huozi
Release huozi 3.5
| الفصل | يوضح |
|---|---|
| ؟ open Open Source List | قائمة مشاريع المصادر المفتوحة في هذا المستودع |
| مقدمة نموذج | مقدمة موجزة للهيكل وعملية التدريب لنموذج النوع المنقول |
| ؟ تنزيل النموذج | رابط تنزيل نموذج النوع المنقول |
| التفكير النموذج | أمثلة على استنتاج نموذج النوع المنقاذ ، بما في ذلك عملية استخدام أطر الاستدلال مثل VLLM و Llama.cpp و Ollama. |
| ؟ أداء النموذج | أداء نموذج النوع المنقول على مهام التقييم السائدة |
| ؟ توليد عينة | أمثلة على تأثير التوليد الفعلي لنموذج النوع المنقول |

أحرز نموذج اللغة على نطاق واسع (LLM) تقدمًا كبيرًا في مجال معالجة اللغة الطبيعية وأظهر إمكاناته القوية في مجموعة واسعة من سيناريوهات التطبيق. لم تجتذب هذه التكنولوجيا اهتمامًا واسع النطاق من المجتمع الأكاديمي ، ولكنها أصبحت أيضًا موضوعًا ساخنًا في هذه الصناعة. في مقابل هذه الخلفية ، أطلق مركز الحوسبة الاجتماعية واسترجاع المعلومات لمعهد هاربين للتكنولوجيا (HIT -SCIR) مؤخرًا أحدث إنجاز - من النوع 3.5 المنقول ، ملتزمًا بتوفير المزيد من الاحتمالات والخيارات للبحث والتطبيق العملي لمعالجة اللغة الطبيعية.
النوع Movable Type 3.5 هو نموذج تم الحصول عليه عن طريق مزيد من تحسين الأداء استنادًا إلى النوع 3.0 المنقول و Mixtral-8x7B الصيني. يدعم النوع 3.5 المنقذ سياقًا طويلًا 32 ألفًا ، ويرث القدرات الشاملة القوية للنوع 3.0 المنقولة ، ويحقق تحسينات في الأداء في العديد من الجوانب مثل المعرفة الصينية والإنجليزية ، والمنطق الرياضي ، وتوليد الكود ، وقدرات الامتثال للتعليم ، وأمن المحتوى ، وما إلى ذلك.
مهم
قد لا يزال نموذج سلسلة Type Movable يولد ردود مضللة تحتوي على أخطاء واقعية أو محتوى ضار يحتوي على التحيز/التمييز. يرجى توخي الحذر من تحديد المحتوى الذي تم إنشاؤه واستخدامه وعدم نشر المحتوى الضار الذي تم إنشاؤه على الإنترنت.
يرجى الاطلاع على الوثائق الخاصة بالنوع 1.0 المنقولة والنوع 2.0 المنقول هنا. يرجى الاطلاع هنا للحصول على الوثائق على نوع Movable Type 3.0 و MT-BECK الصيني.
Sovable Type 3.5 هو نموذج خبير مختلط متفرق (SMOE) ، تحتوي كل طبقة خبراء على 8 FFNs ، ويتم تنشيط كل حساب أمامي بشكل قاطع بواسطة أعلى 2. يحتوي النوع 3.5 المنقح على ما مجموعه 46.7B. بفضل خصائص التنشيط المتفرقة ، يجب تنشيط المعلمة 13B فقط أثناء التفكير الفعلي ، مما يحسن فعليًا من كفاءة الحوسبة وسرعة المعالجة.
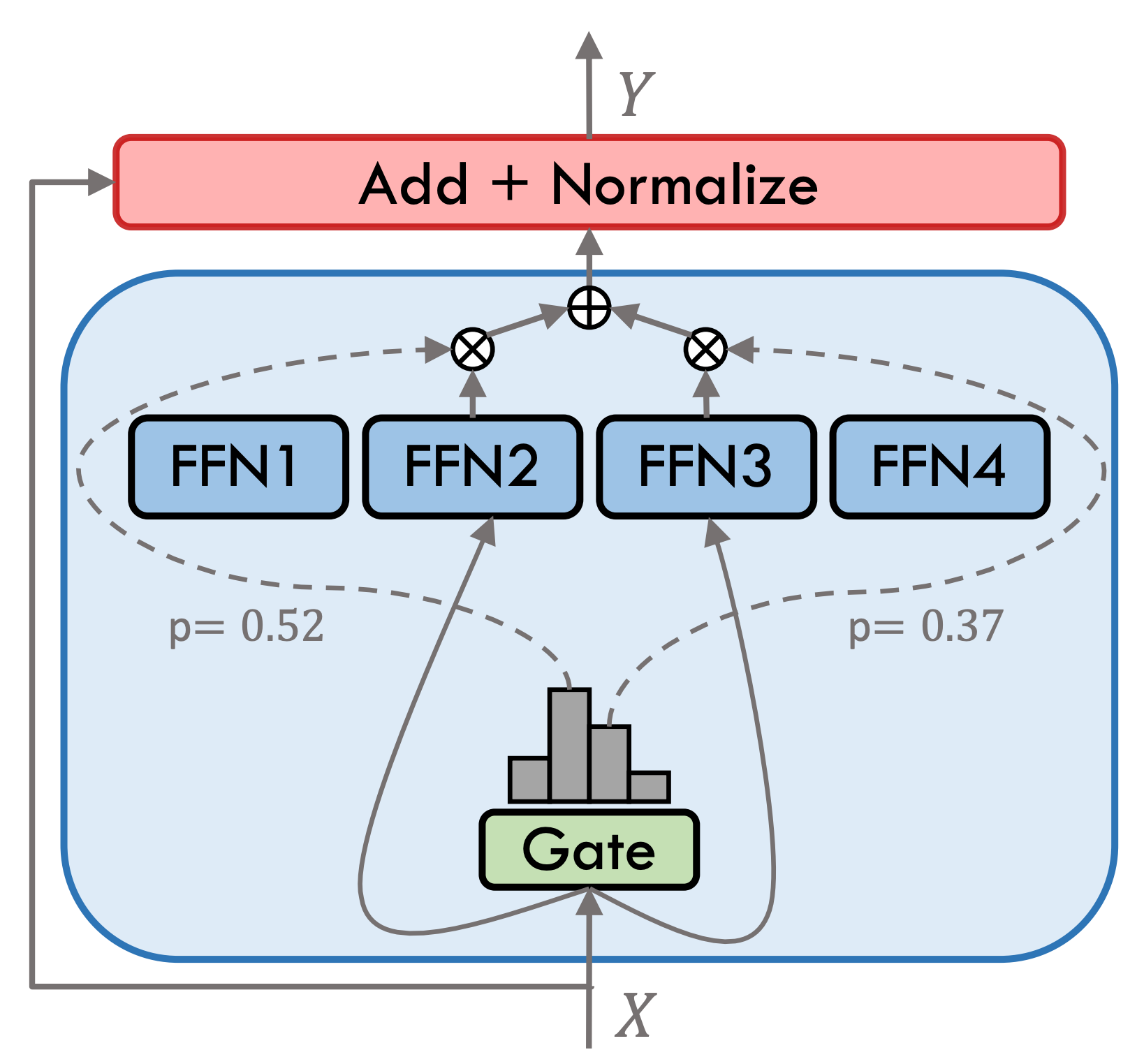
خضع النوع 3.5 المنقح خطوات متعددة للتدريب ، كما هو موضح في الشكل أدناه:
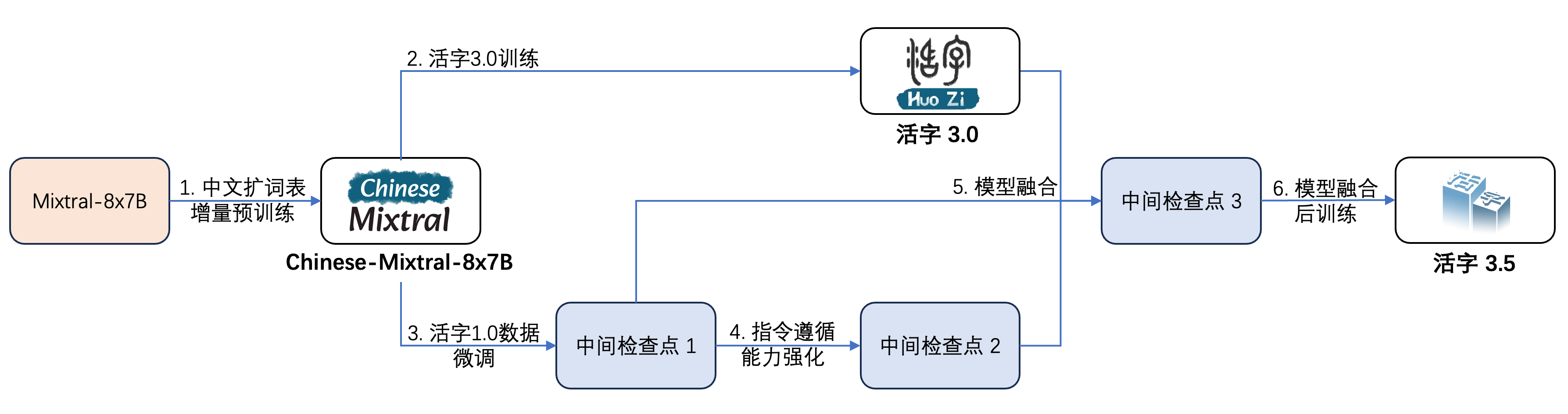
عملية التدريب هي:
| اسم النموذج | حجم الملف | تنزيل عنوان | ملاحظة |
|---|---|---|---|
| Huozi3.5 | 88 جيجابايت | ؟ Huggingface موديلات | النموذج الكامل من النوع 3.5 |
| Huozi3.5-Ckpt-1 | 88 جيجابايت | ؟ Huggingface موديلات | النوع المنقول 3.5 نقطة تفتيش وسيطة 1 |
| Huozi3.5-Ckpt-2 | 88 جيجابايت | ؟ Huggingface موديلات | النوع المنقول 3.5 نقطة تفتيش وسيطة 2 |
| Huozi3.5-Ckpt-3 | 88 جيجابايت | ؟ Huggingface موديلات | النوع المنقول 3.5 نقطة تفتيش وسيطة 3 |
إذا كنت ترغب في ضبط النوع 3.5 أو الصيني-mixtral-8x7b ، فيرجى الرجوع إلى رمز التدريب هنا.
يستخدم Type Type 3.5 Movable Type the Chatml تنسيق proft ، والتنسيق هو:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
رمز المثال للتفكير باستخدام Type Type 3.5 هو كما يلي:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))يدعم Movable Type 3.5 جميع النظم الإيكولوجية النموذجية لـ Mixtral ، بما في ذلك المحولات ، VLLM ، Llama.cpp ، Ollama ، واجهة المستخدم على شبكة الإنترنت من توليد النص والأطر الأخرى.
إذا كانت لديك مشكلات في الشبكة أثناء تنزيل النموذج الخاص بك ، فيمكنك استخدام نقاط التفتيش التي نقدمها على ModelsCope.
تدعم المحولات إضافة قوالب الدردشة لـ Tokenizer ويدعم توليد البث. رمز العينة كما يلي:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)تشبه واجهة ModelsCope إلى حد كبير المحولات ، فقط استبدل المحولات بنطاق النموذج:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))يدعم النوع 3.5 المتغير تنفيذ تسريع الاستدلال من خلال VLLM ، ويكون رمز العينة كما يلي:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )يمكن نشر نوع الصنف 3.5 كخدمة تدعم بروتوكول Openai API ، والذي يتيح استدعاء نوع الصنف 3.5 مباشرة من خلال API Openai.
الإعداد البيئي:
$ pip install vllm openaiابدأ الخدمة:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048إرسال الطلبات باستخدام Openai API:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )فيما يلي رمز عينة يستخدم Openai API + Gradio + Streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()تم تصميم تنسيق GGUF لتحميل وتوفير النماذج بسرعة. يتم إطلاقه بواسطة فريق Llama.cpp وهو مناسب للأطر مثل llama.cpp ، Ollama ، إلخ
أولاً ، تحتاج إلى تنزيل الكود المصدري لـ llama.cpp. نحن نقدم الجهاز الفرعي من llama.cpp في المستودع. تم اختبار هذا الإصدار من llama.cpp ويمكن أن يستنتج بنجاح:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppيمكنك أيضًا تنزيل أحدث إصدار من رمز المصدر llama.cpp:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppثم يجب تجميعها. هناك اختلافات دقيقة في أوامر التجميع اعتمادًا على منصة الأجهزة الخاصة بك:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 يجب أن يكون الأمر التالي في llama.cpp/ directory:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 يجب أن يكون الأمر التالي في llama.cpp/ directory:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " تشير المعلمة -ngl إلى عدد طبقات التفريغ إلى وحدة معالجة الرسومات. يمكن أن يؤدي تقليل هذه القيمة إلى تخفيف ضغط ذاكرة فيديو GPU. بعد اختبارنا الفعلي ، يحتوي النموذج الكمي Q2_K على تفريغ من 16 طبقة ، ويمكن تقليل استخدام الذاكرة إلى 9.6 جيجابايت ، والتي يمكنها تشغيل النموذج على وحدات معالجة الرسومات المستهلك:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " لمزيد من المعلمات main ، يمكنك الرجوع إلى الوثائق الرسمية لـ llama.cpp.
استخدم إطار عمل Ollama للتفكير ، يمكنك الرجوع إلى تعليمات ReadMe من Ollama.
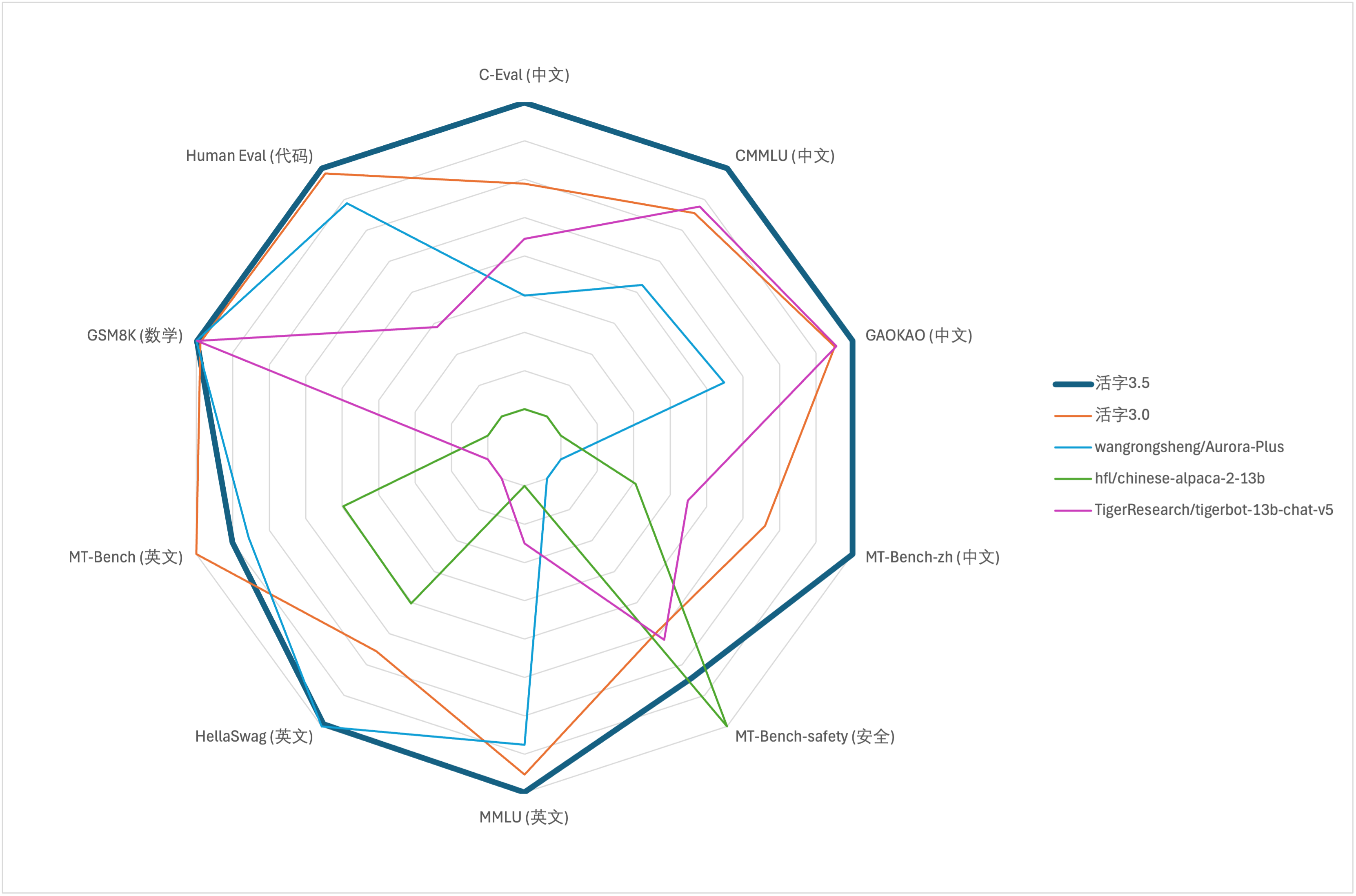
لتقييم القدرة الشاملة للنماذج الكبيرة ، استخدمنا مجموعة بيانات التقييم التالية لتقييم النوع 3.5 المنقص على التوالي:
ينشط النوع 3.5 المتحرك فقط 13B المعلمات عند الاستدلال. يوضح الجدول التالي نتائج النماذج الصينية من النوع 3.5 المتحرك ومقاييس 13B الأخرى والإصدار القديم من النوع المتحرك في كل مجموعة بيانات تقييم:
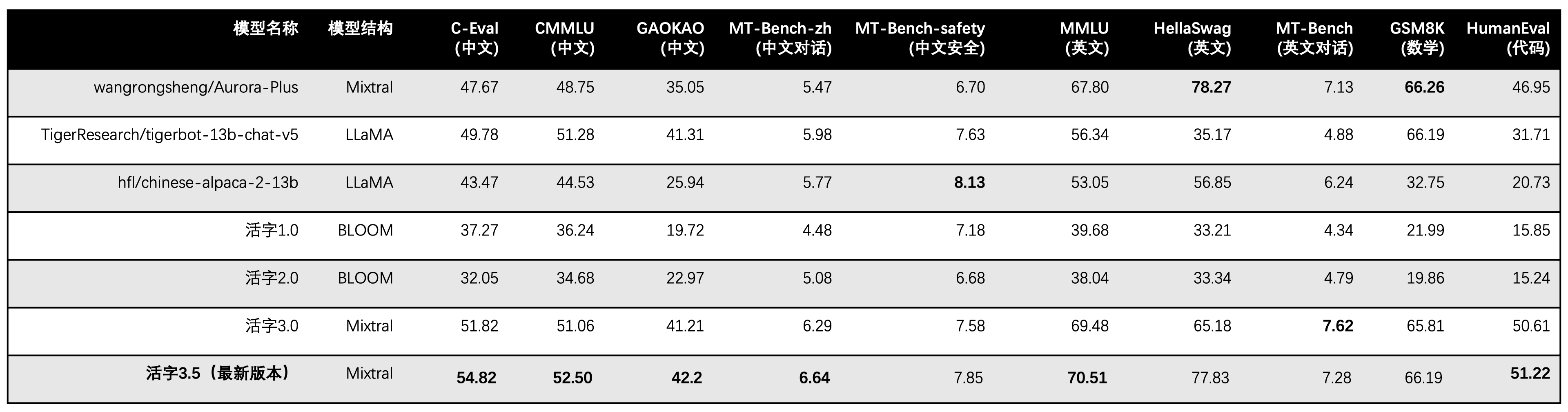
نحن نستخدم 5 طلقات في C-Eval و Cmmlu و MMLU ، ويستخدم GSM8K 4 طلقات ، Hellaswag و Humaneval استخدام 0 طلقة ، ويستخدم Humaneval مؤشر تمرير@1. وكانت جميع الاختبارات استراتيجية الجشع.
نحن نستخدم OpenCompass كإطار التقييم وتجزئة الالتزام هو 4C87E77. يقع رمز المراجعة هنا.
في تقييم الأداء للنوع 3.0 المنقول ، استخدمنا طريقة تقييم النموذج الأساسي في Humaneval بشكل غير صحيح ، وتم تحديث نتائج التقييم الصحيحة في الجدول أعلاه.
وفقًا لنتائج الاختبار في الجدول أعلاه ، حقق النوع 3.5 متحرك تحسنًا مستقرًا نسبيًا في الأداء مقارنة بالنوع 3.0 المنقولة ، وتم تعزيز المعرفة الصينية والإنجليزية ، والتفكير الرياضي ، وتوليد الكود ، وقدرة الامتثال للتعليمات الصينية ، وأمن المحتوى الصيني من النوع 3.5 المنقول.
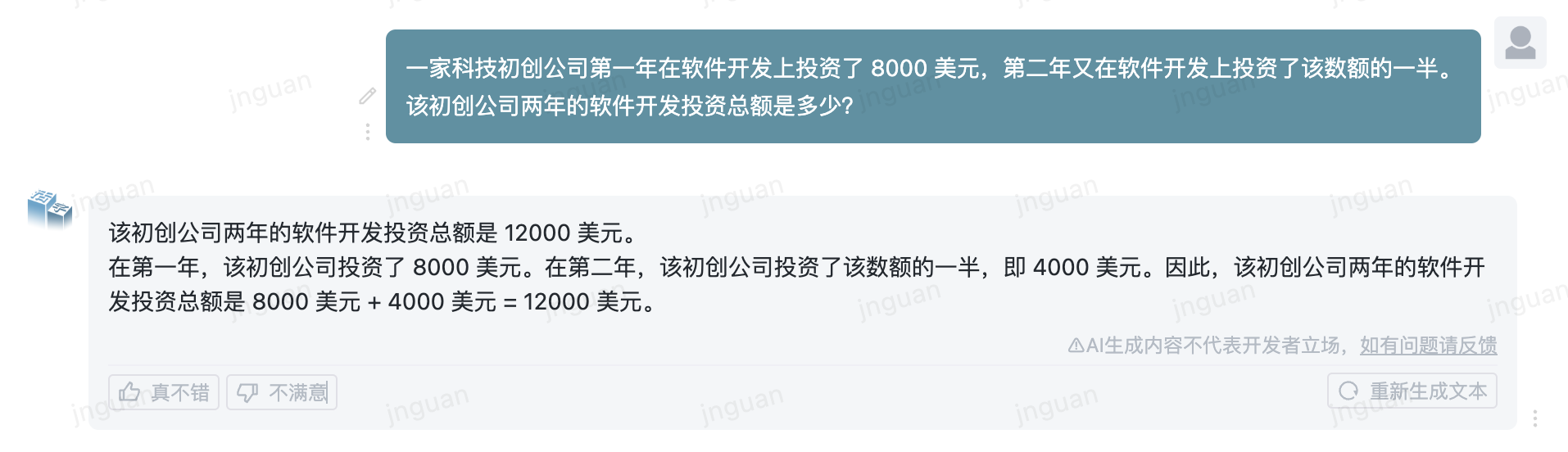
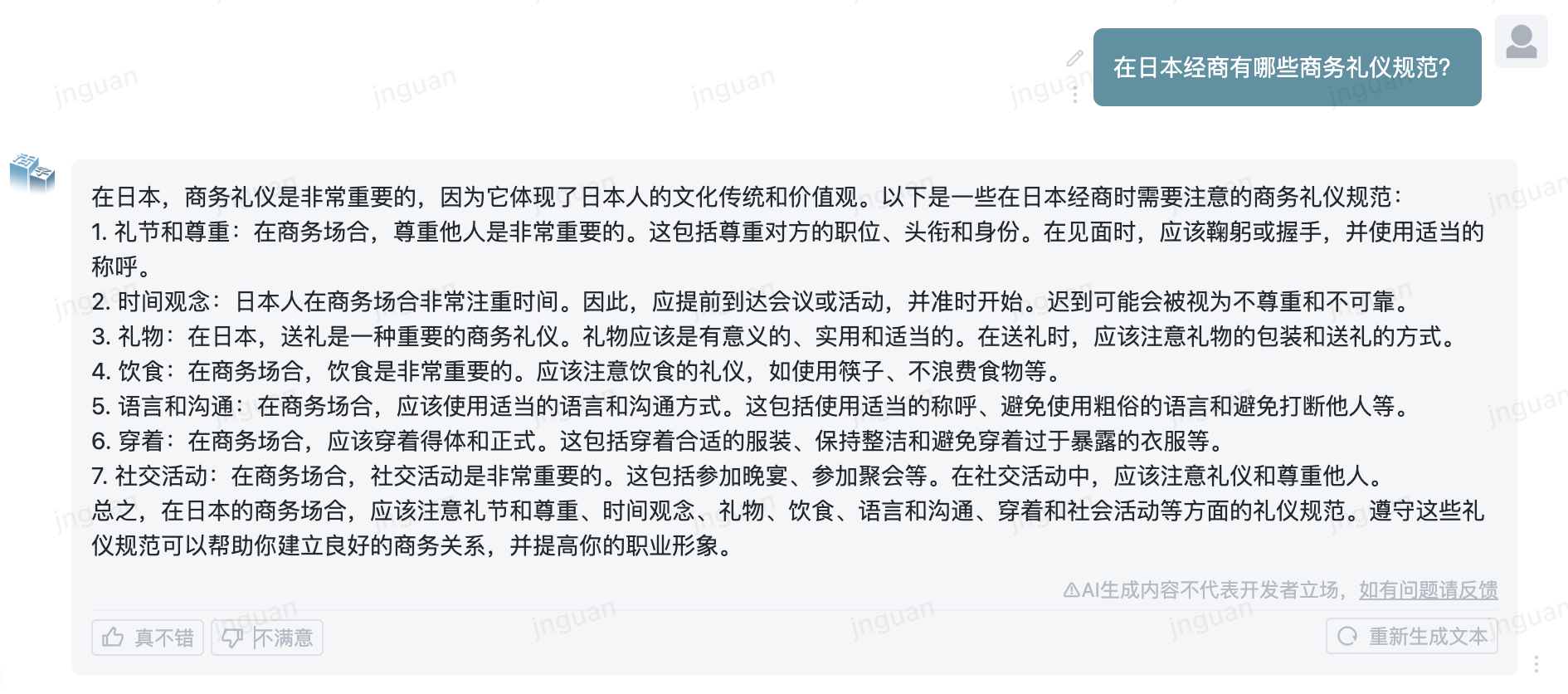
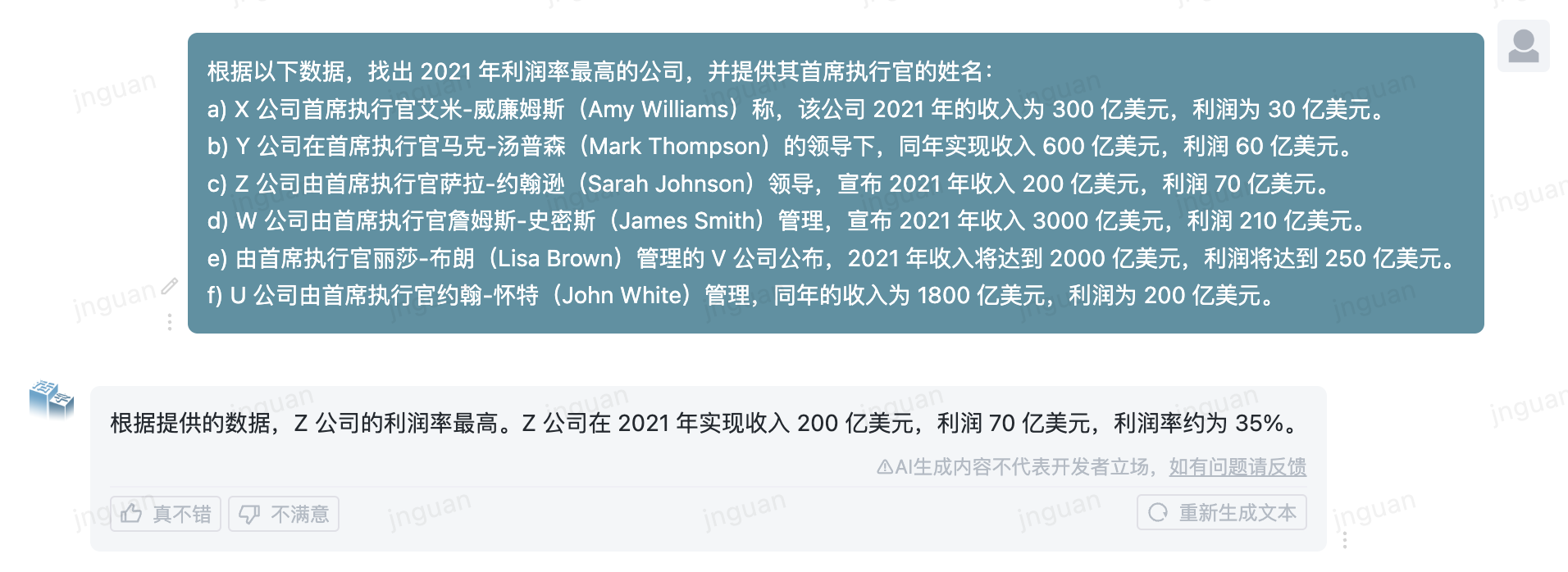
فيما يلي تأثير توليد النوع 3.5 المنقول على مجموعة تقييم MT-bench-ZH:



يخضع استخدام رمز مصدر المستودع هذا لاتفاقية ترخيص المصدر المفتوح Apache 2.0.
نوع الهاتف المحمول متاح تجاريا. إذا كنت تستخدم نموذج النوع المتحرك أو مشتقاته لأغراض تجارية ، فيرجى الاتصال بالمرخص على النحو التالي للتسجيل والتقدم للحصول على إذن كتابي من المرخص: الاتصال بالبريد الإلكتروني: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

