huozi
Release huozi 3.5
| chapter | illustrate |
|---|---|
| ??♂ Open Source List | List of open source projects in this warehouse |
| Model introduction | Brief introduction to the structure and training process of movable type model |
| ? Model download | movable type model download link |
| Model reasoning | Examples of movable type model inference, including the usage process of inference frameworks such as vLLM, llama.cpp, and Ollama. |
| ? Model performance | Performance of movable type model on mainstream evaluation tasks |
| ? Generate sample | Examples of actual generation effect of movable type model |

Large-scale language model (LLM) has made significant progress in the field of natural language processing and has demonstrated its strong potential in a wide range of application scenarios. This technology not only attracted widespread attention from the academic community, but also became a hot topic in the industry. Against this background, the Center for Social Computing and Information Retrieval of Harbin Institute of Technology (HIT-SCIR) recently launched the latest achievement - movable type 3.5 , committed to providing more possibilities and choices for the research and practical application of natural language processing.
Movable type 3.5 is a model obtained by further performance enhancement based on Movable type 3.0 and Chinese-Mixtral-8x7B. movable type 3.5 supports 32K long context , inherits the powerful comprehensive capabilities of movable type 3.0, and achieves performance improvements in many aspects such as Chinese and English knowledge , mathematical reasoning , code generation , instruction compliance capabilities , content security, etc.
Important
The movable type series model may still generate misleading replies containing factual errors or harmful content that contains bias/discrimination. Please be careful to identify and use the generated content and do not spread the generated harmful content to the Internet.
Please see the documentation for movable type 1.0 and movable type 2.0 here. Please see here for documentation on movable type 3.0 and Chinese MT-Bench.
Movable Type 3.5 is a sparse hybrid expert model (SMoE), each expert layer contains 8 FFNs, and each forward calculation is sparsely activated by top-2. The movable type 3.5 has a total of 46.7B parameters. Thanks to its sparse activation characteristics, only 13B parameters need to be activated during actual reasoning, which effectively improves the computing efficiency and processing speed.
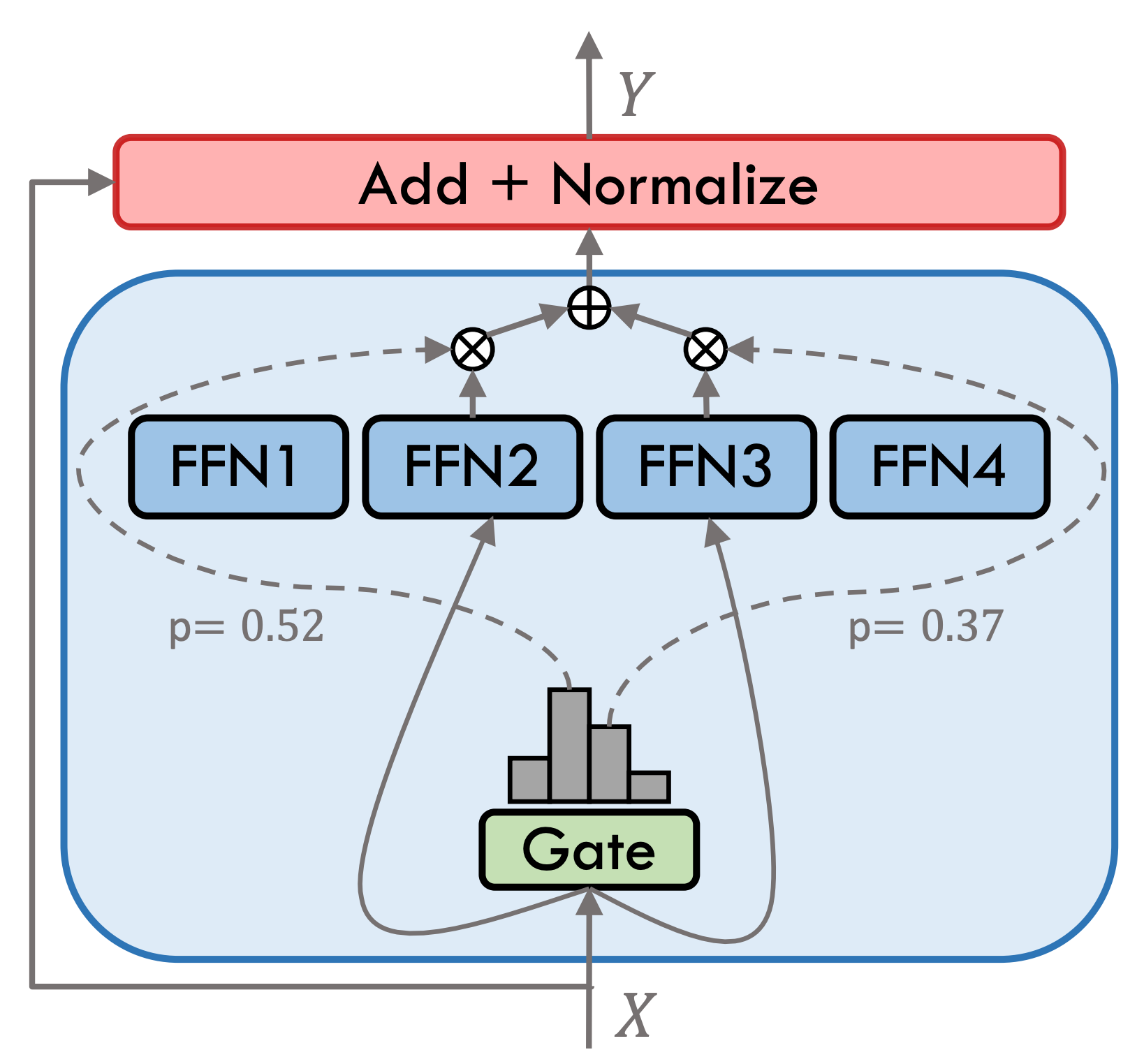
Movable Type 3.5 has undergone multiple steps of training, as shown in the figure below:
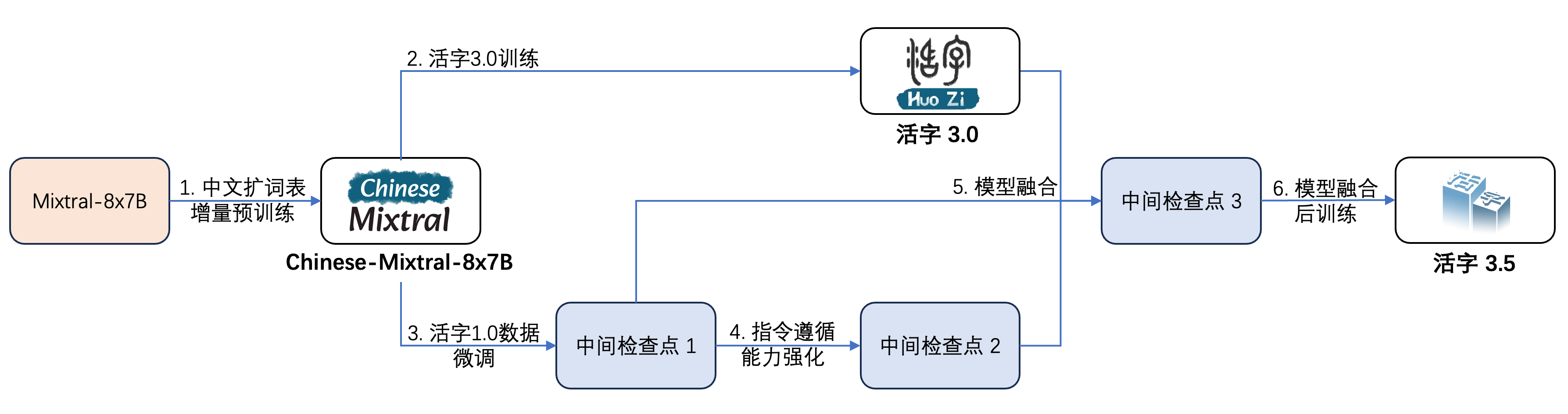
The training process is:
| Model name | File size | Download address | Remark |
|---|---|---|---|
| huozi3.5 | 88GB | ?HuggingFace ModelScope | Movable Type 3.5 Complete Model |
| huozi3.5-ckpt-1 | 88GB | ?HuggingFace ModelScope | Movable Type 3.5 Intermediate Checkpoint 1 |
| huozi3.5-ckpt-2 | 88GB | ?HuggingFace ModelScope | Movable Type 3.5 Intermediate Checkpoint 2 |
| huozi3.5-ckpt-3 | 88GB | ?HuggingFace ModelScope | Movable type 3.5 Intermediate checkpoint 3 |
If you want to fine-tune movable type 3.5 or Chinese-Mixtral-8x7B, please refer to the training code here.
Movable Type 3.5 uses the ChatML format propt template, the format is:
<|beginofutterance|>系统
{system prompt}<|endofutterance|>
<|beginofutterance|>用户
{input}<|endofutterance|>
<|beginofutterance|>助手
{output}<|endofutterance|>
The example code for reasoning using movable type 3.5 is as follows:
# quickstart.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer ( text , return_tensors = "pt" ). to ( 0 )
outputs = model . generate (
** inputs ,
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = False ))Movable Type 3.5 supports all Mixtral model ecosystems, including Transformers, vLLM, llama.cpp, Ollama, Text generation web UI and other frameworks.
If you have network issues while downloading your model, you can use the checkpoints we provide on ModelScope.
transformers support adding chat templates for tokenizer and supports streaming generation. The sample code is as follows:
# example/transformers-stream/stream.py
import torch
from transformers import AutoModelForCausalLM , AutoTokenizer , TextStreamer
model_id = "HIT-SCIR/huozi3.5"
model = AutoModelForCausalLM . from_pretrained (
model_id ,
attn_implementation = "flash_attention_2" ,
torch_dtype = torch . bfloat16 ,
device_map = "auto" ,
)
tokenizer = AutoTokenizer . from_pretrained ( model_id )
tokenizer . chat_template = """{% for message in messages %}{{'<|beginofutterance|>' + message['role'] + ' n ' + message['content']}}{% if (loop.last and add_generation_prompt) or not loop.last %}{{ '<|endofutterance|>' + ' n '}}{% endif %}{% endfor %}
{% if add_generation_prompt and messages[-1]['role'] != '助手' %}{{ '<|beginofutterance|>助手n ' }}{% endif %}"""
chat = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
]
inputs = tokenizer . apply_chat_template (
chat ,
tokenize = True ,
add_generation_prompt = True ,
return_tensors = "pt" ,
). to ( 0 )
stream_output = model . generate (
inputs ,
streamer = TextStreamer ( tokenizer , skip_prompt = True , skip_special_tokens = True ),
eos_token_id = 57001 ,
temperature = 0.8 ,
top_p = 0.9 ,
max_new_tokens = 2048 ,
)ModelScope's interface is very similar to Transformers, just replace transformers with model scope:
# example/modelscope-generate/generate.py
import torch
- from transformers import AutoModelForCausalLM, AutoTokenizer
+ from modelscope import AutoTokenizer, AutoModelForCausalLM
model_id = "HIT-SCIR/huozi3.5"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16,
device_map="auto",
)
text = """<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
"""
inputs = tokenizer(text, return_tensors="pt").to(0)
outputs = model.generate(
**inputs,
eos_token_id=57001,
temperature=0.8,
top_p=0.9,
max_new_tokens=2048,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))Variable Type 3.5 supports the implementation of inference acceleration through vLLM, and the sample code is as follows:
# example/vllm-generate/generate.py
from vllm import LLM , SamplingParams
prompts = [
"""<|beginofutterance|>系统
你是一个智能助手<|endofutterance|>
<|beginofutterance|>用户
请你用python写一段快速排序的代码<|endofutterance|>
<|beginofutterance|>助手
""" ,
]
sampling_params = SamplingParams (
temperature = 0.8 , top_p = 0.95 , stop_token_ids = [ 57001 ], max_tokens = 2048
)
llm = LLM (
model = "HIT-SCIR/huozi3.5" ,
tensor_parallel_size = 4 ,
)
outputs = llm . generate ( prompts , sampling_params )
for output in outputs :
prompt = output . prompt
generated_text = output . outputs [ 0 ]. text
print ( generated_text )Variety Type 3.5 can be deployed as a service that supports the OpenAI API protocol, which allows Variety Type 3.5 to be called directly through the OpenAI API.
Environmental preparation:
$ pip install vllm openaiStart the service:
$ python -m vllm.entrypoints.openai.api_server --model /path/to/huozi3.5/checkpoint --served-model-name huozi --chat-template template.jinja --tensor-parallel-size 8 --response-role 助手 --max-model-len 2048Send requests using OpenAI API:
# example/openai-api/openai-client.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
chat_response = client . chat . completions . create (
model = "huozi" ,
messages = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
{ "role" : "用户" , "content" : "请你用python写一段快速排序的代码" },
],
extra_body = { "stop_token_ids" : [ 57001 ]},
)
print ( "Chat response:" , chat_response . choices [ 0 ]. message . content )Here is a sample code that uses OpenAI API + Gradio + streaming:
# example/openai-api/openai-client-gradio.py
from openai import OpenAI
import gradio as gr
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI (
api_key = openai_api_key ,
base_url = openai_api_base ,
)
def predict ( message , history ):
history_openai_format = [
{ "role" : "系统" , "content" : "你是一个智能助手" },
]
for human , assistant in history :
history_openai_format . append ({ "role" : "用户" , "content" : human })
history_openai_format . append ({ "role" : "助手" , "content" : assistant })
history_openai_format . append ({ "role" : "用户" , "content" : message })
models = client . models . list ()
stream = client . chat . completions . create (
model = models . data [ 0 ]. id ,
messages = history_openai_format ,
temperature = 0.8 ,
stream = True ,
extra_body = { "repetition_penalty" : 1 , "stop_token_ids" : [ 57001 ]},
)
partial_message = ""
for chunk in stream :
partial_message += chunk . choices [ 0 ]. delta . content or ""
yield partial_message
gr . ChatInterface ( predict ). queue (). launch ()The GGUF format is designed to quickly load and save models. It is launched by the llama.cpp team and is suitable for frameworks such as llama.cpp, Ollama, etc. You can manually convert movable type 3.5 in HuggingFace format to GGUF format.
First, you need to download the source code of llama.cpp. We provide the submodule of llama.cpp in the repository. This version of llama.cpp has been tested and can successfully infer:
$ git clone --recurse-submodules https://github.com/HIT-SCIR/huozi
$ cd examples/llama.cppYou can also download the latest version of llama.cpp source code:
$ git clone https://github.com/ggerganov/llama.cpp.git
$ cd llama.cppThen it needs to be compiled. There are subtle differences in compilation commands depending on your hardware platform:
$ make # 用于纯CPU推理
$ make LLAMA_CUBLAS=1 # 用于GPU推理
$ LLAMA_METAL=1 make # 用于Apple Silicon,暂未经过测试 The following command needs to be in llama.cpp/ directory:
# 转换为GGUF格式
$ python convert.py --outfile /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi3.5
# 进行GGUF格式的q4_0量化
$ quantize /path/to/huozi-gguf/huozi3.5.gguf /path/to/huozi-gguf/huozi3.5-q4_0.gguf q4_0 The following command needs to be in llama.cpp/ directory:
$ main -m /path/to/huozi-gguf/huozi3.5-q4_0.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 999 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " The -ngl parameter indicates the number of layers of offload to the GPU. Reducing this value can alleviate the GPU video memory pressure. After our actual test, the q2_k quantized model has a 16-layer offload, and the memory usage can be reduced to 9.6GB, which can run the model on consumer GPUs:
$ main -m /path/to/huozi-gguf/huozi3.5-q2_k.gguf --color --interactive-first -c 2048 -t 6 --temp 0.2 --repeat_penalty 1.1 -ngl 16 --in-prefix " <|beginofutterance|>用户n " --in-suffix " <|endofutterance|>n<|beginofutterance|>助手" -r " <|endofutterance|> " For more parameters of main , you can refer to the official documentation of llama.cpp.
Use the Ollama framework for reasoning, you can refer to Ollama's README instructions.
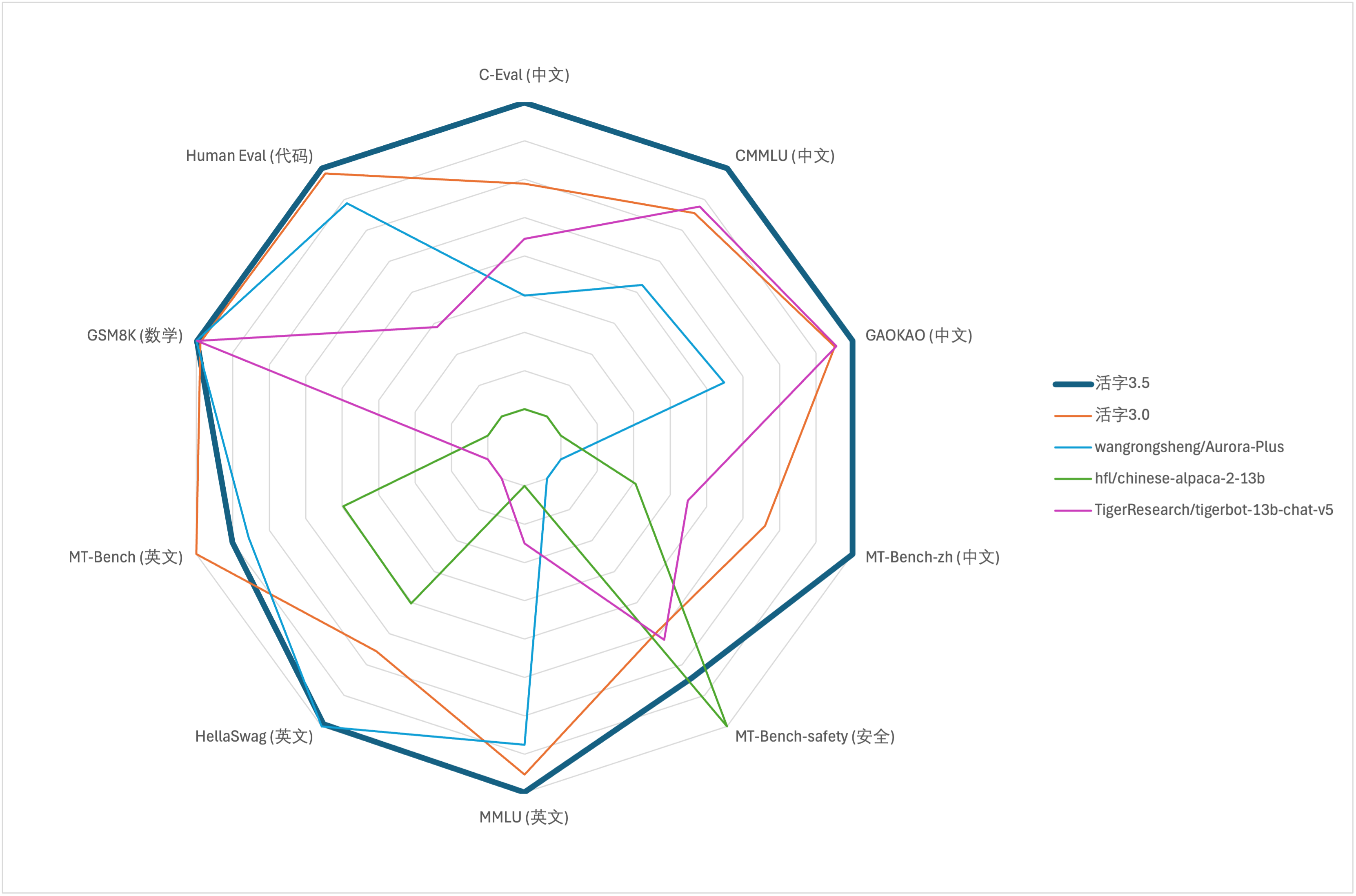
For the comprehensive ability evaluation of large models, we used the following evaluation dataset to evaluate movable type 3.5 respectively:
Movable Type 3.5 activates only 13B parameters when inference. The following table shows the results of Chinese models of movable type 3.5 and other 13B scales and the old version of movable type on each evaluation dataset:
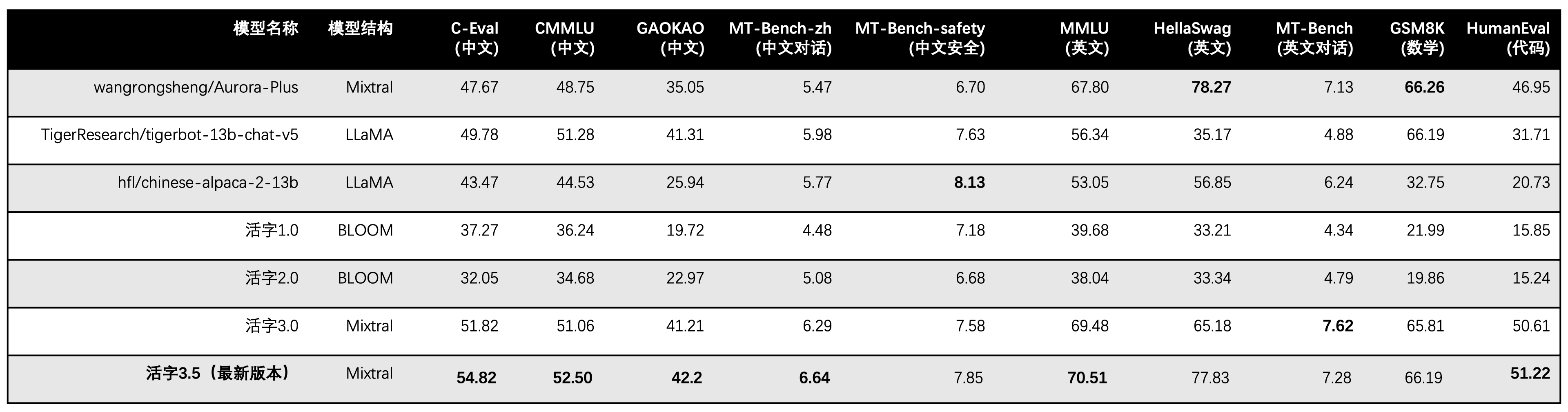
We use 5-shot in C-Eval, CMMLU, and MMLU, GSM8K uses 4-shot, HellaSwag and HumanEval use 0-shot, and HumanEval uses pass@1 indicator. All tests were greedy strategy.
We use OpenCompass as the evaluation framework and the commit hash is 4c87e77. The review code is located here.
In the performance evaluation of movable type 3.0, we used the base model evaluation method in HumanEval incorrectly, and the correct evaluation results have been updated in the above table.
According to the test results in the above table, movable type 3.5 has achieved a relatively stable performance improvement compared with movable type 3.0, and the Chinese and English knowledge , mathematical reasoning , code generation , Chinese instruction compliance ability , and Chinese content security of movable type 3.5 have been strengthened.
The following is the generation effect of movable type 3.5 on the MT-Bench-zh evaluation set:
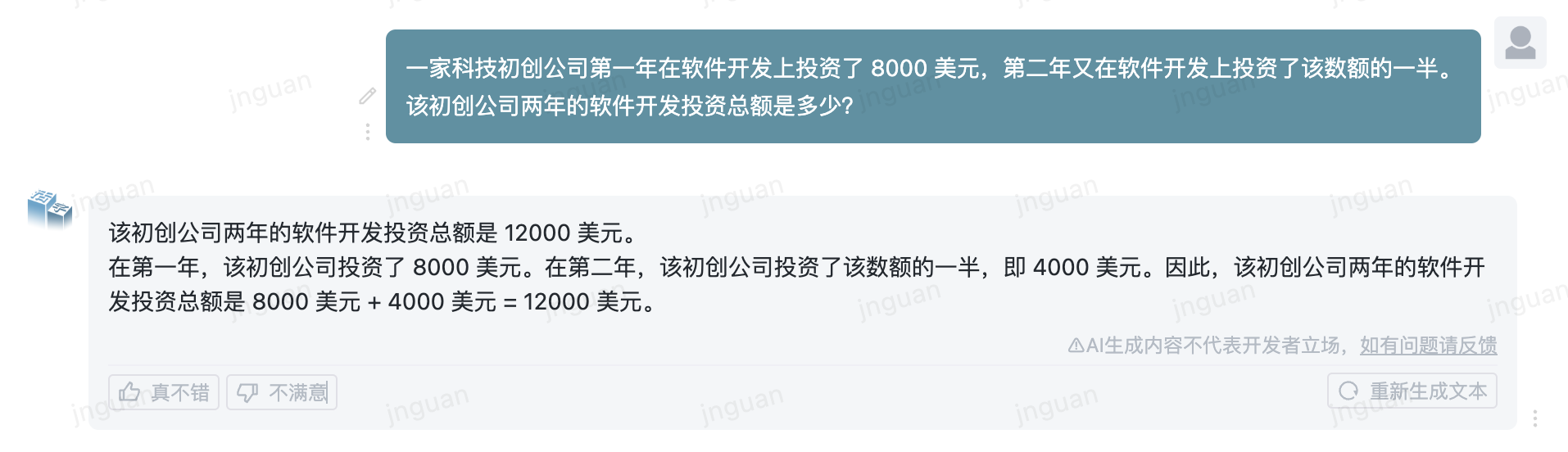



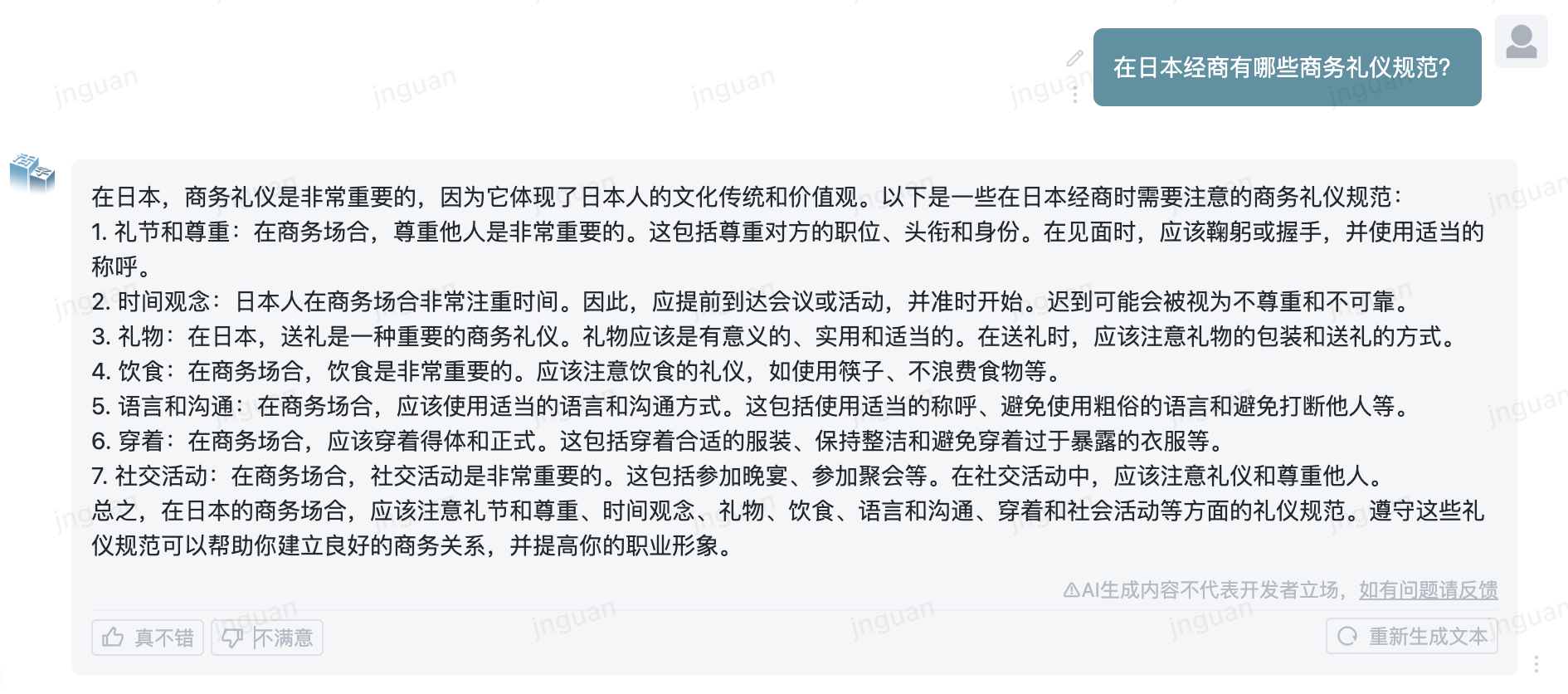
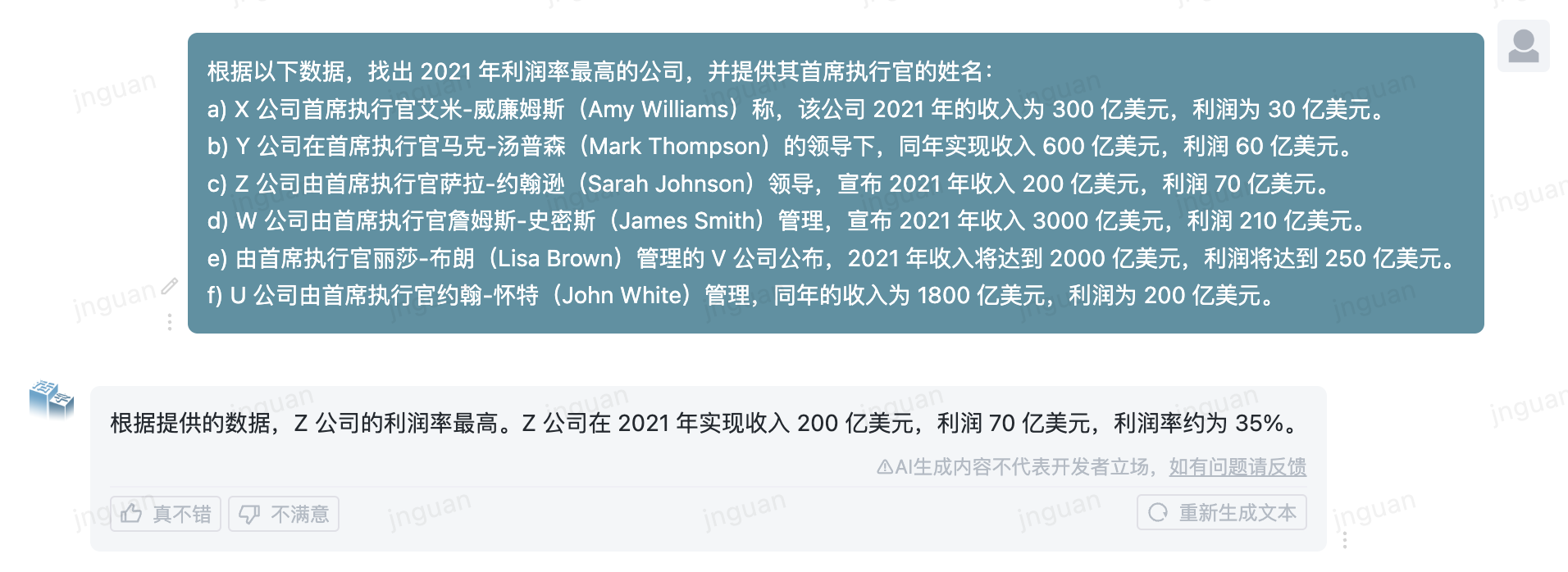
The use of this repository source code is subject to the open source license agreement Apache 2.0.
Mobile type is commercially available. If you use the movable type model or its derivatives for commercial purposes, please contact the licensor as follows to register and apply for written authorization from the licensor: Contact email: [email protected].
@misc{huozi,
author = {Huozi-Team}.
title = {Huozi: Leveraging Large Language Models for Enhanced Open-Domain Chatting}
year = {2024},
publisher = {GitHub},
journal = {GitHub repository}
howpublished = { url {https://github.com/HIT-SCIR/huozi}}
}

