huozi
Release huozi 3.5
| 章 | 説明します |
|---|---|
| オープンソースリスト | この倉庫のオープンソースプロジェクトのリスト |
| モデルの紹介 | 可動型モデルの構造とトレーニングプロセスの簡単な紹介 |
| ?モデルダウンロード | 可動型モデルダウンロードリンク |
| モデルの推論 | VLLM、llama.cpp、Ollamaなどの推論フレームワークの使用プロセスを含む、可動型モデル推論の例。 |
| ?モデルのパフォーマンス | 主流の評価タスクでの可動型モデルのパフォーマンス |
| ?サンプルを生成します | 可動型モデルの実際の生成効果の例 |

大規模な言語モデル(LLM)は、自然言語処理の分野で大きな進歩を遂げ、幅広いアプリケーションシナリオでその強い可能性を実証しています。このテクノロジーは、学術コミュニティからの広範な注目を集めただけでなく、業界のホットトピックにもなりました。このバックグラウンドに対して、ハルビン工科大学(HIT -SCIR)のソーシャルコンピューティングおよび情報検索センターは最近、最新の成果であるMovable Type 3.5を開始しました。
Movable Type 3.5は、可動型3.0および中国Mixtral-8x7bに基づいたさらなる性能向上によって得られるモデルです。 Movable Type 3.5は、 32Kの長さのコンテキストをサポートし、可動型3.0の強力な包括的な機能を継承し、中国および英語の知識、数学的推論、コード生成、命令コンプライアンス機能、コンテンツセキュリティなど、多くの側面でパフォーマンスの改善を達成します。
重要
可動型シリーズモデルは、事実上のエラーまたはバイアス/差別を含む有害なコンテンツを含む誤解を招く返信を生成する可能性があります。生成されたコンテンツを特定して使用するように注意してください。生成された有害なコンテンツをインターネットに広めないでください。
ここで、可動型1.0および可動型タイプ2.0のドキュメントをご覧ください。 Movable Type 3.0と中国MTベンチのドキュメントについては、こちらをご覧ください。
可動型3.5はスパースハイブリッドエキスパートモデル(SMOE)であり、各エキスパート層には8つのFFNが含まれ、各フォワード計算はTOP-2でまばらに活性化されます。可動型3.5には、合計46.7bパラメーターがあります。スパースアクティベーション特性のおかげで、実際の推論中にアクティブ化する必要があるのは13Bパラメーターのみであり、コンピューティング効率と処理速度を効果的に改善します。
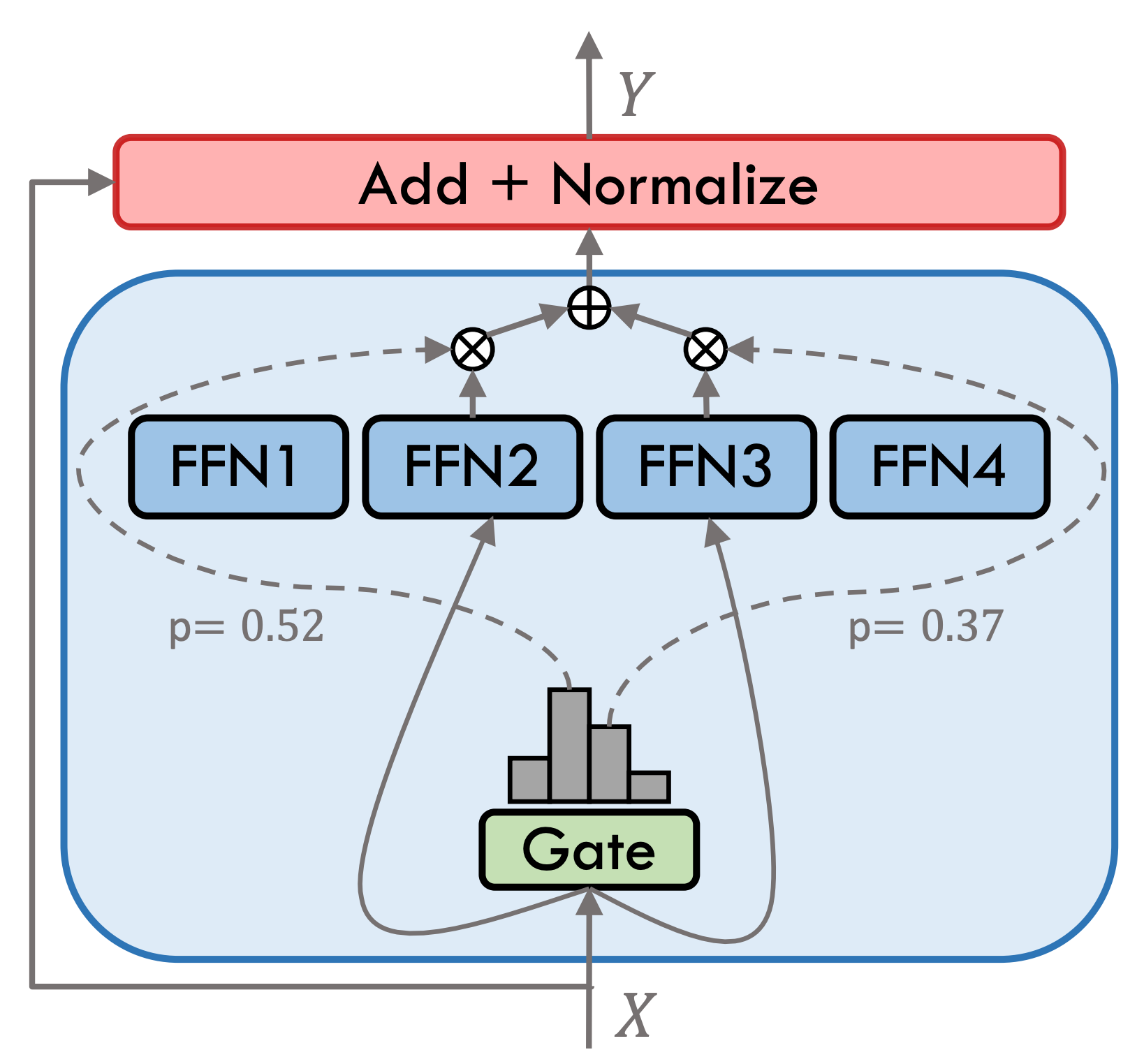
下の図に示すように、可動型3.5は複数のトレーニングを受けています。
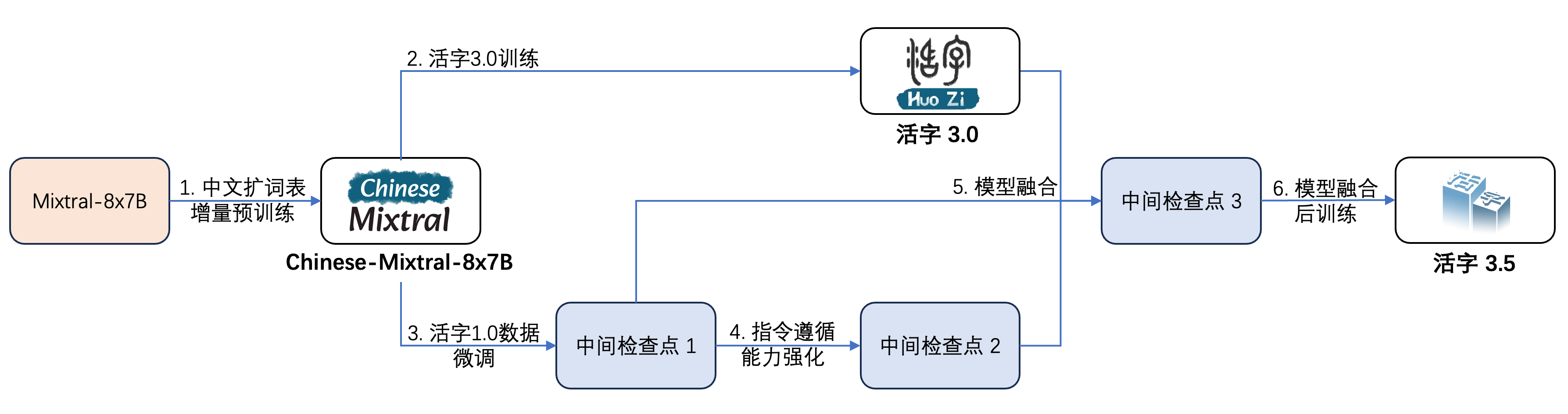
トレーニングプロセスは次のとおりです。
| モデル名 | ファイルサイズ | アドレスをダウンロードしてください | 述べる |
|---|---|---|---|
| huozi3.5 | 88GB | ?Huggingface ModelScope | 可動型3.5完全なモデル |
| huozi3.5-ckpt-1 | 88GB | ?Huggingface ModelScope | 可動型3.5中間チェックポイント1 |
| huozi3.5-ckpt-2 | 88GB | ?Huggingface ModelScope | 可動型3.5中間チェックポイント2 |
| huozi3.5-ckpt-3 | 88GB | ?Huggingface ModelScope | 可動型3.5中間チェックポイント3 |
Movable Type 3.5または中国のMixtral-8x7Bを微調整する場合は、こちらのトレーニングコードを参照してください。
Movable Type 3.5は、chatML形式のproptテンプレートを使用します。形式は次のとおりです。
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
可動型3.5を使用して推論するための例コードは次のとおりです。
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5は、変圧器、VLLM、LLAMA.CPP、Ollama、Text Generation Web UI、その他のフレームワークなど、すべてのMixTralモデルエコシステムをサポートしています。
モデルのダウンロード中にネットワークの問題がある場合は、ModelScopeで提供するチェックポイントを使用できます。
トランスフォーマーは、トークン剤のチャットテンプレートの追加をサポートし、ストリーミング生成をサポートします。サンプルコードは次のとおりです。
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)ModelScopeのインターフェイスは変圧器に非常に似ており、変圧器をモデルスコープに置き換えるだけです。
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))変数タイプ3.5は、VLLMを介した推論加速度の実装をサポートし、サンプルコードは次のとおりです。
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Variety Type 3.5は、Openai APIプロトコルをサポートするサービスとして展開できます。これにより、Variety Type 3.5をOpenAI APIを介して直接呼び出すことができます。
環境準備:
$ pip install vllm openaiサービスを開始します:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Openai APIを使用してリクエストを送信します。
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Openai API + Gradio +ストリーミングを使用するサンプルコードは次のとおりです。
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()GGUF形式は、モデルをすばやくロードおよび保存するように設計されています。 llama.cppチームによって発売され、llama.cpp、ollamaなどのフレームワークに適しています。移動可能なタイプ3.5をHuggingface形式でGGUF形式に手動で変換できます。
まず、llama.cppのソースコードをダウンロードする必要があります。リポジトリにllama.cppのサブモジュールを提供します。 llama.cppのこのバージョンはテストされており、正常に推測できます。
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppllama.cppソースコードの最新バージョンをダウンロードすることもできます。
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppその後、コンパイルする必要があります。ハードウェアプラットフォームに応じて、編集コマンドに微妙な違いがあります。
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试次のコマンドはllama.cpp/ディレクトリにある必要があります。
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0次のコマンドはllama.cpp/ディレクトリにある必要があります。
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " -nglパラメーターは、GPUへのオフロードの層の数を示します。この値を減らすと、GPUビデオメモリの圧力が軽減される可能性があります。実際のテストの後、Q2_K Quantizedモデルには16層のオフロードがあり、メモリ使用量を9.6GBに減らすことができ、消費者GPUでモデルを実行できます。
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " mainのパラメーターの詳細については、llama.cppの公式ドキュメントを参照できます。
Ollama Frameworkを使用して推論するには、OllamaのReadmeの指示を参照できます。
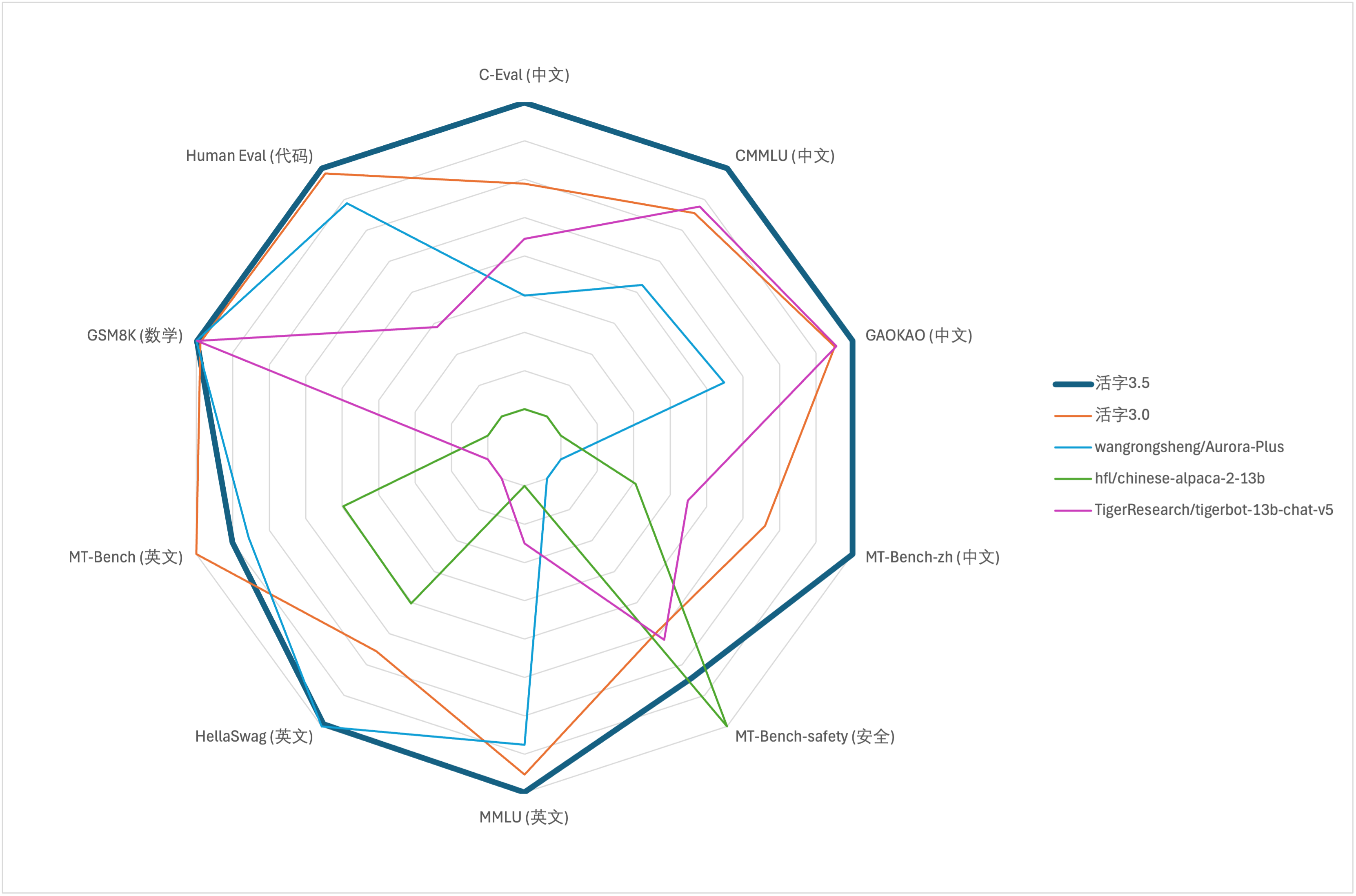
大規模モデルの包括的な能力評価には、次の評価データセットを使用して、それぞれ可動型3.5を評価します。
可動型3.5は、推論時に13Bパラメーターのみをアクティブにします。次の表は、可動型3.5およびその他の13Bスケールの中国モデルの結果と、各評価データセットの可動型の古いバージョンの結果を示しています。
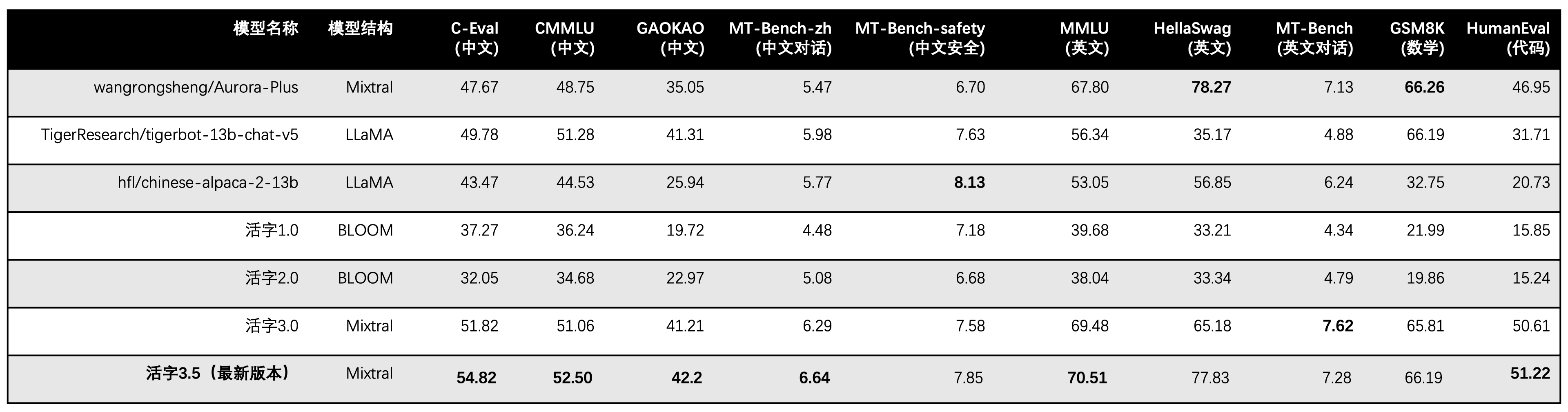
C-EVAL、CMMLU、およびMMLUで5ショットを使用して、GSM8Kは4ショット、Hellaswag、およびHumaneval使用0ショットを使用し、HumanevalはPass@1インジケーターを使用します。すべてのテストは貪欲な戦略でした。
評価フレームワークとしてOpenCompassを使用し、コミットハッシュは4C87E77です。レビューコードはここにあります。
可動型3.0のパフォーマンス評価では、Humanevalの基本モデル評価方法を誤って使用し、上記の表で正しい評価結果を更新しました。
上記の表のテスト結果によると、可動型3.5は、可動型3.0と比較して比較的安定したパフォーマンスの改善を達成しました。また、中国と英語の知識、数学的推論、コード生成、中国の指導コンプライアンス能力、および中国のコンテンツのセキュリティは、可動型3.5のセキュリティが強化されました。
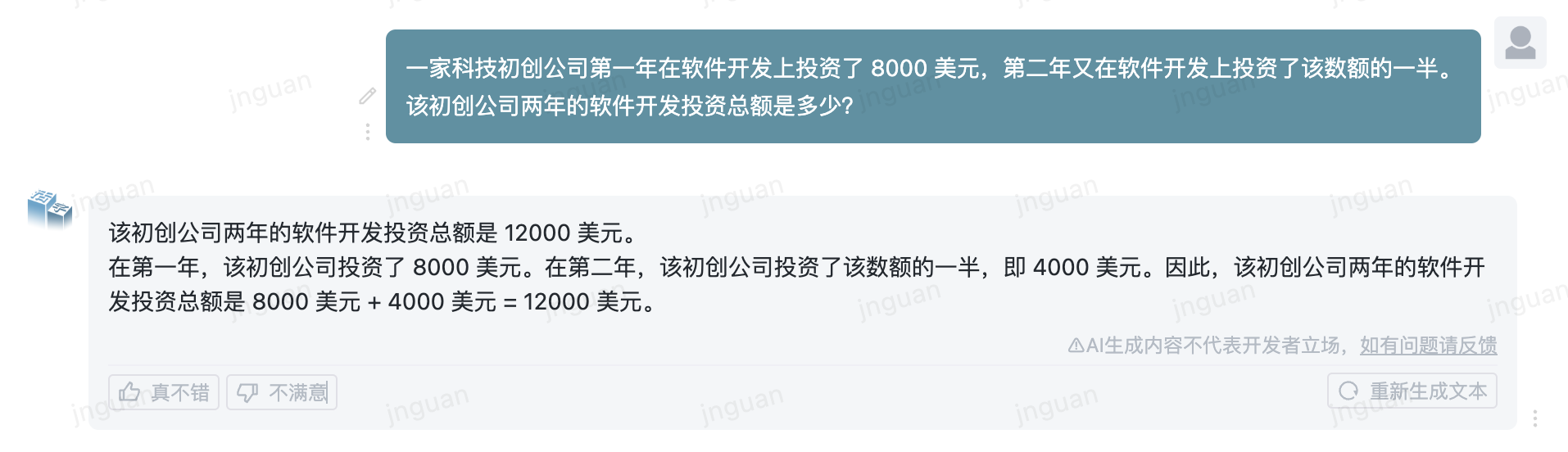
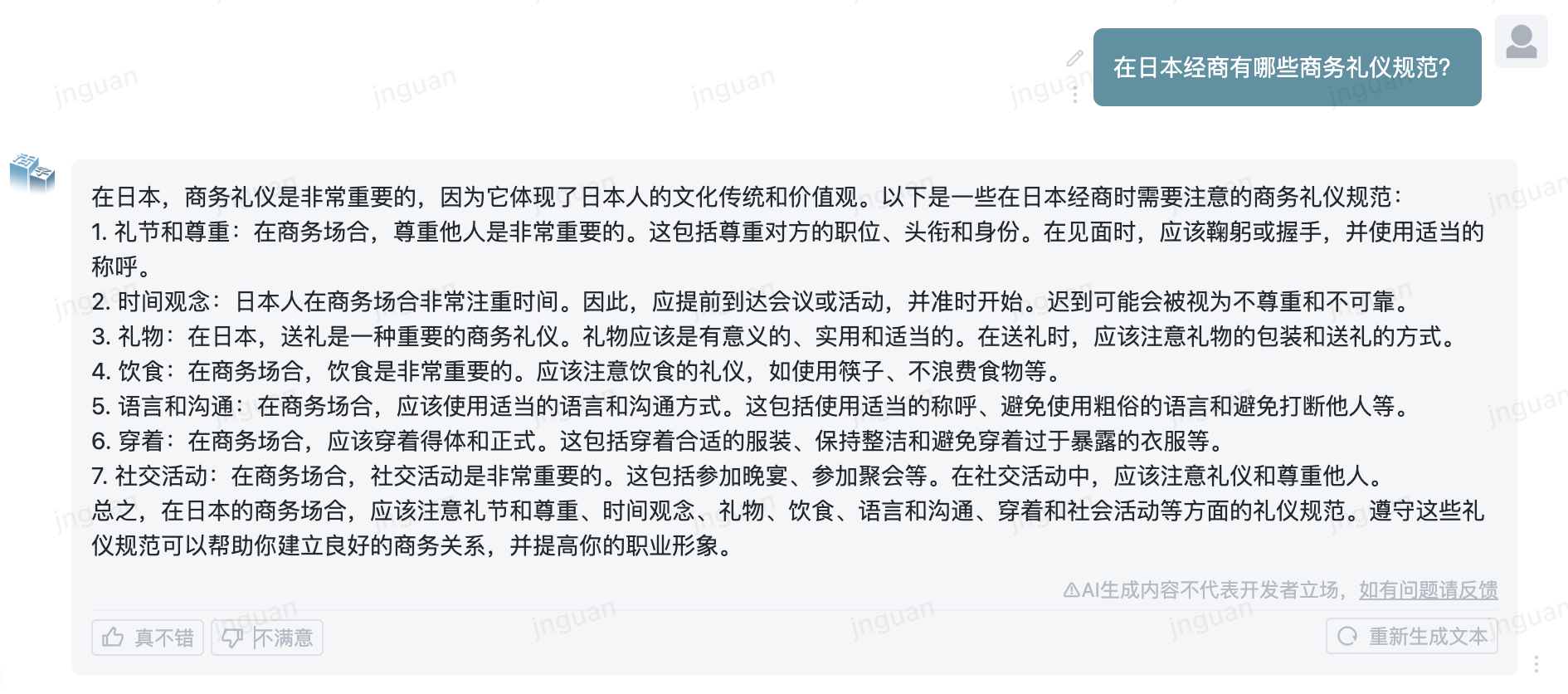
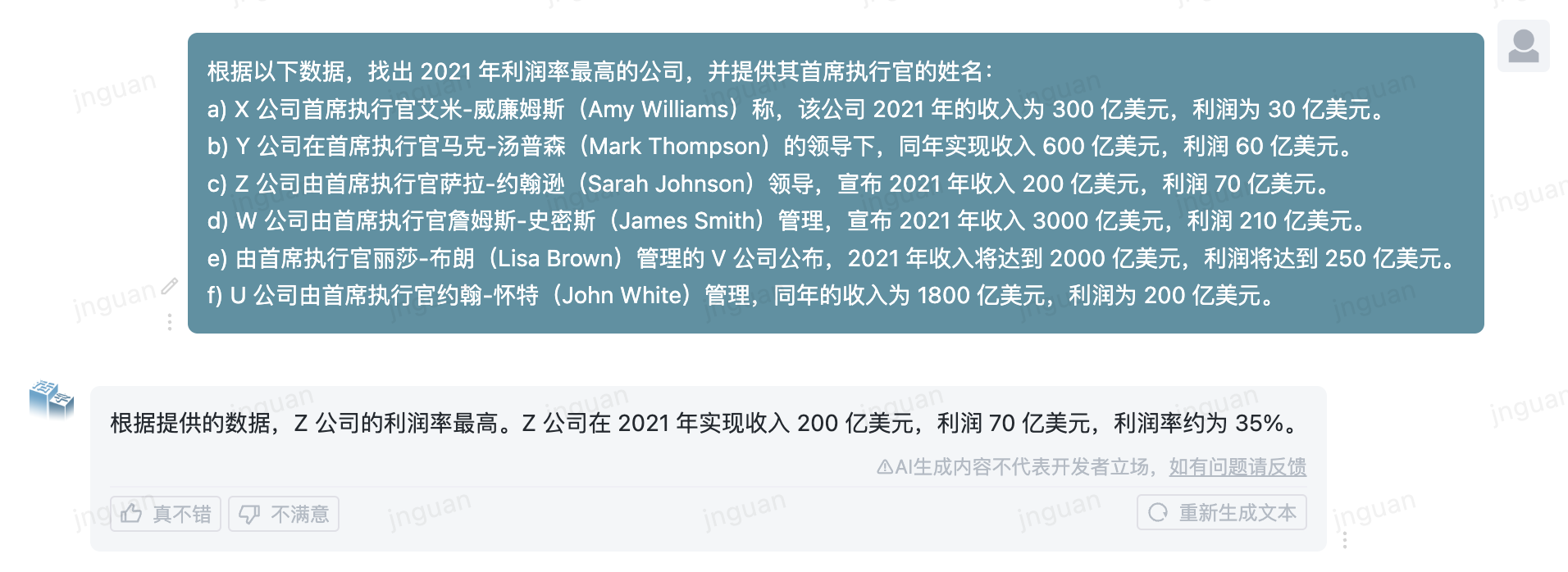
以下は、MTベンチZH評価セットに対する可動型3.5の生成効果です。



このリポジトリソースコードの使用は、オープンソースライセンス契約Apache 2.0の対象となります。
モバイルタイプは市販されています。 Movable Type Modelまたはそのデリバティブを商業目的で使用する場合は、ライセンサーに連絡して、ライセンサーから書面による許可を申請してください:[email protected]にお問い合わせください。
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

