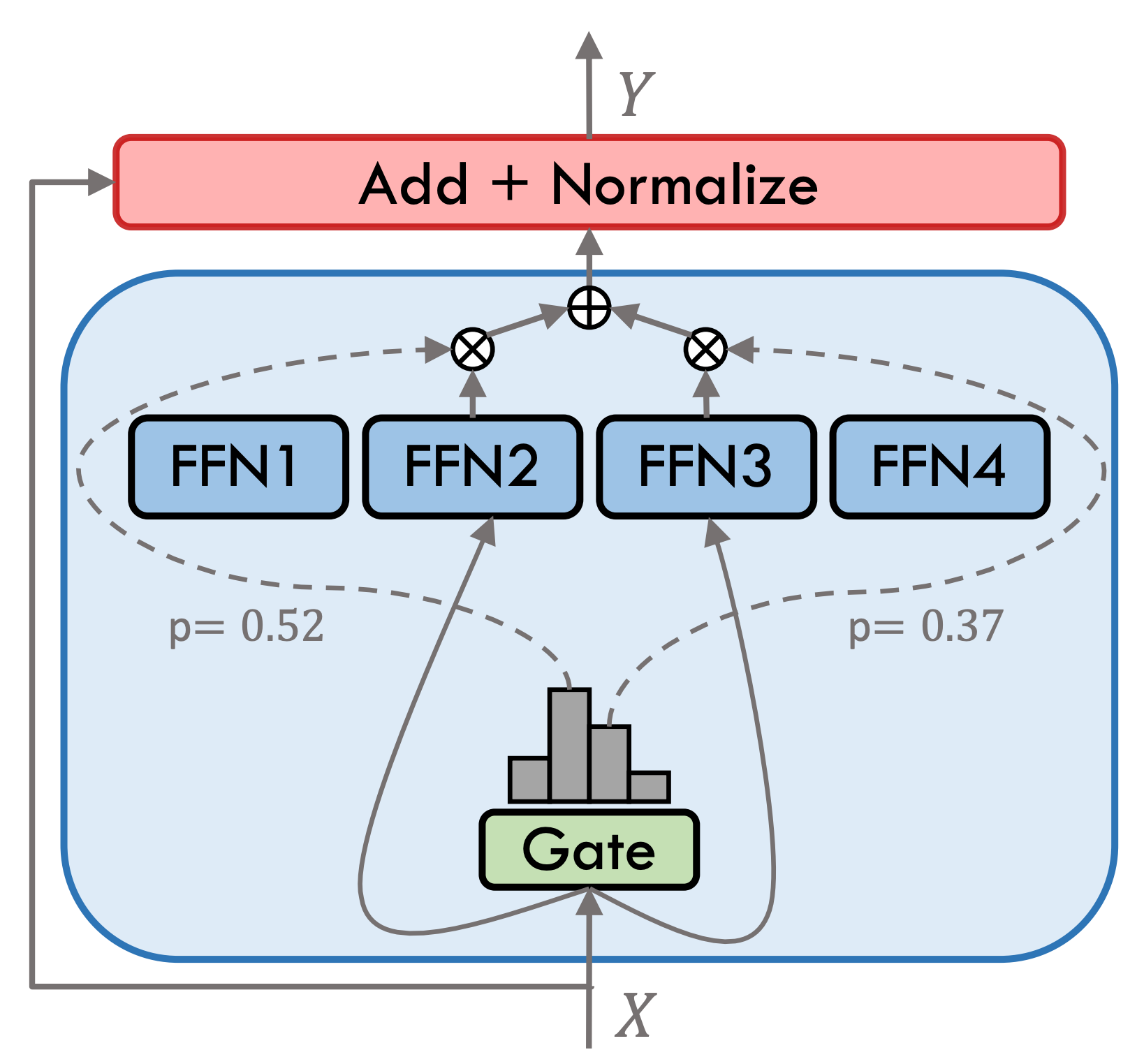
이동식 유형 3.5는 스파 스 하이브리드 전문가 모델 (SMOE)이며 각 전문가 레이어에는 8 개의 FFN이 포함되어 있으며 각 전방 계산은 상위 2에 의해 드물게 활성화됩니다. 이동식 유형 3.5에는 총 46.7b 매개 변수가 있습니다. 희소 활성화 특성 덕분에 실제 추론 중에 13b 매개 변수 만 활성화되어야하므로 컴퓨팅 효율 및 처리 속도가 효과적으로 향상됩니다.
아래 그림과 같이 이동식 유형 3.5는 여러 단계의 훈련을 받았습니다.
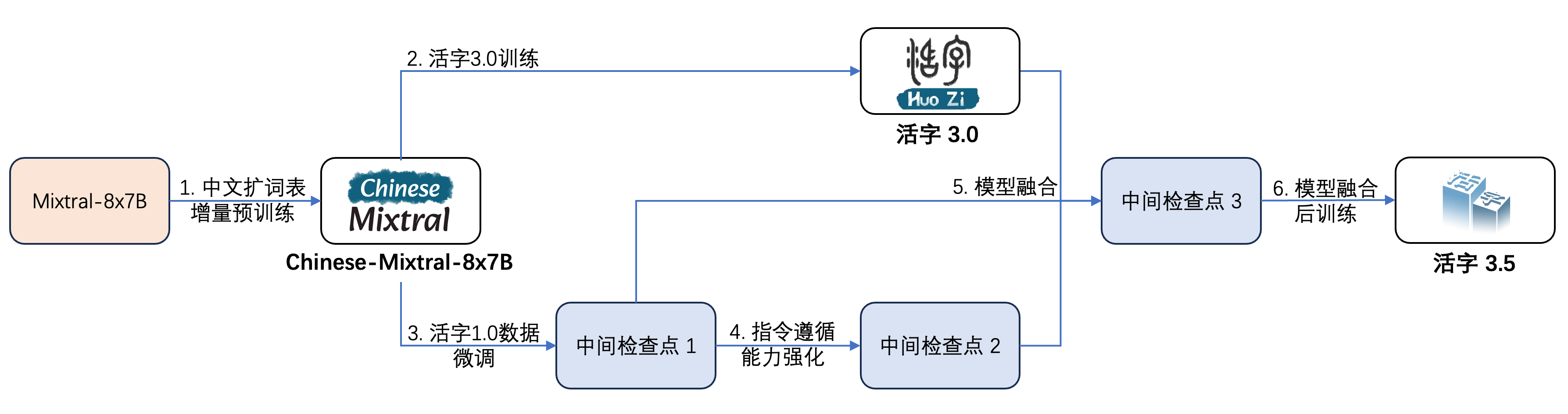
훈련 과정은 다음과 같습니다.
| 모델 이름 | 파일 크기 | 주소를 다운로드하십시오 | 주목 |
|---|---|---|---|
| huozi3.5 | 88GB | ? 포옹 ModelsCope | 이동식 유형 3.5 완전한 모델 |
| huozi3.5-ckpt-1 | 88GB | ? 포옹 ModelsCope | 이동식 유형 3.5 중간 체크 포인트 1 |
| huozi3.5-ckpt-2 | 88GB | ? 포옹 ModelsCope | 이동식 유형 3.5 중간 체크 포인트 2 |
| huozi3.5-ckpt-3 | 88GB | ? 포옹 ModelsCope | 이동식 유형 3.5 중간 체크 포인트 3 |
Movable Type 3.5 또는 Chinese-Mixtral-8x7b를 미세 조정하려면 여기 교육 코드를 참조하십시오.
Movable Type 3.5는 Chatml Format Propt 템플릿을 사용합니다. 형식은 다음과 같습니다.
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
이동식 유형 3.5를 사용한 추론의 예제 코드는 다음과 같습니다.
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5는 Transformers, VLLM, LLAMA.CPP, Ollama, Text Generation Web UI 및 기타 프레임 워크를 포함한 모든 Mixtral 모델 생태계를 지원합니다.
모델을 다운로드하는 동안 네트워크 문제가있는 경우 ModelScope에서 제공하는 체크 포인트를 사용할 수 있습니다.
Transformers는 Tokenizer 용 채팅 템플릿 추가를 지원하고 스트리밍 생성을 지원합니다. 샘플 코드는 다음과 같습니다.
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)ModelsCope의 인터페이스는 변압기와 매우 유사하며 변압기를 모델 스코프로 바꾸십시오.
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))가변 유형 3.5는 VLLM을 통한 추론 가속 구현을 지원하며 샘플 코드는 다음과 같습니다.
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )버라이어티 타입 3.5는 OpenAI API 프로토콜을 지원하는 서비스로 배포 될 수 있으며, 이는 OpenAI API를 통해 다양성 유형 3.5를 직접 호출 할 수 있습니다.
환경 준비 :
$ pip install vllm openai서비스 시작 :
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048OpenAI API를 사용하여 요청을 보냅니다.
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )다음은 OpenAI API + Gradio + 스트리밍을 사용하는 샘플 코드입니다.
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()GGUF 형식은 모델을 빠르게로드하고 저장하도록 설계되었습니다. LLAMA.CPP 팀이 시작하여 LLAMA.CPP, Ollama 등과 같은 프레임 워크에 적합합니다. HuggingFace 형식의 이동식 유형 3.5를 GGUF 형식으로 수동으로 변환 할 수 있습니다.
먼저 llama.cpp의 소스 코드를 다운로드해야합니다. 우리는 저장소에 llama.cpp의 하위 모듈을 제공합니다. 이 버전의 llama.cpp는 테스트되었으며 성공적으로 추론 할 수 있습니다.
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppLlama.cpp 소스 코드의 최신 버전을 다운로드 할 수도 있습니다.
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cpp그런 다음 컴파일해야합니다. 하드웨어 플랫폼에 따라 컴파일 명령에는 미묘한 차이가 있습니다.
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 다음 명령은 llama.cpp/ directory에 있어야합니다.
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 다음 명령은 llama.cpp/ directory에 있어야합니다.
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " -ngl 파라미터는 GPU에 오프로드 레이어 수를 나타냅니다. 이 값을 줄이면 GPU 비디오 메모리 압력이 완화 될 수 있습니다. 실제 테스트 후 Q2_K 양자화 된 모델은 16 계층 오프로드를 가지며 메모리 사용량을 9.6GB로 줄일 수 있으며, 이는 소비자 GPU에서 모델을 실행할 수 있습니다.
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " main 의 더 많은 매개 변수는 llama.cpp의 공식 문서를 참조 할 수 있습니다.
추론을 위해 Ollama 프레임 워크를 사용하십시오. Ollama의 ReadMe 지침을 참조하십시오.
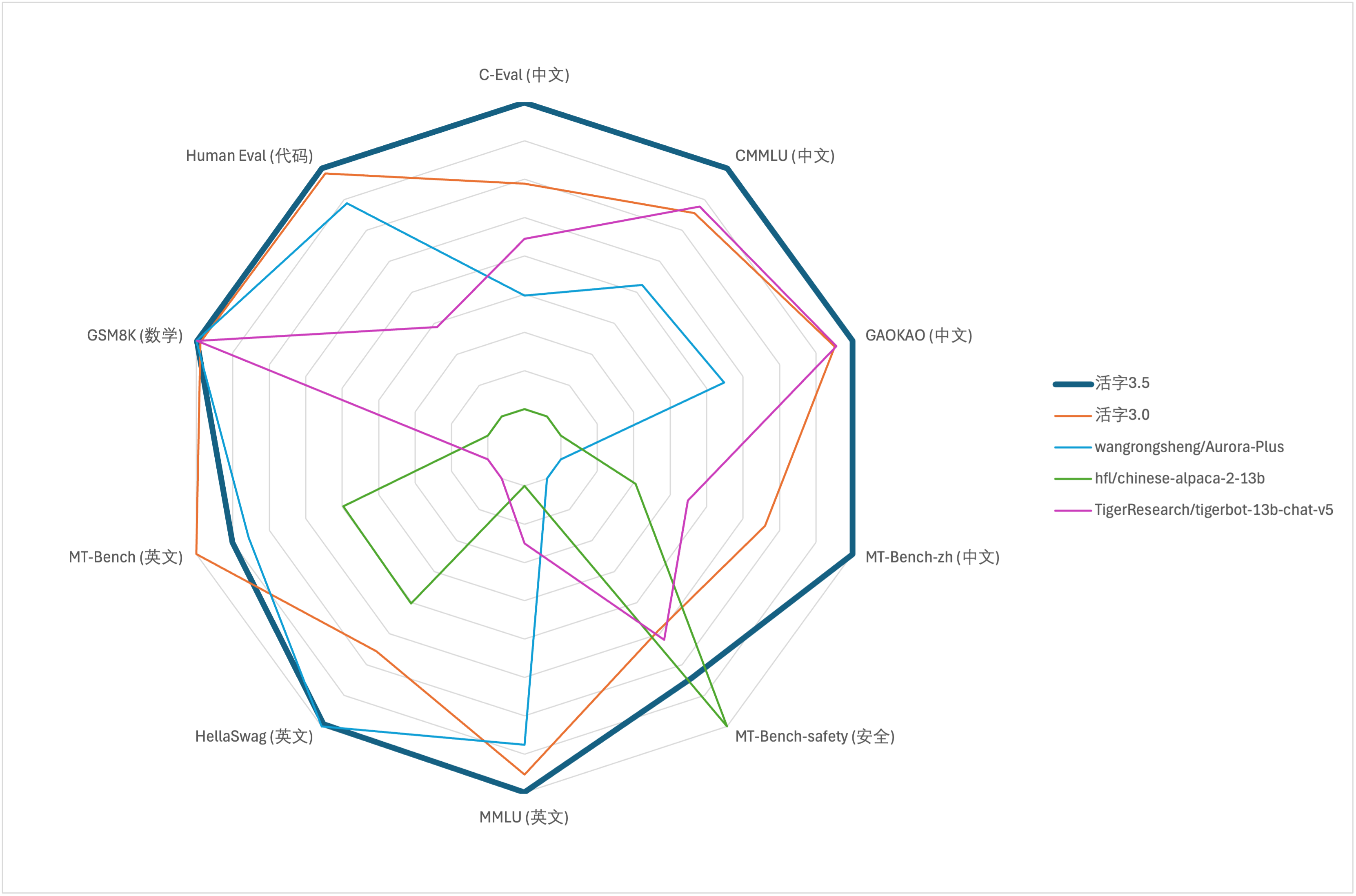
대형 모델의 포괄적 인 능력 평가를 위해 다음 평가 데이터 세트를 사용하여 각각 이동식 유형 3.5를 평가했습니다.
이동식 유형 3.5는 추론 할 때 13b 매개 변수 만 활성화합니다. 다음 표는 각 평가 데이터 세트에서 이동식 유형 3.5 및 기타 13b 스케일의 중국 모델과 이전 버전의 이동식 유형의 결과를 보여줍니다.
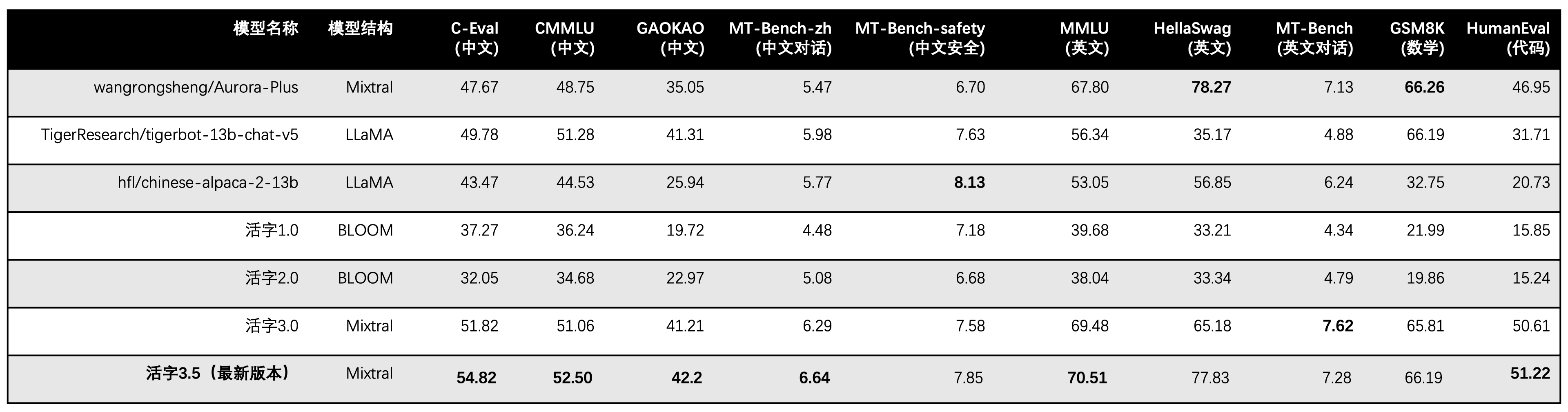
우리는 C-Eval, CMMLU 및 MMLU에서 5- 샷을 사용하고 GSM8K는 4- 샷, Hellaswag 및 HumaneVal 사용 0- 샷을 사용하고 HumaneVal 사용 Pass@1 표시기를 사용합니다. 모든 테스트는 탐욕스러운 전략이었습니다.
우리는 OpenCompass를 평가 프레임 워크로 사용하고 Commit 해시는 4C87E77입니다. 검토 코드는 여기에 있습니다.
이동식 유형 3.0의 성능 평가에서 HumaneVal의 기본 모델 평가 방법을 잘못 사용했으며 올바른 평가 결과가 위 표에서 업데이트되었습니다.
위의 테이블의 테스트 결과에 따르면, 이동식 유형 3.5는 이동식 유형 3.0과 비교하여 비교적 안정적인 성능 개선을 달성했으며, 중국어 및 영어 지식 , 수학적 추론 , 코드 생성 , 중국어 교육 규정 준수 능력 및 중국 콘텐츠 3.5의 중국 내용 보안이 강화되었습니다.
다음은 MT-Bench-ZH 평가 세트에 대한 이동식 유형 3.5의 생성 효과입니다.
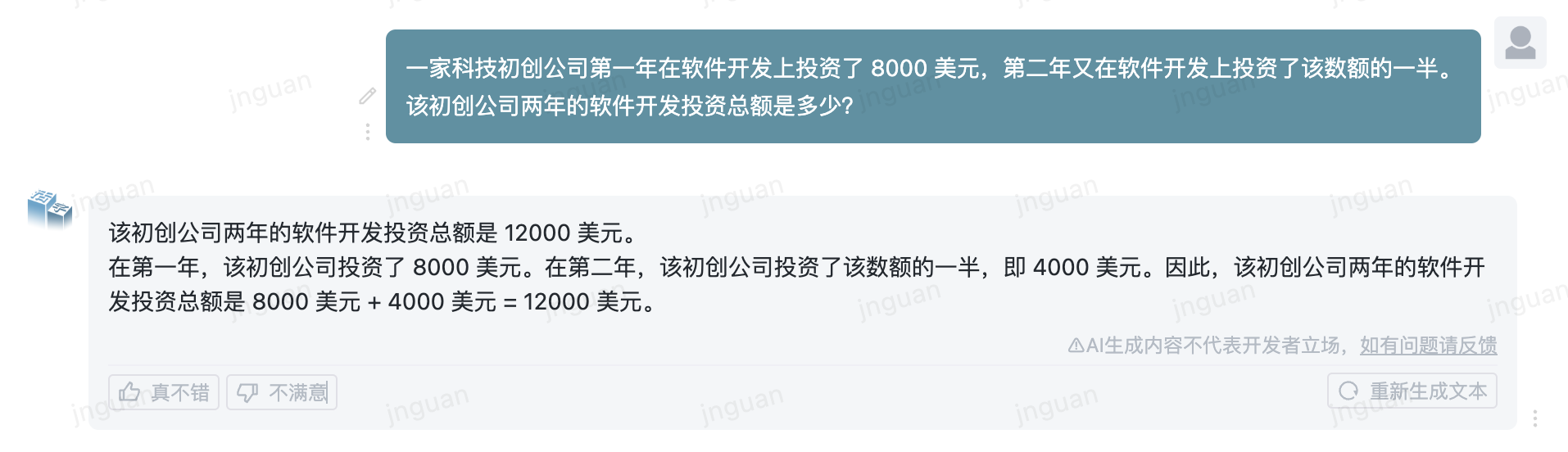



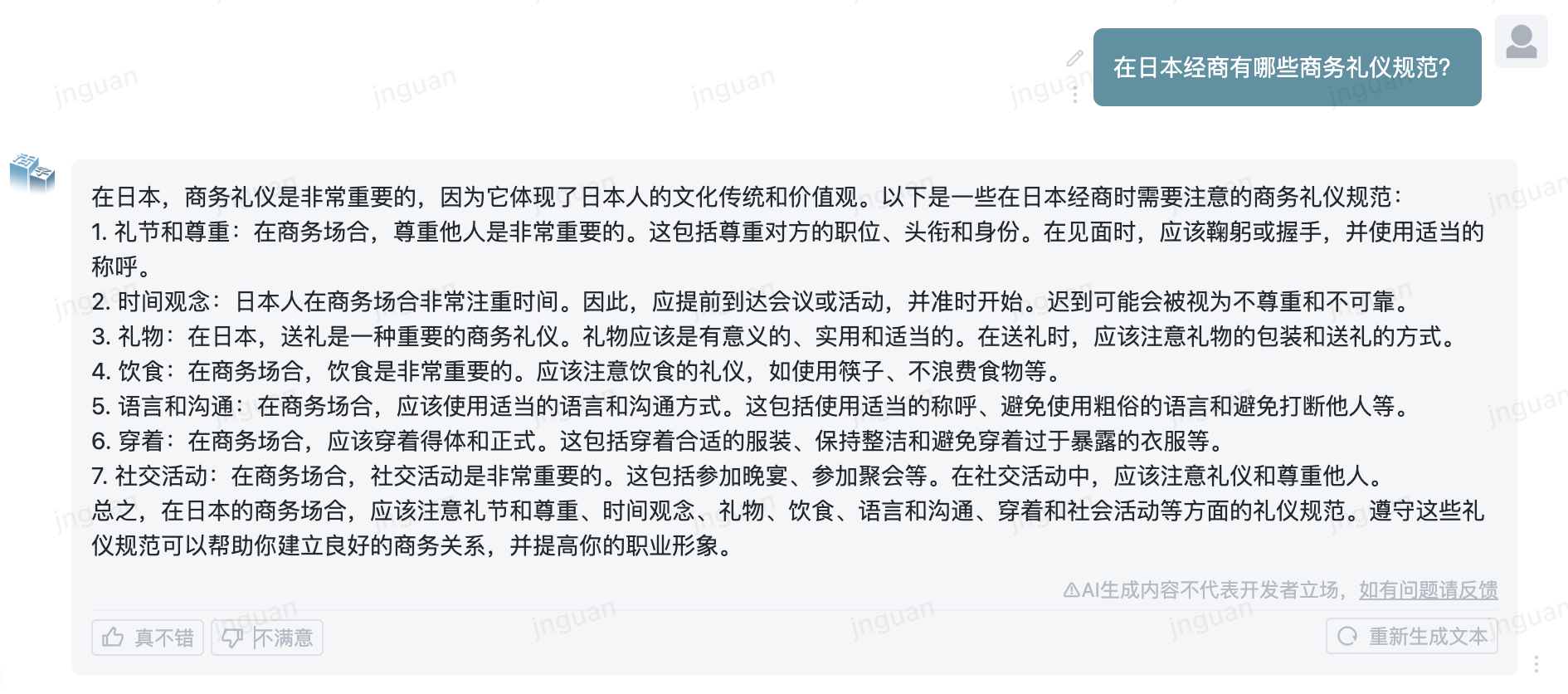
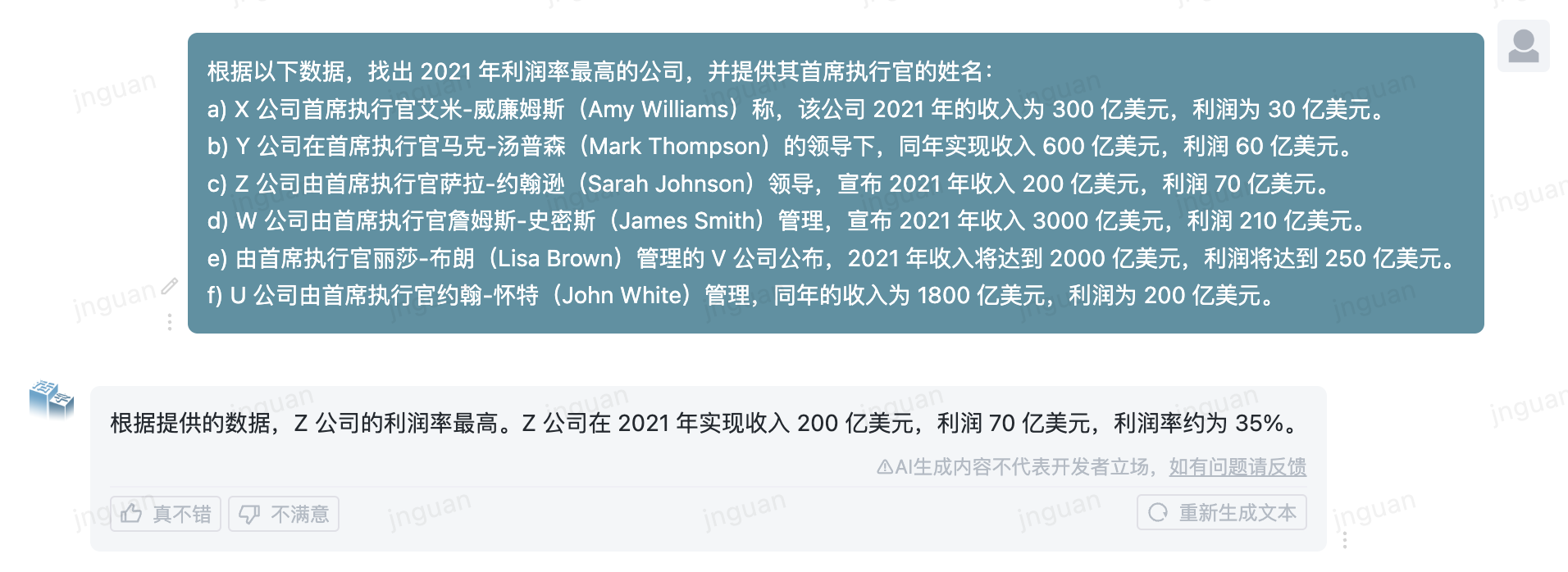
이 저장소 소스 코드의 사용은 오픈 소스 라이센스 계약 APACHE 2.0의 적용을받습니다.
모바일 유형은 상업적으로 이용 가능합니다. 상업용 목적으로 이동식 유형 모델 또는 그 파생 상품을 사용하는 경우 라이센스 제공자에게 문의하고 서면 승인을 신청하려면 라이센스 제공자에게 문의하십시오.
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

