huozi
Release huozi 3.5
| глава | иллюстрировать |
|---|---|
| Создание списка с открытым исходным кодом | Список проектов с открытым исходным кодом на этом складе |
| Введение модели | Краткое введение в структуру и учебный процесс модели подвижного типа |
| ? Модель скачать | Ссылка для загрузки модели подвижного типа |
| Модель рассуждения | Примеры вывода модели подвижного типа, включая процесс использования структур вывода, таких как VLLM, Llama.cpp и Ollama. |
| ? Производительность модели | Производительность модели подвижного типа по основной оценке задач |
| ? Генерировать образец | Примеры фактического эффекта генерации модели подвижного типа |

Крупномасштабная языковая модель (LLM) добилась значительного прогресса в области обработки естественного языка и продемонстрировала свой сильный потенциал в широком спектре сценариев применения. Эта технология не только привлекала широкое внимание академического сообщества, но и стала горячей темой в отрасли. На этом фоне Центр социальных вычислений и извлечения информации Института технологии Харбина (HIT -SCIR) недавно запустил последние достижения - подвижный тип 3.5 , приверженные предоставлению большего количества возможностей и выбора для исследования и практического применения обработки естественного языка.
Подвижный тип 3.5-это модель, полученная путем дальнейшего повышения производительности на основе подвижного типа 3.0 и китайского Миксал-8x7B. Подвижный тип 3.5 поддерживает контекст длиной 32K , наследует мощные всеобъемлющие возможности подвижного типа 3.0 и достигает улучшения производительности во многих аспектах, таких как знание китайского и английского языка , математические рассуждения , генерация кода , возможности соответствия инструкциям , безопасность контента и т. Д.
Важный
Модель серии подвижных типов может по -прежнему генерировать вводящие в заблуждение ответы, содержащие фактические ошибки или вредное содержание, которое содержит смещение/дискриминацию. Пожалуйста, будьте осторожны, чтобы идентифицировать и использовать сгенерированный контент и не распространять сгенерированный вредный контент в Интернет.
Пожалуйста, смотрите документацию для подвижного типа 1.0 и подвижного типа 2.0 здесь. Пожалуйста, смотрите здесь для документации по подвижному типу 3.0 и китайскому MT-Bench.
Подвижный тип 3.5-редкая гибридная экспертная модель (SMOE), каждый экспертный слой содержит 8 FFN, и каждый прямое расчет редко активируется TOP-2. Подвижный тип 3.5 имеет в общей сложности 46,7B параметры. Благодаря его редким характеристикам активации необходимо активировать только параметры 13B во время фактических рассуждений, что эффективно повышает эффективность вычислений и скорость обработки.
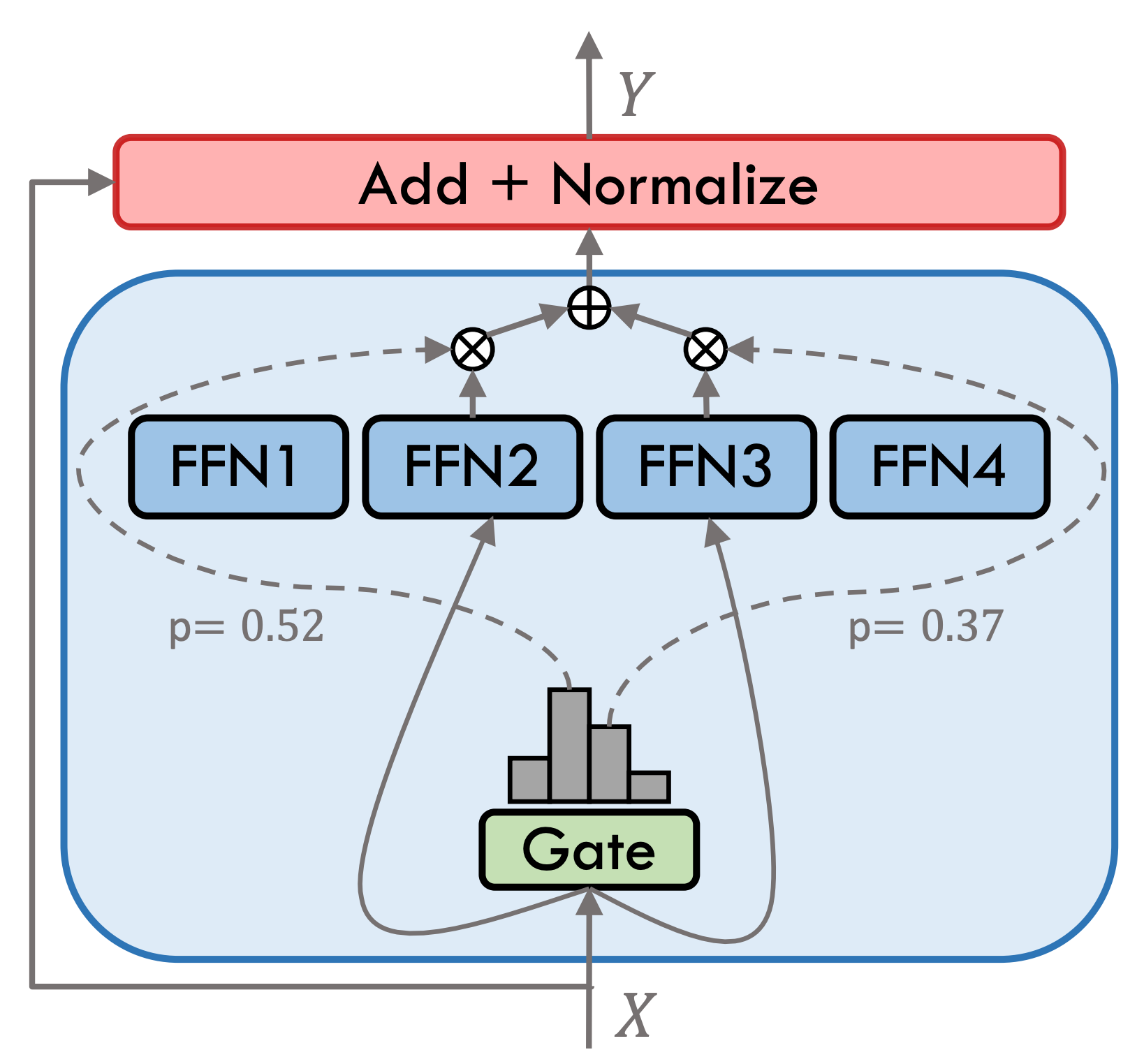
Подвижный тип 3.5 подвергся нескольким этапам обучения, как показано на рисунке ниже:
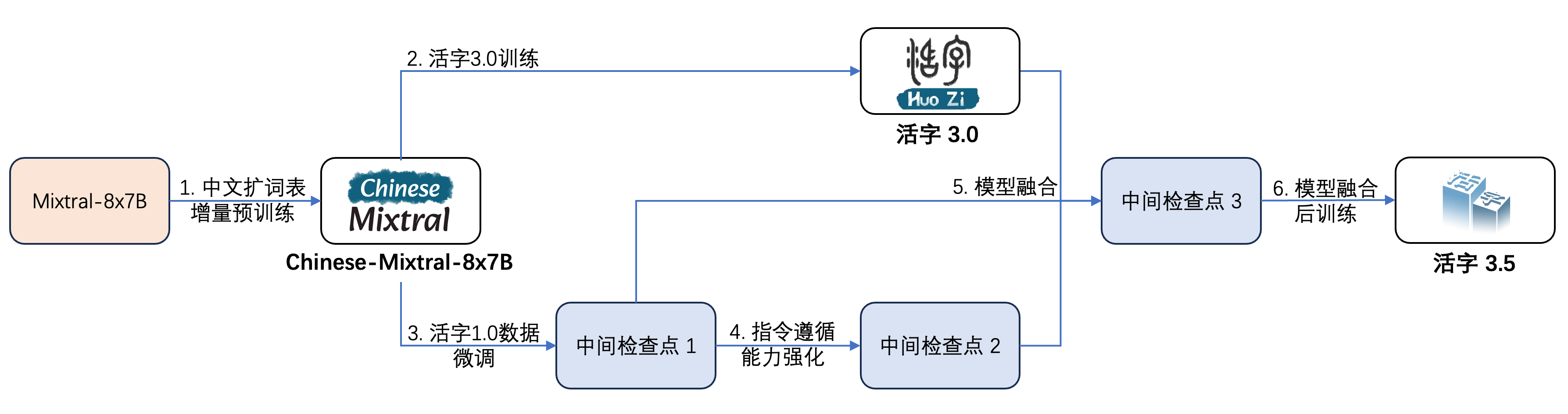
Процесс обучения:
| Название модели | Размер файла | Скачать адрес | Примечание |
|---|---|---|---|
| Huozi3.5 | 88 ГБ | ? Huggingface Моделикоп | Подвижной тип 3.5 Полная модель |
| HUOZI3.5-CKPT-1 | 88 ГБ | ? Huggingface Моделикоп | Подвижный тип 3.5 Промежуточная контрольная точка 1 |
| HUOZI3.5-CKPT-2 | 88 ГБ | ? Huggingface Моделикоп | Подвижный тип 3.5 Промежуточная контрольная точка 2 |
| HUOZI3.5-CKPT-3 | 88 ГБ | ? Huggingface Моделикоп | Подвижный тип 3.5 Промежуточная контрольная точка 3 |
Если вы хотите настроить подвижный тип 3.5 или китайский Mixtral-8x7b, обратитесь к коду обучения здесь.
Подвижный тип 3.5 использует шаблон Propt Format Chatml, формат:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
Пример кода рассуждения с использованием подвижного типа 3.5 выглядит следующим образом:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5 поддерживает все экосистемы миктральной модели, включая трансформаторы, VLLM, Llama.cpp, Ollama, веб -интерфейс Text Generation и другие рамки.
Если у вас есть проблемы с сетью при загрузке вашей модели, вы можете использовать контрольные точки, которые мы предоставляем на моделях.
Трансформеры поддерживают добавление шаблонов чата для токенизатора и поддерживают потоковую генерацию. Пример кода заключается в следующем:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)Интерфейс ModelsCope очень похож на трансформаторы, просто замените трансформаторы на прицел модели:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Переменная Тип 3.5 поддерживает реализацию ускорения вывода через VLLM, а пример кода заключается в следующем:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Разнообразие типа 3.5 может быть развернут в качестве сервиса, которая поддерживает протокол API OpenAI, который позволяет выставлять напрямую через API OpenAI типа 3.5.
Подготовка окружающей среды:
$ pip install vllm openaiНачните сервис:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Отправить запросы с помощью API OpenAI:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Вот пример кода, который использует OpenAI API + Gradio + потоковая передача:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()Формат GGUF предназначен для быстрого загрузки и сохранения моделей. Он запущен командой Llama.cpp и подходит для таких рамок, как llama.cpp, ollama и т. Д.
Во -первых, вам нужно скачать исходный код llama.cpp. Мы предоставляем подмодуль llama.cpp в репозитории. Эта версия llama.cpp была проверена и может успешно сделать вывод:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppВы также можете скачать последнюю версию исходного кода Llama.cpp:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppТогда это должно быть скомпилировано. Существуют тонкие различия в командах компиляции в зависимости от вашей аппаратной платформы:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 Следующая команда должна быть в llama.cpp/ Directory:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 Следующая команда должна быть в llama.cpp/ Directory:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Параметр -ngl указывает количество слоев разгрузки в графический процессор. Сокращение этого значения может облегчить давление в видео памяти GPU. После нашего фактического теста квантовая модель Q2_K имеет 16-слойную разгрузку, и использование памяти может быть уменьшено до 9,6 ГБ, что может запустить модель на графических процессорах потребителей:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Для получения дополнительных параметров main вы можете обратиться к официальной документации Llama.cpp.
Используйте Ollama Framework для рассуждения, вы можете ссылаться на инструкции Ollama Readme.
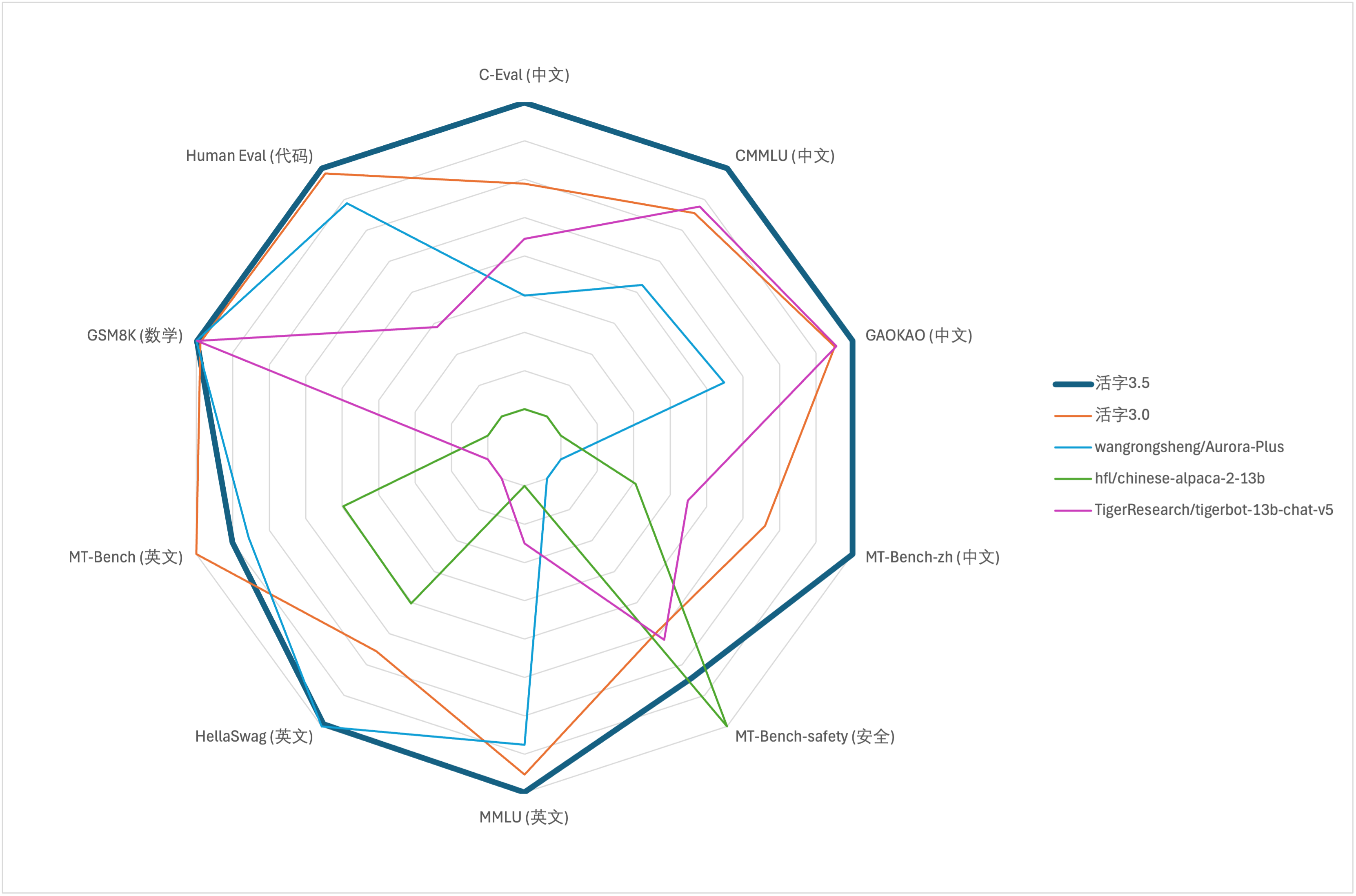
Для оценки комплексной способности крупных моделей мы использовали следующий набор данных оценки для оценки подвижного типа 3.5 соответственно:
Подвижный тип 3.5 активирует только 13b параметры при выводе. В следующей таблице показаны результаты китайских моделей подвижного типа 3.5 и других 13B шкал и старой версии подвижного типа в каждом наборе данных оценки:
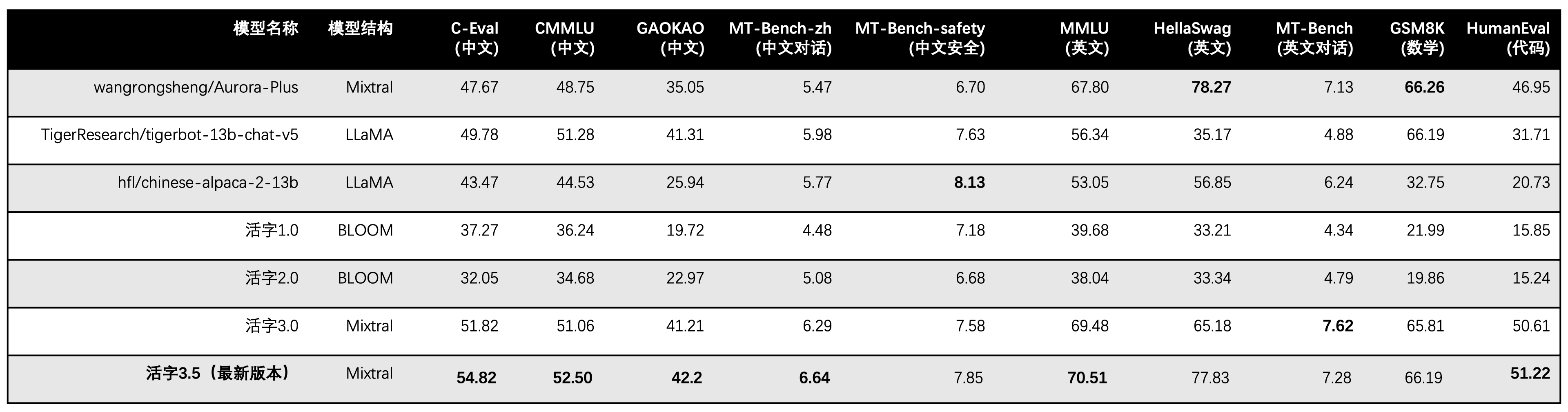
Мы используем 5 выстрелов в C-eval, CMMLU и MMLU, GSM8K используют 4-выстрел, Hellaswag и Humaneval использование 0-Shot, а Humaneval использует индикатор Pass@1. Все тесты были жадной стратегией.
Мы используем OpenCompass в качестве структуры оценки, а хэш коммита - 4C87E77. Код обзора находится здесь.
В оценке эффективности подвижного типа 3.0 мы неправильно использовали метод оценки базовой модели в гуманевале, и правильные результаты оценки были обновлены в приведенной выше таблице.
Согласно результатам теста в вышеуказанной таблице, подвижный тип 3.5 достиг относительно стабильного улучшения производительности по сравнению с подвижным типом 3.0, и были укреплены знания китайского и английского языка , математические рассуждения , генерация кода , способность соблюдения требований китайского обучения и безопасность контента китайского подвижного типа 3.5.
Ниже приводится эффект генерации подвижного типа 3.5 на набор оценки MT-Bench-ZH:
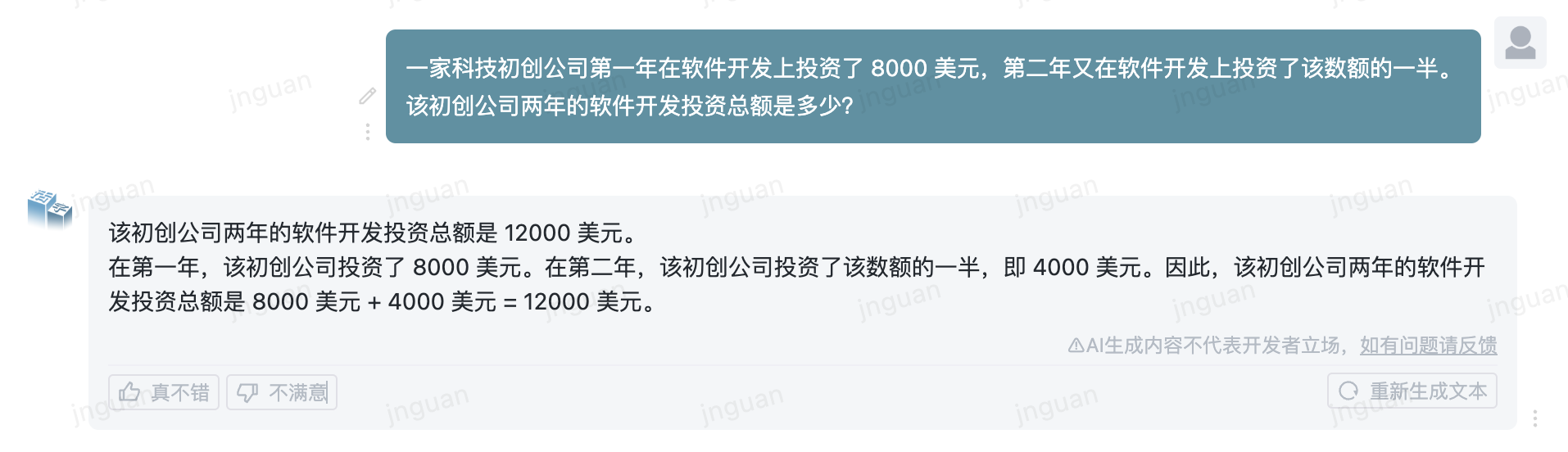



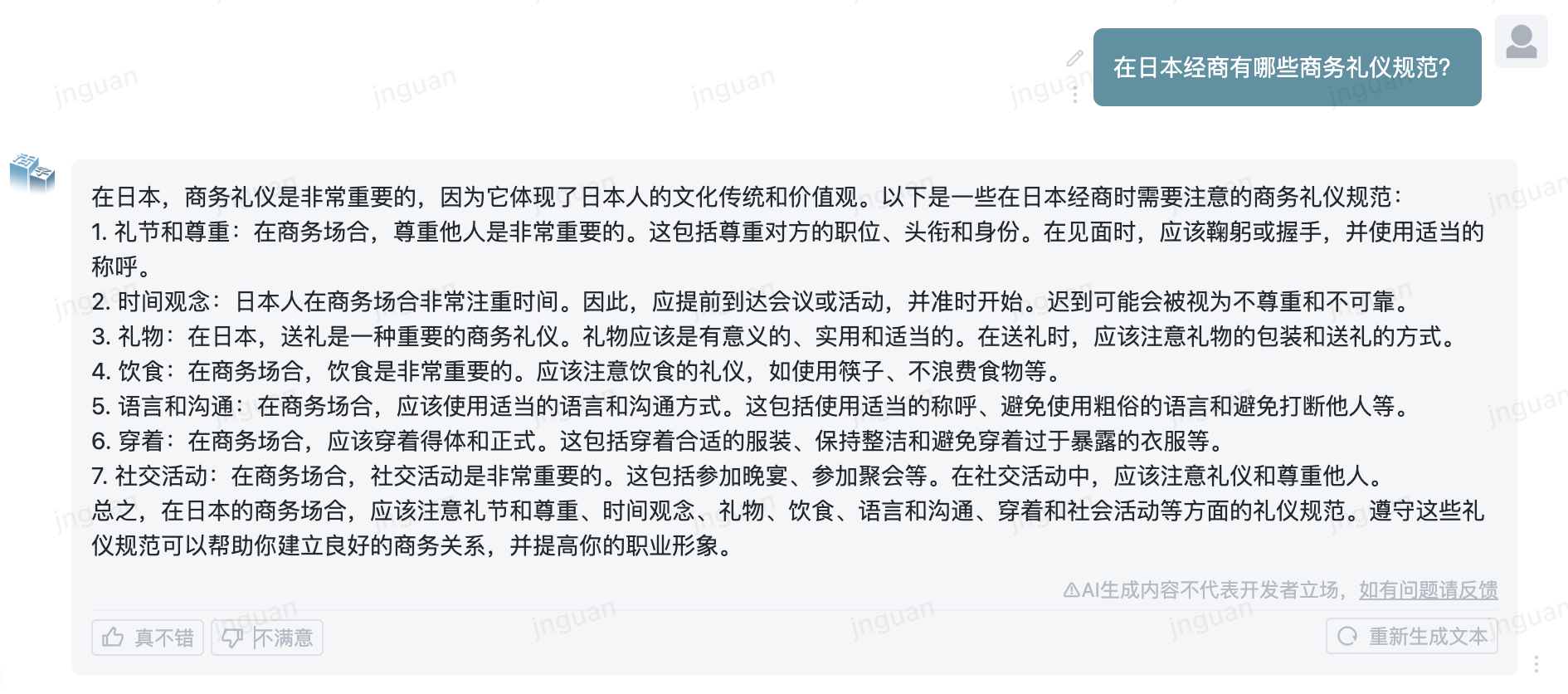
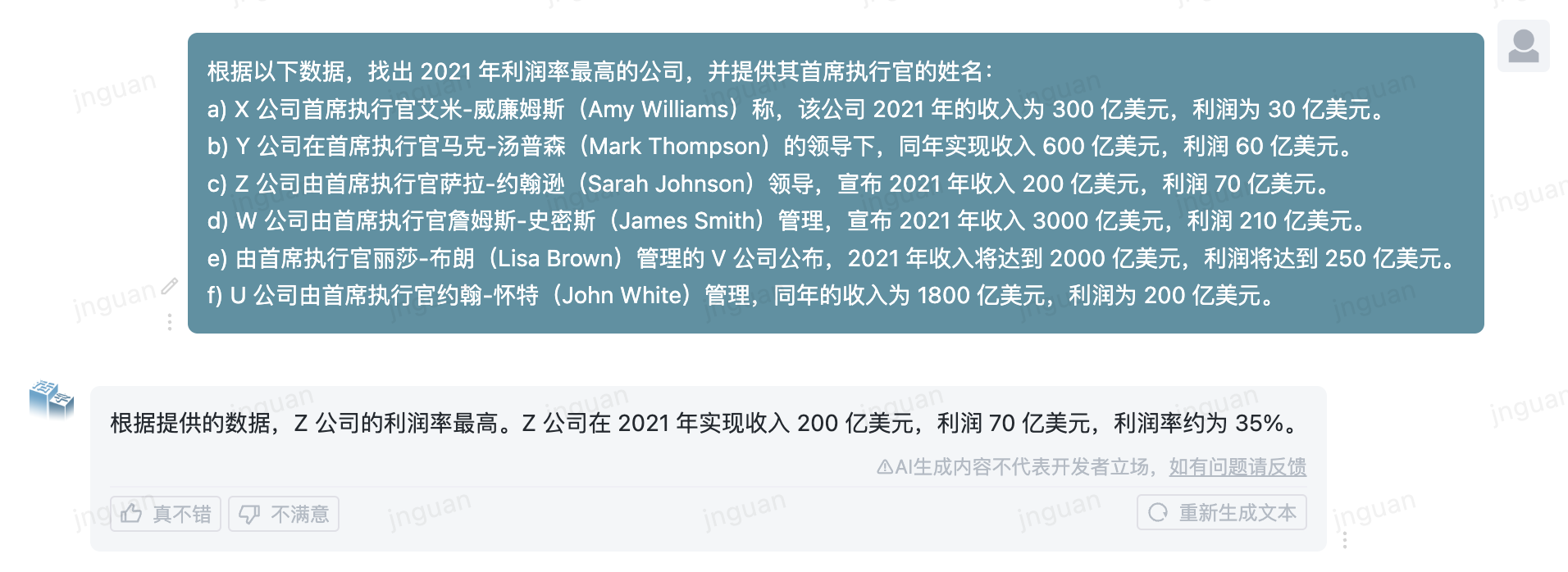
Использование этого исходного кода репозитория подлежит лицензионному соглашению с открытым исходным кодом Apache 2.0.
Мобильный тип коммерчески доступен. Если вы используете модель подвижного типа или ее производные в коммерческих целях, пожалуйста, свяжитесь с лицензиаром следующим образом, чтобы зарегистрироваться и подать заявку на письменное разрешение от лицензиара: Контактная электронная почта: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

