huozi
Release huozi 3.5
| Kapitel | veranschaulichen |
|---|---|
| Ähm Open Source -Liste | Liste der Open -Source -Projekte in diesem Lagerhaus |
| Modelleinführung | Kurze Einführung in den Struktur- und Trainingsprozess des beweglichen Typmodells |
| ? Modell Download | MOVABLE TYPE MODEL DOWNLOAD -LIND |
| Modellminimierung | Beispiele für bewegliche Typmodellinferenz, einschließlich des Nutzungsprozesses von Inferenz -Frameworks wie Vllm, Lama.cpp und Ollama. |
| ? Modellleistung | Leistung des beweglichen Typmodells bei Mainstream -Bewertungsaufgaben |
| ? Probe erzeugen | Beispiele für den tatsächlichen Erzeugungseffekt des beweglichen Typmodells |

Das großräumige Sprachmodell (LLM) hat im Bereich der Verarbeitung natürlicher Sprache erhebliche Fortschritte erzielt und sein starkes Potenzial in einer Vielzahl von Anwendungsszenarien gezeigt. Diese Technologie erregte nicht nur die akademische Gemeinschaft, sondern wurde auch zu einem heißen Thema in der Branche. Vor diesem Hintergrund hat das Zentrum für Social Computing und Information Abruf des Harbin Institute of Technology (HIT -SCIR) kürzlich die neueste Errungenschaft auf den Markt gebracht - bewegbarer Typ 3.5 , der sich dafür einsetzt, mehr Möglichkeiten und Auswahlmöglichkeiten für die Forschung und die praktische Anwendung der Verarbeitung natürlicher Sprache zu bieten.
Der bewegliche Typ 3.5 ist ein Modell, das durch weitere Leistungsverbesserung basierend auf beweglichen Typ 3.0 und chinesischem Mixtral-8x7b erhalten wird. Movable Typ 3.5 unterstützt einen langen Kontext von 32K , erbt die leistungsstarken umfassenden Fähigkeiten des beweglichen Typs 3.0 und erzielt Leistungsverbesserungen in vielen Aspekten wie chinesischem und englischem Wissen , mathematisches Denken , Codegenerierung , Compliance -Funktionen für Anweisungen , Inhaltssicherheit usw.
Wichtig
Das Modell der beweglichen Typ -Serien kann möglicherweise weiterhin irreführende Antworten erzeugen, die Faktenfehler oder schädliche Inhalte enthalten, die Verzerrungen/Diskriminierung enthält. Bitte achten Sie darauf, den generierten Inhalt zu identifizieren und zu verwenden, und verteilen Sie die generierten schädlichen Inhalte nicht im Internet.
In der Dokumentation für bewegliche Typ 1.0 und bewegliche Typ 2.0 finden Sie hier. Weitere Dokumentationen zum beweglichen Typ 3.0 und chinesischen MT-Bench finden Sie hier.
Movable Typ 3.5 ist ein spärliches Hybrid-Expertenmodell (Smoe), jede Expertenschicht enthält 8 FFNs, und jede Vorwärtsberechnung wird durch Top-2 spärlich aktiviert. Der bewegliche Typ 3.5 hat insgesamt 46,7B -Parameter. Dank der spärlichen Aktivierungseigenschaften müssen nur 13B -Parameter während des tatsächlichen Arguments aktiviert werden, was die Recheneffizienz und die Verarbeitungsgeschwindigkeit effektiv verbessert.
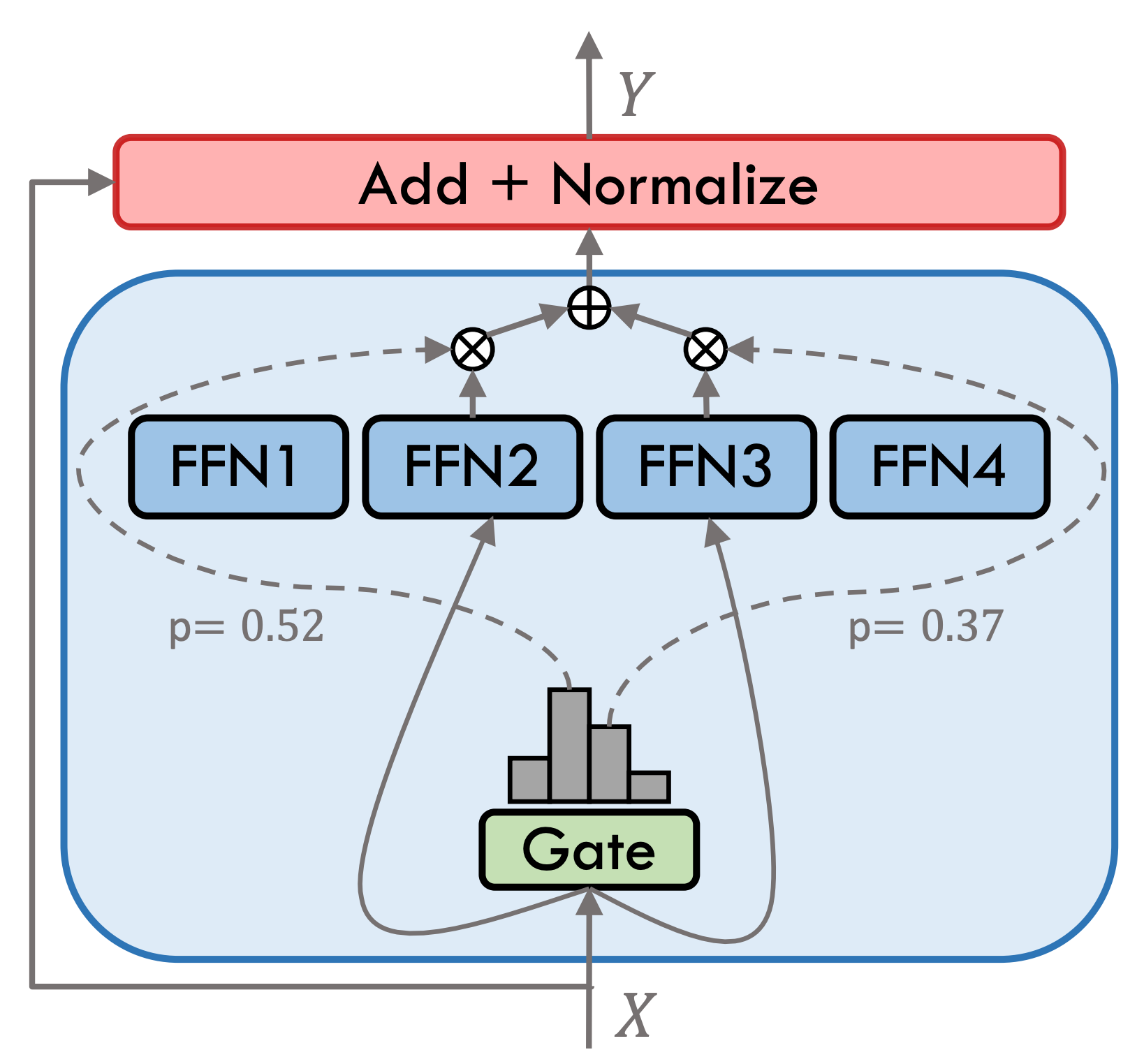
Der bewegliche Typ 3.5 hat mehrere Trainingsschritte durchgeführt, wie in der folgenden Abbildung gezeigt:
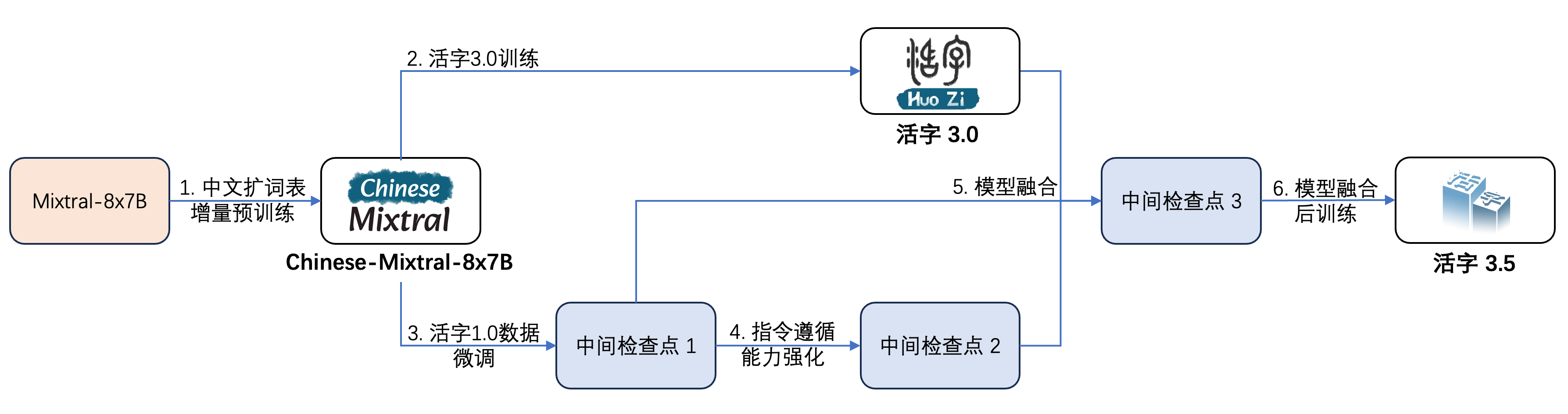
Der Schulungsprozess ist:
| Modellname | Dateigröße | Adresse herunterladen | Bemerkung |
|---|---|---|---|
| Huozi3.5 | 88 GB | ? Umarmung ModelsCope | Beweglicher Typ 3.5 Komplettes Modell |
| Huozi3.5-CKPT-1 | 88 GB | ? Umarmung ModelsCope | Beweglicher Typ 3.5 Intermediate Checkpoint 1 |
| Huozi3.5-CKPT-2 | 88 GB | ? Umarmung ModelsCope | Beweglicher Typ 3.5 Intermediate Checkpoint 2 |
| Huozi3.5-CKPT-3 | 88 GB | ? Umarmung ModelsCope | Beweglicher Typ 3.5 Intermediate Checkpoint 3 |
Wenn Sie bewegliche Typ 3.5 oder chinesisch-mixtral-8x7b fein abgestimmen möchten, finden Sie hier den Trainingscode.
Movable Typ 3.5 verwendet das ChatML -Format -ProPT -Vorlage. Das Format lautet:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
Der Beispielcode für die Argumentation unter Verwendung des beweglichen Typs 3.5 ist wie folgt:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Typ 3.5 unterstützt alle Mixtral -Modell -Ökosysteme, einschließlich Transformers, Vllm, Llama.cpp, Ollama, Web -UI -UI und anderen Frameworks.
Wenn Sie beim Herunterladen Ihres Modells Netzwerkprobleme haben, können Sie die von uns angestellten Kontrollpunkte auf ModelsCope verwenden.
Transformers unterstützen das Hinzufügen von Chat -Vorlagen für Tokenizer und unterstützt die Streaming -Generierung. Der Beispielcode lautet wie folgt:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)Die Schnittstelle von ModelsCope ist Transformatoren sehr ähnlich. Ersetzen Sie Transformatoren einfach durch Modellumfang:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Variabler Typ 3.5 unterstützt die Implementierung der Inferenzbeschleunigung durch VLLM, und der Beispielcode lautet wie folgt:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Der Varietytyp 3.5 kann als Dienst bereitgestellt werden, der das OpenAI -API -Protokoll unterstützt, mit dem die Varietytyp 3.5 direkt über die OpenAI -API aufgerufen werden kann.
Umweltvorbereitung:
$ pip install vllm openaiStarten Sie den Service:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Anfragen mit OpenAI -API senden:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Hier ist ein Beispielcode, der OpenAI API + Gradio + Streaming verwendet:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()Das GGUF -Format ist so konzipiert, dass sie Modelle schnell laden und speichern. Es wird vom Lama.CPP -Team gestartet und eignet sich für Frameworks wie llama.cpp, Ollama usw. Sie können den beweglichen Typ 3.5 im GGUF -Format manuell in das GGUF -Format konvertieren.
Zunächst müssen Sie den Quellcode von lama.cpp herunterladen. Wir stellen das Submodul von llama.cpp im Repository zur Verfügung. Diese Version von llama.cpp wurde getestet und kann erfolgreich schließen:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppSie können auch die neueste Version von llama.cpp Quellcode herunterladen:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppDann muss es zusammengestellt werden. Abhängig von Ihrer Hardware -Plattform gibt es subtile Unterschiede in den Kompilierungsbefehlen:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 Der folgende Befehl muss im Verzeichnis llama.cpp/ verzeichnet sein:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 Der folgende Befehl muss im Verzeichnis llama.cpp/ verzeichnet sein:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Der Parameter -ngl gibt die Anzahl der Offloadschichten an die GPU an. Durch die Reduzierung dieses Wertes kann der GPU -Videospeicherdruck lindern. Nach unserem tatsächlichen Test verfügt das quantisierte Q2_K-Modell über einen 16-Schicht-Offload, und die Speicherverwendung kann auf 9,6 GB reduziert werden, wodurch das Modell für Verbraucher-GPUs ausgeführt werden kann:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Weitere Parameter von main finden Sie auf die offizielle Dokumentation von llama.cpp.
Verwenden Sie das OLLAMA -Framework, um sich zu argumentieren, Sie können sich auf Ollamas Readme -Anweisungen beziehen.
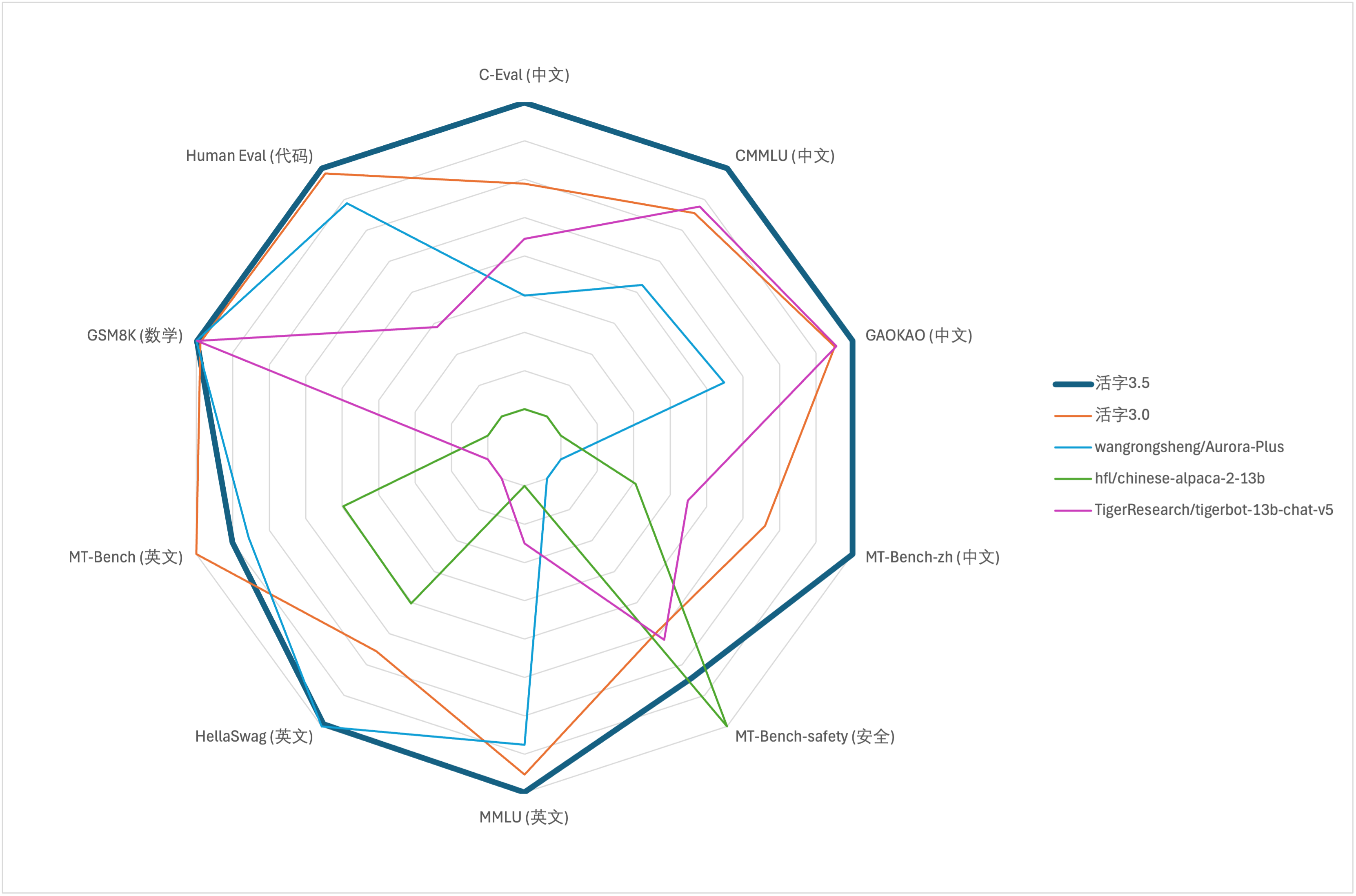
Für die umfassende Fähigkeitsbewertung großer Modelle verwendeten wir den folgenden Bewertungsdatensatz, um den beweglichen Typ 3.5 zu bewerten:
Der bewegliche Typ 3.5 aktiviert nur 13b -Parameter, wenn die Inferenz inferenz ist. Die folgende Tabelle zeigt die Ergebnisse chinesischer Modelle des beweglichen Typs 3.5 und anderer 13B -Skalen und die alte Version des beweglichen Typs auf jedem Bewertungsdatensatz:
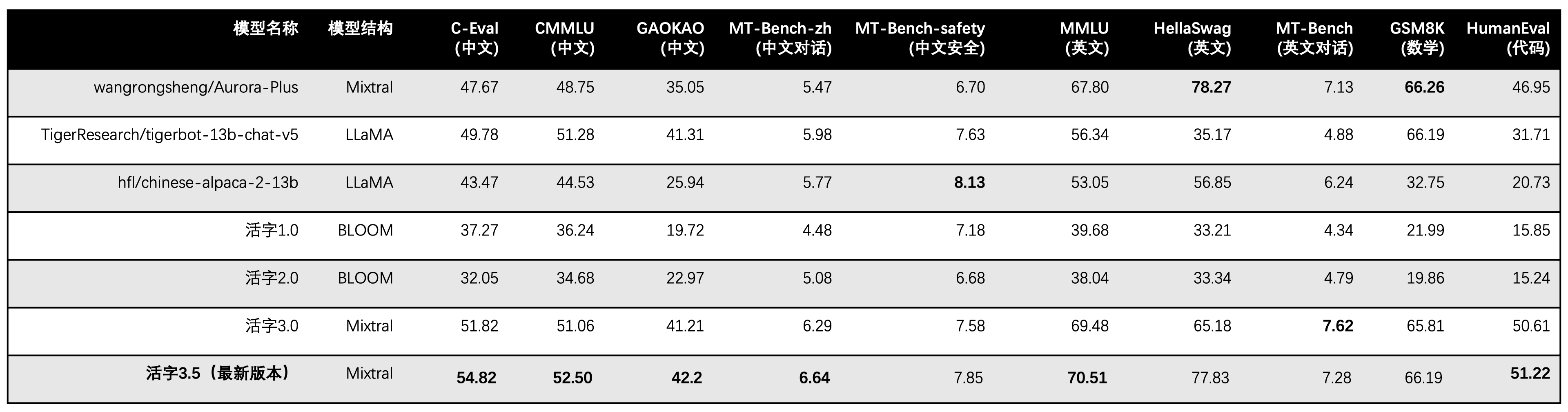
Wir verwenden 5-shot in C-Eval, CMMLU und MMLU, GSM8K verwendet 4-Shot-, Hellaswag- und Humaneval-Verwendung 0-Shot, und Humaneval verwendet Pass@1-Indikator. Alle Tests waren gierige Strategie.
Wir verwenden OpenCompass als Bewertungsrahmen und der Commit Hash ist 4C87E77. Der Überprüfungscode befindet sich hier.
Bei der Leistungsbewertung des beweglichen Typs 3.0 haben wir die Basismodellbewertungsmethode in Humaneval falsch verwendet, und die korrekten Bewertungsergebnisse wurden in der obigen Tabelle aktualisiert.
Gemäß den Testergebnissen in der obigen Tabelle hat der bewegliche Typ 3.5 im Vergleich zu beweglichen Typ 3.0 eine relativ stabile Leistungsverbesserung erzielt, und das chinesische und englische Wissen , das mathematische Denken , die Erzeugung des Codes , die Compliance -Fähigkeit des chinesischen Unterrichts und die chinesische Inhaltssicherheit des beweglichen Typs 3.5 wurden gestärkt.
Das Folgende ist der Erzeugungseffekt des beweglichen Typs 3.5 auf den MT-Bench-ZH-Bewertungssatz:
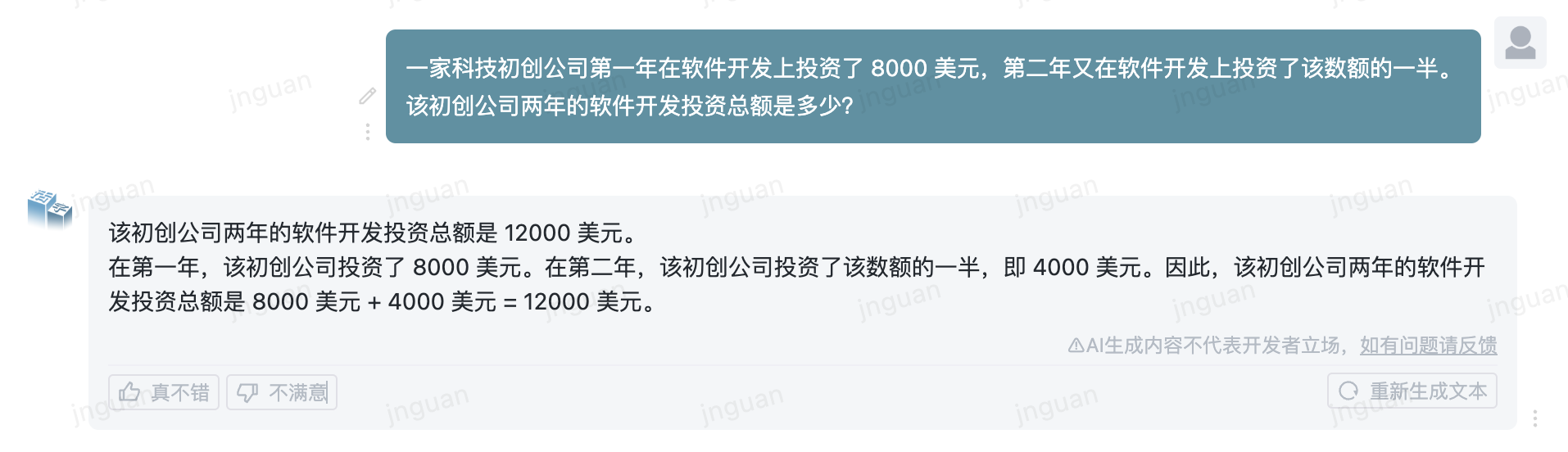



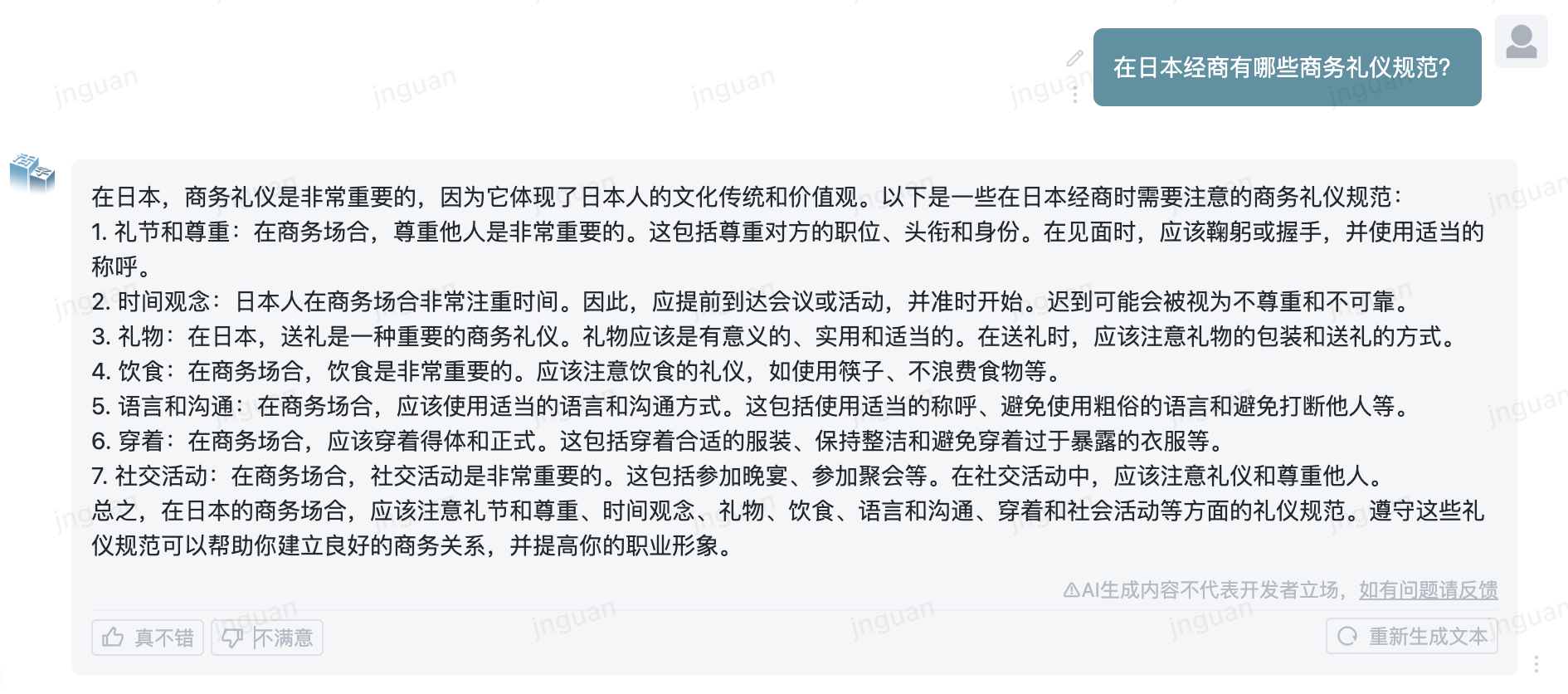
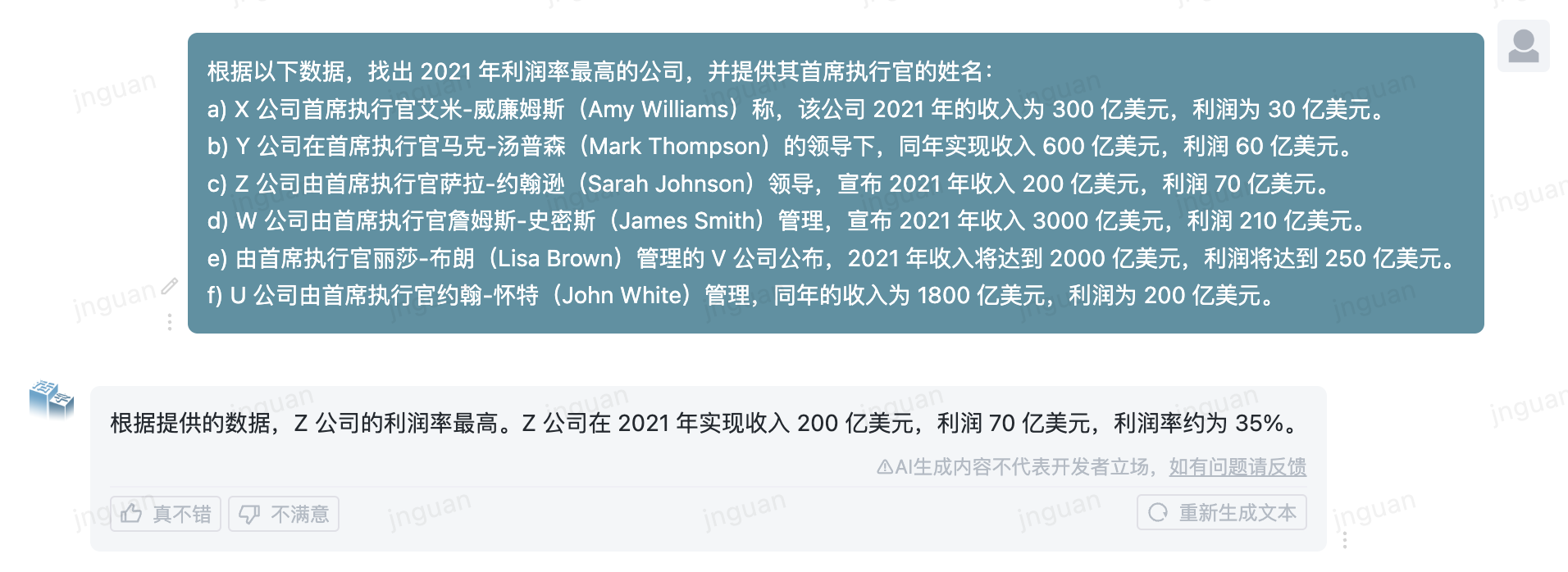
Die Verwendung dieses Repository -Quellcodes unterliegt der Open -Source -Lizenzvereinbarung Apache 2.0.
Der mobile Typ ist im Handel erhältlich. Wenn Sie das bewegliche Typmodell oder seine Derivate für kommerzielle Zwecke verwenden, wenden Sie sich wie folgt an den Lizenzgeber, um sich vom Lizenzgeber zu registrieren und eine schriftliche Genehmigung zu beantragen: Kontaktieren Sie E -Mail: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

