huozi
Release huozi 3.5
| capítulo | ilustrar |
|---|---|
| ?? ♂ Lista de código aberto | Lista de projetos de código aberto neste armazém |
| Introdução ao modelo | Breve introdução à estrutura e processo de treinamento do modelo de tipo móvel |
| ? Download do modelo | Link para download de modelo de tipo móvel |
| Raciocínio do modelo | Exemplos de inferência de modelo de tipo móvel, incluindo o processo de uso de estruturas de inferência como VLLM, llama.cpp e ollama. |
| ? Desempenho do modelo | Desempenho do modelo de tipo móvel nas tarefas de avaliação convencionais |
| ? Gerar amostra | Exemplos de efeito de geração real do modelo de tipo móvel |

O modelo de linguagem em larga escala (LLM) fez um progresso significativo no campo do processamento de linguagem natural e demonstrou seu forte potencial em uma ampla gama de cenários de aplicação. Essa tecnologia não apenas atraiu a atenção generalizada da comunidade acadêmica, mas também se tornou um tópico quente no setor. Nesse contexto, o Centro de Computação Social e a Recuperação de Informações do Harbin Institute of Technology (HIT -SCIR) lançou recentemente a última conquista - o MOVILABLE TIPO 3.5 , comprometido em fornecer mais possibilidades e opções para a pesquisa e a aplicação prática do processamento de linguagem natural.
O MOVABLE TIPO 3.5 é um modelo obtido por um aumento adicional de desempenho com base no MOVILABLE TIPO 3.0 e chinês-mixtral-8x7b. O MOVABLE TIPO 3.5 suporta 32k de contexto longo , herda as poderosas capacidades abrangentes do MOVILIVE TIPO 3.0 e alcança melhorias de desempenho em muitos aspectos, como conhecimento chinês e inglês , raciocínio matemático , geração de código , recursos de conformidade de instruções , segurança de conteúdo, etc.
Importante
O modelo de série de tipos móveis ainda pode gerar respostas enganosas contendo erros factuais ou conteúdo prejudicial que contém viés/discriminação. Tenha cuidado para identificar e usar o conteúdo gerado e não espalhe o conteúdo prejudicial gerado para a Internet.
Consulte a documentação para o MOVILABLE TIPO 1.0 e o MOVILLE TIPO 2.0 AQUI. Por favor, veja aqui a documentação sobre o MOVILABLE TIPO 3.0 e o chinês MT-banch.
O MOVABLE TIPO 3.5 é um modelo de especialista híbrido esparso (SMOE), cada camada de especialista contém 8 FFNs, e cada cálculo direto é escassamente ativado pelo Top-2. O Tipo MOVABLE 3.5 possui um total de 46,7b parâmetros. Graças às suas características de ativação escassa, apenas os parâmetros 13B precisam ser ativados durante o raciocínio real, o que melhora efetivamente a eficiência da computação e a velocidade de processamento.
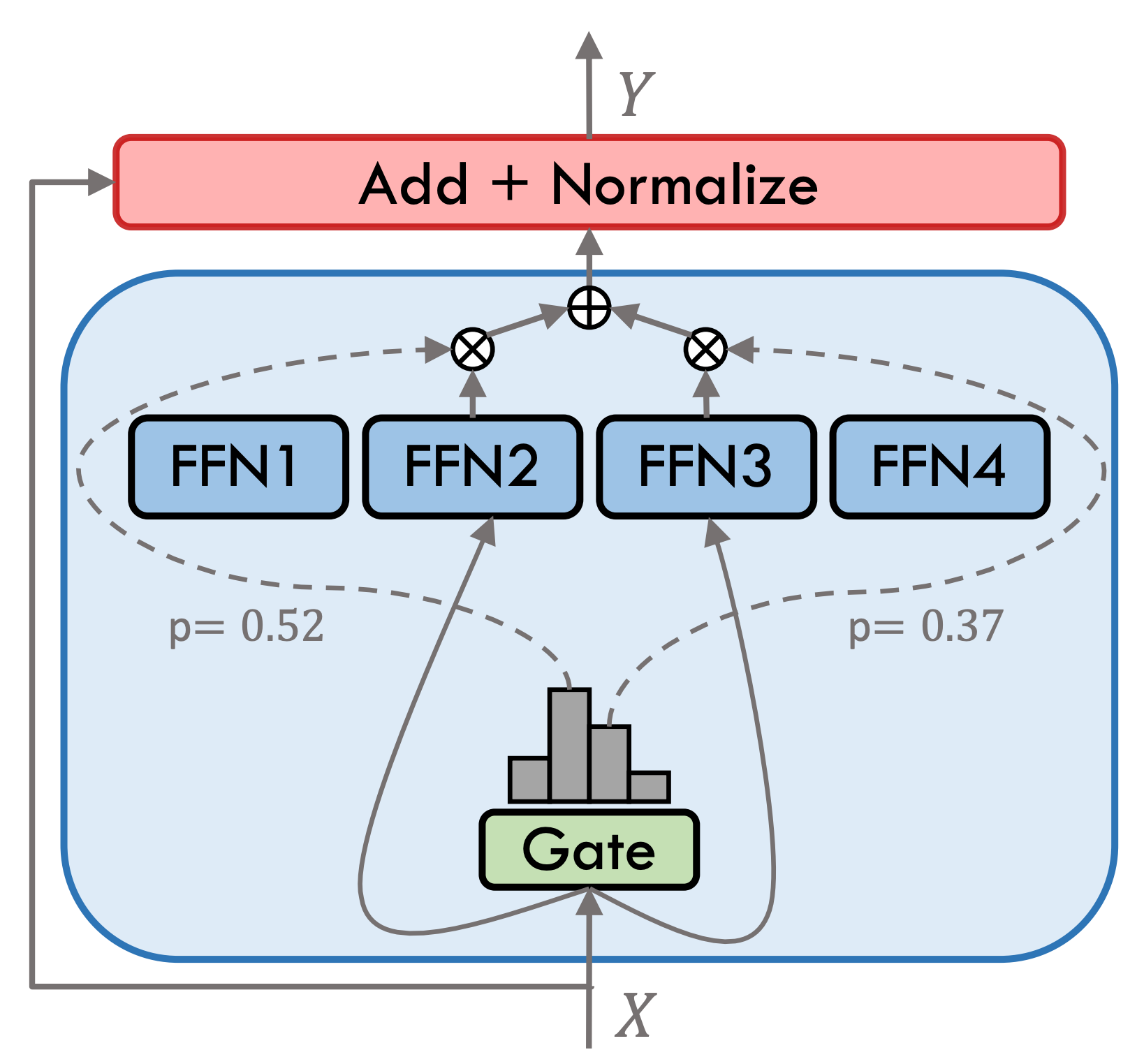
O MOVILABLE TIPO 3.5 passou por várias etapas de treinamento, conforme mostrado na figura abaixo:
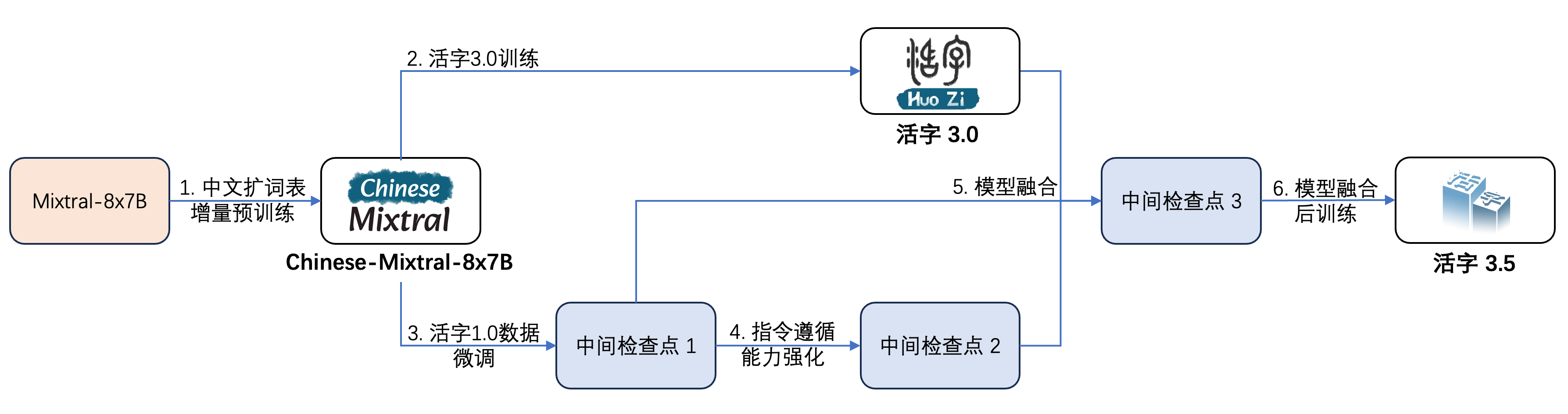
O processo de treinamento é:
| Nome do modelo | Tamanho do arquivo | Endereço para download | Observação |
|---|---|---|---|
| Huozi3.5 | 88 GB | ? Huggingface Modelscope | Modelo Movável Tipo 3.5 Completo |
| huozi3.5-ckpt-1 | 88 GB | ? Huggingface Modelscope | Tipo móvel 3.5 Ponto de verificação intermediário 1 |
| HUOZI3.5-CKPT-2 | 88 GB | ? Huggingface Modelscope | Ponto de verificação intermediário do tipo móvel 3.5 |
| HUOZI3.5-CKPT-3 | 88 GB | ? Huggingface Modelscope | Tipo móvel 3.5 Ponto de verificação intermediário 3 |
Se você deseja ajustar o MOVILE TIPO 3.5 ou o chinês-mixtral-8x7b, consulte o código de treinamento aqui.
O MOVILABLE TIPO 3.5 usa o modelo de propt de formato chatml, o formato é:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
O código de exemplo para raciocínio usando o MOVILABLE TIPO 3.5 é o seguinte:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))O MOVABLE TIPO 3.5 suporta todos os ecossistemas de modelo mixtral, incluindo Transformers, VLLM, LLAMA.CPP, Ollama, UI da Web de geração de texto e outras estruturas.
Se você tiver problemas de rede ao baixar seu modelo, poderá usar os pontos de verificação que fornecemos no ModelsCope.
Os transformadores suportam a adição de modelos de bate -papo para o tokenizer e suporta geração de streaming. O código de amostra é o seguinte:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)A interface do ModelsCope é muito semelhante aos transformadores, basta substituir os transformadores pelo escopo do modelo:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Variável Tipo 3.5 suporta a implementação da aceleração de inferência através da VLLM, e o código de amostra é o seguinte:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )A variedade Tipo 3.5 pode ser implantada como um serviço que suporta o protocolo da API OpenAI, que permite que a variedade Tipo 3.5 seja chamada diretamente através da API OpenAI.
Preparação ambiental:
$ pip install vllm openaiInicie o serviço:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Envie solicitações usando API OpenAI:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Aqui está um código de amostra que usa o OpenAI API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()O formato GGUF foi projetado para carregar e salvar rapidamente modelos. Ele é lançado pela equipe LLAMA.CPP e é adequado para estruturas como llama.cpp, ollama, etc. Você pode converter manualmente o MOVILIVE TIPO 3.5 no formato Huggingface em formato GGUF.
Primeiro, você precisa baixar o código -fonte do llama.cpp. Fornecemos o submódulo de llama.cpp no repositório. Esta versão do llama.cpp foi testada e pode inferir com sucesso:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppVocê também pode baixar a versão mais recente do código -fonte llama.cpp:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppEntão ele precisa ser compilado. Existem diferenças sutis nos comandos de compilação, dependendo da sua plataforma de hardware:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 O comando a seguir precisa estar no llama.cpp/ diretório:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 O comando a seguir precisa estar no llama.cpp/ diretório:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " O parâmetro -ngl indica o número de camadas de descarga na GPU. Reduzir esse valor pode aliviar a pressão da memória de vídeo da GPU. Após nosso teste real, o modelo Q2_K quantizado tem uma descarga de 16 camadas, e o uso da memória pode ser reduzido para 9,6 GB, que pode executar o modelo nas GPUs de consumo:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " Para mais parâmetros do main , você pode consultar a documentação oficial do llama.cpp.
Use a estrutura Ollama para raciocínio, você pode consultar as instruções de leitura de Ollama.
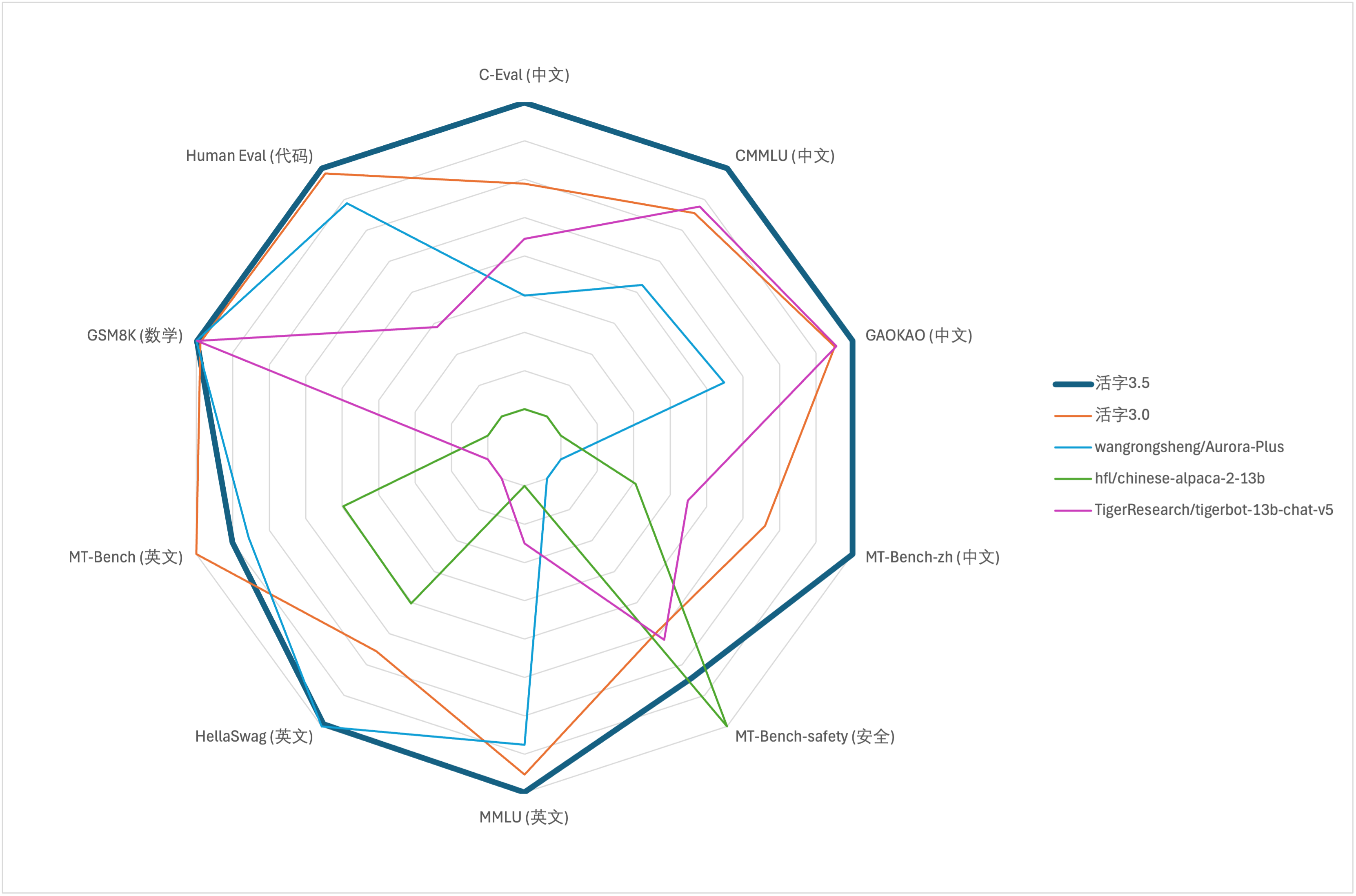
Para a avaliação abrangente da capacidade de grandes modelos, usamos o seguinte conjunto de dados de avaliação para avaliar o Tipo MOVILENTE 3.5, respectivamente:
O MOVILLE TIPO 3.5 ativa apenas os parâmetros 13B quando a inferência. A tabela a seguir mostra os resultados dos modelos chineses do tipo móvel 3.5 e outras escalas 13B e a versão antiga do tipo móvel em cada conjunto de dados de avaliação:
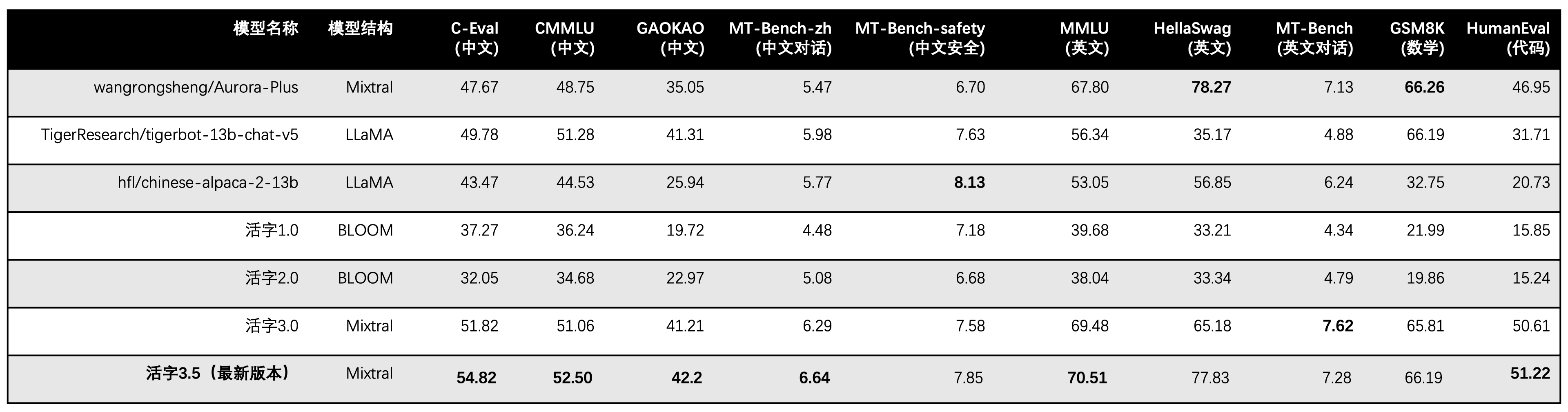
Utilizamos 5 tiros no C-EVAL, CMMLU e MMLU, o GSM8K usa 4 tiros, Hellaswag e Humaneval Use 0-Shot, e o Humaneval usa PASS@1 Indicator. Todos os testes eram estratégia gananciosa.
Utilizamos o OpenCompass como estrutura de avaliação e o hash de comprometimento é 4C87E77. O código de revisão está localizado aqui.
Na avaliação de desempenho do Tipo Motorável 3.0, usamos o método de avaliação do modelo básico no Humaneval incorretamente e os resultados corretos da avaliação foram atualizados na tabela acima.
De acordo com os resultados do teste na tabela acima, o MOVABLE TIPO 3.5 alcançou uma melhoria de desempenho relativamente estável em comparação com o Tipo MOVILIVADO 3.0, e o conhecimento chinês e inglês , raciocínio matemático , geração de código , capacidade de conformidade com instruções chinesas e segurança de conteúdo chinês do tipo móvel do tipo 3.5 foram fortalecidas.
A seguir, é apresentado o efeito de geração do tipo móvel 3.5 no conjunto de avaliação MT-Bench-ZH:
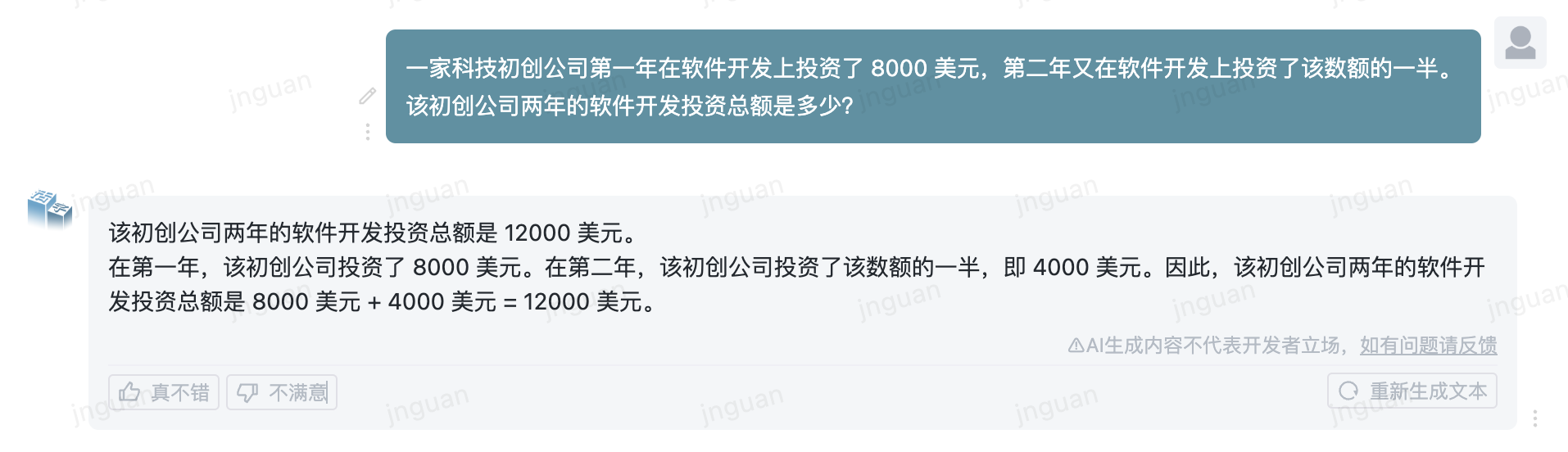



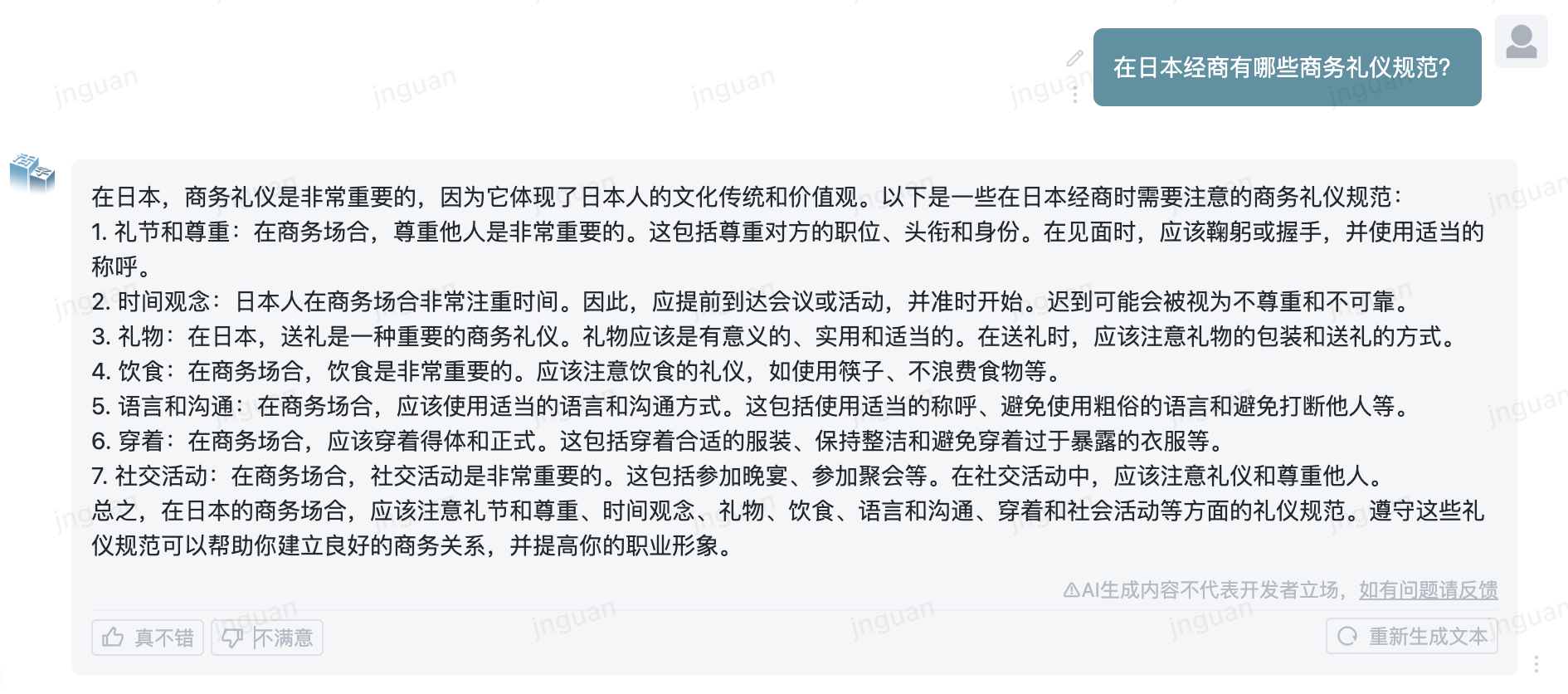
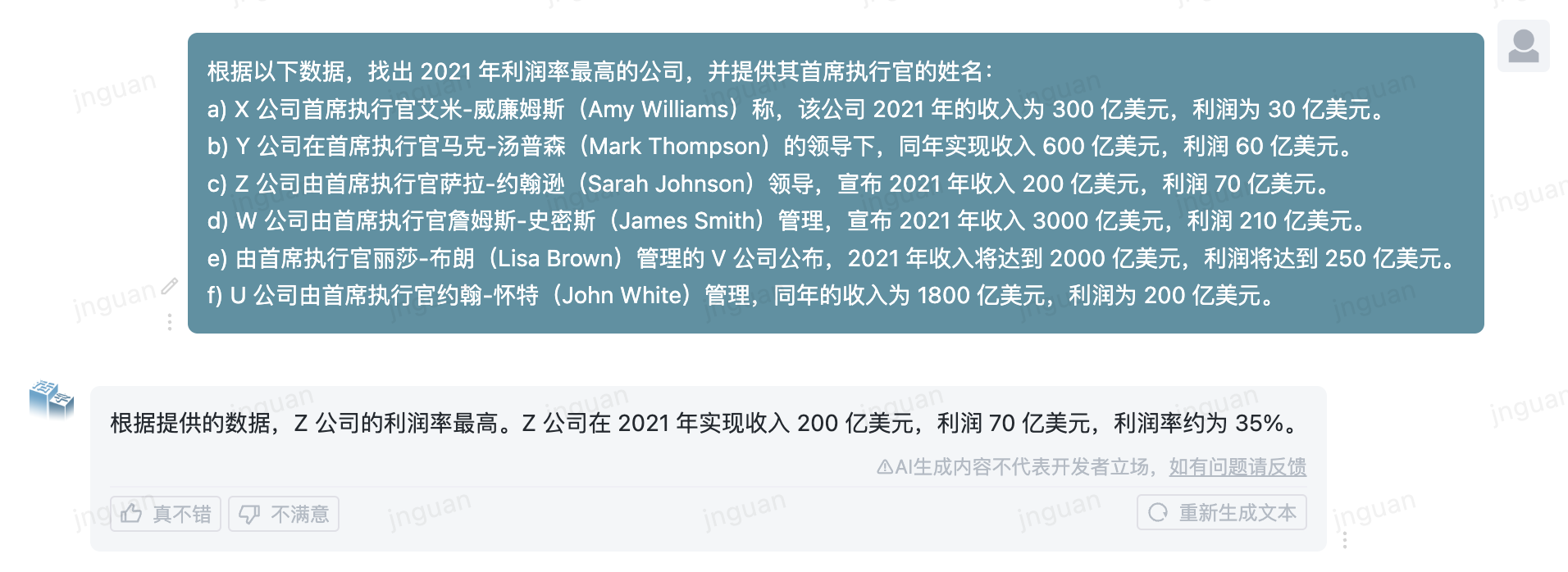
O uso desse código -fonte do repositório está sujeito ao contrato de licença de código aberto Apache 2.0.
O tipo móvel está disponível comercialmente. Se você usar o modelo de tipo móvel ou seus derivados para fins comerciais, entre em contato com o licenciante da seguinte forma para se registrar e solicitar a autorização por escrito do licenciante: Entre em contato com o e -mail: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

